
检索增强生成(RAG)系统通过集成外部知识源,提升了大型语言模型(LLMs)的准确性和上下文相关性。然而,现有的RAG方法仍存在明显的不足,包括对平面数据表示的依赖和对复杂上下文的处理能力不足,这常常导致回答碎片化,无法捕捉信息之间的深层关系。


为了解决这些问题,我们推出了LightRAG。这一创新框架将图形结构引入文本索引和信息检索过程,采用双级检索系统,提升了从低级和高级知识发现中获取综合信息的能力。图形结构与向量表示的结合,不仅优化了检索效率,还支持对相关实体及其关系的精确搜索,显著缩短响应时间,并保持强烈的上下文关联性。增量更新算法的集成,确保了系统在动态数据环境中的敏捷性和时效性。
在实际应用中,LightRAG可以通过两个层级的检索策略应对各种复杂查询需求:第一层级关注具体实体及其关系的精准信息检索,第二层级覆盖更广泛的主题范围。这种结合细节与整体的检索方式,保证了用户获取的回答更贴合实际需求,信息更连贯。
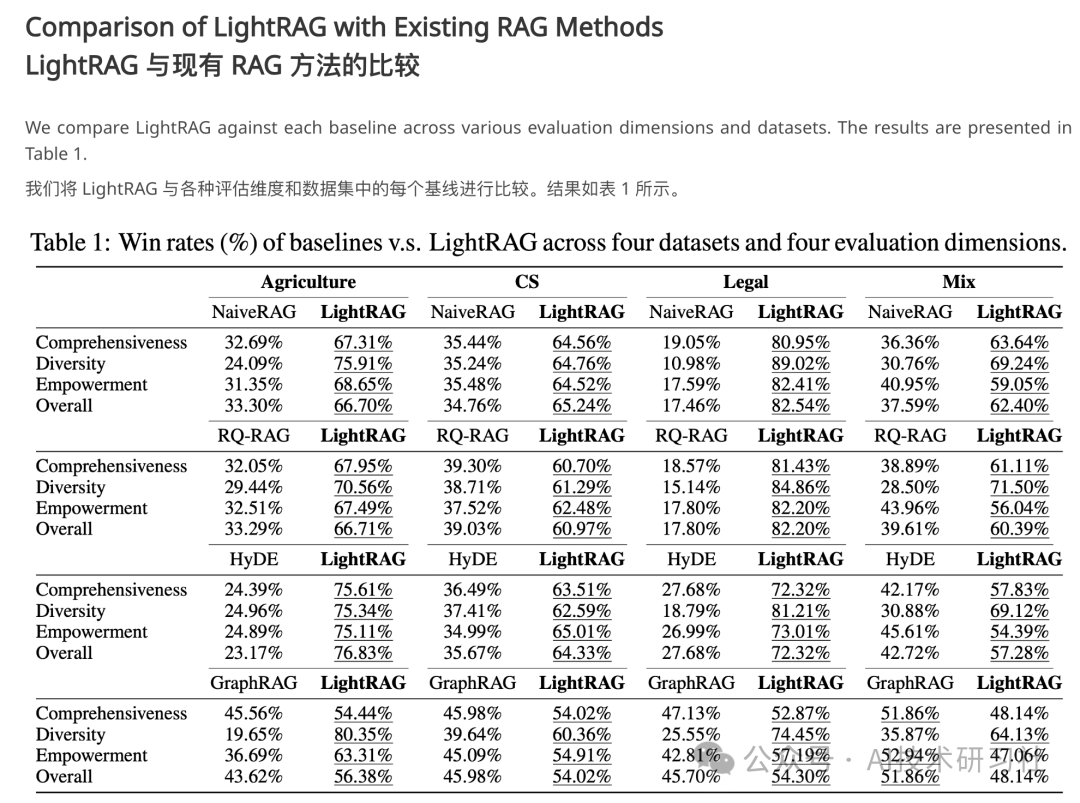
此外,图结构的整合使得LightRAG能够识别信息间的复杂相互依赖性,将原本可能分散的答案编织成逻辑严谨的响应。广泛的实验结果表明,LightRAG在检索准确性和响应速度上均优于现有系统。代码已开源,详情请访问:LightRAG项目地址。
LightRAG 增强了分段检索系统 将文档转换为更小、更易于管理的片段。此策略允许快速 识别和访问相关 信息,而无需分析整个文档。接下来,我们利用LLMs 来识别和 提取各种实体(例如 名称、日期、位置和事件)以及它们之间的关系。这通过此收集的信息进程将用于创建一个全面的知识图谱,该图谱突出显示跨整个文档集合。基于图形的文本索引中使用的函数 paradigm 的描述如下:
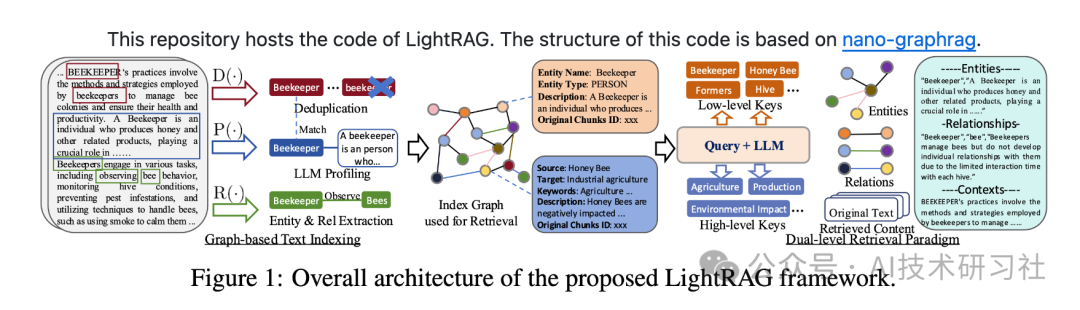
这张图片展示了LightRAG框架的整体架构,主要涉及以下几个步骤和组件:
- 图形化文本索引:
- 文本经过处理,提取出实体及其关系。例如,从“BEKEEPER”相关的文本段落中提取出“Beekeeper”和“Bees”等实体。
- 通过实体识别和关系提取,将这些信息以图形结构的形式进行组织。
- 重复的实体会被去重,生成的图形索引用于后续的信息检索。
- 索引图的创建:
- 实体之间的关系被映射到图中,图中节点表示不同的实体或概念,边表示实体之间的关系。
- 通过这种方式,图结构可以更好地表达数据中的上下文信息,帮助系统理解复杂的相互依赖关系。
- 双级检索策略:
- 在检索过程中,LightRAG采用双级检索:低级检索侧重于具体的细节和实体(如“Beekeeper”、“Honey Bee”等),而高级检索涵盖更广泛的主题(如“农业”、“生产”或“环境影响”等)。
- 这种双级策略能够更好地响应不同层次的问题,既能回答具体的问题,也能提供整体的背景信息。
- 检索与生成集成:
- 检索到的信息根据查询的需求与语言模型(LLM)结合,生成最终的响应。
- 图结构中包含的实体、关系和上下文信息,能够提高响应的连贯性和上下文关联性。
- 增量更新与响应生成:
- 系统支持动态数据更新,通过增量更新算法保证图形结构的及时更新。
- 在图结构的基础上生成的响应,结合了最新的数据和最相关的实体与关系,从而提升系统的响应质量和速度。
整体上,LightRAG框架通过图形化索引和双级检索策略,克服了传统RAG系统的局限,使得信息检索和生成的过程更加智能和高效。

简要概括安装和使用LightRAG的过程如下:
- 源码安装(推荐):
cd LightRAGpip install -e . - 通过PyPI安装:
pip install lightrag-hku - 如果使用OpenAI模型,请在环境中设置OpenAI API密钥。
- 快速开始
import osfrom lightrag import LightRAG, QueryParamfrom lightrag.llm import gpt_4o_mini_complete, gpt_4o_complete########## Uncomment the below two lines if running in a jupyter notebook to handle the async nature of rag.insert()# import nest_asyncio# nest_asyncio.apply()#########WORKING_DIR = "./dickens"if not os.path.exists(WORKING_DIR):os.mkdir(WORKING_DIR)rag = LightRAG(working_dir=WORKING_DIR,llm_model_func=gpt_4o_mini_complete # Use gpt_4o_mini_complete LLM model# llm_model_func=gpt_4o_complete # Optionally, use a stronger model)with open("./book.txt") as f:rag.insert(f.read())# Perform naive searchprint(rag.query("What are the top themes in this story?", param=QueryParam(mode="naive")))# Perform local searchprint(rag.query("What are the top themes in this story?", param=QueryParam(mode="local")))# Perform global searchprint(rag.query("What are the top themes in this story?", param=QueryParam(mode="global")))# Perform hybrid searchprint(rag.query("What are the top themes in this story?", param=QueryParam(mode="hybrid")))
参考:https://github.com/HKUDS/LightRAG