收录于话题
本文来自剑桥同学(微信号:AI_Discovery_)的投稿
Tudor Brindus,Jane Street的软件工程师,在一次技术分享中深入探讨了如何在低延迟系统中减少抖动——即输入处理时间的偏差。在高频交易等对延迟敏感的领域,保持稳定且低的抖动对于降低风险至关重要,这可以让我们在不增加额外风险的情况下提供更紧密的市场报价。如果因为抖动导致处理数据的延迟,即使是10微秒的滞后,都可能导致错误的交易,这对于交易公司来说是不可接受的。
Tudor 以一个简单的内存乒乓应用为案例,详细讲解了如何识别并解决由 Linux 内核 和 微架构条件 引起的常见抖动源。


一个玩具示例:在机器内的多核间分发消息
Tudor 以一个简单的乒乓案例作为切入点,向大家讲解了在机器内多个进程之间分发消息的机制。虽然这是一个简化的示例,但在现实生活中,这可能类似于从交易所获取的市场数据行情。这些数据量非常庞大,可能每秒达到约 1GB,并且对延迟非常敏感。他指出,抖动可能导致交易滞后,即使是 1 毫秒 或 10 微秒 的滞后,也可能引发错误的交易决策,这对交易公司来说是不可接受的。
引入环形缓冲区
Tudor 介绍了环形缓冲区(Ring Buffer) 的概念,这是一个具有固定大小单元的数组,当数据到达数组末尾时会重新循环到起点。他解释道,通过在机器上的两个进程之间建立环形缓冲区,可以实现高效的数据传递。

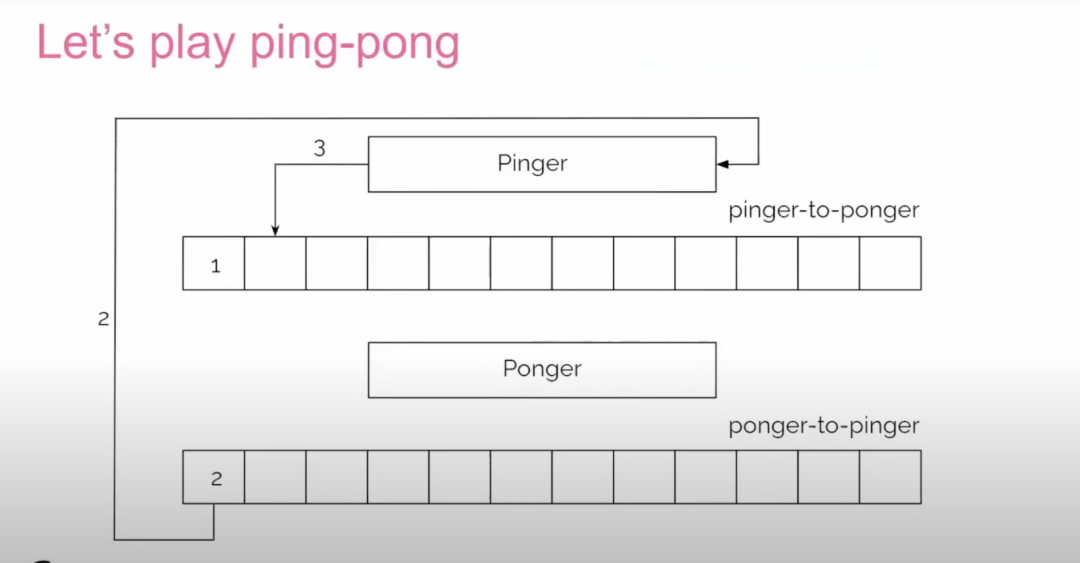
在他的乒乓示例中,有两个进程:pinger 和 ponger,以及两个环形缓冲区,用于在这两个进程之间传递数据。他们通过在缓冲区中写入和读取整数,实现数据的往返传输。Tudor 用一个发球者(Pinger)和接球者(Ponger)的案例演示了环形缓冲区的使用:
-
发球者在发球者到接球者的环形缓冲区的第一个单元中写入整数 1。 -
接球者读取该值 1,加1得到2,然后将其写回接球者到发球者的环形缓冲区。 -
发球者读取回来的值,继续加 1得到3,然后写入环形缓冲区的下一个单元。 -
当到达环形缓冲区的末尾时,循环重新开始。
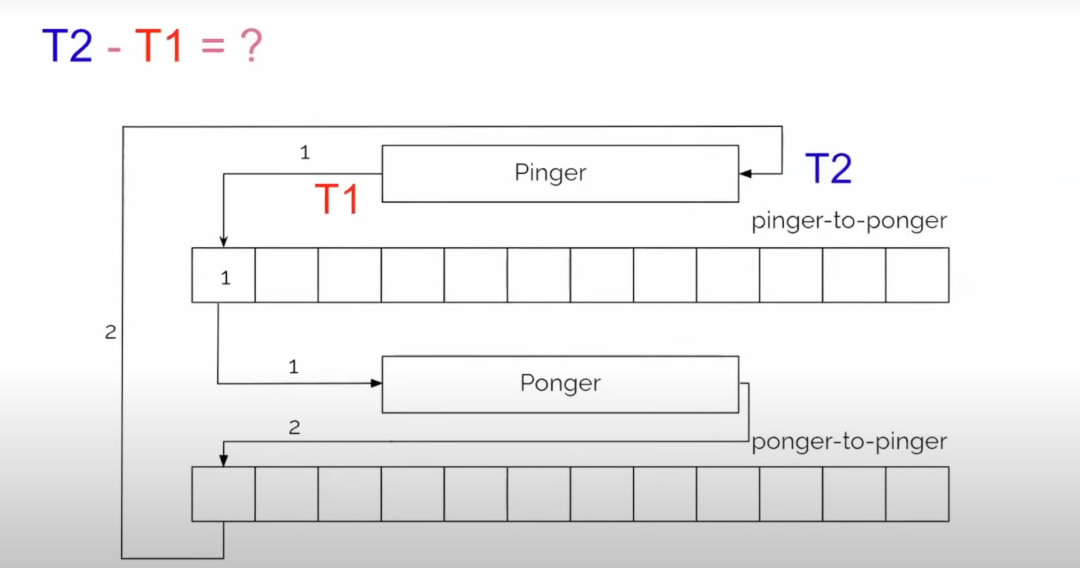
他通过 OCaml 代码 展示了这一逻辑,并讨论了延迟的测量方法——通过记录发球者写入值和接球者完成处理的时间戳,计算延迟 T2 - T1。
let ping_pong consumer producer =
while true do
let read_buf = Ringbuf.Consumer.poll consumer in
if not (Iobuf.is_empty read_buf)
then (
let data = Iobuf.Consume.int64_le_trunc read_buf in
let new_data = data + 1 in
let write_buf = Ringbuf.Producer.write_buf producer in
Iobuf.Fill.int64_le write_buf new_data;
Ringbuf.Producer.finish_write producer;
Ringbuf.Consumer.finish_poll consumer
)
done
;;
Tudor 指出,Jane Street 非常重视 OCaml,但 OCaml 基本上是一个 单线程 的运行时环境。要实现并行性,需要使用多个进程,并可能需要在它们之间传递共享内存。他介绍了如何在同一台机器上的两个进程之间传递内存,使用一个 环形缓冲区(ring buffer) 来实现数据交换。
基准测试设置
-
典型的英特尔服务器 -
第二代英特尔至强金牌 CPU @ 3.6 GHz(Cascade Lake) -
2666 MHz DDR4 内存 -
Linux 3.10

基准测试的初步结果
在基准测试设置中,Tudor 使用了一台典型的 Intel 服务器(第二代 Cascade Lake,运行频率 3.6GHz)。测试表明,抖动可能高达 16 微秒。
这引出了一个重要问题:抖动的来源是什么?
优化前的初始尝试:虚拟化环境与裸机硬件
Tudor 在优化过程中,首先比较了虚拟化环境(Virtualized Environment) 和裸机硬件(Bare Metal Hardware) 的性能差异,结果显示裸机硬件在延迟和抖动控制上具有明显优势。
Try 1: 虚拟化环境(Virtualized Environment)
在虚拟机(VM)中运行测试时,延迟测量的结果显示:
-
延迟: 抖动范围高达 16 微秒。 -
特征: -
存在大量噪声,尤其在延迟的长尾部分(如 1 微秒以上)。 -
可能是由于邻居噪声问题(Noisy Neighbor Problem),即同一物理主机上运行的其他虚拟机占用了 CPU 周期。 -
还可能存在虚拟机额外开销,例如上下文切换和虚拟化相关的中断处理。
问题分析:
虚拟机引入了大量不可控的延迟,尤其是尾部延迟。对于高性能低延迟系统来说,这种不确定性会极大影响稳定性。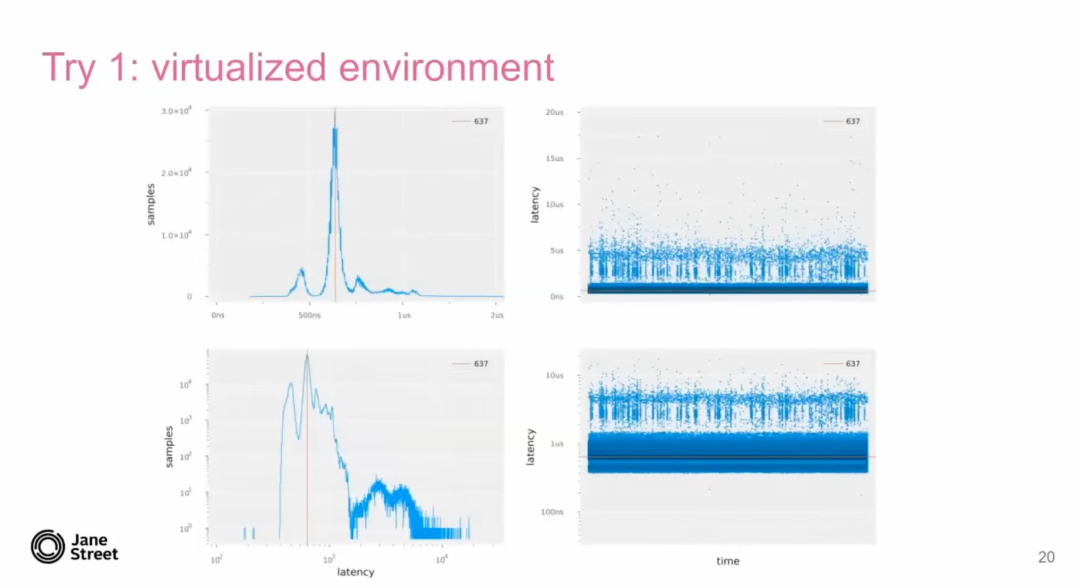
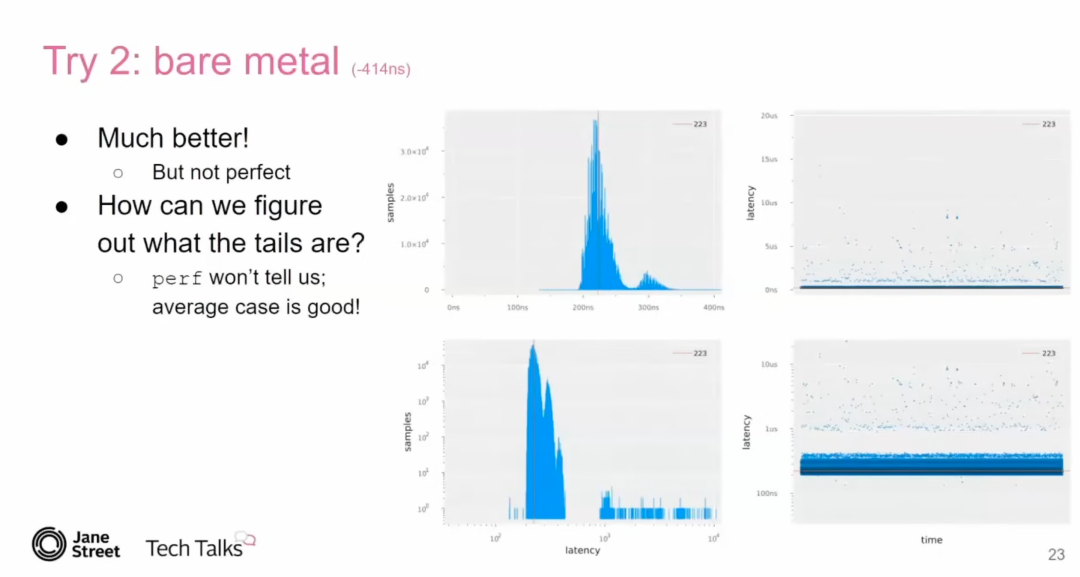
Try 2: 裸机硬件(Bare Metal Hardware)
通过将相同的测试程序从虚拟化环境切换到裸机硬件(直接在物理主机上运行)后,结果显著改善:
-
延迟: 从 637 纳秒 降至 223 纳秒。 -
特征: -
抖动减少了大部分噪声。 -
延迟曲线更加平滑,尤其是尾部延迟显著改善。
优化分析:
-
无虚拟化开销: 裸机硬件直接运行程序,避免了虚拟机带来的中断处理和邻居噪声问题。 -
更高的性能确定性: 裸机硬件的延迟更可预测,减少了不确定性。
总结:虚拟化与裸机的对比
Tudor 强调,如果性能和延迟确定性非常重要,应优先选择裸机硬件而非虚拟机环境。虽然裸机硬件可能会增加基础设施成本,但其在性能上的优势为高性能低延迟系统带来了更稳定和可靠的运行环境。
然而,在裸机环境下仍然存在一些延迟峰值(例如 1 微秒 的延迟),这需要进一步优化。
深入识别并消除抖动源
虚拟化环境的影响
Tudor 指出,由于在虚拟机(VM)上运行程序,可能会遇到 邻居噪声问题(Noisy Neighbor Problem),即共享主机的其他用户占用了资源。此外,虚拟机还可能带来额外的开销。
他建议使用裸机硬件(Bare Metal Hardware) 来避免这些问题。通过简单地切换到裸机运行,延迟从 637 纳秒 降至 223 纳秒,同时大幅减少了噪声。
然而,在裸机环境下仍然存在一些延迟峰值(例如 1 微秒 的延迟),这需要进一步优化。
网络中断导致的抖动
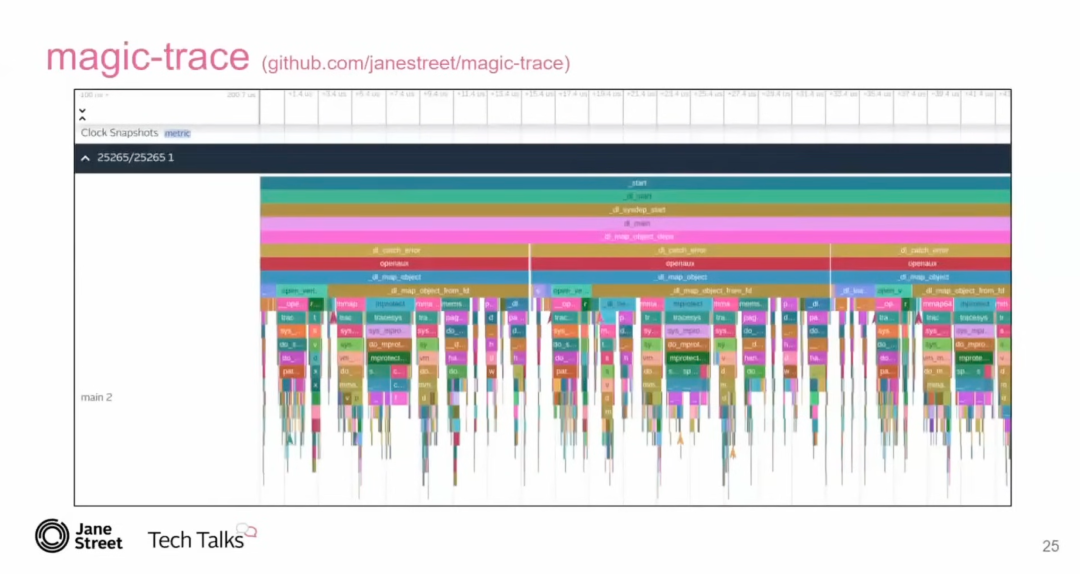
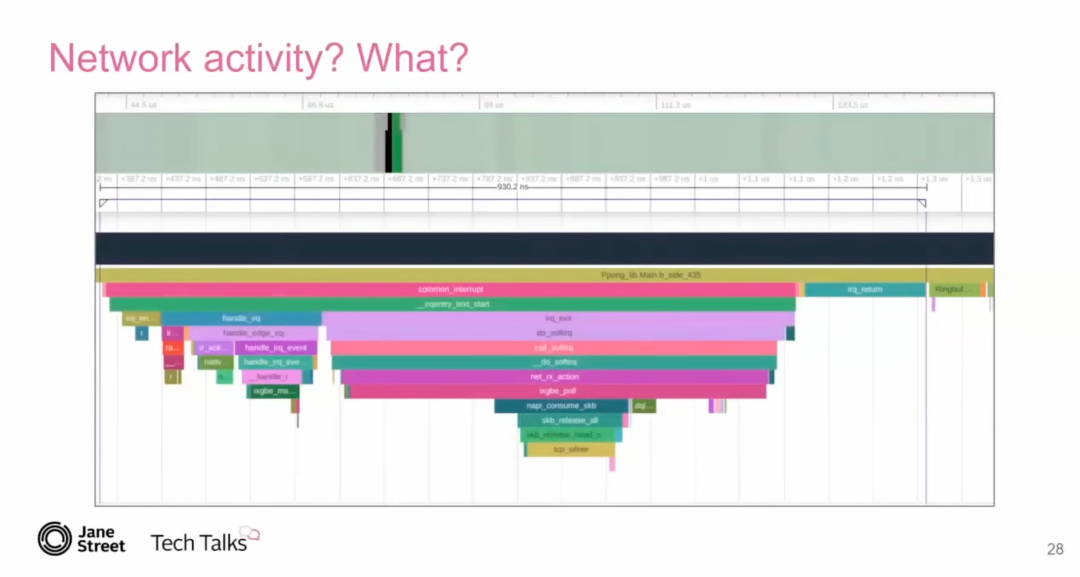
面对即使在裸机上,系统仍然存在抖动的问题,Tudor 使用了 MagicTrace 。MagicTrace 这个工具可以生成包含调用栈深度和时间轴的图表,帮助定位抖动的来源。Tudor使用MagicTrace分析延迟峰值后发现,网络活动 会通过中断机制干扰 CPU 的正常运行,导致系统抖动。这是因为当网络设备接收到数据包时,会通过中断通知 CPU,这些中断可能会影响正在运行的应用程序。

解决方法:
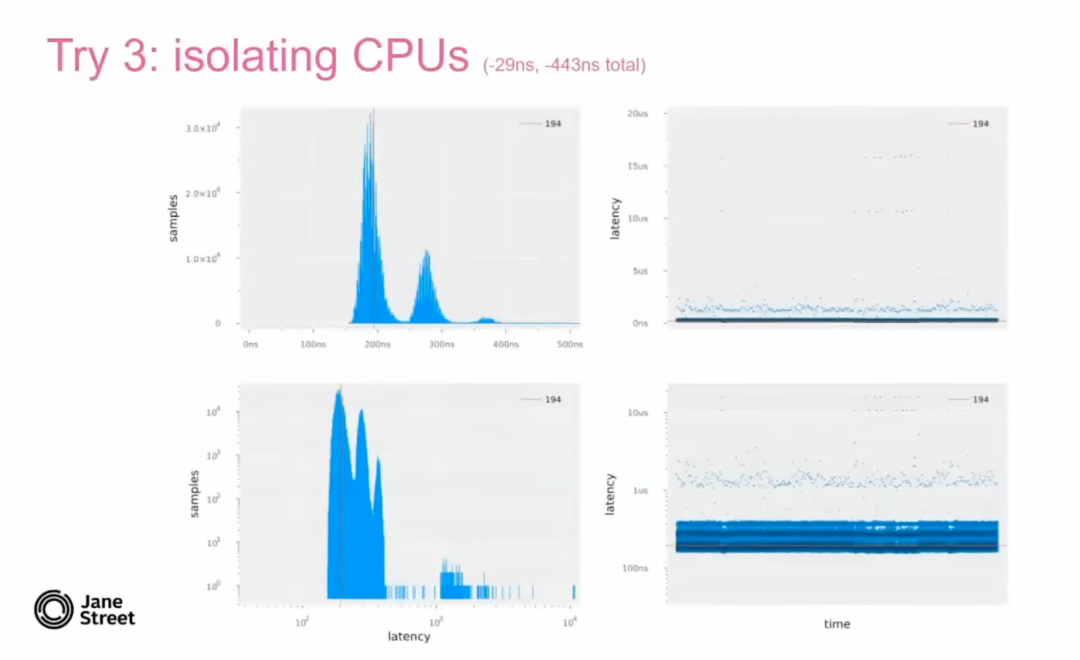
-
使用内核参数 isolcpus隔离特定的 CPU 核心,将特定的 CPU 核心隔离出来,避免它们处理网络中断。 -
将需要运行的进程绑定到隔离的 CPU 核心上(例如通过 taskset命令)。
优化效果:
通过这一调整,系统延迟从 223 纳秒 降低到了 194 纳秒,同时抖动显著减少。
定时器中断的影响
进一步的分析显示,本地定时器中断 也是抖动的来源。默认情况下,内核每秒钟会触发 1000 次 定时器中断,用于调度和统计。通过设置 nohz_full 参数,可以关闭这些定时器中断,从而将延迟降低到 170 纳秒。

解决方法:
-
使用内核参数 nohz_full关闭定时器中断,使内核在特定 CPU 核心上尽量减少中断频率。
优化效果:
这一调整将定时器中断的频率从每秒一千次减少到每秒一次,使延迟进一步降低了 24 纳秒。
处理器频率调整的影响
Turbo Boost 等处理器频率调整技术会引入频率转换的延迟,导致抖动。禁用 Turbo Boost 可以提高延迟的一致性,尽管这可能会略微降低平均性能。在实验中,禁用后系统的延迟稳定在了 164 纳秒。
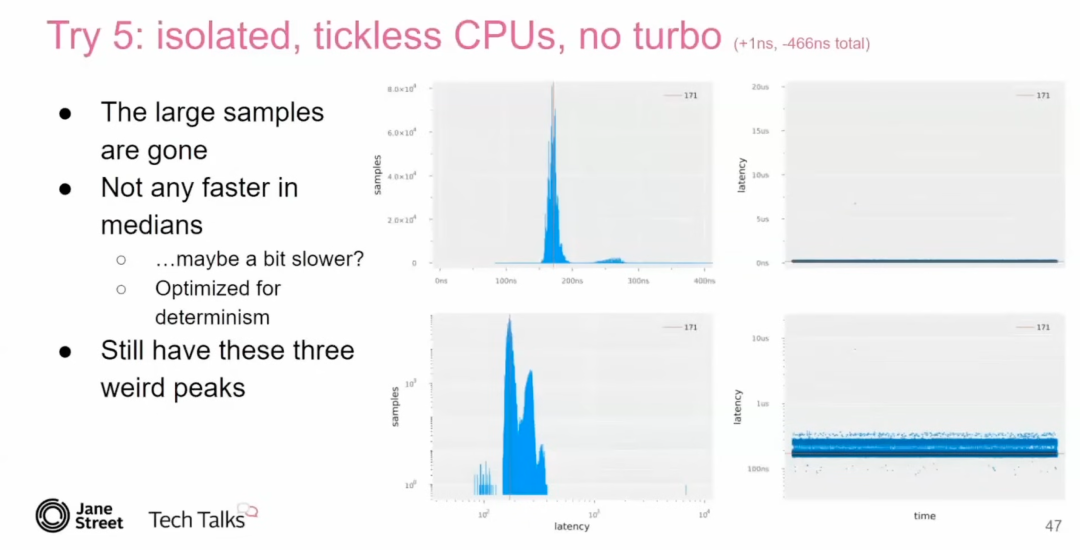
微架构级别的优化
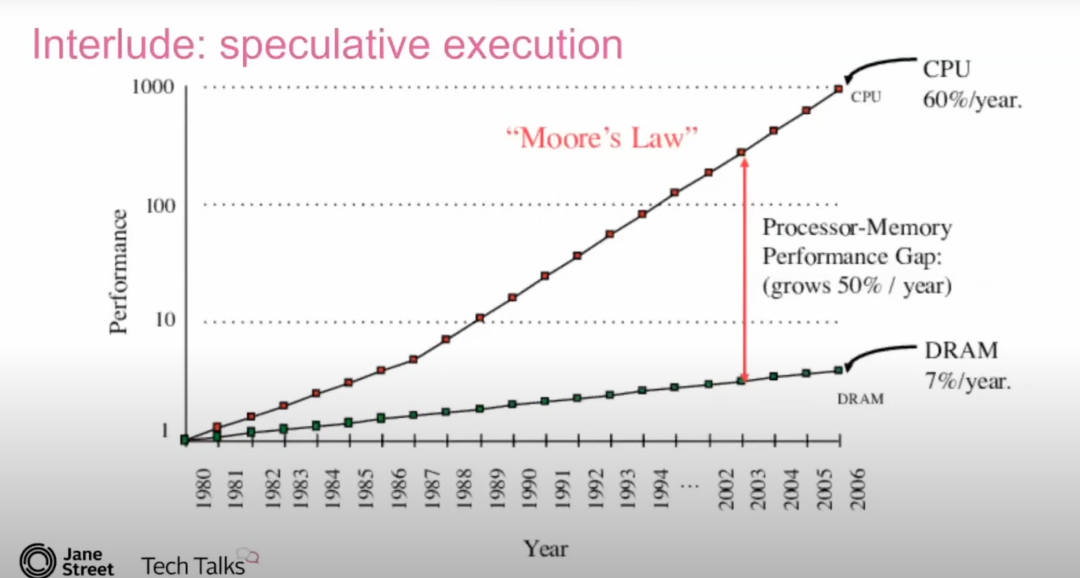
即使经过上述优化,仍然存在一些抖动。Tudor 指出,这可能与 推测执行(speculative execution) 相关。在高频循环中,CPU 会猜测下一个操作,从而导致 错误推测(bad speculation),引入性能开销。
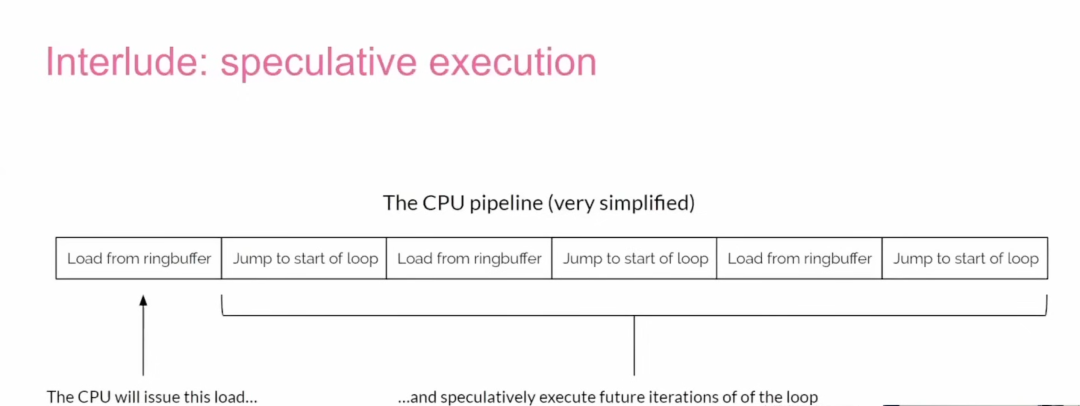
通过在循环中加入 pause 指令,可以提示处理器进行优化,减少错误推测。对于 OCaml 代码,需要在编译器中引入对应的 内联函数(intrinsic)。这一优化使延迟进一步降低到了 163 纳秒。
关于推测执行的代码示例
let ping_pong consumer producer =
while true do
let read_buf = Ringbuf.Consumer.poll consumer in
if not (Iobuf.is_empty read_buf)
then (
let data = Iobuf.Consume.int64_le_trunc read_buf in
let new_data = data + 1 in
let write_buf = Ringbuf.Producer.write_buf producer in
Iobuf.Fill.int64_le write_buf new_data;
Ringbuf.Producer.finish_write producer;
Ringbuf.Consumer.finish_poll consumer
)
done
;;
硬件选择的重要性
最后,Tudor 还提到了硬件本身对性能的影响。使用更高频率的 CPU 和更快的内存可以显著提高性能。然而,过度超频可能导致系统不稳定,甚至出现内存错误。
关键总结
通过这一系列优化,Tudor 将系统的延迟从最初的 637 纳秒 降低到了 163 纳秒,抖动也大大减少。
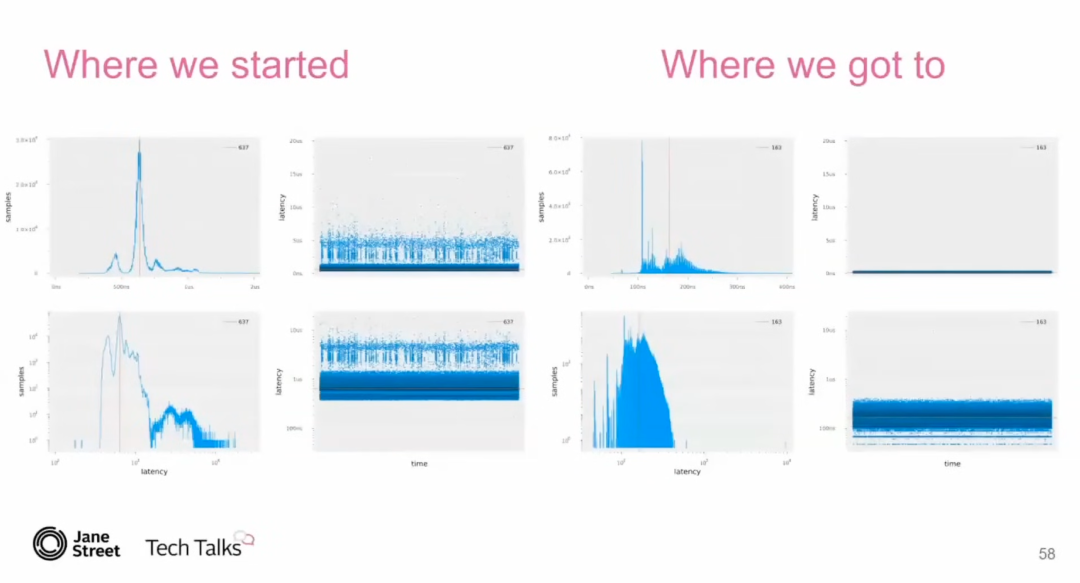
主要的经验教训包括:
-
避免在虚拟化环境中运行对延迟敏感的应用。 -
深入理解系统架构,针对性地进行优化。 -
硬件选择至关重要,但需要平衡性能和稳定性。 -
持续监测系统性能,及时发现并解决问题。
总结
Tudor的本次分享深入揭示了在低延迟系统中减少抖动的各种方法。从软件层面的参数调整到微架构级别的优化,每一步都需要对系统有深刻的理解。
对于从事高频交易、实时系统或任何对延迟敏感的领域的工程师,这些经验都具有重要的参考价值。
QuantML星球内有各类丰富的量化资源,包括上百篇量化论文代码,QuantML-Qlib框架,研报复现项目等,星球群内有许多大佬,包括量化私募创始人,公募jjjl,券商研究员,顶会论文作者,github千星项目作者等,星球人数已经500+,欢迎加入交流
我们的愿景是搭建最全面的量化知识库,无论你希望查找任何量化资料,都能够高效的查找到相关的论文代码以及复现结果,期待您的加入。