
2024年10月28日arXiv cs.CV发文量约64余篇,减论Agent通过算法为您推荐并自动化整理为卡片供您参考,预计为您节省25分钟浏览Arxiv的时间。
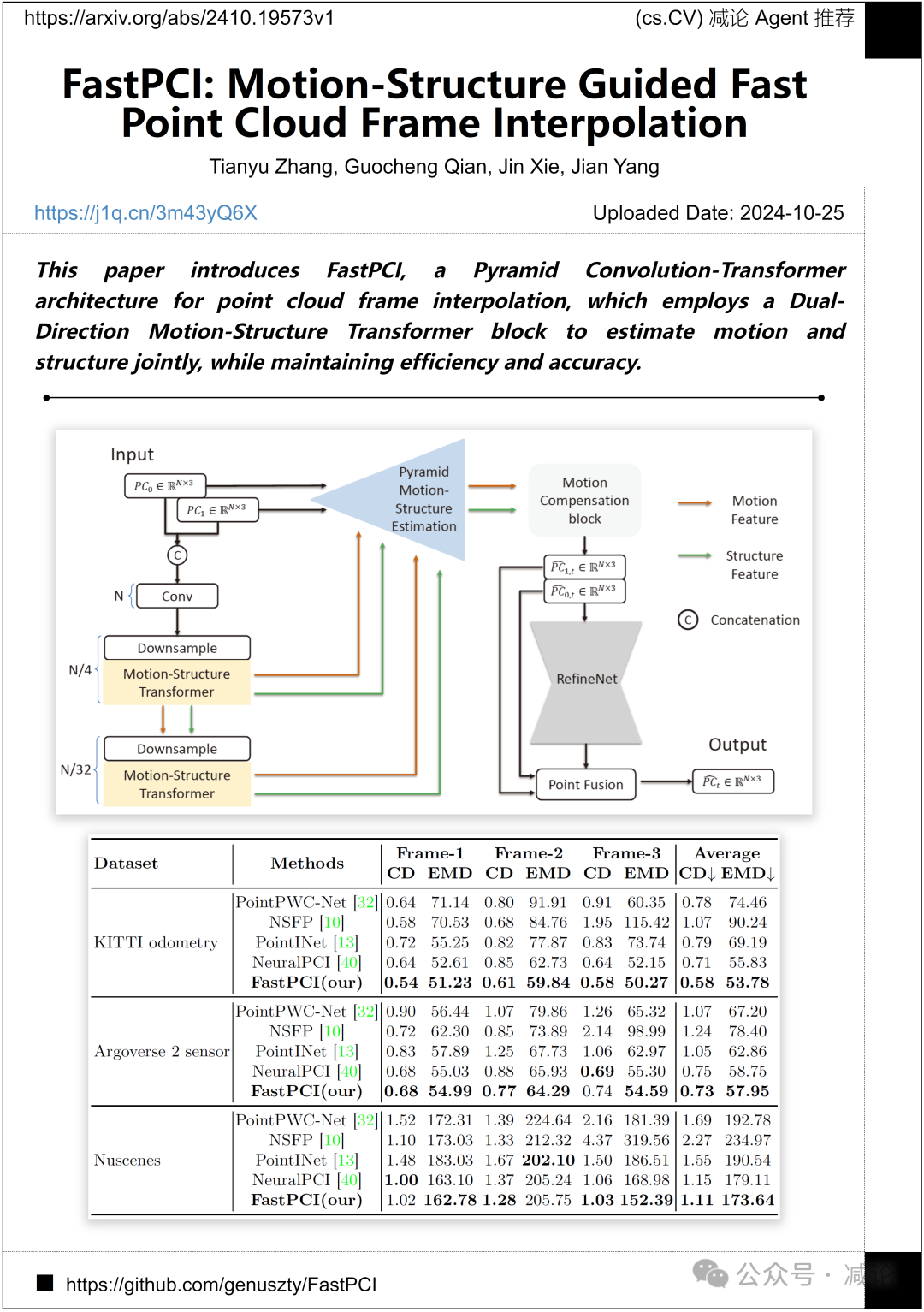

南开大学、快照研究和南京大学的团队提出了FastPCI,一种用于点云帧插值的金字塔卷积-Transformer架构,它采用双向运动–结构Transformer块来联合估计运动和结构,同时保持效率和准确性。
https://j1q.cn/3m43yQ6X
http://arxiv.org/abs/2410.19573v1
https://github.com/genuszty/FastPCI

香港中文大學、香港科技大學和中國電子科技大學的研究團隊提出了一種名為Bifr?st的3D感知圖像合成框架。這個框架利用擴散模型處理語言指令並集成深度圖,以增強空間理解,實現尊重複雜空間關係的高保真圖像合成。
https://j1q.cn/C022Zw48
http://arxiv.org/abs/2410.19079v1
https://github.com/lingxiao-li/Bifrost

厦门大学、清华大学、华东师范大学的研究团队提出了一种名为融合–蒸馏(FtD++)的新方法,用于领域自适应3D语义分割中的跨模态正蒸馏。核心思想是利用跨模态融合表示的互补性,通过模型不可知的特征融合模块、跨模态正蒸馏和跨模态去偏伪标签来弥合跨模态和跨领域差距。
https://j1q.cn/w84ra9IO
http://arxiv.org/abs/2410.19446v1
https://github.com/Barcaaaa/FtD-PlusPlus
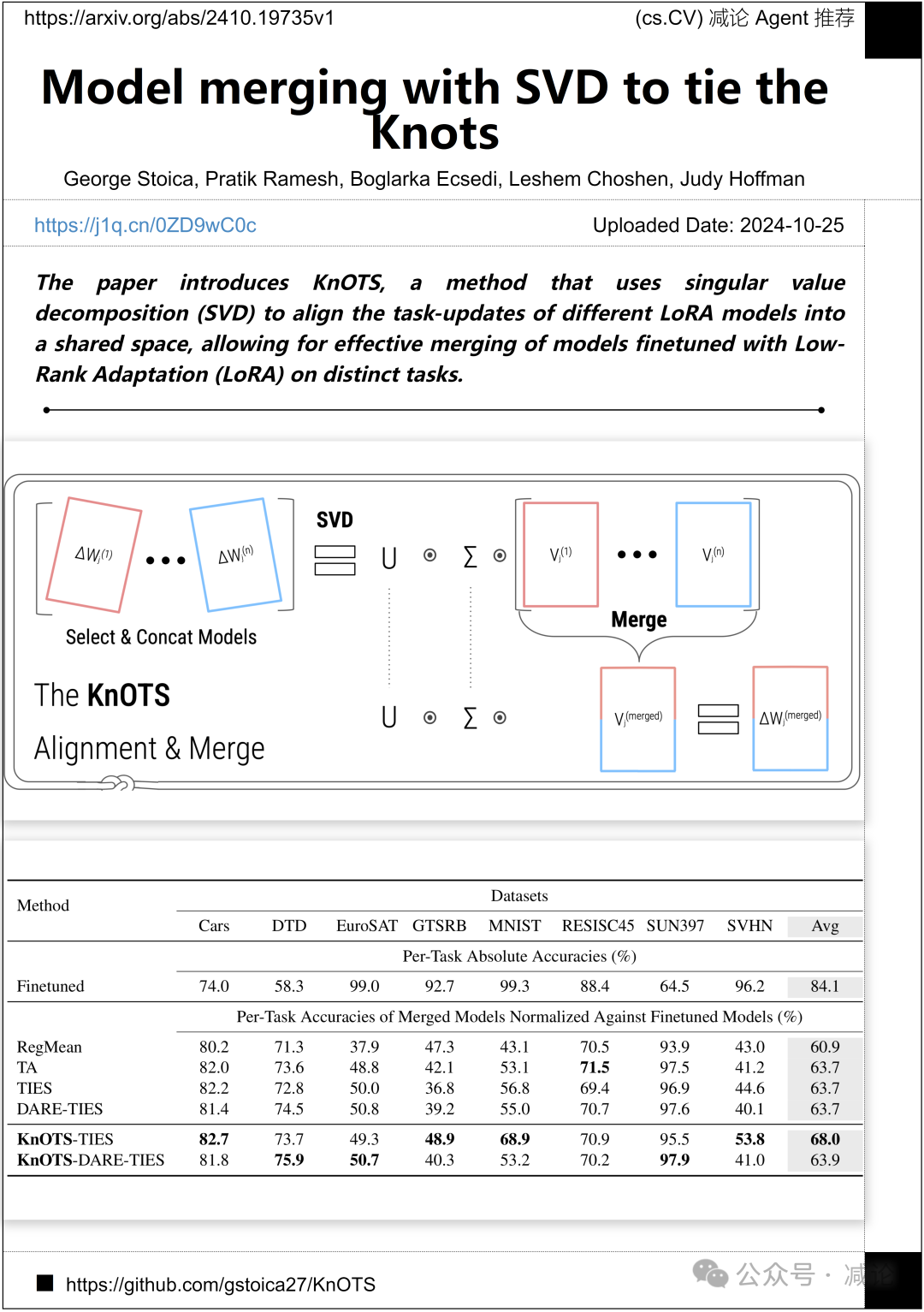
佐治亚理工学院、IBM研究和麻省理工学院的研究团队提出了一种名为KnOTS的方法。该方法利用奇异值分解(SVD)将不同LoRA模型的任务更新对齐到共享空间,实现了对在不同任务上进行低秩适应(LoRA)微调的模型进行有效合并。
https://j1q.cn/0ZD9wC0c
http://arxiv.org/abs/2410.19735v1
https://github.com/gstoica27/KnOTS

南洋理工大学和南开大学的研究团队提出了一种用于动画制作中油漆桶着色的包含匹配流程。该流程使得网络能够理解分段之间的包含关系,以实现跨帧准确着色,而不是依赖直接的视觉对应关系。
https://j1q.cn/xDIX6nRb
http://arxiv.org/abs/2410.19424v1
https://github.com/ykdai/BasicPBC

清华大学深圳研究生院的研究团队介绍了MonoDGP,一种基于Transformer的单目3D物体检测方法,该方法利用透视不变几何误差修改投影公式,并将深度引导解码器解耦以构建仅依赖视觉特征的2D解码器。
https://j1q.cn/Lrnx2xLI
http://arxiv.org/abs/2410.19590v1
https://github.com/PuFanqi23/MonoDGP

香港大学、南洋理工大学、上海人工智能实验室的研究团队提出了FasterCache,一种无需训练的策略,通过动态重复使用特征并优化条件和无条件输出的重复使用,加速基于扩散的视频生成,以提高推理速度而不影响视频质量。
https://j1q.cn/KG1Mq004
http://arxiv.org/abs/2410.19355v1
https://github.com/Vchitect/FasterCache

中国科学技术大学和南洋理工大学的研究团队提出了一个名为Frolic的无标签提示分布学习和偏差校正框架,以增强零-shot视觉模型。Frolic学习提示原型的分布,以捕获多样的视觉表示,通过置信度匹配将这些与原始的CLIP模型自适应地融合,并通过无标签logit调整校正标签偏差,而无需标记数据或超参数调整。
https://j1q.cn/cI2UIamE
http://arxiv.org/abs/2410.19294v1
https://github.com/zhuhsingyuu/Frolic
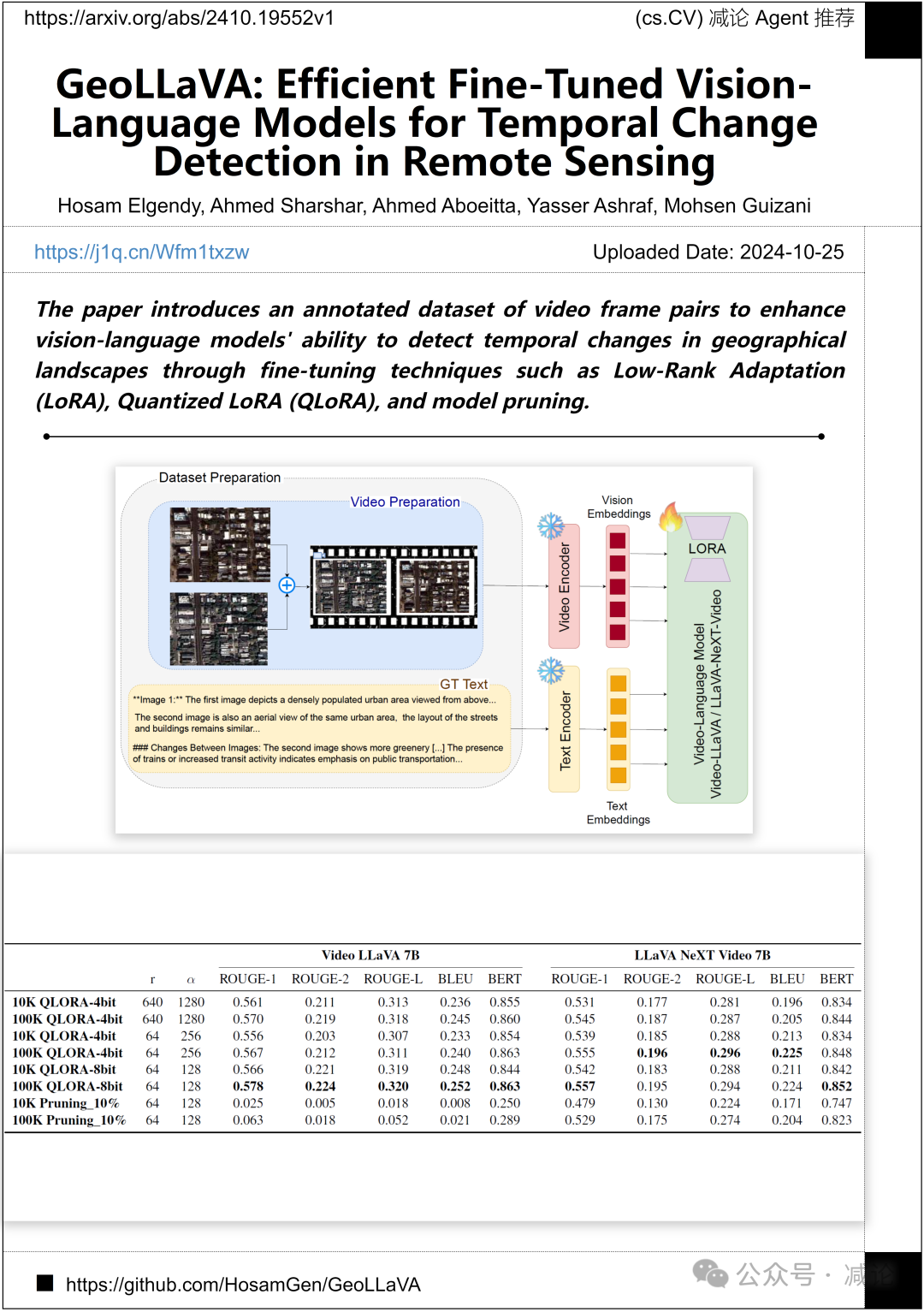
穆罕默德·本·扎耶德人工智能大学的研究团队提出了一个带注释的视频帧对数据集,通过微调技术(如低秩适应(LoRA)、量化低秩适应(QLoRA)和模型修剪)来增强视觉语言模型在检测地理景观中的时间变化能力的论文。
https://j1q.cn/Wfm1txzw
http://arxiv.org/abs/2410.19552v1
https://github.com/HosamGen/GeoLLaVA

中山大学和阿里巴巴集团的研究团队提出了Frozen-DETR方法,该方法将冻结的基础模型集成到基于DETR的目标检测器中。通过利用基础模型中的类令牌和补丁令牌来解码目标查询和在编码器中进行特征融合,从而提高性能。
https://j1q.cn/fHXGU7V1
http://arxiv.org/abs/2410.19635v1
https://github.com/iSEE-Laboratory/Frozen-DETR
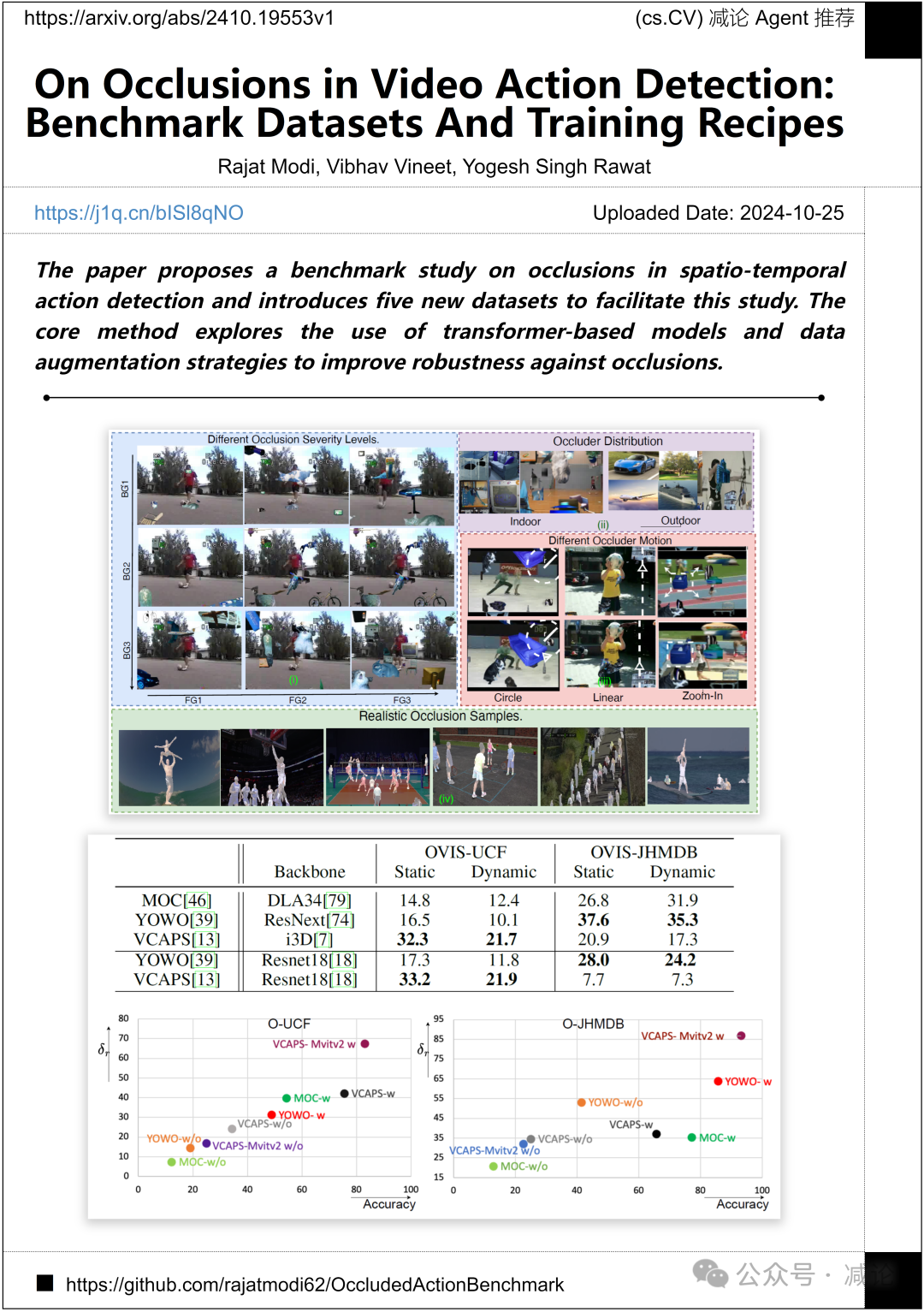
中佛罗里达大学, 微软研究团队提出了关于时空动作检测中遮挡的基准研究,并引入了五个新数据集来促进这项研究。他们的核心方法探索了使用基于transformer的模型和数据增强策略来提高对遮挡的鲁棒性。
https://j1q.cn/bISl8qNO
http://arxiv.org/abs/2410.19553v1
https://github.com/rajatmodi62/OccludedActionBenchmark
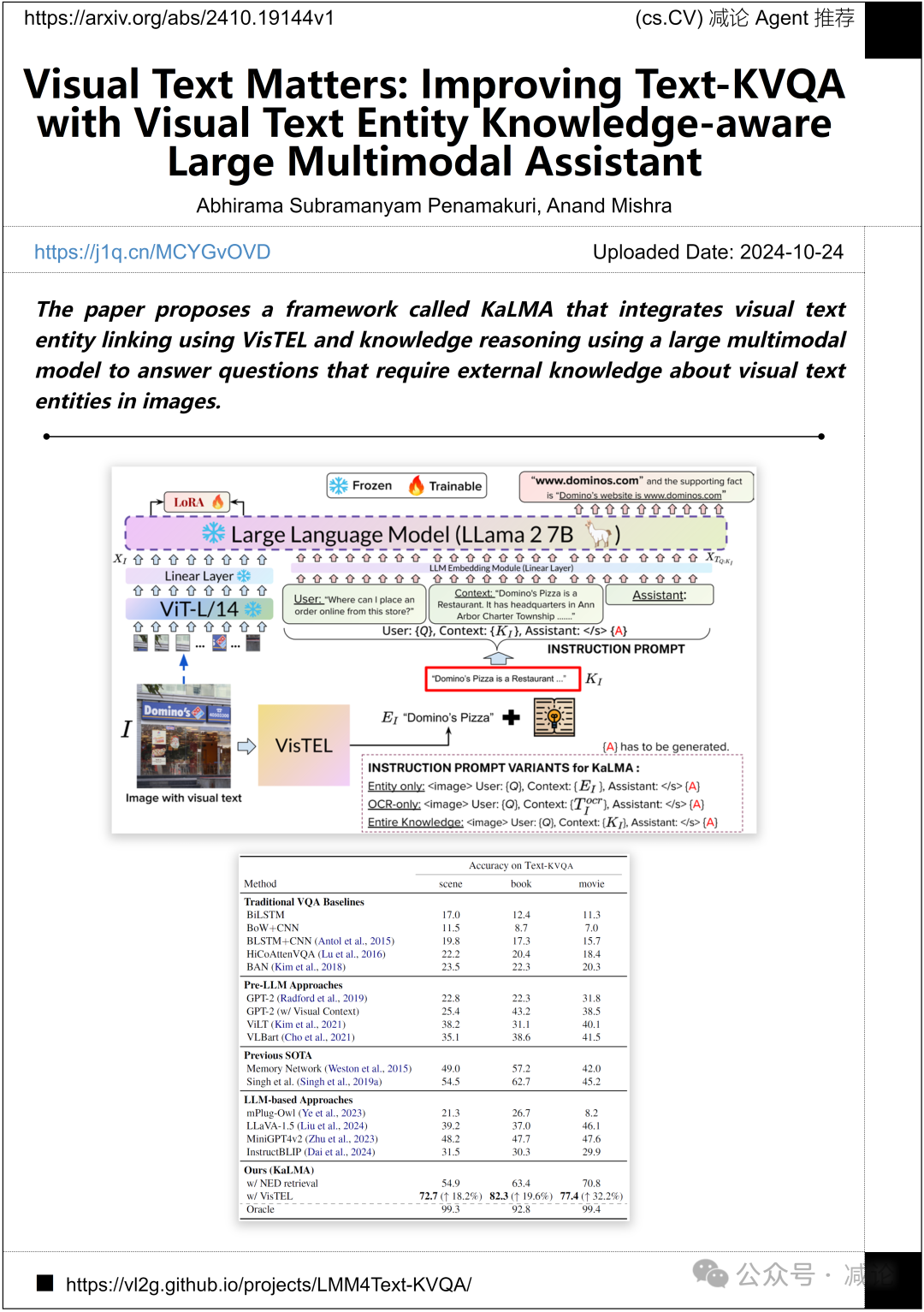
印度理工学院焦特布尔的研究团队提出了一个名为KaLMA的框架,该框架集成了使用VisTEL进行视觉文本实体链接和使用大型多模型进行知识推理,以回答关于图像中视觉文本实体的外部知识问题。
https://j1q.cn/MCYGvOVD
http://arxiv.org/abs/2410.19144v1
https://vl2g.github.io/projects/LMM4Text-KVQA/
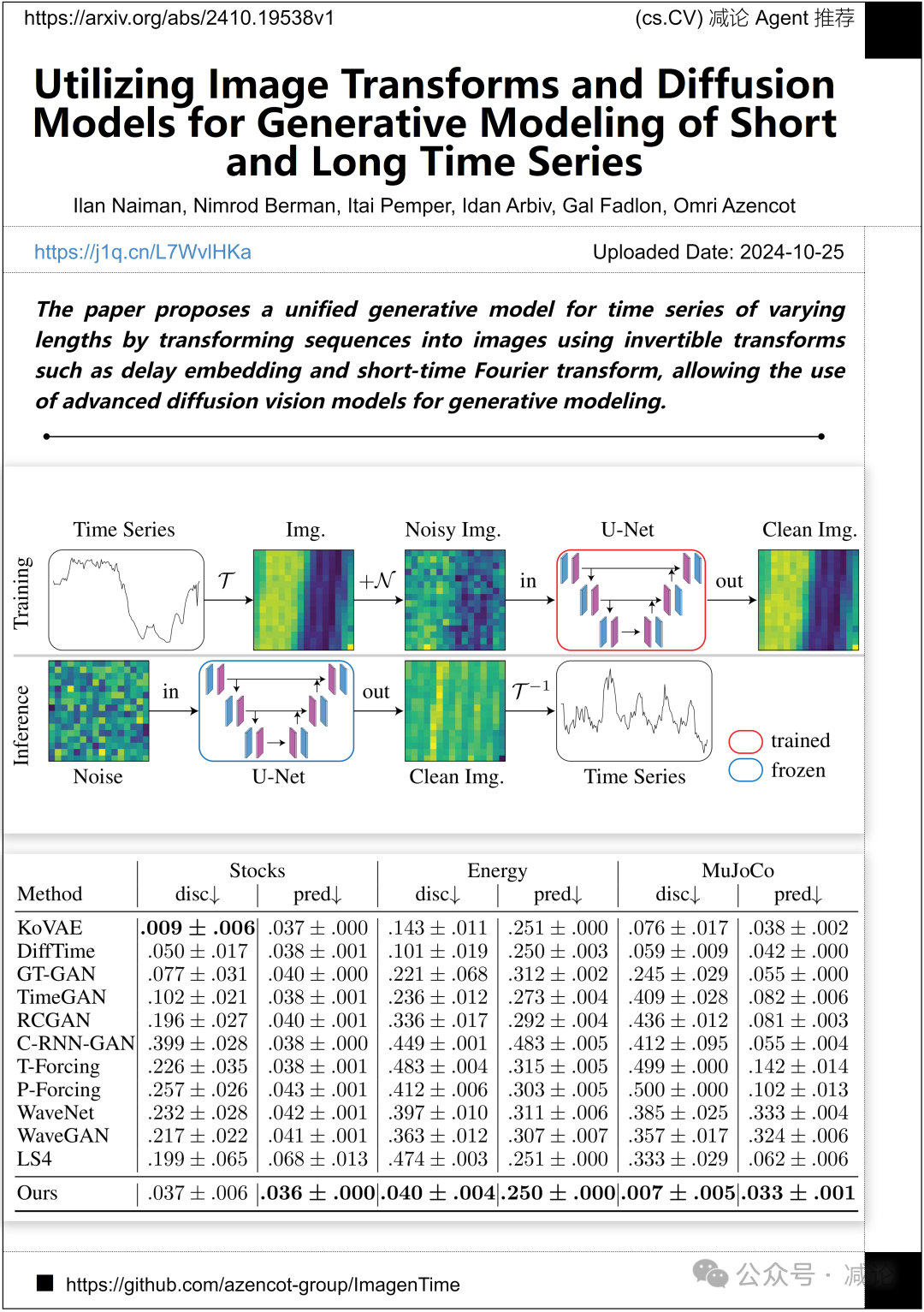
内盖夫大学的研究团队提出了一种统一的生成模型,通过将序列转换为图像,使用可逆变换(如延迟嵌入和短时傅里叶变换)来处理不同长度的时间序列,从而可以利用先进的扩散视觉模型进行生成建模。
https://j1q.cn/L7WvlHKa
http://arxiv.org/abs/2410.19538v1
https://github.com/azencot-group/ImagenTime

卡内基梅隆大学、微软、纽约大学的研究团队介绍了VideoWebArena(VideoWA),这是一个用于评估长上下文多模态智能体在视频理解方面能力的基准,重点关注技能保留和事实保留任务。
https://j1q.cn/9j6LHkYw
http://arxiv.org/abs/2410.19100v1
https://github.com/ljang0/videowebarena