
2024年12月6日arXiv cs.CV发文量约148余篇,减论Agent通过算法为您推荐并自动化整理为卡片供您参考,预计为您节省60分钟浏览arXiv的时间。
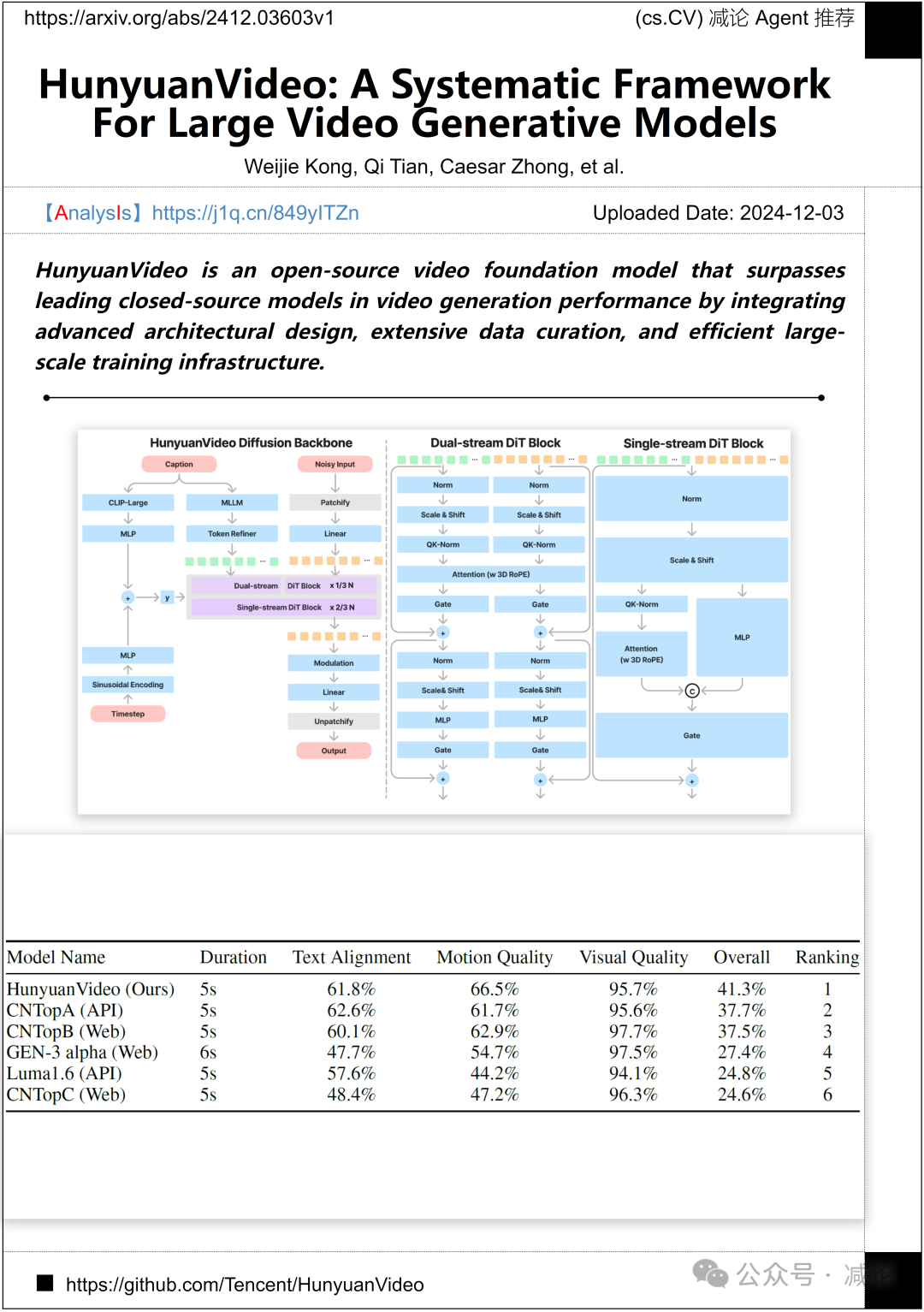

腾讯推出的HunyuanVideo方法是一个开源的视频基础模型。该模型结合了先进的架构设计、广泛的数据筛选和高效的大规模训练基础设施,实现了在视频生成性能上超越领先的闭源模型。
【Bohr精读】
https://j1q.cn/849yITZn
【arXiv链接】
http://arxiv.org/abs/2412.03603v1
【代码地址】
https://github.com/Tencent/HunyuanVideo

新加坡国立大学、北京大学与Skywork AI联合推出了HumanEdit方法。HumanEdit是一个包含5,751张图像的数据集,专用于指导图片编辑。该方法通过大量人类反馈,提高了与人类偏好的对齐度,并支持通过详细的开放式语言指令进行多样化的编辑任务。
【Bohr精读】
https://j1q.cn/b30oN1s8
【arXiv链接】
http://arxiv.org/abs/2412.04280v1
【代码地址】
https://huggingface.co/datasets/BryanW/HumanEdit
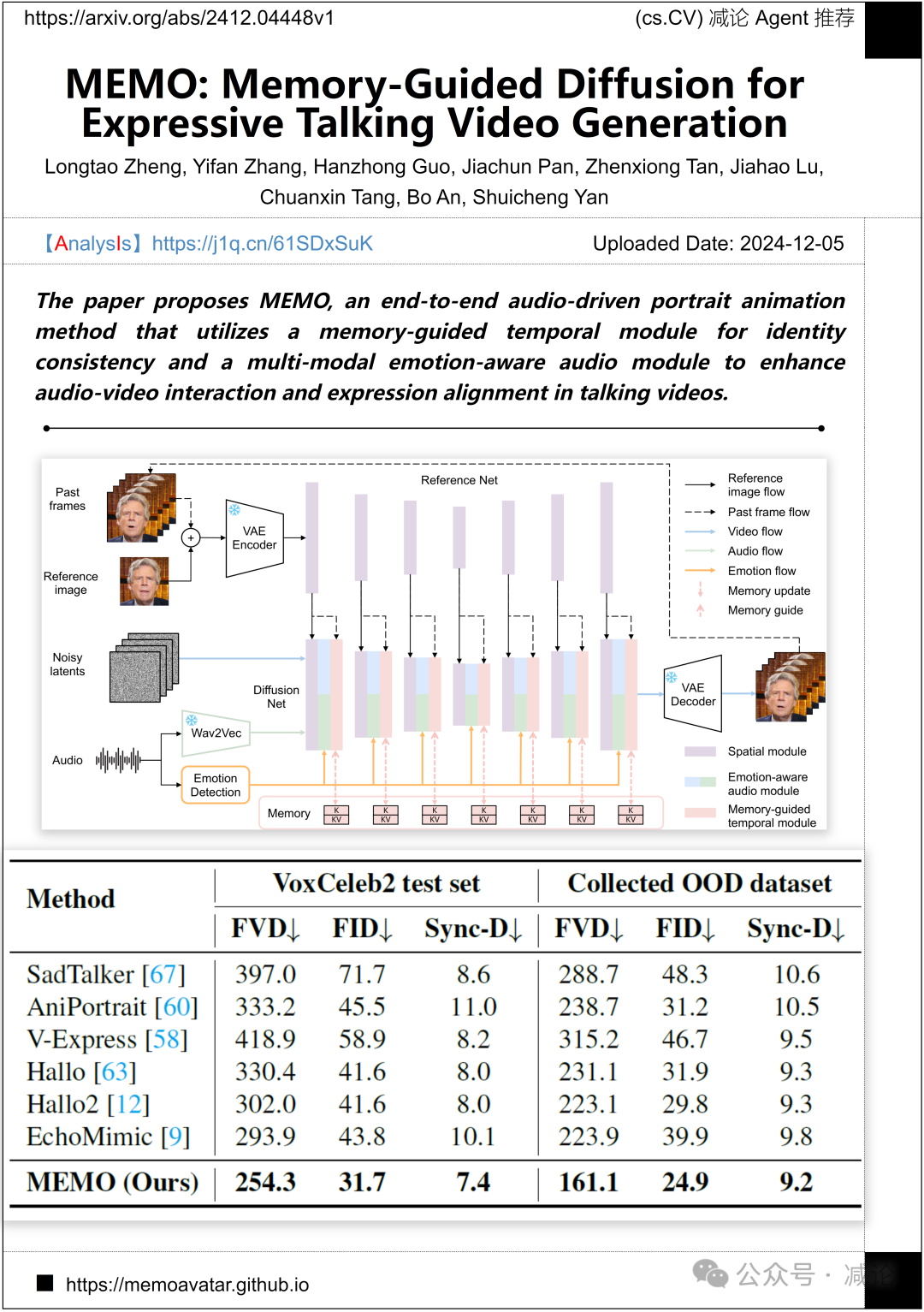
南洋理工大学、Skywork AI和新加坡国立大学提出了一种端到端的音频驱动肖像动画方法——MEMO。该方法通过记忆引导的时间模块确保身份一致性,并利用多模态情感感知音频模块增强对话视频中的音视频交互和表达对齐。
【Bohr精读】
https://j1q.cn/61SDxSuK
【arXiv链接】
http://arxiv.org/abs/2412.04448v1
【代码地址】
https://memoavatar.github.io
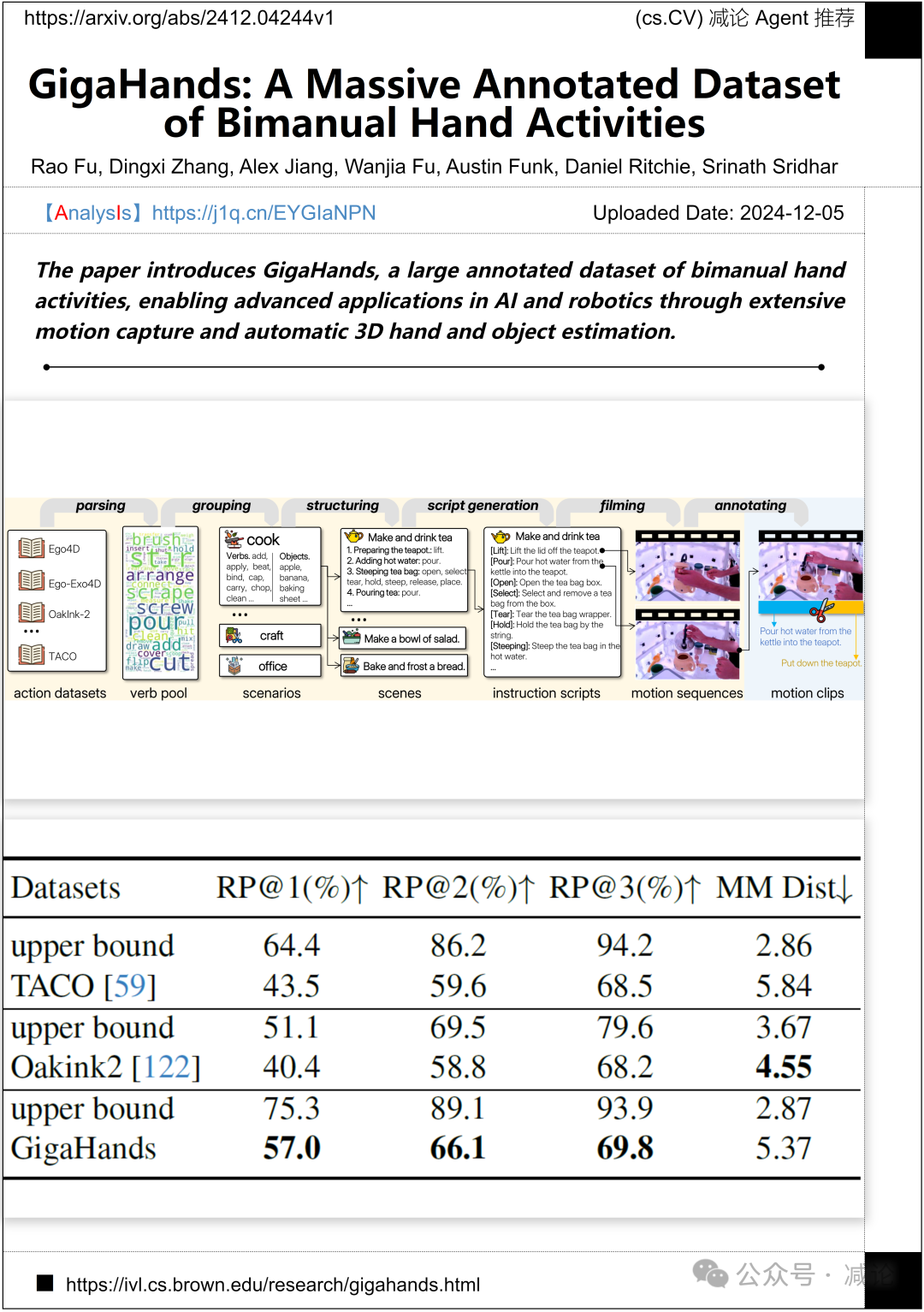
布朗大学与苏黎世联邦理工学院推出了GigaHands,一个大规模注释的双手活动数据集。该数据集通过广泛的动作捕捉和自动3D手部及物体估计,推动了人工智能和机器人技术的应用。
【Bohr精读】
https://j1q.cn/EYGIaNPN
【arXiv链接】
http://arxiv.org/abs/2412.04244v1
【代码地址】
https://ivl.cs.brown.edu/research/gigahands.html
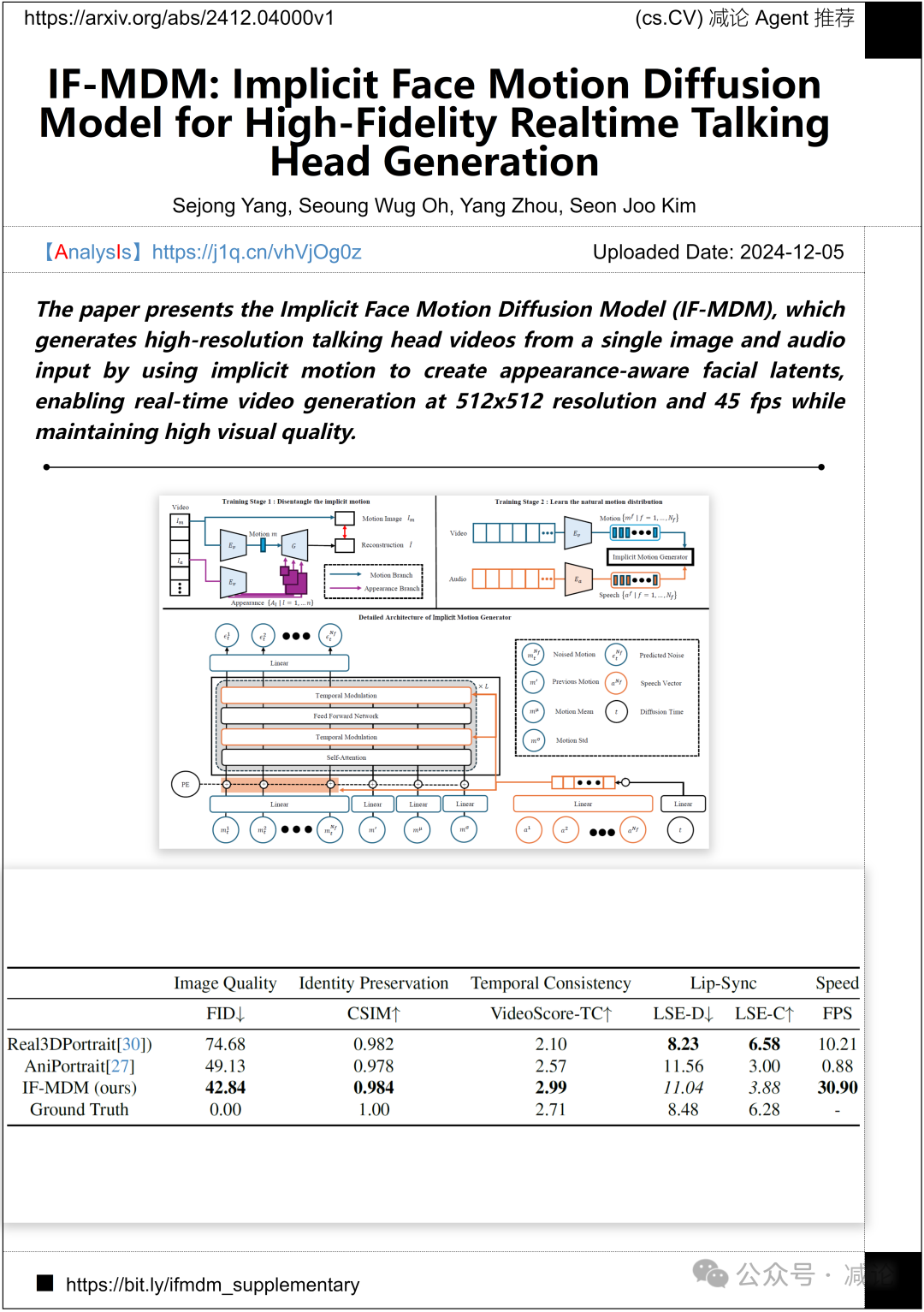
延世大学与Adobe研究联合提出了隐式人脸运动扩散模型(IF-MDM)。该模型利用隐式运动生成注意外观的面部潜在变量,从单张图像和音频输入生成高清晰度的说话人脸视频。实现了512×512分辨率和45 fps的实时视频生成,并保持高视觉质量。
【Bohr精读】
https://j1q.cn/vhVjOg0z
【arXiv链接】
http://arxiv.org/abs/2412.04000v1
【代码地址】
https://bit.ly/ifmdm_supplementary

卡内基梅隆大学、麻省理工学院与Adobe研究联合提出了Turbo3D方法。这是一种超高速文本到3D系统,能在不到一秒内通过4步、4视图扩散生成器和高效的前馈高斯重建器,在潜在空间中生成高质量的高斯喷溅资源。
【Bohr精读】
https://j1q.cn/dJrIq76I
【arXiv链接】
http://arxiv.org/abs/2412.04470v1
【代码地址】
https://turbo-3d.github.io/

特伦托大学与布鲁诺·凯斯勒基金会提出的COPS模型,通过从多个视角渲染点云并提取二维特征,结合视觉语义和三维几何,显著提升了部件分割效果。该模型还采用几何感知的特征聚合,确保物体部件的有效聚类和标记。
【Bohr精读】
https://j1q.cn/Q86uWzod
【arXiv链接】
http://arxiv.org/abs/2412.04247v1
【代码地址】
https://3d-cops.github.io

利物浦大学、南洋理工大学和香港中文大学(深圳)联合推出了社交媒体图像检测数据集(SID-Set)和SIDA框架。该研究利用大型多样化的数据集和先进的多模态模型,实现了对社交媒体上深度伪造图像的有效检测、定位和解释。
【Bohr精读】
https://j1q.cn/olzFFx7Y
【arXiv链接】
http://arxiv.org/abs/2412.04292v1
【代码地址】
https://hzlsaber.github.io/projects/SIDA/

香港大学与腾讯PCG联合推出了EgoPlan-Bench2,这是评估多模态大型语言模型在真实场景中规划能力的综合基准。同时,研究提出了一种无需训练的多模态思维链提示方法,以提升GPT-4V在规划任务中的表现。
【Bohr精读】
https://j1q.cn/LsKoIdAK
【arXiv链接】
http://arxiv.org/abs/2412.04447v1
【代码地址】
https://qiulu66.github.io/egoplanbench2/

清华大学提出了一种基于高斯的EmbodiedOcc框架,用于具身3D占用预测。该框架通过均匀的3D语义高斯初始化全局场景,并利用可变形的交叉注意力逐步更新局部区域,从而帮助具身代理在探索过程中细化对环境的理解。
【Bohr精读】
https://j1q.cn/Nqdk9fah
【arXiv链接】
http://arxiv.org/abs/2412.04380v1
【代码地址】
https://github.com/YkiWu/EmbodiedOcc
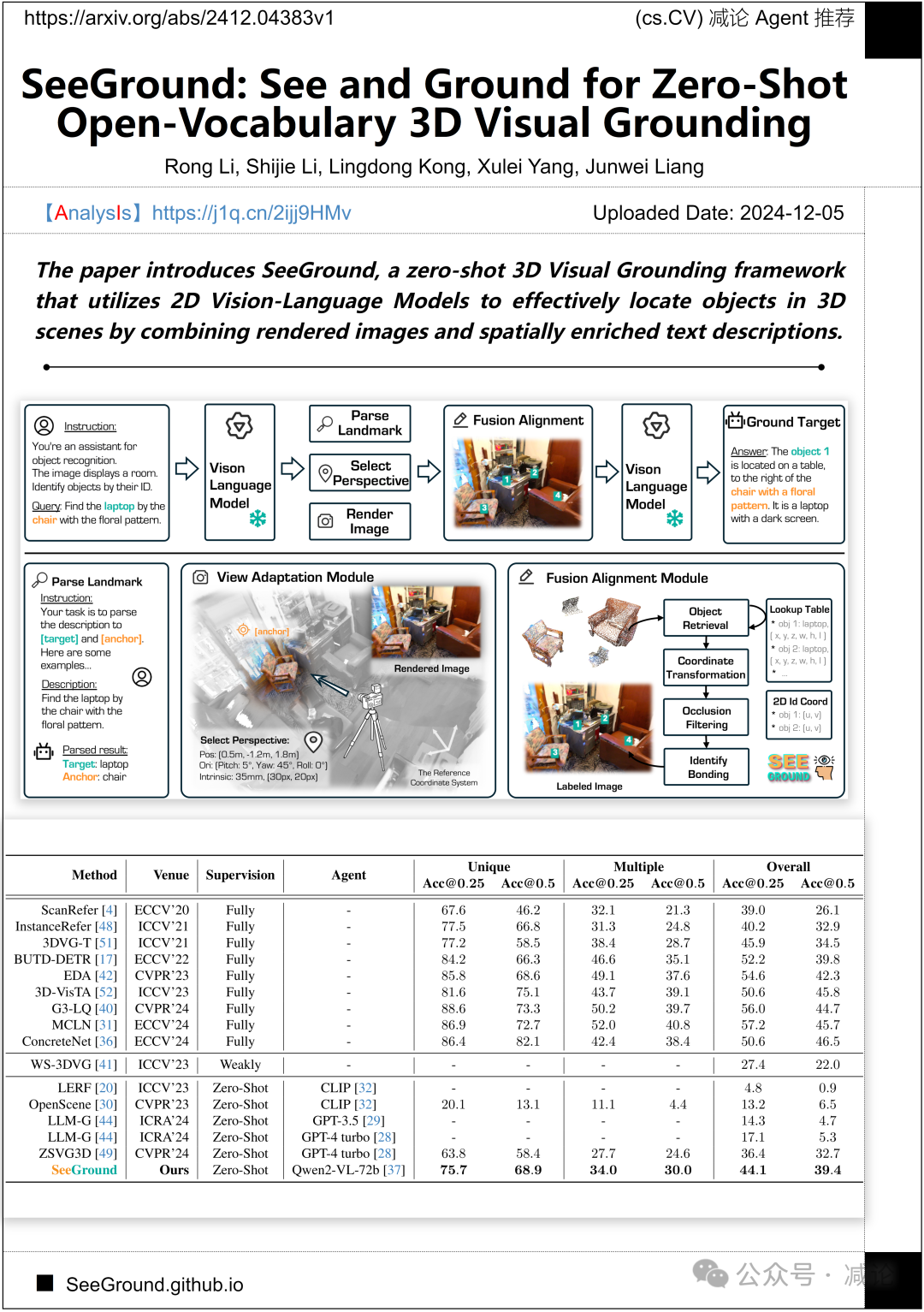
香港科技大学信息与通信研究院与新加坡科技研究局合作推出了SeeGround方法,这是一个零样本3D视觉定位框架。该框架通过结合渲染图像和空间丰富的文本描述,利用2D视觉语言模型有效定位3D场景中的物体。
【Bohr精读】
https://j1q.cn/2ijj9HMv
【arXiv链接】
http://arxiv.org/abs/2412.04383v1
【代码地址】
SeeGround.github.io

香港大学、清华大学与微软研究院联合提出了GenMAC方法,采用迭代多智能体框架实现组合文本到视频生成。该方法将复杂任务分解为简单任务,由专门代理处理,通过设计、生成和再设计阶段的协作工作流程逐步优化视频输出。
【Bohr精读】
https://j1q.cn/CFwhk7Ex
【arXiv链接】
http://arxiv.org/abs/2412.04440v1
【代码地址】
https://karine-h.github.io/GenMAC/

马里兰大学与微软研究院推出的Florence-VL方法是一种多模态大型语言模型,采用深度–广度融合架构整合Florence-2模型的视觉表示,显著增强了视觉–语言对齐能力。该方法在多个基准测试中表现出显著提升。
【Bohr精读】
https://j1q.cn/pcAtNL1u
【arXiv链接】
http://arxiv.org/abs/2412.04424v1
【代码地址】
https://github.com/JiuhaiChen/Florence-VL

字节跳动与清华大学联合提出的AnyDressing方法利用GarmentsNet和DressingNet两个网络提取服装特征,基于任意服装组合和个性化文本提示生成定制图像。该方法增强纹理细节,保持文本与图像的一致性,实现多服装虚拟试穿。
【Bohr精读】
https://j1q.cn/HDjvTBv0
【arXiv链接】
http://arxiv.org/abs/2412.04146v1
【代码地址】
https://crayon-shinchan.github.io/AnyDressing/
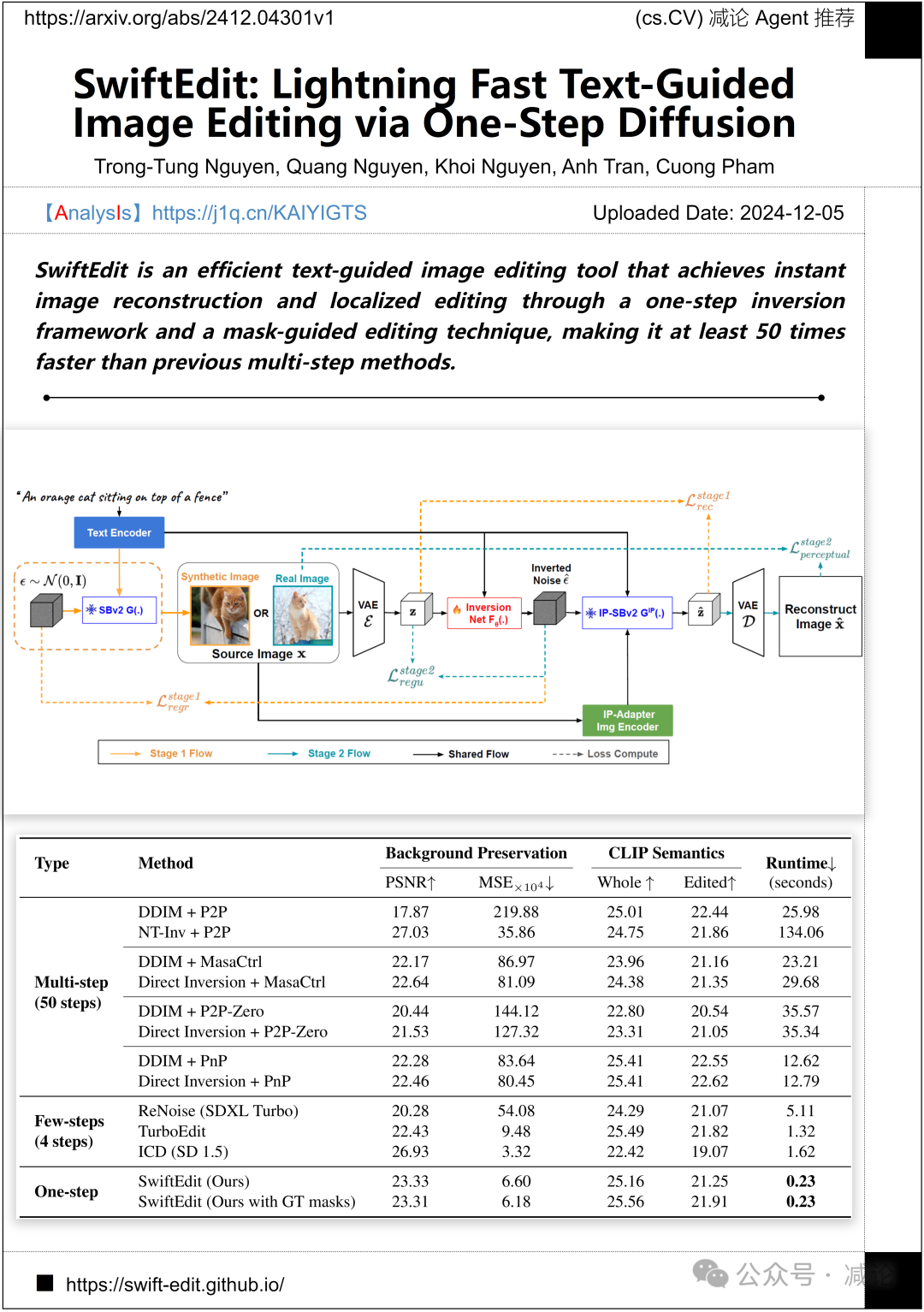
VinAI研究与邮电科技学院提出了SwiftEdit方法,这是一款高效的文本引导图像编辑工具。该方法采用一步反演框架和掩码引导编辑技术,实现即时图像重建和局部编辑,速度比传统多步骤方法快至少50倍。
【Bohr精读】
https://j1q.cn/KAIYIGTS
【arXiv链接】
http://arxiv.org/abs/2412.04301v1
【代码地址】
https://swift-edit.github.io/

英伟达、加州大学圣地亚哥分校和清华大学联合提出了NVILA方法,这是一系列开放视觉语言模型。该方法采用“先扩展后压缩”策略,提高了模型的效率和准确性,优化了模型架构,以适应高分辨率图像和长视频,并显著降低了训练和部署成本。
【Bohr精读】
https://j1q.cn/mINKFhmk
【arXiv链接】
http://arxiv.org/abs/2412.04468v1
【代码地址】
https://github.com/NVlabs/VILA
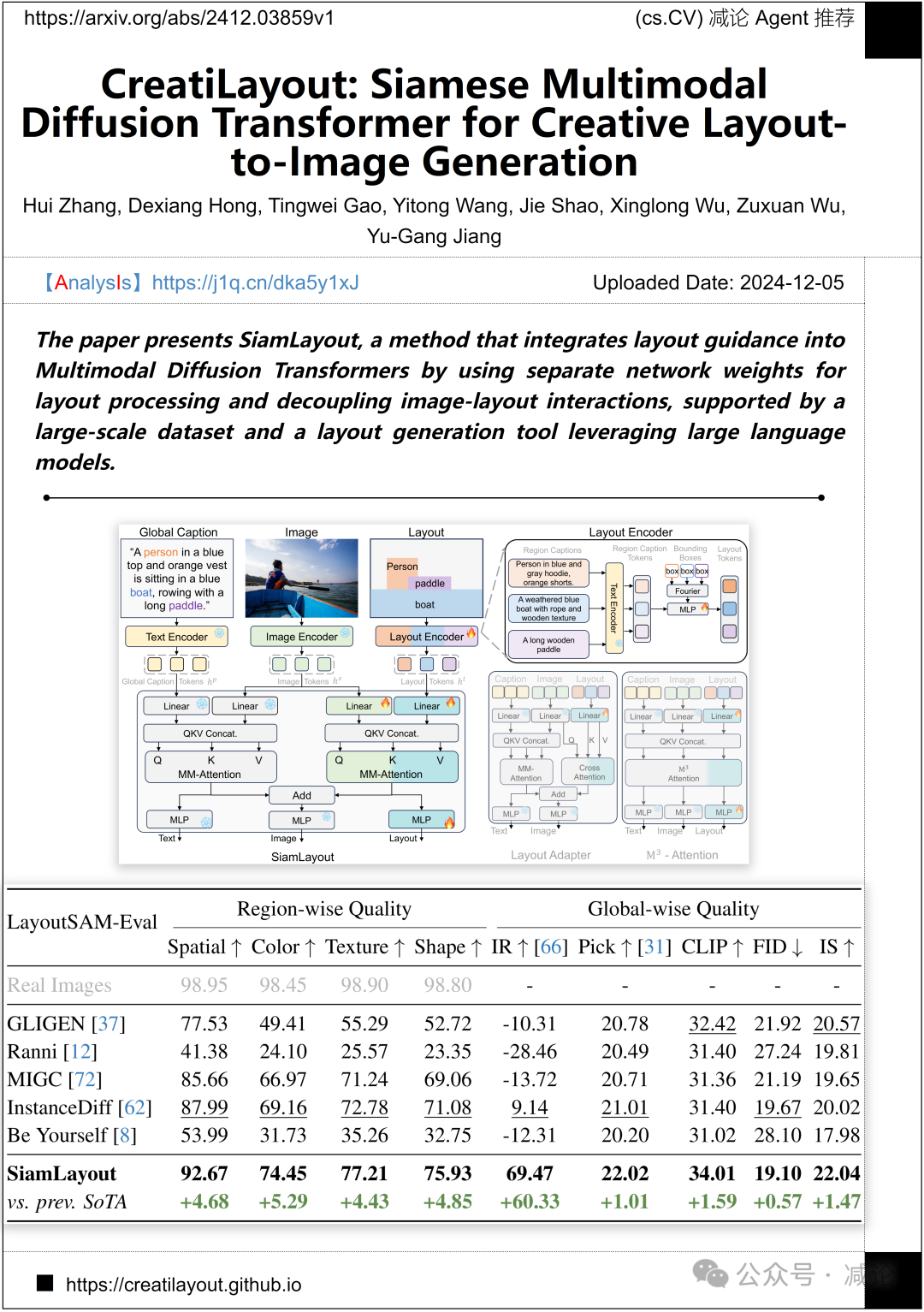
复旦大学与字节跳动有限公司联合提出了SiamLayout方法。该方法通过独立的网络权重处理布局,解耦图像与布局之间的交互,将布局指导集成到多模态扩散Transformer中。该方法基于一个大规模数据集,并使用大型语言模型进行布局生成。
【Bohr精读】
https://j1q.cn/dka5y1xJ
【arXiv链接】
http://arxiv.org/abs/2412.03859v1
【代码地址】
https://creatilayout.github.io
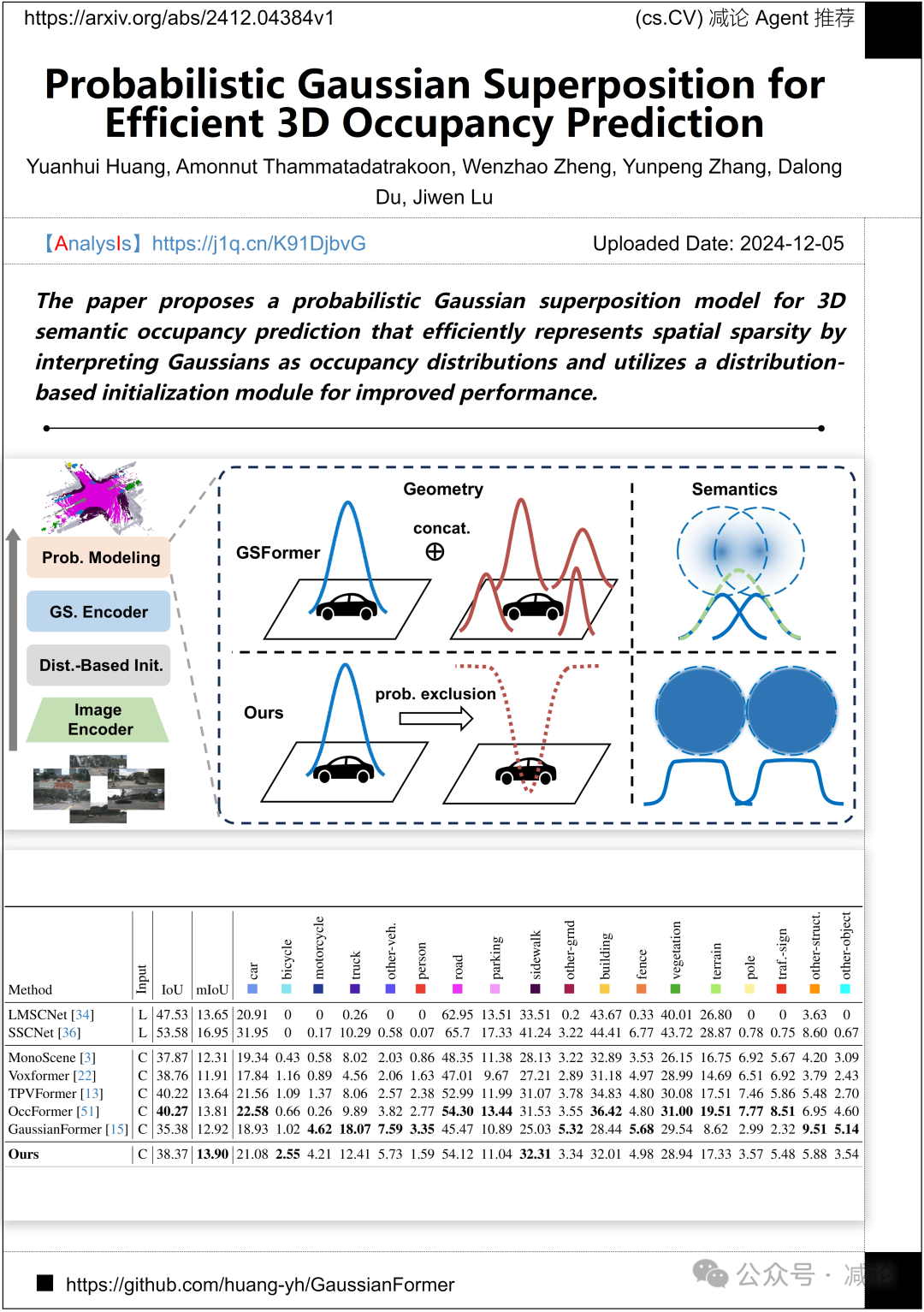
清华大学与PhiGent Robotics提出了一种概率高斯叠加模型用于3D语义占据预测。该模型将高斯视为占据分布,有效表示空间稀疏性,并采用基于分布的初始化模块以提升性能。
【Bohr精读】
https://j1q.cn/K91DjbvG
【arXiv链接】
http://arxiv.org/abs/2412.04384v1
【代码地址】
https://github.com/huang-yh/GaussianFormer

博洛尼亚大学提出的Stereo Anywhere方法是一种立体匹配框架,采用双分支架构和新颖的代价体融合机制,将几何约束与单目深度线索结合,有效应对无纹理区域和遮挡等挑战,实现了先进的零样本泛化性能。
【Bohr精读】
https://j1q.cn/dsQ7duXj
【arXiv链接】
http://arxiv.org/abs/2412.04472v1
【代码地址】
https://stereoanywhere.github.io/
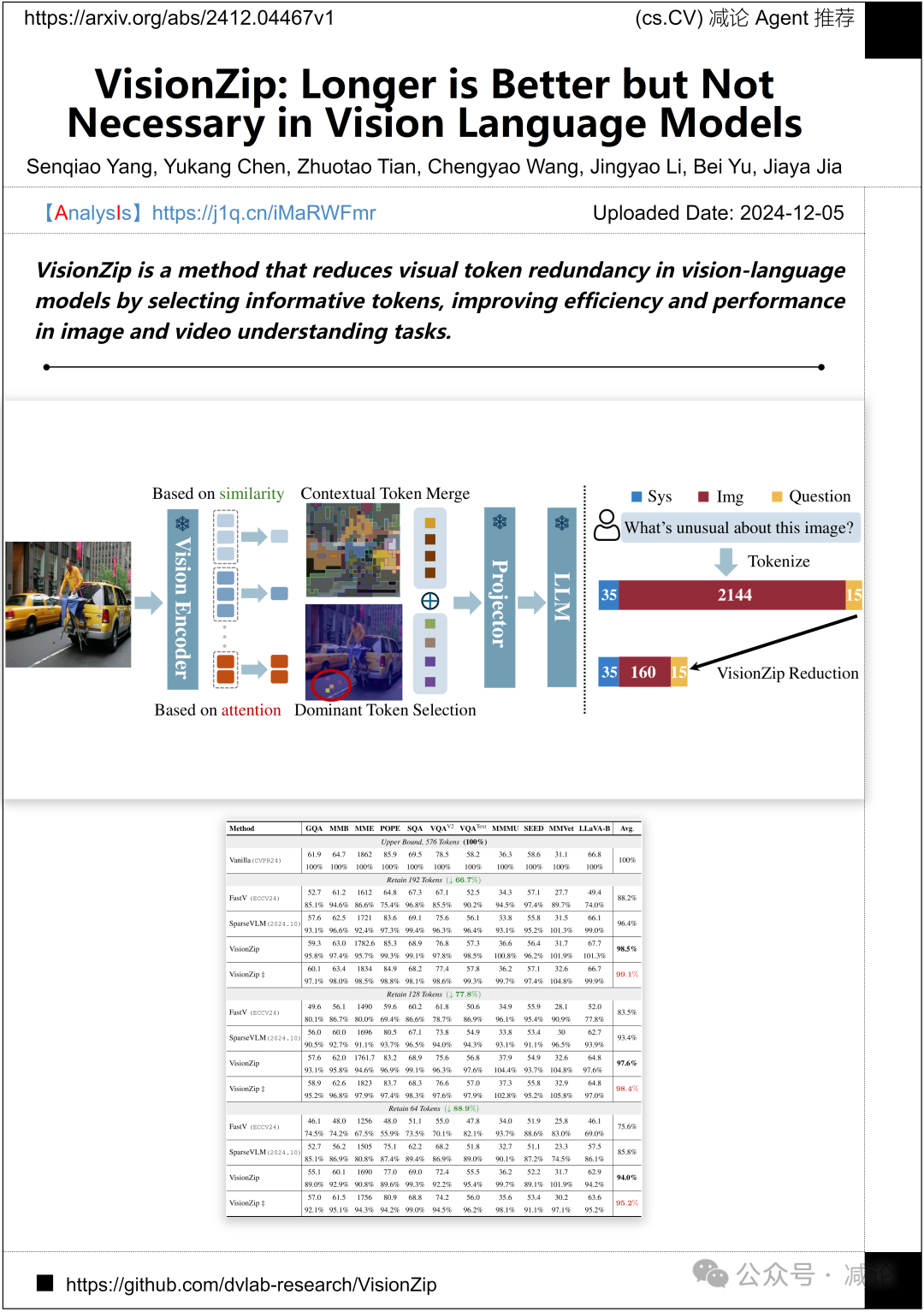
香港中文大学、哈尔滨工业大学和香港科技大学提出了VisionZip方法,通过选择信息丰富的token,减少视觉–语言模型中的冗余视觉token,提高图像和视频理解任务的效率与性能。
【Bohr精读】
https://j1q.cn/iMaRWFmr
【arXiv链接】
http://arxiv.org/abs/2412.04467v1
【代码地址】
https://github.com/dvlab-research/VisionZip

字节跳动提出了INFP,一种音频驱动的头部生成框架。该框架通过二元音频输入交替动画化代理的头部,采用运动模仿和音频引导运动生成的两阶段过程,实现动态互动对话。
【Bohr精读】
https://j1q.cn/plrcgbAc
【arXiv链接】
http://arxiv.org/abs/2412.04037v1
【代码地址】
https://grisoon.github.io/INFP/

伊利诺伊大学厄本那–香槟分校提出的UnZipLoRA方法,通过两个兼容的LoRA,将图像分解为独特的主题和风格组件,实现对单个图像中这些元素的独立操控和重新设定。
【Bohr精读】
https://j1q.cn/eoL5jyWp
【arXiv链接】
http://arxiv.org/abs/2412.04465v1
【代码地址】
https://unziplora.github.io
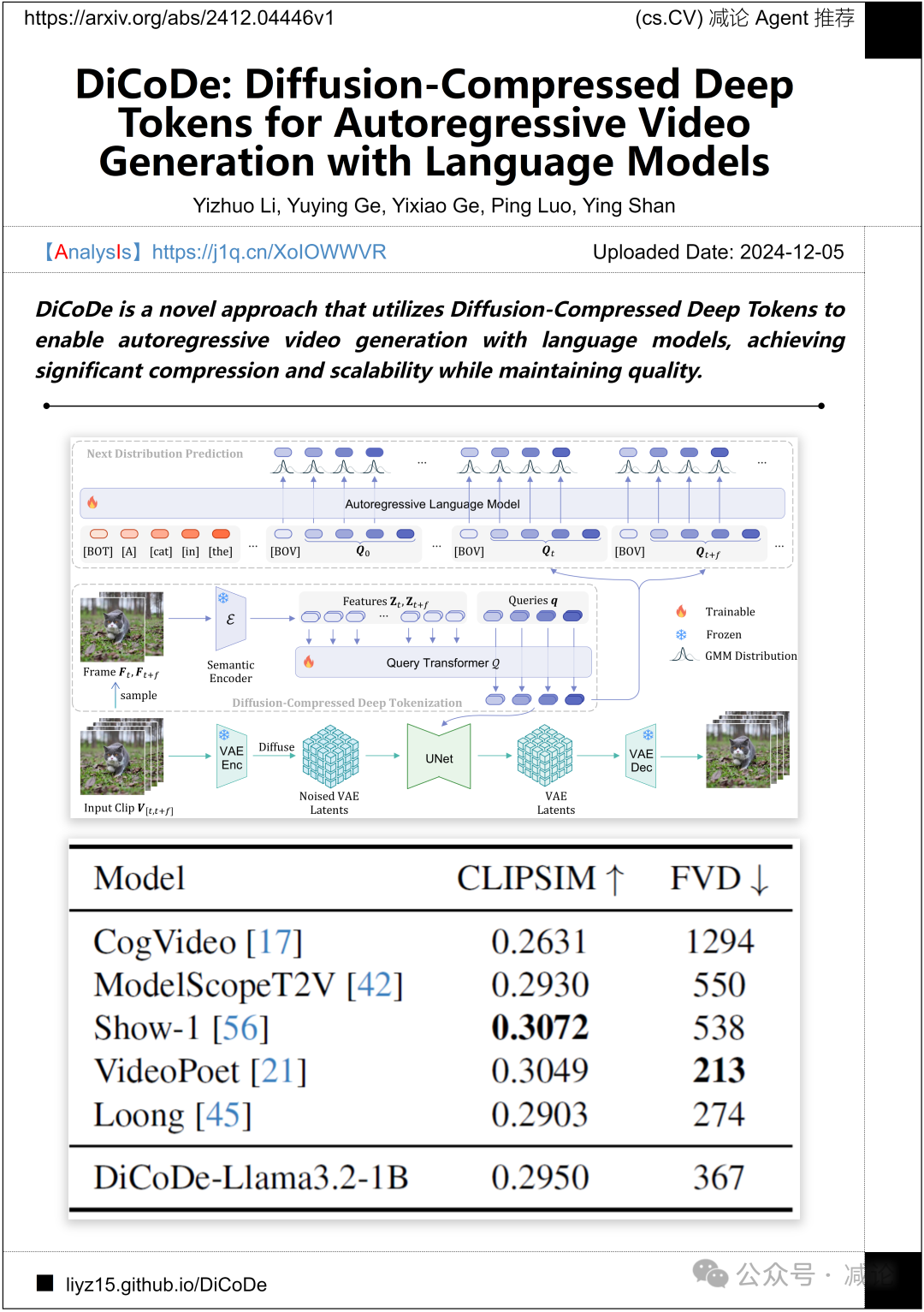
香港大学与腾讯推出的DiCoDe方法利用扩散压缩深度token,通过语言模型实现自回归视频生成。该方法显著提高了压缩率和可扩展性,同时保持了视频质量,为视频生成领域带来了突破。
【Bohr精读】
https://j1q.cn/XoIOWWVR
【arXiv链接】
http://arxiv.org/abs/2412.04446v1
【代码地址】
liyz15.github.io/DiCoDe
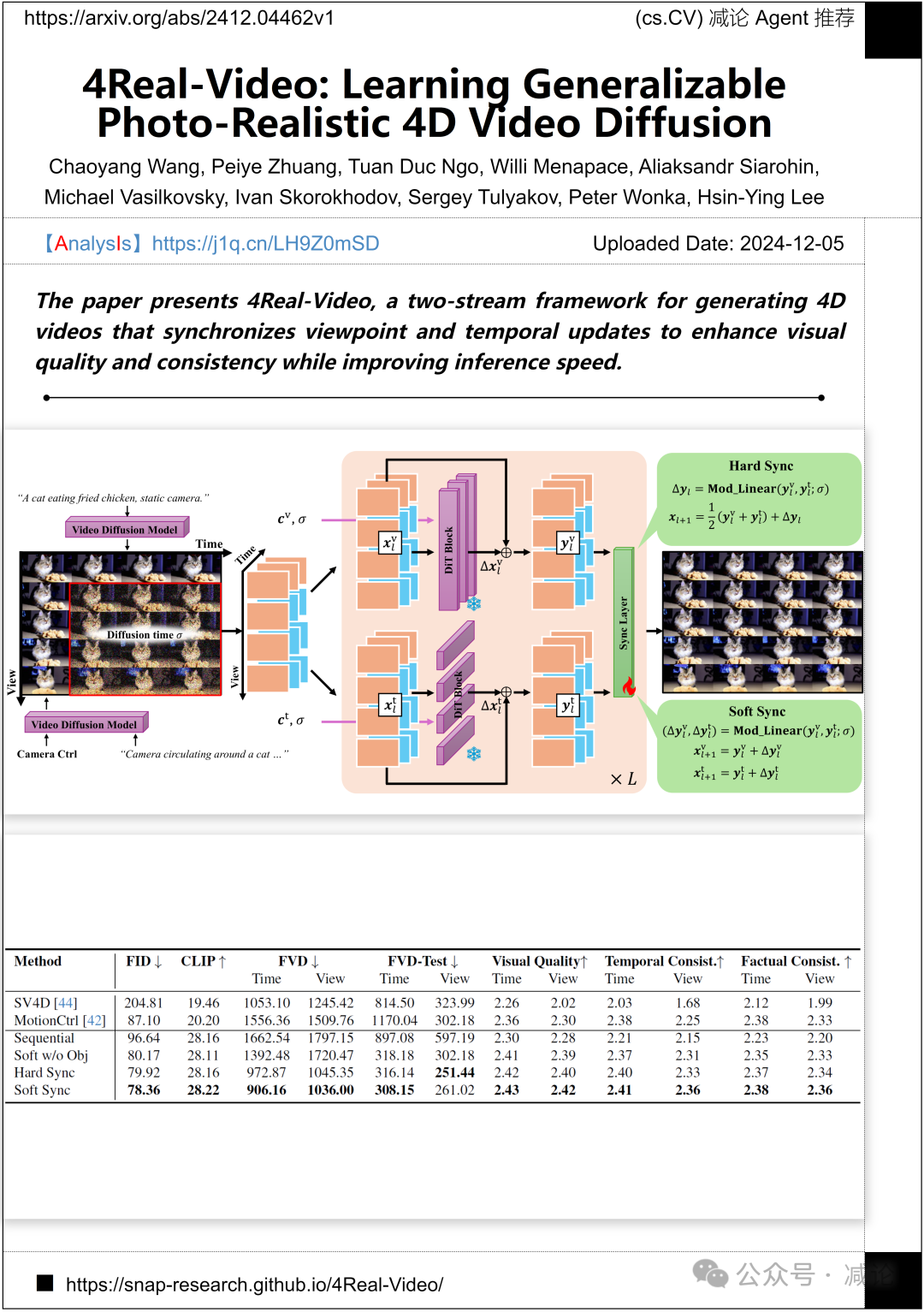
Snap Inc和国王阿卜杜拉科技大学提出了4Real-Video方法,这是一种双流框架,用于生成4D视频。该方法通过同步视角和时间更新,提高了视觉质量和一致性,并提升了推理速度。
【Bohr精读】
https://j1q.cn/LH9Z0mSD
【arXiv链接】
http://arxiv.org/abs/2412.04462v1
【代码地址】
https://snap-research.github.io/4Real-Video/
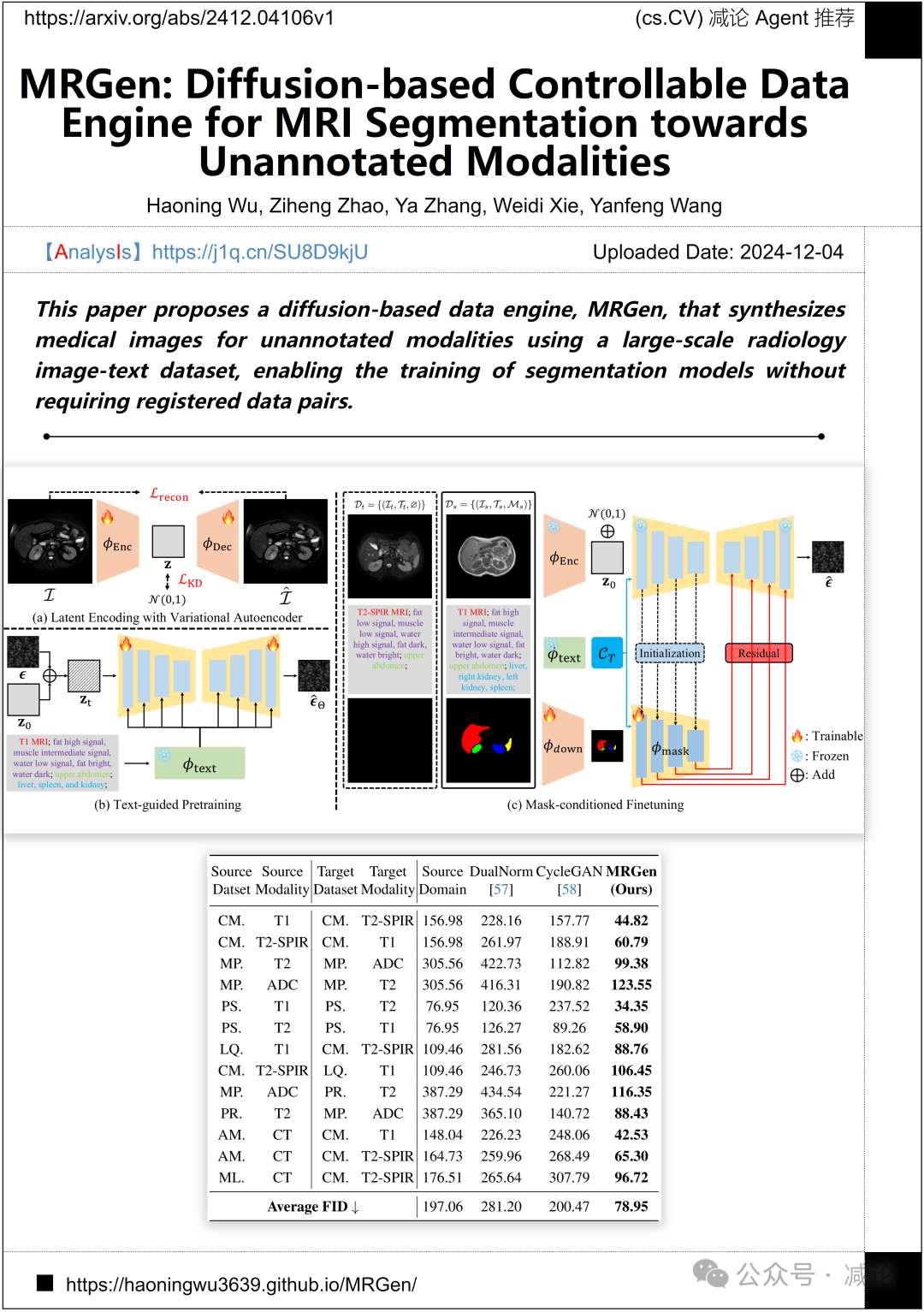
上海交通大学开发了一种名为MRGen的扩散数据引擎。该引擎利用大规模放射影像–文本数据集,实现了未标注模态的医学图像合成,从而无需配对数据即可训练分割模型。
【Bohr精读】
https://j1q.cn/SU8D9kjU
【arXiv链接】
http://arxiv.org/abs/2412.04106v1
【代码地址】
https://haoningwu3639.github.io/MRGen/

字节跳动推出了Infinity方法,这是一个按位视觉自回归建模框架。该框架利用无限词汇表的tokenizer和分类器,以及按位自校正机制,从语言指令生成高分辨率、真实感图像。Infinity在生成能力和速度上显著优于现有模型。
【Bohr精读】
https://j1q.cn/ctHe0ylG
【arXiv链接】
http://arxiv.org/abs/2412.04431v1
【代码地址】
https://github.com/FoundationVision/Infinity
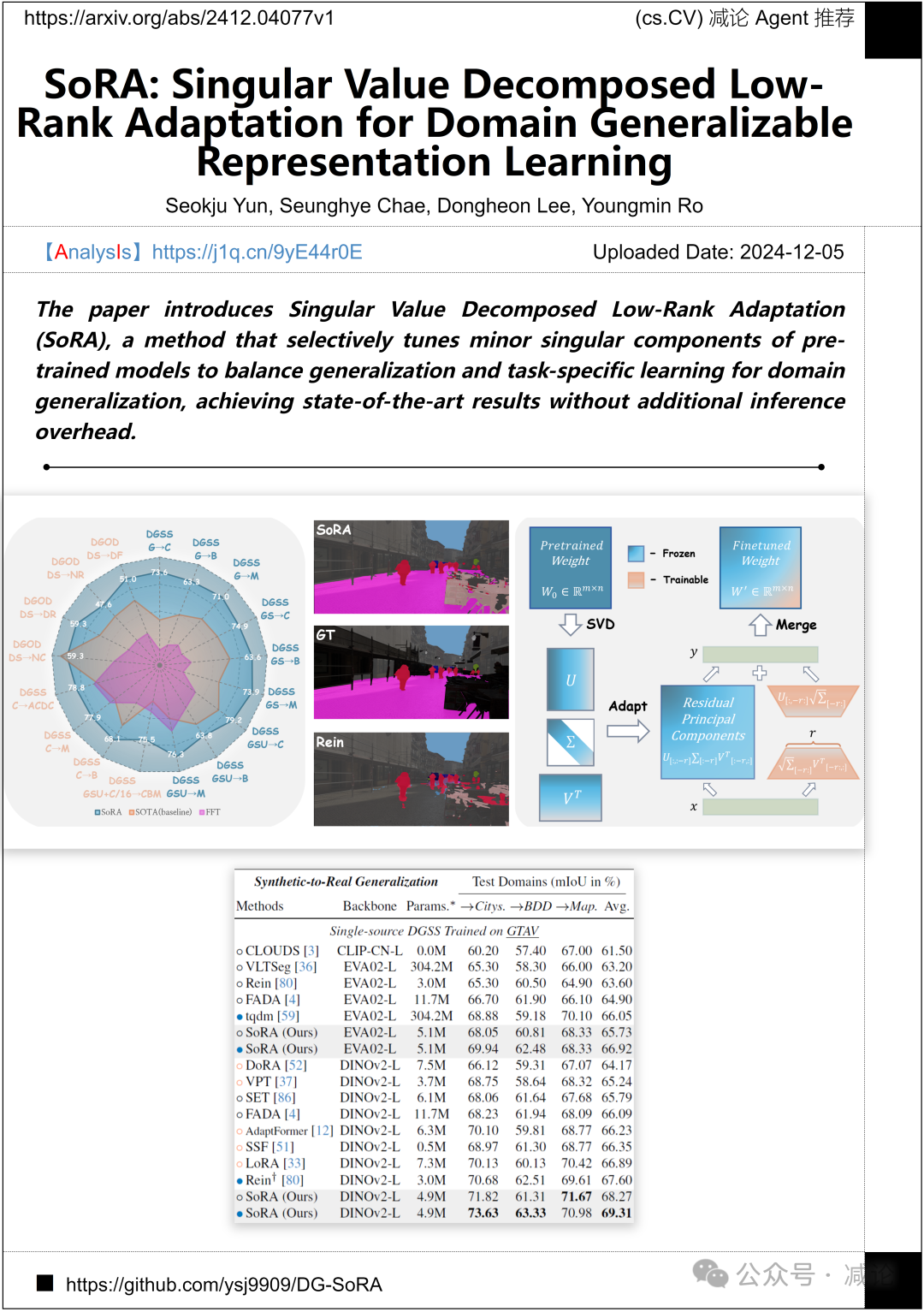
首尔大学推出的奇异值分解低秩适应方法(SoRA)通过选择性调整预训练模型的小奇异成分,平衡了泛化能力与特定任务的学习。该方法在不增加额外推理开销的情况下,实现了最先进的结果。
【Bohr精读】
https://j1q.cn/9yE44r0E
【arXiv链接】
http://arxiv.org/abs/2412.04077v1
【代码地址】
https://github.com/ysj9909/DG-SoRA

欢迎关注减论,持续输出有深度的人工智能极减理解,提升信息获取效率和认知维度。看完点颗小星星再走呗~