
那么多AI平台,到底哪个更强呢?以最基础的文字创作能力为例,进行一个大比拼。
一、测试流程设计
1.1 测试目标
-
评估多个AI平台的中文写作能力
-
对比不同写作场景下的表现
-
总结实用建议
1.2 评估维度
-
内容质量(逻辑性、创意性、准确性)
-
语言表达(用词、语法、风格)
-
任务理解(是否准确完成要求)
-
字数控制(是否符合限制要求)
1.3 测试平台
2.1 智能手表产品文案测试
测试一Prompt:
评分排名:
-
ChatGPT(4.7/5)
-
场景化描述生动
-
功能介绍完整
-
情感共鸣强
-
字数:224字(略超)


-
通义千问(4.6/5)
-
技术细节丰富
-
目标用户定位准确
-
专业度高
-
字数:238字(超出较多)

-
Kimi(4.3/5)
-
表达平实自然
-
情感共鸣好
-
重点突出
-
字数:164字(稍少)
-
豆包(4.2/5)
-
信息传递清晰
-
语言简练
-
核心价值明确
-
字数:134字(偏少)

-
Claude(4.1/5)
-
重点突出
-
结构合理
-
职场特征把握准确
-
字数:178字(达标)

2.2 职场故事改编测试
测试二Prompt:
评分排名:
-
ChatGPT(4.8/5)
-
三次递进式危机设计巧妙
-
情节张力强
-
职场特征突出
-
字数:2100字(基本达标)
-
通义千问(4.7/5)
-
五章节结构完整
-
人物刻画细腻
-
情节展开合理
-
字数:3500字(严重超标)
-
Kimi(4.5/5)
-
技术视角新颖
-
故事情节紧凑
-
主题表达清晰
-
字数:1500字(未达标)
-
豆包(4.4/5)
-
细节描写丰富
-
文笔优美
-
职场氛围真实
-
字数:3000字(超标)
-
Claude(4.3/5)
-
主题表达清晰
-
结构简练
-
逻辑性强
-
字数:1000字(未达标)
2.3 春节营销邮件测试
测试三Prompt:
评分排名:
-
ChatGPT(4.8/5)
-
社交营销设计创新
-
情感营销到位
-
活动设计合理
-
字数:550字(略超)
-
通义千问(4.7/5)
-
活动设计最全面
-
服务细节周到
-
节日氛围浓厚
-
字数:800字(严重超标)
-
Claude(4.5/5)
-
优惠信息具体
-
结构清晰
-
重点突出
-
字数:300字(达标)
-
Kimi(4.4/5)
-
视觉设计出色
-
互动性强
-
emoji运用恰当
-
字数:400字(达标)
-
豆包(4.2/5)
-
传统节日氛围浓
-
文案优美
-
营销感适中
-
字数:400字(达标)
三、综合评估
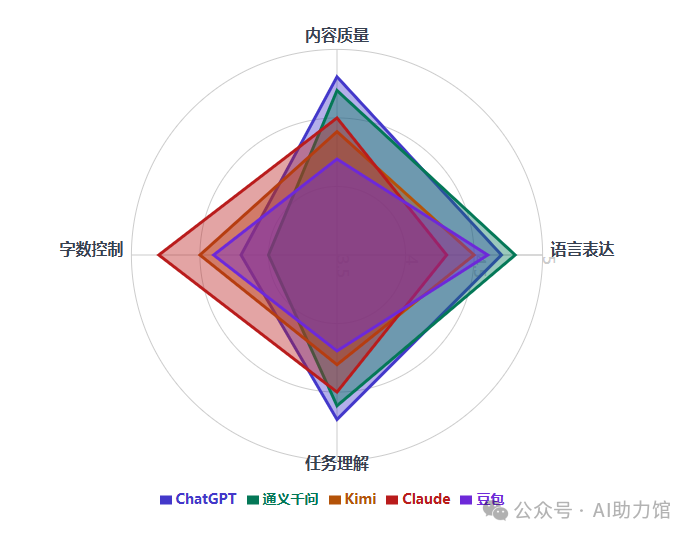
3.1 总体排名
-
ChatGPT(4.77/5)
-
优势:结构性强,创意好,场景化描述生动
-
特点:各类型写作均衡发挥
-
改进:字数控制需加强
-
通义千问(4.67/5)
-
优势:内容丰富,细节完整,服务周到
-
特点:长篇写作表现突出
-
改进:字数控制有待提升
-
Kimi(4.40/5)
-
优势:互动性好,视觉效果佳
-
特点:新媒体写作能力强
-
改进:内容深度和字数控制
-
Claude(4.30/5)
-
优势:逻辑清晰,重点突出,字数控制好
-
特点:商务写作表现稳定
-
改进:创意性和内容丰富度
-
豆包(4.27/5)
-
优势:文笔优美,传统风格强
-
特点:文学性写作出色
-
改进:现代感和创新性
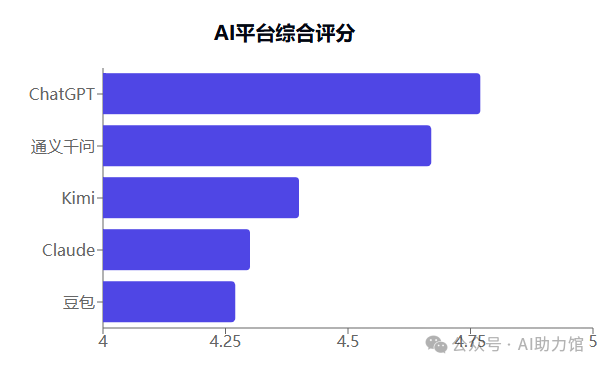
||不得不说,开源的通义,表现有点惊艳了,今后要多用用!||
对评估项目进行加权后,得到如下表格:
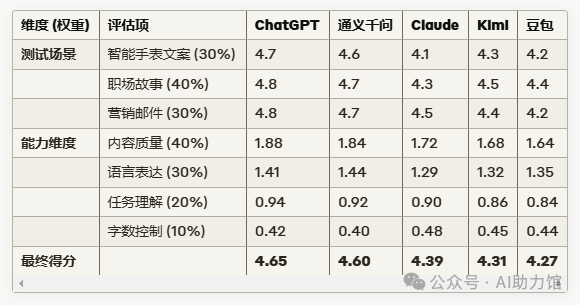
通义的表现还是占优,而豆包仍然垫底,这个结果有点出乎意料。
3.2 应用场景推荐
-
产品文案:ChatGPT、通义千问
-
故事创作:ChatGPT、通义千问
-
营销策划:ChatGPT、Kimi
-
商务写作:Claude、豆包
-
传统文案:豆包、通义千问
-
重要营销活动:ChatGPT + Kimi
-
长篇创意内容:ChatGPT + 通义千问
-
商务正式文案:Claude + 豆包
3.3 测试局限性
-
样本局限
-
单次测试,未考虑平台状态波动
-
未进行多轮对比测试
-
提示词变化影响未知
-
评分主观性
-
评分标准定性为主
-
缺乏量化指标
-
评估者单一
-
场景覆盖
-
仅测试三类写作场景
-
未覆盖所有商业写作需求
-
缺乏长期稳定性数据
3.4 优化建议
-
平台改进方向
-
加强字数控制能力
-
增加风格切换选项
-
提升跨场景适应性
-
用户使用建议
-
根据场景选择适合平台
-
提供精准prompt指引
-
重要内容需人工审核
-
测试方法改进
-
扩大测试样本数量
-
建立量化评分标准
-
进行长期跟踪测试

