
收录于话题
2024年12月4日arXiv cs.CV发文量约135余篇,减论Agent通过算法为您推荐并自动化整理为卡片供您参考,预计为您节省58分钟浏览arXiv的时间。
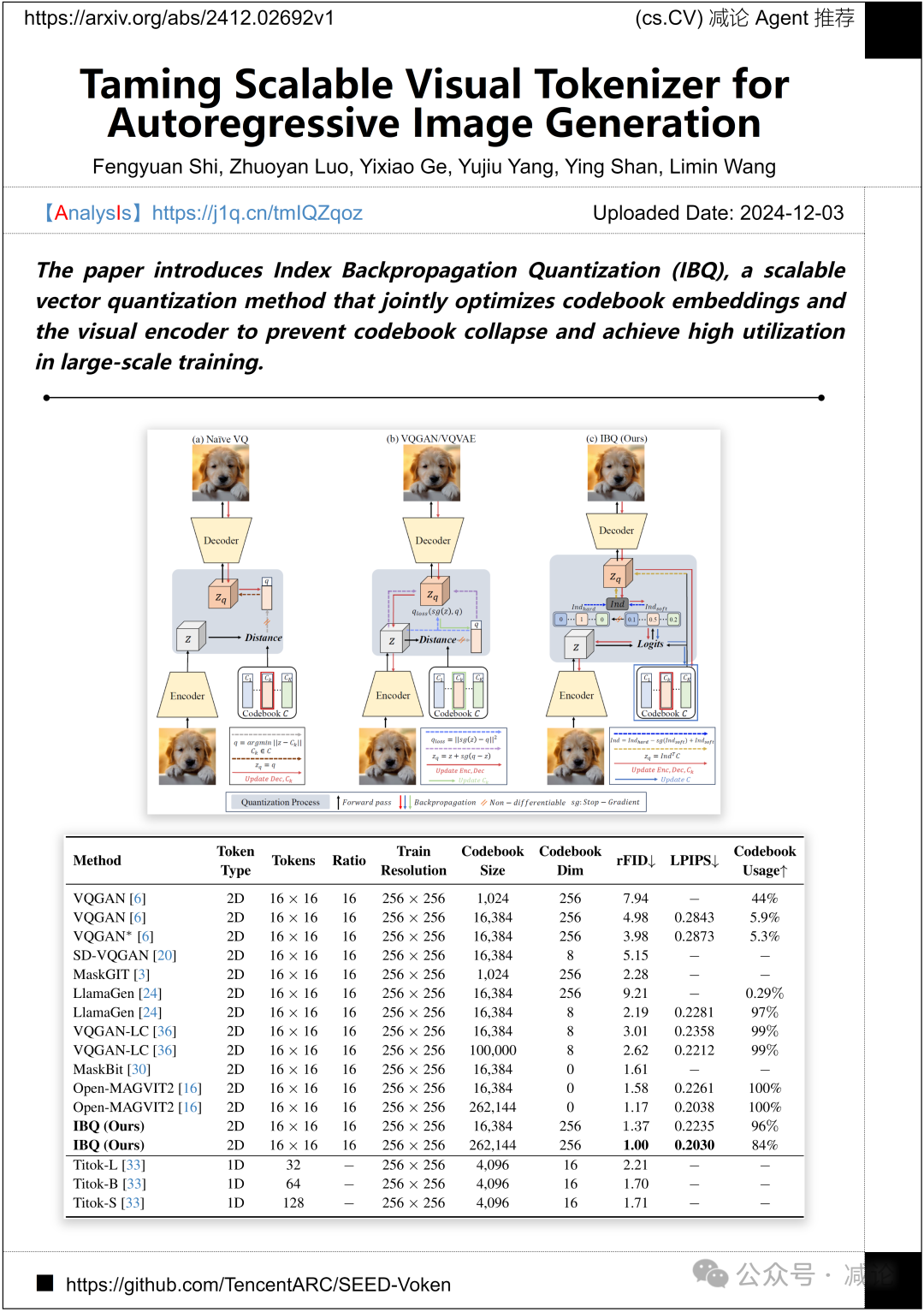

南京大学、清华大学和腾讯PCG联合提出了索引反向传播量化(IBQ)方法,介绍了一种可扩展的向量量化技术。该技术能够联合优化码本嵌入和视觉编码器,有效防止码本崩溃,并在大规模训练中实现高效利用。
【Bohr精读】
https://j1q.cn/tmIQZqoz
【arXiv链接】
http://arxiv.org/abs/2412.02692v1
【代码地址】
https://github.com/TencentARC/SEED-Voken
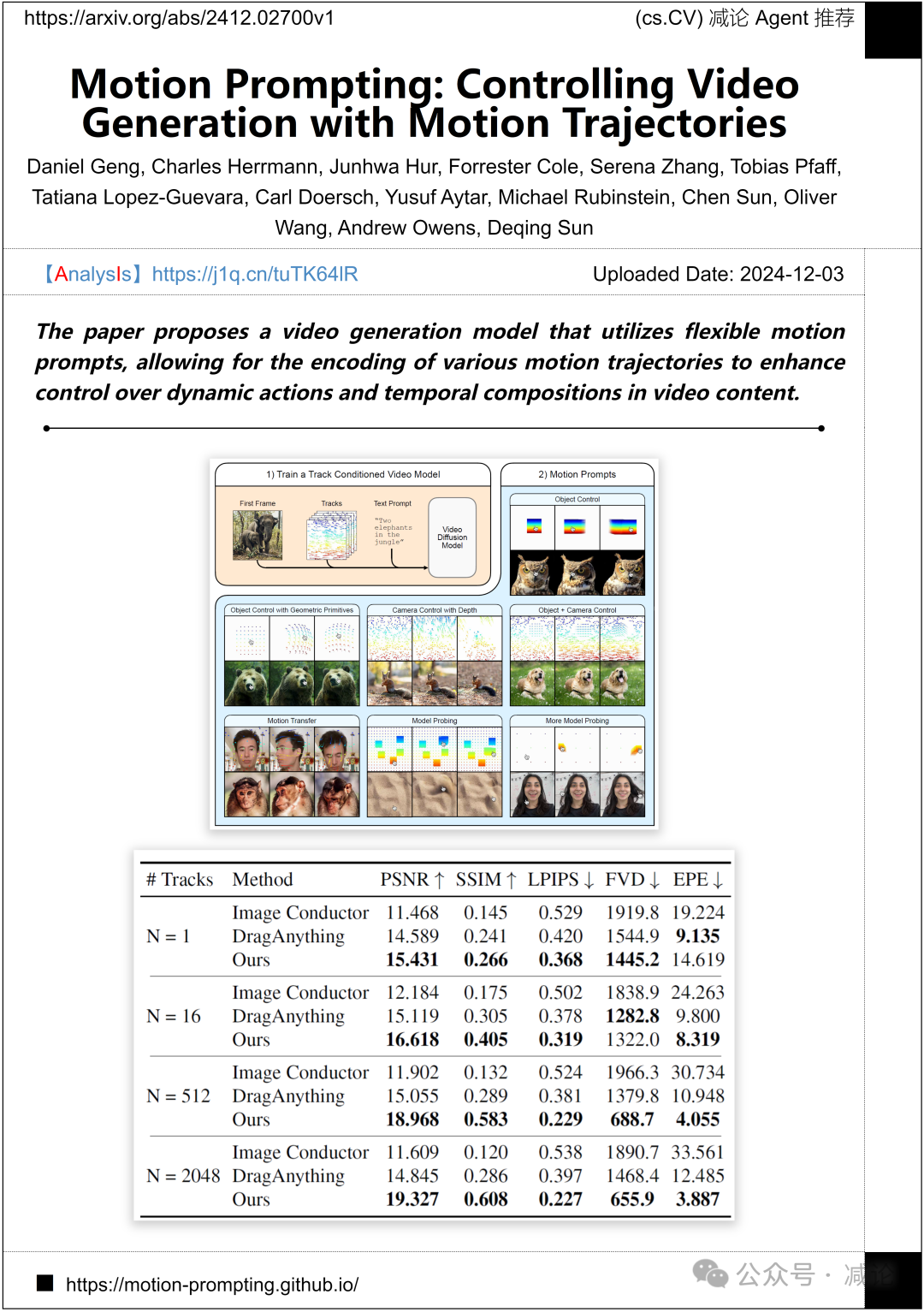
密歇根大学与谷歌深度学习联合推出了一种视频生成模型,利用灵活的运动提示编码多种运动轨迹,从而增强对视频内容中动态动作和时间构图的控制。
【Bohr精读】
https://j1q.cn/tuTK64lR
【arXiv链接】
http://arxiv.org/abs/2412.02700v1
【代码地址】
https://motion-prompting.github.io/

捷克技术大学捷克信息学、机器人和网络安全研究所、布里斯托大学、穆罕默德·本·扎耶德人工智能大学提出了一种新方法,通过教学视频创建大型数据集,并开发了名为ShowHowTo的视频扩散模型。该模型能够从输入图像和文本指令生成逐步的视觉指令,并在生成准确的图像序列方面达到了最先进的效果。
【Bohr精读】
https://j1q.cn/RPmcCJa7
【arXiv链接】
http://arxiv.org/abs/2412.01987v1
【代码地址】
https://soczech.github.io/showhowto/
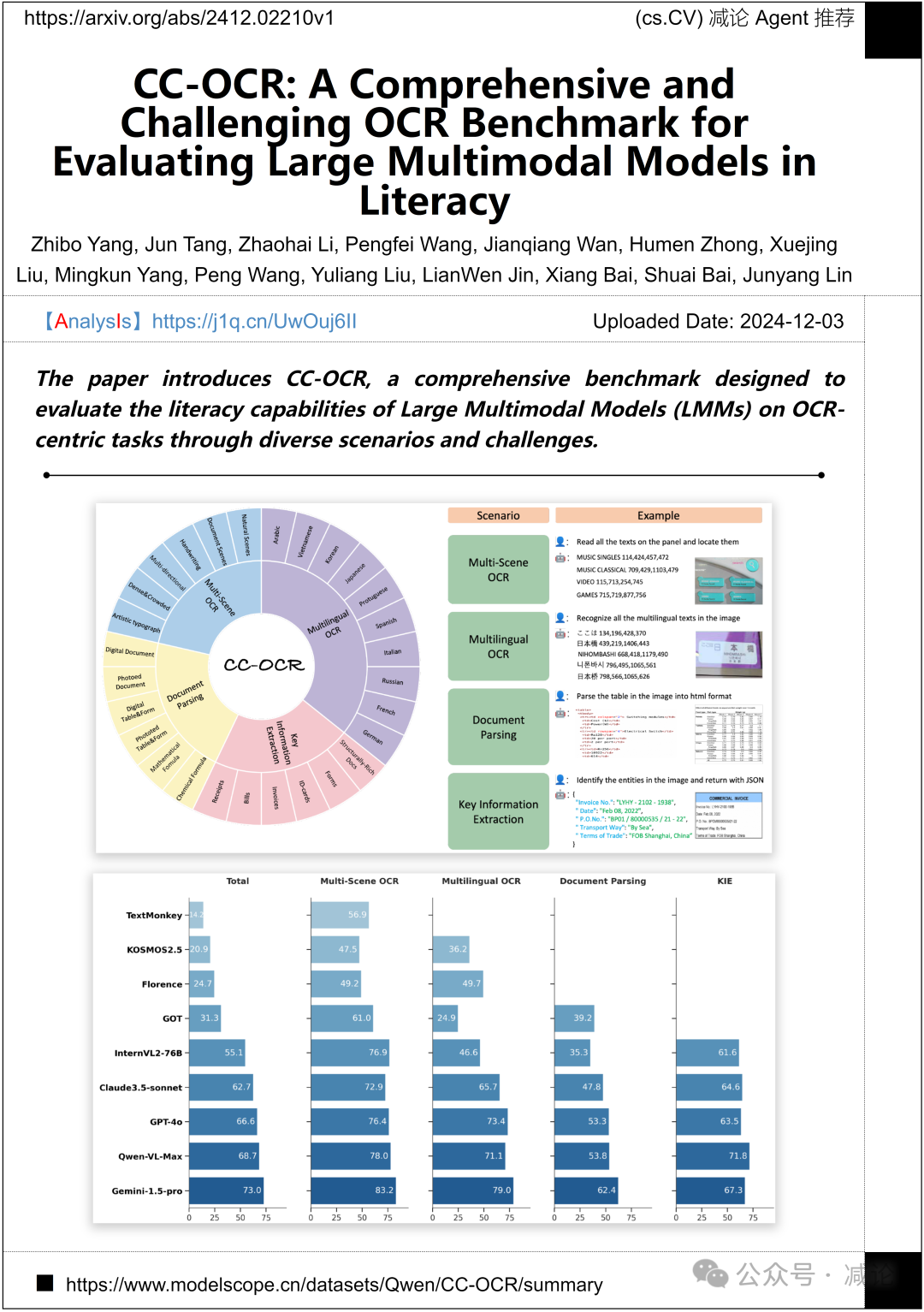
阿里巴巴集团与华中科技大学联合推出了CC-OCR方法,这是一个综合基准,用于评估大型多模态模型(LMMs)在多样化场景和挑战下的OCR任务识字能力。
【Bohr精读】
https://j1q.cn/UwOuj6II
【arXiv链接】
http://arxiv.org/abs/2412.02210v1
【代码地址】
https://www.modelscope.cn/datasets/Qwen/CC-OCR/summary

北京大学提出了RelayGS方法,通过学习具有规范3D高斯和紧凑运动场的4D表示,增强了3D Gaussian Splatting,有效重建高度动态场景。该方法采用三阶段过程:动态前景与背景分离、优化时间段的中继高斯、精炼运动表示。
【Bohr精读】
https://j1q.cn/fbhFWsq0
【arXiv链接】
http://arxiv.org/abs/2412.02493v1
【代码地址】
https://github.com/gqk/RelayGS

阿卜杜拉国王科技大学太空研究所提出了一种新的无模态深度估计方法,利用大规模数据集Amodal Depth In the Wild (ADIW)进行相对深度预测。研究引入两个互补框架,以提高模型在预测被遮挡物体深度时的泛化能力和准确性。
【Bohr精读】
https://j1q.cn/hvzw1RKX
【arXiv链接】
http://arxiv.org/abs/2412.02336v1
【代码地址】
https://zhyever.github.io/amodaldepthanything/

厦门大学与腾讯联合开发了一种规则引导空间感知网络(RG-SAN)用于3D指代表达分割。该网络通过空间信息进行监督,结合文本驱动的定位模块和规则引导的弱监督策略,优化实例定位,从而显著提升分割精度和推理能力。
【Bohr精读】
https://j1q.cn/vfa3cPfp
【arXiv链接】
http://arxiv.org/abs/2412.02402v1
【代码地址】
https://github.com/sosppxo/RG-SAN

华东师范大学与上海交通大学提出了一种名为Diffusion Implicit Policy (DIP)的框架,用于场景感知的动作合成。该方法在训练中将人–场景交互与动作合成解耦,推理时采用基于交互的隐式策略,消除了对配对动作–场景数据的需求,从而增强了动作的自然性和交互的合理性。
【Bohr精读】
https://j1q.cn/EbInhjWh
【arXiv链接】
http://arxiv.org/abs/2412.02261v1
【代码地址】
https://jingyugong.github.io/DiffusionImplicitPolicy/

布朗大学与Meta Reality Lab推出的FoundHand方法是一种领域特定的扩散模型,利用大规模2D关键点数据生成逼真的单手和双手图像,实现对手部关节和外观的精确控制。FoundHand在手部图像生成和操控方面达到了最先进的性能。
【Bohr精读】
https://j1q.cn/YXi71vTO
【arXiv链接】
http://arxiv.org/abs/2412.02690v1
【代码地址】
https://ivl.cs.brown.edu/research/foundhand.html

天津大学提出的ShadowHack方法采用分而治之策略,通过定制神经网络分别恢复图像的亮度和还原颜色,有效解决阴影相关的图像问题。
【Bohr精读】
https://j1q.cn/kzesxC4q
【arXiv链接】
http://arxiv.org/abs/2412.02545v1
【代码地址】
https://github.com/lime-j/ShadowHack

加利福尼亚大学洛杉矶分校与斯坦福大学联合提出了VISCO方法,这是一个用于分析大型视觉语言模型(LVLMs)批判和纠正能力的基准。该论文通过细粒度评估推理步骤,提出了一种LookBack策略,利用视觉输入的信息验证来提升模型性能。
【Bohr精读】
https://j1q.cn/XJix8UNH
【arXiv链接】
http://arxiv.org/abs/2412.02172v1
【代码地址】
https://visco-benchmark.github.io/
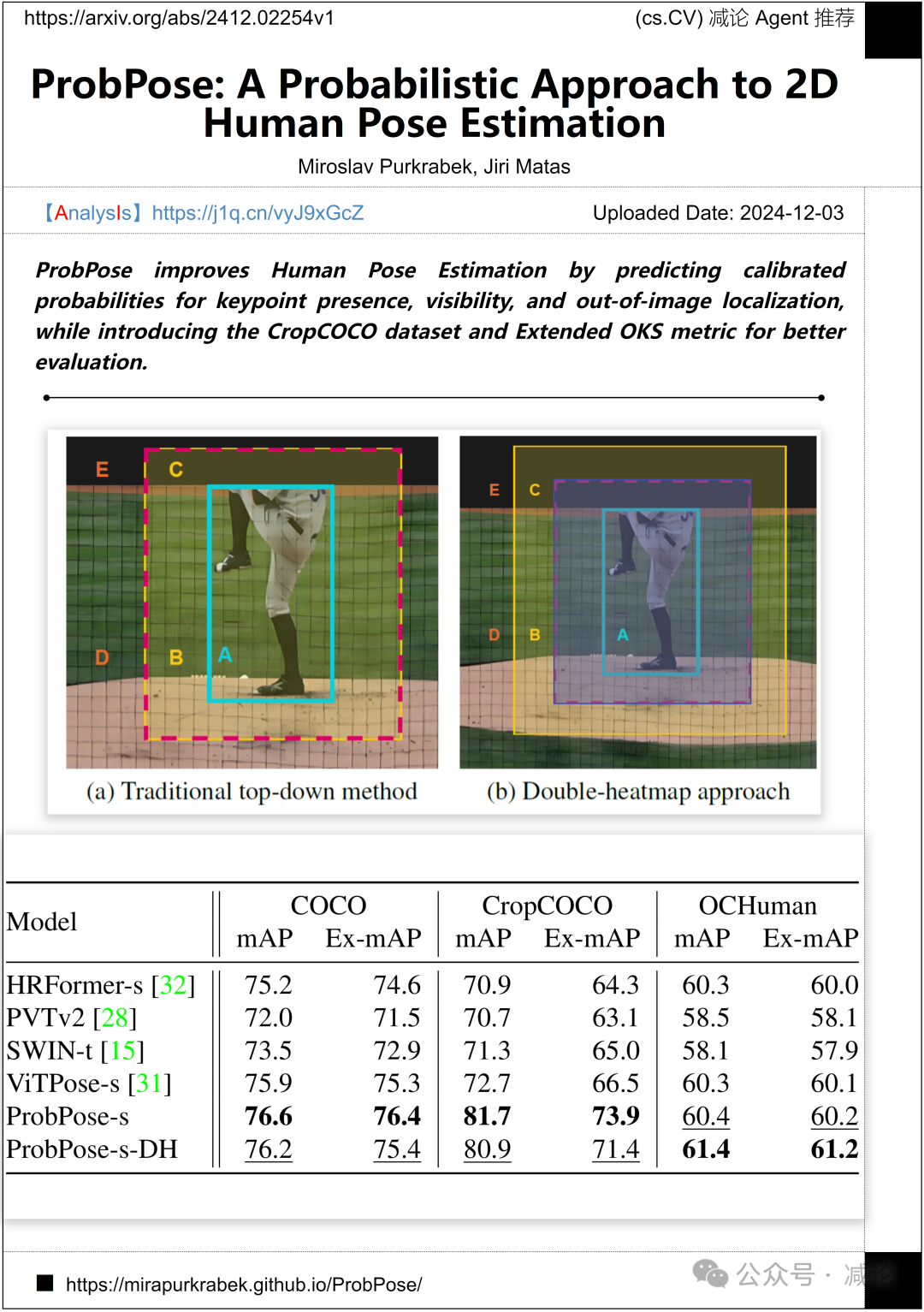
捷克理工大学提出了ProbPose方法,改进了人体姿态估计,通过预测关键点的存在、可见性和图像外定位的校准概率。研究还引入了CropCOCO数据集和扩展OKS指标,以提高评估效果。
【Bohr精读】
https://j1q.cn/vyJ9xGcZ
【arXiv链接】
http://arxiv.org/abs/2412.02254v1
【代码地址】
https://mirapurkrabek.github.io/ProbPose/

波士顿动力人工智能研究所与康奈尔大学联合提出了GLIDE方法。该方法结合了基于模型的运动规划和任务条件扩散策略学习,生成高质量的合成运动轨迹,以实现复杂双手操作任务中的有效物体操控。GLIDE适用于多种场景,具有广泛的应用前景。
【Bohr精读】
https://j1q.cn/nf28TowE
【arXiv链接】
http://arxiv.org/abs/2412.02676v1
【代码地址】
https://glide-manip.github.io/

萨里大学与NetMind.AI提出了NitroFusion方法,采用动态对抗框架和专门的判别器组。该方法通过在不同噪声水平下提供多样化反馈,显著提高了单步扩散生成的质量,实现了灵活的质量与速度权衡。
【Bohr精读】
https://j1q.cn/vOQxdDrK
【arXiv链接】
http://arxiv.org/abs/2412.02030v1
【代码地址】
https://chendaryen.github.io/NitroFusion.github.io

北斗信息技术有限公司提出了非对称语义对齐网络(ASANet)方法。该网络通过语义聚焦模块和级联融合模块,有效学习和融合RGB与SAR图像的互补特征,从而提升多模态地物分类的效果。
【Bohr精读】
https://j1q.cn/kHf6Jeli
【arXiv链接】
http://arxiv.org/abs/2412.02044v1
【代码地址】
https://github.com/whu-pzhang/ASANet

上海人工智能实验室与香港中文大学提出了TimeWalker框架,通过新颖的神经参数模型模拟个体一生中的身份,构建逼真的3D头部头像。该模型有效解耦形状、表情和外观,并结合动态神经基混合模块与动态2D高斯喷射技术,实现高度逼真的渲染和动画效果。
【Bohr精读】
https://j1q.cn/55HKLaob
【arXiv链接】
http://arxiv.org/abs/2412.02421v1
【代码地址】
https://timewalker2024.github.io/

厦门大学与Skywork AI联合推出的AccDiffusion v2方法引入了补丁内容感知提示和辅助局部结构信息,增强了高分辨率的扩散外推,有效减少了对象重复和局部失真,无需额外训练。
【Bohr精读】
https://j1q.cn/pFgk8E62
【arXiv链接】
http://arxiv.org/abs/2412.02099v1
【代码地址】
https://github.com/lzhxmu/AccDiffusion_v2

永伦人工智能、香港科技大学和密歇根州立大学提出了OmniCreator方法。OmniCreator是一个统一框架,专注于文本提示的图像和视频生成与编辑。该方法利用自监督学习在文本和视频之间建立语义对应,实现多功能编辑,并能够从文本提示生成高质量视频。
【Bohr精读】
https://j1q.cn/8OFJlaXL
【arXiv链接】
http://arxiv.org/abs/2412.02114v1
【代码地址】
https://haroldchen19.github.io/OmniCreator-Page/

北京航空航天大学提出了Inline Prior Guided Score Matching (IPSM)方法,利用视点姿态关系中的视觉内联先验,校正图像分布,并实现无需微调或预训练的优化,从而增强稀疏视图的3D重建。
【Bohr精读】
https://j1q.cn/HpcXwpYd
【arXiv链接】
http://arxiv.org/abs/2412.02225v1
【代码地址】
https://github.com/iCVTEAM/IPSM

欢迎关注减论,持续输出有深度的人工智能极减理解,提升信息获取效率和认知维度。看完点颗小星星再走呗~