
什么是 cuDF Pandas?
如果你是一个使用 Python 的 Pandas 库的用户,并且希望或需要最大限度地提高程序的运行速度,那么你有一些选择。这些选择大多围绕着使用外部库,这些库取代了现有的 Pandas 操作,并针对大规模和快速数据处理进行了优化。这些库的示例有 VAEX、POLARS、DuckDB 等。这些库的问题在于,它们通常要求你或多或少地重写代码,这可能不是你想要或有能力做的事情。
如果你足够幸运,你的系统上有一个 GPU,那么另一个更新的选择是 cuDF.pandas。
cuDF.pandas 是基于 cuDF 构建的,cuDF 是一个 Python GPU DataFrame 库(基于 Apache Arrow 列式内存格式),用于加载、连接、聚合、过滤以及以其他方式操作数据。
要使用 cuDF Pandas,你只需在从命令行运行 Python 时提供一个标志,或者在通过 Jupyter Notebook 运行 Python 时加载一个扩展。当支持 GPU 计算(例如,有 NVIDIA GPU 可用,并且 cuDF 知道如何运行 Pandas 代码)时,你的代码将在 GPU 上运行。在不支持的情况下,cuDF 会自动切换到在 CPU 上运行。你不需要编写代码的两个版本,也不需要手动处理 GPU 和 CPU 之间的切换。
cuDF 是 RAPIDS 的一部分,RAPIDS 是一个开源软件库和 API 套件,由 NVIDIA 创建和维护。NVIDIA 是 GPU(图形处理单元)技术的先驱,也是 CUDA(计算统一设备架构)的创建者。RAPIDS 旨在使数据科学家和工程师能够利用 GPU 加速的优势进行数据探索和分析管道。它利用了 GPU 的并行处理能力,与传统的基于 CPU 的数据处理相比,可以显著提高性能。
在本文中,我们将让普通的 Pandas 与 cuDF Pandas 进行对比,看看 cuDF Pandas 的优势在哪里。我们将获取一个大型输入文件,将其读取到 pandas 数据框中,并对数据框执行一些操作。在每个步骤中,我们将记录使用常规 Pandas 进行操作所需的时间与 cuDF pandas 进行比较。
前提条件
-
安装 WSL Ubuntu Linux
由于我使用的是基于 Windows 的系统,并且在 Windows 平台上安装 Cuda 更加复杂,因此我选择在 Linux 下进行安装。幸运的是,Windows Linux 子系统(WSL)可以派上用场。
要安装它,请打开 PowerShell 命令窗口,然后可以简单地输入:
(base) PS C:Usersthoma> wsl -- install
Installing: Windows Subsystem for Linux Windows Subsystem for Linux has been installed. Installing: Ubuntu Ubuntu has been installed.
所请求的操作已成功完成。更改将在重新启动后生效。
或者,你可以从 Microsoft Store 下载合适的 WSL(它是免费的!)并按照那里的安装说明进行操作。以下是链接:
Ubuntu – Microsoft Store 中的官方应用
通过 Windows Linux 子系统 (WSL) 在几分钟内安装一个完整的 Ubuntu 终端环境。使用 WSL 开发…
安装完成后,重新启动你的电脑,WSL 应该会自动启动,系统会要求你设置用户名和密码。如果一切正常,你的命令窗口应该如下所示:
Ubuntu 已经安装。
安装成功!要以管理员身份运行命令(用户“root”),请使用“sudo”。有关详细信息,请参阅“man sudo_root”。
欢迎使用 Ubuntu 22.04.3 LTS (GNU/Linux 5.15.133.1-microsoft-standard-WSL2 x86_64)
-
文档:https: //help. ubuntu. com -
管理:https: //landscape. canonical. com -
支持:https: / /ubuntu. com/advantage
此消息每天显示一次。要禁用它,请创建 /home/tom/. hushlogin 文件。
要退出 WSL Linux,请在提示符下输入 exit。安装完成后,要再次调用 Ubuntu,在常规 PowerShell 命令窗口中输入 ubuntu 以返回到 Linux shell。
-
为你的 GPU 和系统安装最新的 NVIDIA 驱动程序
访问 NVIDIA 网站并安装与你的系统和 GPU 规格相关的最新驱动程序。
下载最新的官方 NVIDIA 驱动程序
下载适用于 NVIDIA 产品的最新驱动程序,包括 GeForce、TITAN、NVIDIA RTX、数据中心、GRID 等。
-
在 WSL 上安装 Miniconda
安装 WSL 并启动后,输入以下命令以获取 Miniconda 并进行安装。
$ wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh
$ ./Miniconda3-latest-Linux-x86_64.sh
-
安装 RAPIDS
你可以通过 conda、pip 或 docker 文件安装 RAPIDS 环境,但我们将使用 conda。点击下面的 RAPIDS 指南以获取完整的安装说明:
RAPIDS 安装指南
在安装指南的顶部附近,你会看到一个如下所示的屏幕,
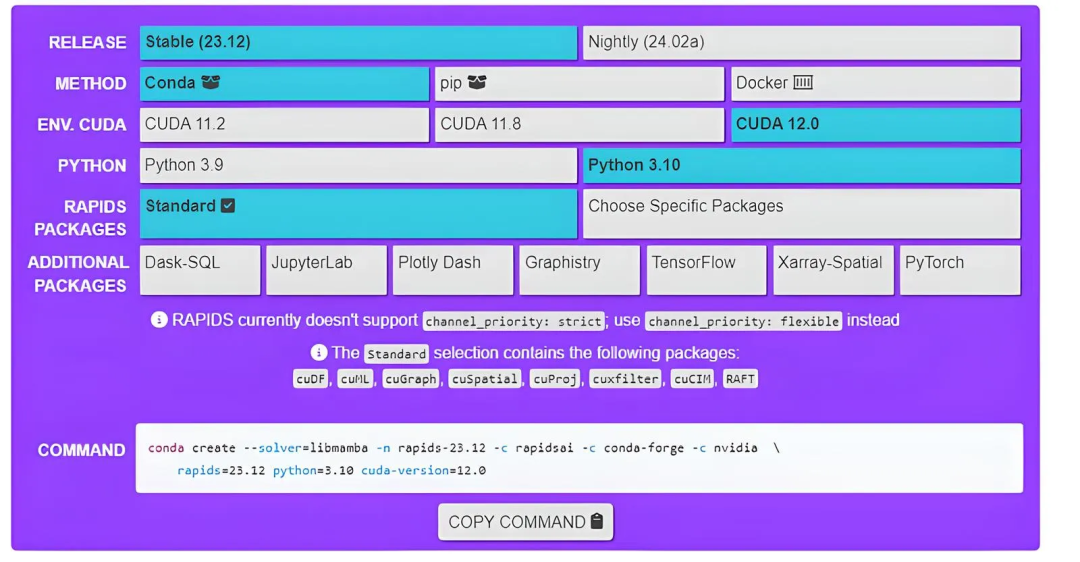

复制该命令并将其输入到 WSL 终端中。它将需要几分钟才能完成。我的命令如下所示,但你的可能会有所不同。
conda create -- solver=libmamba -n rapids-23.12 -c rapidsai -c conda-forge -c nvidia rapids=23.12 python=3.10 cuda-version=12.0
完成后,我们可以使用以下命令激活新环境,
$ conda activate rapids-23.12
-
安装 Jupyter
为了运行我们的速度测试,我们将安装 Jupyter,这样我们就可以运行笔记本了。
(rapids-23.12)$ pip install jupyter
好了,我们基本上已经完成了设置。现在让我们进入正题。
请注意,我在 HP Envy Desktop TE02 上运行了这些测试,该台式机在 Windows 11 下运行 Ubuntu WSL,配备 NVIDIA GeForce RTX 4070 Ti GPU 处理器和第 13 代 Intel i9-13900K,3000 Mhz,24 核,32 逻辑处理器。
使用的 Pandas 版本为 1.5.3
我们的输入数据
对于输入数据,我们将使用托管在 Kaggle 上的开源数据集。我选择的数据是纽约市 FHV(Uber/Lyft)行程数据扩展版(2019-2022),可以在以下网址找到:
纽约市 FHV(Uber/Lyft)行程数据扩展版(2019-2022)
纽约市 2019-22 年期间所有网约车行程的完整数据
该数据集最初来自 nyc.gov 网站,并根据 nyc.gov 使用条款进行管理。该数据集由纽约市开放数据提供,该数据根据知识共享 CC0:公共领域许可进行提供,如该公司在 Kaggle 上的帐户数据集元数据部分所述。这意味着任何人都可以“……复制、修改、分发和执行作品,即使出于商业目的,也无需征得许可。”
我将数据下载到我的本地桌面。有几个辅助文件和查找文件,但主数据集包含 46 个 Parquet 文件,总大小为 18 GB,包含以下列。在最初的测试中,整个数据集太大,无法读取到数据框中,因此我将 2021 年前 6 个月的文件复制出来,并将其用作我的输入。
启动你的 Jupyter Notebook
(rapids-23.12)$ jupyter notebook
你的笔记本可能会在浏览器中自动启动,但如果不是,在上述命令输出结束时,你会看到几个链接,你可以将其粘贴到浏览器中以手动启动笔记本,如下所示:
要访问服务器,请在浏览器中打开此文件:
file: ///home/tom/. local/share/jupyter/runtime/jpserver-897-open.html
或复制粘贴以下其中一个 URL:
http://localhost:8888/tree?token=703515a870b45b58eed9b73b69621b3f0f1cb7
http://127.0.0.1:8888/tree?token=703515a870b45b58eed9b73b69621b3f0f1cb7
复制其中一个 URL 并将其粘贴到浏览器中,笔记本应该会启动。
测试 1:将输入数据读取到 Pandas 数据框中
首先,使用常规 Pandas 读取数据。
! dir /mnt/d/test2
fhvhv_tripdata_2021-01.parquet
fhvhv_tripdata_2021-02.parquet
fhvhv_tripdata_2021-03.parquet
fhvhv_tripdata_2021-04.parquet
fhvhv_tripdata_2021-05.parquet
fhvhv_tripdata_2021-06.parquet
%%time # regular Pandas
import pandas as pd
print (pd)
df=pd.read_parquet("/mnt/d/test2/")
print ('df shape = ' , df.shape)
Pandas 输出。
<module 'pandas' from ' /home/tom/miniconda3/envs/rapids-23.12/lib/python3.10/si
df shape = (81542237,
### 测试 1:将输入数据读取到 Pandas 数据框中
首先,使用常规 Pandas 读取数据。
```python
! dir /mnt/d/test2
fhvhv_tripdata_2021-01.parquet
fhvhv_tripdata_2021-02.parquet
fhvhv_tripdata_2021-03.parquet
fhvhv_tripdata_2021-04.parquet
fhvhv_tripdata_2021-05.parquet
fhvhv_tripdata_2021-06.parquet
%%time # regular Pandas
import pandas as pd
print (pd)
df=pd.read_parquet("/mnt/d/test2/")
print ('df shape = ' , df.shape)
Pandas 输出:
<module 'pandas' from '/home/tom/miniconda3/envs/rapids-23.12/lib/python3.10/site-packages/pandas/__init__.py'>
df shape = (81542237, 24)
CPU times: user 32.6 s, sys: 9.9 s, total: 42.5 s
Wall time: 1min 6s
接下来,我们加载扩展程序。之后,任何 Pandas 操作都将自动使用 cuDF.Pandas 处理。
%load_ext cudf.pandas
%%time
import pandas as pd
# 现在我们使用 cuDF Pandas
print(pd)
df=pd.read_parquet("/mnt/d/test2/")
print ('df shape = ' , df.shape)
cuDF Pandas 输出:
<module 'pandas' (ModuleAccelerator (fast=cudf, slow=pandas))>
df2 shape = (81542237, 24)
CPU times: user 6.41 s, sys: 344 ms, total: 6.75 s
Wall time: 19.3 s
这是一个很好的开始,与常规 Pandas 相比,我们节省了大约三分之二的时间来加载数据集。好的,让我们对数据框进行一些数据处理。
测试 2:找出最繁忙的接载时间
%%time
df['pickup_hour'] = df['pickup_datetime'].dt.hour
df['pickup_minute'] = df['pickup_datetime'].dt.minute
pickup_time_hour = df['pickup_hour'].value_counts()
pickup_time_minute = df['pickup_minute'].value_counts()
busiest_pickup_time = str(pickup_time_hour.idxmax()).zfill(2) + ':' + str(pickup_time_minute.idxmax()).zfill(2)
print("The busiest pick-up time was ", busiest_pickup_time)
Pandas 输出:
The busiest pick-up time was 18:05
CPU times: user 2.32 s, sys: 341 ms, total: 2.67 s
Wall time: 2.89 s
cuDF Pandas 输出:
The busiest pick-up time was 18:05
CPU times: user 477 ms, sys: 11.9 ms, total: 488 ms
Wall time: 611 ms
这次速度提高了 4 倍。
测试 3:计算每个基地的总收入
%%time
total_revenue = df.groupby('dispatching_base_num')[['base_passenger_fare']].sum()
print(total_revenue)
Pandas 输出:
base_passenger_fare
dispatching_base_num
B02395 1.474796e+07
B02510 4.716340e+08
B02512 19379214.63
B02617 19215713.10
B02682 6.186856e+06
B02764 236174.51
B02765 262159.19
B02800 3.836497e+07
B02835 1515676.50
B02836 1153720.09
B02844 1847330.64
B02864 1334644.86
B02865 5713613.94
B02866 4361999.91
B02867 4.526493e+07
B02869 1.469802e+08
B02870 8.166917e+07
B02871 1.622731e+07
B02872 3334981.85
B02875 90408.83
B02876 2384550.98
B02877 308746.87
B02878 2.867439e+07
B02879 1137756.51
B02880 821118.32
B02882 1.931810e+07
B02883 5.292548e+05
B02884 4.199323e+07
B02887 1.177934e+07
B02888 469413.75
B02889 574488.16
B03136 402665.20
CPU 时间:
CPU times: user 2.19 s, sys: 587 ms, total: 2.78 s
Wall time: 2.94 s
cuDF Pandas 输出:
# 数据输出与上述相同,这里仅显示时间统计
CPU 时间:
CPU times: user 425 ms, sys: 0 ns, total: 425 ms
Wall time: 453 ms
同样,速度提高了 4 倍以上。
测试 4:平均票价按天计算
%%time
df['pickup_day_of_week'] = df['pickup_datetime'].dt.day_name()
average_fare_per_day = df.groupby('pickup_day_of_week')['base_passenger_fare'].mean()
print(average_fare_per_day)
Pandas 输出:
pickup_day_of_week
Friday 21.277356
Monday 20.333885
Saturday 21.122636
Sunday 21.445824
Thursday 20.702871
Tuesday 20.141152
Wednesday 20.375923
Name: base_passenger_fare, dtype: float64
CPU times: user 8.55 s, sys: 1.41 s, total: 9.96 s
Wall time: 10.2 s
cuDF Pandas 输出:
pickup_day_of_week
Friday 21.277356
Monday 20.333885
Saturday 21.122636
Sunday 21.445824
Thursday 20.702871
Tuesday 20.141152
Wednesday 20.375923
Name: base_passenger_fare, dtype: float64
CPU times: user 8.77 s, sys: 1.28 s, total: 10 s
Wall time: 10 s
我对为什么在最后一个测试中常规 pandas 和 cuDF pandas 的运行时间没有真正的差异感到好奇。幸运的是,有一些分析器可以使用。让我们来看一个分析器的实际应用。
%%cudf.pandas.line_profile
df['pickup_day_of_week'] = df['pickup_datetime'].dt.day_name()
average_fare_per_day = df.groupby('pickup_day_of_week')['base_passenger_fare'].mean()
print(average_fare_per_day)
这产生了以下输出:
pickup_day_of_week
Friday 21.277356
Monday 20.333885
Saturday 21.122636
Sunday 21.445824
Thursday 20.702871
Tuesday 20.141152
Wednesday 20.375923
Name: base_passenger_fare, dtype: float64
Total time elapsed: 9.975 seconds
Stats
Line no.
Line
│
1 | df2['pickup_day_of_week'] = df2['pickup_datetime'].dt.day_name() │
2 | average_fare_per_day = df2.groupby('pickup_day_of_week')['base_pass │
│
3 print(average_fare_per_day) │
│
从这个输出中可以清楚地看出,第一行代码主要在常规 CPU 上运行,而不是在 GPU 上,我假设这是因为日期操作在 GPU 上不能很好地扩展,或者根本无法运行。
总结
总而言之,Pandas 的所有测试总共花费了 82.3 秒,而使用 cuDF Pandas 的总时间为 30.36 秒,因此这是一个 60% 的改进。虽然节省的时间大部分是在加载输入数据时,但这仍然是一个显著的提升。
使用 cuDF Pandas 最重要的一个方面是,你根本不需要更改你的 Pandas 代码。只需在运行程序之前,在 Jupyter Notebook 中加载一个扩展程序或一个额外的标志即可。系统初始设置可能有点复杂,但这是一次性操作,我认为潜在的时间效益将弥补这一点。
深入分析
1. 数据加载速度的提升
在测试 1 中,我们观察到 cuDF Pandas 在加载数据时显著优于常规 Pandas。具体来说,cuDF Pandas 加载 18 GB 的数据仅用了 19.3 秒,而常规 Pandas 则用了 1 分 6 秒。这主要归功于 cuDF 利用了 GPU 的并行处理能力,可以同时处理大量数据,从而大幅缩短了数据加载时间。
2. 数据处理速度的提升
在测试 2 和测试 3 中,我们对数据进行了简单的处理操作,包括提取日期时间字段中的小时和分钟,以及按基地编号分组并计算总收入。cuDF Pandas 在这两个测试中都表现出了约 4 倍的速度提升。
-
测试 2 中,提取小时和分钟的操作在常规 Pandas 中耗时约 2.89 秒,而在 cuDF Pandas 中仅耗时约 0.611 秒。这是因为 cuDF 可以高效地并行处理日期时间字段的提取操作。 -
测试 3 中,按基地编号分组并计算总收入的操作在常规 Pandas 中耗时约 2.94 秒,而在 cuDF Pandas 中仅耗时约 0.453 秒。cuDF 的并行分组和聚合能力在这里得到了充分体现。
3. 日期操作的局限性
在测试 4 中,我们计算了每个工作日的平均票价,结果发现常规 Pandas 和 cuDF Pandas 的运行时间几乎没有差异。为了找出原因,我们使用了 cudf.pandas.line_profile 分析器。
分析结果显示,第一行代码 df['pickup_day_of_week'] = df['pickup_datetime'].dt.day_name() 主要在 CPU 上运行,而不是在 GPU 上。这是因为日期操作(尤其是涉及字符串转换的操作)在 GPU 上并不总是高效的,甚至在某些情况下无法有效执行。
cuDF 在处理日期和时间数据时,虽然支持一些基本的操作,但在某些复杂操作(如字符串转换)上仍然存在局限性。这是因为 GPU 架构更适合处理数值计算和大规模并行任务,而对于字符串操作等需要复杂逻辑处理的任务,CPU 仍然是更合适的选择。
cuDF Pandas 的优势与局限
优势
-
显著的速度提升: 尤其是在数据加载和大规模数据处理任务中,cuDF Pandas 利用 GPU 的并行计算能力,可以显著缩短运行时间。 -
无缝集成: 无需修改现有的 Pandas 代码,只需加载扩展程序或添加标志即可使用 cuDF Pandas 的功能。 -
易于使用: 对于已经熟悉 Pandas 的用户来说,cuDF Pandas 的使用方式与 Pandas 非常相似,学习成本较低。
局限性
-
部分操作效率不高: 某些操作(如复杂的日期和时间操作、字符串处理等)在 GPU 上执行效率不高,甚至无法有效执行。 -
内存限制: GPU 的内存容量通常比 CPU 小,对于超大规模数据集,cuDF Pandas 可能会遇到内存不足的问题。 -
生态系统不完善: 相对于 Pandas,cuDF Pandas 的生态系统还不够完善,某些 Pandas 功能和第三方库可能无法直接使用。
结论
cuDF Pandas 是一个强大的工具,可以在特定场景下大幅提升数据处理速度,尤其是对于那些需要处理大规模数据集且主要进行数值计算和聚合任务的用户来说,cuDF Pandas 是一个非常有吸引力的选择。
然而,用户在使用 cuDF Pandas 时需要注意其局限性,例如部分操作效率不高以及内存限制等。对于需要频繁进行复杂日期和时间操作或字符串处理的用户,常规 Pandas 可能仍然是更好的选择。
参考资料
-
RAPIDS 官方网站 -
cuDF 文档 -
Pandas 文档
