
收录于话题


-
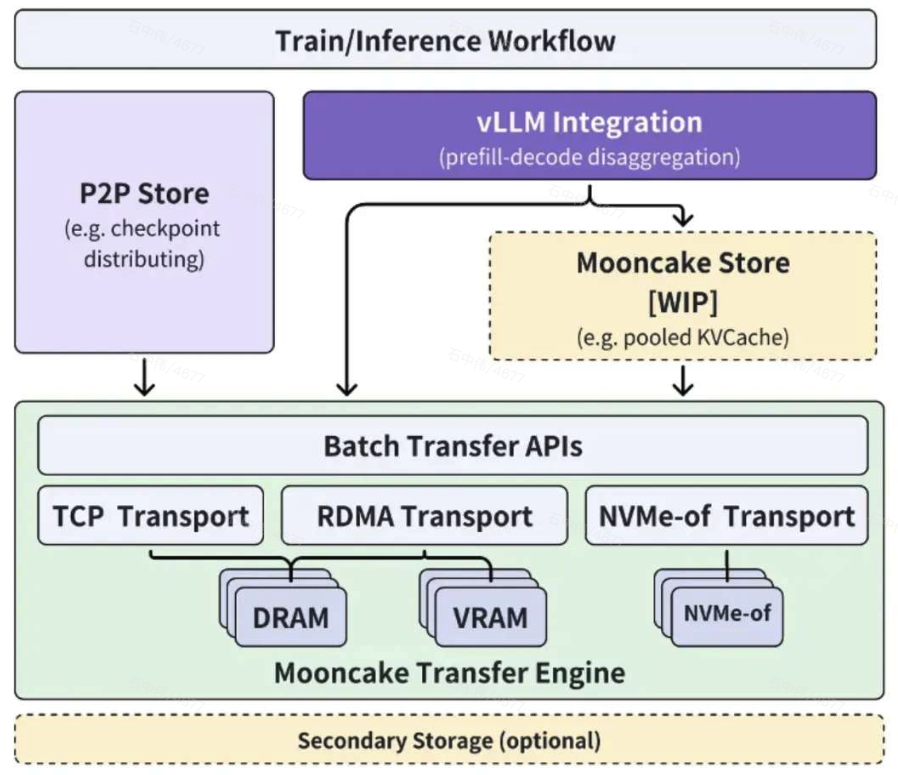
Mooncake的底层部分是传输引擎(Transfer Engine),它支持通过TCP、RDMA、基于NVIDIA GPUDirect的RDMA以及NVMe over Fabric(NVMe-of)协议进行快速、可靠和灵活的数据传输。与gloo(分布式PyTorch使用的)和TCP相比,Mooncake传输引擎具有最低的I/O延迟。 -
基于传输引擎,实现了点对点存储库(P2P Store library),支持在集群中的节点之间共享临时对象(例如,检查点文件)。它避免了单台机器上的带宽饱和。 -
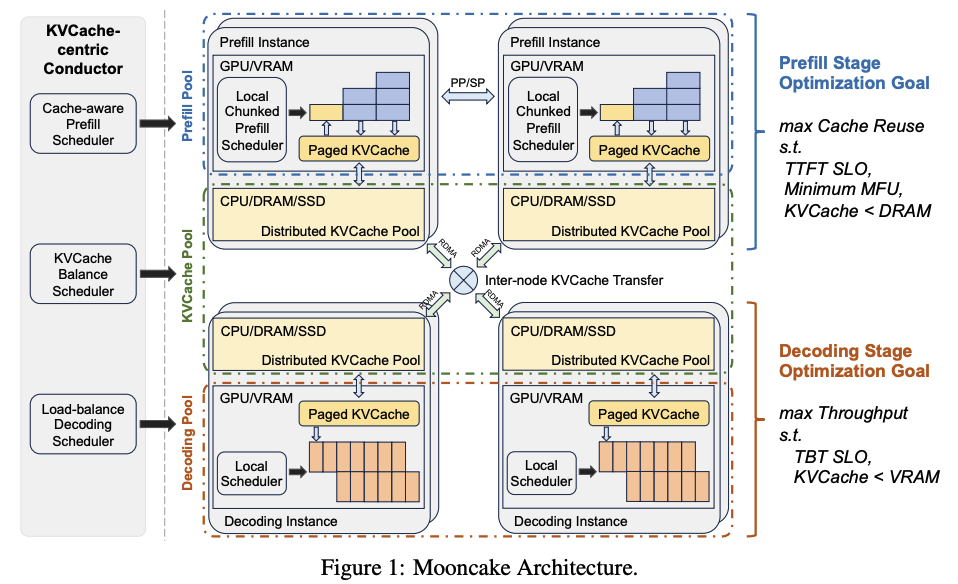
此外,修改了vLLM,以便集成传输引擎。它通过利用RDMA设备,使预填充-解码解耦更加高效。 -
未来,计划在传输引擎的基础上构建Mooncake Store,它支持池化的KVCache,以实现更灵活的预填充/解码(P/D)解耦。
https://arxiv.org/pdf/2407.00079https://github.com/kvcache-ai/Mooncake
推荐阅读
欢迎关注我的公众号“PaperAgent”,每天一篇大模型(LLM)文章来锻炼我们的思维,简单的例子,不简单的方法,提升自己。