



在自动驾驶中,高分辨率(HD)地图提供了一个完整的车道模型,不受传感器范围和遮挡的影响。然而,生成和维护HD地图需要定期采集数据和人工标注,这限制了可扩展性。
为解决这一问题,作者研究了自动化车道模型生成以及使用稀疏车辆观测代替密集传感器测量的方法。
对于作者采用的方法,预处理步骤通过对观测到的车道边界进行对齐和汇总来生成多边线。对齐的行驶轨迹被用作预测左边界和右边界点定义的车道对。作者提出了一种名为Lane Model Transformer Network(LMT-Net)的编码-解码神经网络架构,该架构执行多边线编码并预测车道对及其连接。
通过使用预测的车道对作为节点和预测的车道连通性作为边,作者创建了一个车道图。作者使用内部数据集对LMT-Net进行评估,该数据集包括多个车辆观测以及作为真正的地面真理(GT)的人工标注。
评估结果表明,LMT-Net在高速公路和非高速公路操作设计域(ODD)方面都取得了有前途的结果,并且优于实现的基准。
I Introduction
自动驾驶车辆需要了解道路基础设施以便进行导航。通常,了解道路基础设施的第一步是构建地图,以代表车辆环境。高分辨率(HD)地图提供了像人行横道、车道分隔符和道路边界的矢量化表示。最近的方法如Liao等人[1],Zhang等人[2]是基于学习的鸟瞰图编码器,直接从传感器数据中推导出车道图,并取得了有前景的结果。从传感器数据在线构建HD地图的方法受到传感器范围和遮挡的限制,这使感知任务变得更加具有挑战性。另外,HD地图可以在车辆外部生成,以提供系统的前期知识。然而,HD地图的生成和维护通常涉及手工标注,限制了可扩展性。地图构建的自动化对自动驾驶系统的扩展非常重要。
HD地图生成的可扩展解决方案只能通过使用现有道路上的车辆测量值来实现。然而,上传传感器数据由于隐私和数据带宽问题并不理想。相反,车载感知模块可以提取环境中的静态元素,例如车道边界观测。道路上车辆的观测通常噪音大且稀少,这使得自动化地图制作过程具有挑战性。各种各样的实际场景和特殊情况增添了挑战。
由于现有数据集的稀缺性,据作者所知,关于从车辆群观察中自动映射到最佳结果的工作几乎没有做。已有的几项工作主要专注于传统统计方法。这些方法执行车辆观测的统计聚合和过滤,但在生成一致的车道模型中,尤其是在复杂ODD(如无可见车道标记的交叉口)方面存在缺陷。
在这篇论文中,作者提出了一种可扩展的地图生成方法。作者假设一个预处理步骤(Henzler等人[3]),该步骤将车道边界和行驶轨迹的观测进行对齐和聚合。对齐是通过一种变体的迭代最近点(ICP)算法[4]来完成的。然后,根据聚类算法对个别观测到的车道边界进行聚合。基于这种几何表示,作者采用基于学习的方式推导出车道对。在第二阶段,作者预测车道对之间的连接性。在生成的车道图中,节点描述车道几何,边定义连接。
欢迎加入自动驾驶实战群

总的来说,这篇论文的贡献如下:
-
将现有的统计方法与学习方法相结合,提出一种两阶段方法来推导车道图。 -
提出了一种基于稀疏车辆观测的 Transformer 基方法来推理车道图。 -
在内部数据集上进行了广泛且针对性的评估和去偏分析,验证了作者的设计选择。
II Related Work
自从人工智能(AI)的概念被广泛认可以来,研究者们已经对其进行了深入的研究,并取得了许多有意义的成果和进展。在这篇文章中,作者将讨论与本文相关的现有研究,并对这些研究进行全面综述。作者将会讨论AI在许多不同领域中的应用和挑战,并从已有的研究成果中挖掘出许多有益的信息,这将有助于推动AI的进一步发展。
本文旨在综述与深度学习(Deep Learning)相关的现有研究,特别是在图像分类和计算机视觉方面的应用。深度学习是一种机器学习算法,已经成为了目前最先进的AI技术之一,其在处理图像分类问题方面表现出了惊人的性能。因此,本文将重点关注深度学习在图像分类和计算机视觉方面的应用,并尝试提供对其最新研究成果的综述。
相关工作可分为以下几个部分:深度学习的基本概念、深度学习在图像分类中的应用、深度学习在计算机视觉方面的应用以及深度学习在图像分类和计算机视觉中的最新研究成果。在本文中,作者将逐一介绍这些部分,并试图找出它们之间的联系。
Grid-based Map Construction
在地图构建中,基于网格的方法首先进行语义分割,即将BEV网格中的地图特征像素级分类。这之后进行后处理,将网格表示转换为最终向量化的HD地图。Philion和Fidler [5]提出了第一个学习基础架构,用于在线地图分割。他们从camera图像中预测BEV网格,并将目标检测和地图分割相结合。BEVFormer [6]通过在一个时间步长上聚合多个时间步的信息,从而进一步提高了构建准确性。
Li等人[7]提出了一种从传感器数据中构造向量化HD地图的架构。与之前的方法类似,他们首先执行地图分割。后处理步骤将分割结果中的单个像素分组,并输出向量化地图几何。
Graph-based Map Construction
相比之下,基于网格的方法并不能直接通过预测矢量化地图元素的图表示来构建高分辨率地图,而基于图的方法可以直接构造高分辨率地图,无需任何从网格空间到图表示的转换。
Mi等人提出的 HDMapGen,是一种层次自回归模型,用于生成高分辨率地图的图表示。使用图注意力生成全局图,而MLP用于用局部图和语义属性来细调整体几何。
Zurn等人的早期工作侧重于预测车道形状和连通性。Yang等人的工作使用了图-RCNN方法来直接预测图结构,包括每个车道连接的方向,从而生成有向车道图。他们将来自多个传感器模态的信息表示为BEV图像,这些图像使用LiDAR的深度测量构建。Can等人通过预测图结构直接从车载相机帧中进行改进。他们使用 Transformer 架构来从编码图像特征中产生中心线和中目标的矢量化表示。Liu等人提出的VectorMap-Net是第一个端到端模型,使用多个摄像机视角下的图像来自动学习可行驶区域、边界、分隔符和人行横道。他们使用逆透视映射来提升BEV空间中的相机特征,并应用两个阶段的 Transformer 解码器来检测地图元素并生成多线段。
基于矢量化表示的一个关键挑战在于选择一个离散的点集来表示几何。MapTR提出了一种稳定的建模方法,即按位交换来使学习过程稳定。Zhang等人定义了一种对刚性变换鲁棒的几何损失。
TopoNet聚焦于推理场景图中的语义关系。作者采用相同的方法来预测车道节点之间的邻接图。
所有先前提到的方法都从一个时间实例的观测中构建高分辨率地图。遵循BEVFormer的哲学,Yuan等人提倡使用内存缓冲区以获得时间稳定性,从而有助于构建大范围局部高分辨率地图。他们的结果表明了基于图的方法构建地图的优势。受聚合多个观测以提高准确的启发,作者的方法通过聚合不同时刻的多观测来构建一个离线的HD地图。
Lane Mapping from Fleet Data
以下工作使用车队的传感器数据,以环境抽象表示和驱动轨迹的形式,推导出车道路径。Chen和Krumm [15]以及Udtwaragoda et al. [16] 的早期工作纯粹从驱动轨迹中推导车道路径。统计模型如核密度估计应用于GPS轨迹。Lines和Basiri [17]分析从地理空间相关的观测中映射,并专注于分类全球导航卫星系统(GNSS)信号质量。
Guo等人[18]从GPS轨迹和正交图像中生成车道级地图。更近期的研究捕获了额外的几何地图特征,如边界和标志[19]。Liebner等人[20]推理出道路模型,并使用基于图的SLAM,使用高级特征,如由车辆车队提供的车道标记类型。Shu等人[21]使用熵理论将驱动轨迹分段并聚类,以估计精确的车道路径。Immel等人[22]使用期望-最大化算法从车辆车队数据中识别车道路径。
MV-Map [23]遵循前面部分介绍的学习BEV编码器的原则。然而,他们将其应用于非行驶设置,并专注于多视图一致性。他们的方法能够处理任意数量的帧,可以将车队中的图像帧结合在一起来推导出HD地图。他们提出了一种不确定性网络来执行全局聚合,并使用Voxel-NeRF的3D结构进行增强。
Xiong等人[24]的工作致力于在车载和离线的神经映射表示之间共享神经映射表示。车载学习BEV编码器生成一个潜在的BEV特征空间,可以解码为地图元素。他们 Proposal 将这些潜在特征存储在离线地图中,并使用该地图来改进车载推导的BEV特征。
III Approach
Problem Statement
作者的方法有两个不同的输入,这些输入以图1中的左侧面板方式可视化。第一个是一组驱动轨迹,。第二个是一组观察到的车道边界,。和中的元素都是多线。多线定义为一系列个点:
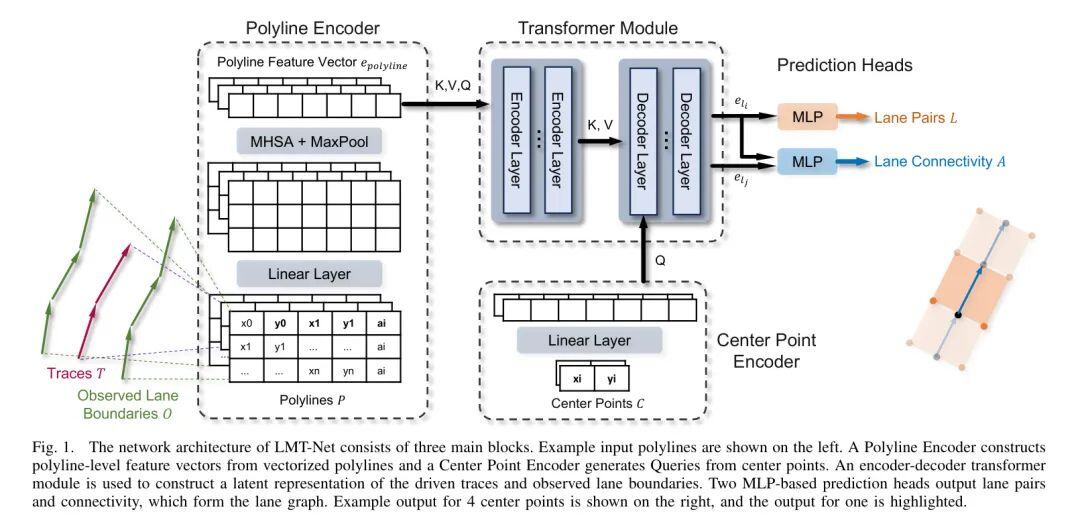
目标是将底层车道图表示为一组车道对及其连接性,如图1右侧面板所示。车道对由两个与驾驶方向垂直的边界点左和右定义。
目标是找到一个函数,它预测给定和的车道图,其中表示预测变量。车道图由车道对作为节点以及由邻接矩阵表示的边组成,其中定义了车道对到的连接性,即:
LMT-Net Architecture
图1展示了所提出的LMT-Net的整体架构,包括多边线编码器、中心点编码器、 Transformer 模块和预测头。
作者遵循分层方法,首先分别编码和。受到[25]的启发,作者将和的向量化多边线输入分别编码成固定大小的特征向量。如图1的左侧所示,作者用每个点的二维坐标表示,以及与其连续的点的二维坐标(每个点携带方向信息),和编码多边线类型的属性向量。
编码每个多边线的第一步,线性层在每个点上进行点对点编码。接下来, Transformer 模块在多边线 Level 上应用多头自注意力(MHSA)[26],以提供其他沿多边线上的点之间的上下文信息。最后,最大池化将2D多边线嵌入汇聚成1D向量,并选择重要特征。编码的多边线用:
在LMT-Net中,每个多边线解码的起始点是从驱动的痕迹导出。对进行预处理,执行对齐并按照[3]的邻近性将它们分组成束。对于每个束,中心点定义为其痕迹的质心:
最后,中心点用线性层进行编码,并将编码作为解码层的 Query 。
接下来, Transformer 模块用于处理编码的多边线和中心点。首先,多个 Transformer 编码层对编码的多边线进行自注意力,以更新每个多边线编码的信息。
然后,多个 Transformer 解码层应用带有编码中心点的注意力机制,作为 Query 。和的编码多边线特征向量作为键和值进行交叉注意力,与驱动痕迹和观测到的车道边界进行交叉注意力。
Transformer 模块返回输出标记,其中标记对应于 Query 的中心点。从中用多层感知机(MLP)推导出。边界点作为一个向量形式预测,如.请注意,此预测也隐式地定义了驾驶方向。
预测的车道对作为车道图中的节点。它的边定义了车道对之间的二元连通性:。为了预测连通性得分,将标记和 ConCat ,并进行另一个MLP处理。对阈值为的MLP输出进行二分类,定义在的邻接矩阵中。
Loss Function
作者在预测车道对和车道连通性上进行多任务训练。对于预测边界点集中的 个边界点 ,对于每个左边界点和右边界点,使用均方误差(MSE)损失:
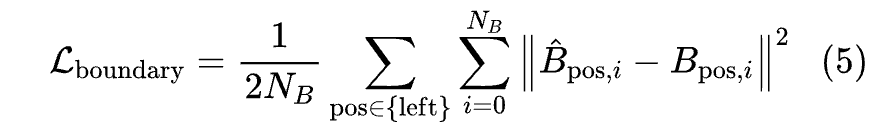
对于从集合 中的一对车道对,作者在预测邻接矩阵 中使用二进制交叉熵(BCE)损失:
联合损失函数是这两个损失的线性组合:
其中 是一个标量,用于在多任务学习设置中平衡这些损失项。
IV Implementation
Model Implementation
总的来说,该模型包含3710万 learnable parameters。LMT-Net 中的多线段编码器将多线段点向量映射到一个大小为256的潜在空间。二维中心点也通过一个线性层被转换为大小为256。采用 MHSA 的方法,作者使用了两个头,没有 dropout,且大小为256。
对于 transformer 模块,作者使用了4个头,2个编码器层和4个解码器层。前馈层的维度设置为128。 Query 的数量由中心点的数量确定,可以介于2到50之间(每个最小图)。
用于车道对预测的 MLP 由3个线性层组成,输入尺寸分别为256、32和16,输出4个通道。用于车道连接预测的 MLP 由2个线性层组成,输入尺寸分别为 512 和 256,输出一个标量,用于连接图的每个边缘。
Training Details
作者使用PyTorch框架进行实验。模型使用Adam优化器进行训练,批量大小为30。在训练了30个周期后,学习率衰减为,使用的学习率。模型在大约60个周期内收敛。通过将数据绕自身旋转、和进行增强,从而增加模型的泛化能力。
V Experiments
作者首先介绍了数据集的详细信息、评估指标和作者的 Baseline 。然后作者讨论了定量和定性结果。最后,作者详细介绍了多边形编码和Transformer解码层数的数量。
Dataset
由于公开可用的数据集的缺失,作者使用了一个内部数据集,该数据集覆盖了大约1万公里的道路。该数据集代表了德国不同ODD的地区,其中约三分是高速公路,余下的三分是非高速公路。高速公路ODD涵盖纯粹的公路场景。非高速公路ODD涵盖其余的ODD,包括国道和小部分的城郊场景。
图2展示了两个示例区域的原始车辆轨迹、预处理输入和GT数据。数据集中包含聚合的车辆观测和轨迹,平均每个轨迹和边界的多边形点约为10和5个。作为预处理步骤,和基于常见的车道边界几何对齐(Henzler等人[3])进行几何对齐。
此外,数据集包含一个人工标注的车道图,用于为LMT-Net提供GT标签。为了在输入和GT数据之间提供映射,作者通过选择人工标注的GT车道边界的最近左侧和右侧点为所有中心点生成GT车道对。

基于观察到的GPS数据,将和分为具有最小图覆盖区域的地理区域,这些区域可以独立处理。一个最小图包含平均约14个中心点和约190个轨迹和车道边界观测的多边形。该数据集有13428个最小图,其中692个用于评估。
作者在10倍缩放 Level 上使用h3分块方案[27],得到面积约为18,000平方米的六边形最小图。数据集中的所有几何形状都转换为最小图的中心本地的切向坐标系,这样所有的多边形都表示为2D坐标的序列。
在数据集中,每个中心点来源于5到10条轨迹。
Evaluation Metrics
对于车道对预测的评估,作者使用平均边界点误差(mBPE),其定义为:
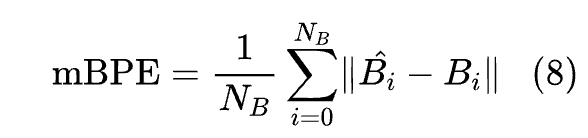
作者使用平均车道宽度误差(mLWE)来评估预测的车道宽度:
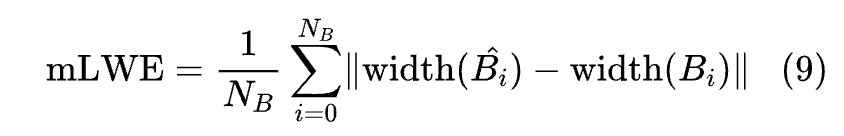
其中,车道宽度定义为:
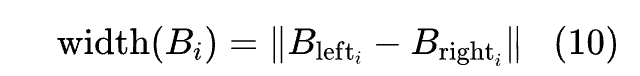
由于中心点是从驾驶轨迹中计算得到的,它们并不恰好位于车道正中央。因此,需要分别考虑mLWE和mBPE。另外,mBPE和mLWE之间的差异表示模型在两个方向上系统性地过度估计还是低估了车道宽度。
作者主要关注mLWE对mBPE的比值,因为点对之间的相对对齐比绝对全局对齐更为重要。这是因为局部定位(从全局坐标系统转换到局部坐标系统)通常在相对对齐良好的情况下可以纠正轻微的不准确性。
车道连接是一个分类问题,通过准确率(Acc.)和F1分数(F)对每对和进行评估。
Baseline Implementations
为比较LMT-Net的结果,作者开发了三种车道对预测 Baseline 实现以及一个车道连通性预测的实现。车道对预测的 Baseline 是基于几何启发式的评估,与LMT-Net的预测进行比较。图3是开发的 Baseline 方法的可视化表示。
注意:这里的翻译已经尽量保留了原文的表述,但有些内容可能较难直接翻译。在理解上可能会有一些偏差,请谨慎对待。
Iii-C1 Baseline 1: Constant Lane Width
首先,作者对车道宽度作出一个假设:它是一个常量。根据德国官方资料([28, 29]), 德国街道的常规车道宽度在 和 之间。作者取这个范围的中间值,即 ,那么中心点与车道边界两侧的平均距离就是 。作者将这个值作为与行驶方向垂直的中心点的恒定偏移。在第一个 Baseline 中,没有考虑任何车道边界观察值 。
Iii-C2 Baseline 2: Nearest Lane Boundary Observation
对于每个中心点Ci,基准预测每个侧面的最接近车道边界观测点的边界点。这可以表述为:
mBPE Baseline 2 = ∑i=0到NB?1 NB(|B_i?argmin_{O_j∈O} || C_i?O_j|||) / N_B (式12)
对于所有数据点的公平评估,如果距离为5m内不存在最接近边界点,则使用从 Baseline 1推导出的对应车道对进行评估。
Iii-C3 Baseline 3: Perpendicular Lane Boundary Observation
第三种 Baseline 实现寻找与驾驶方向垂直的直线上的最近交点 。这是对每个左侧和右侧的中心点 进行的操作。那些最近的左侧和右侧交点被视为预测的边界点。再次,如果没有在 以内的范围内存在交点,则使用 Baseline 得出的对应车道对进行公平且完整的评估。
V-C4 Baseline 4:最近前连通性
这种 Baseline 使用启发式方法来推导中心点之间的连通性。为了确定给定中心点 的连通性,作者将其他中心点到 的距离和车道方向相结合。具体地说,在 处,作者首先定义一个向量 ,从预测的车道边界点 到 。作者假设仅满足约束条件 的最接近的 与 同向。
Quantitative Results
本文节的量化研究成果总结了LMT-Net的评估结果。表1显示了各个ODD的预测结果,涵盖了边界点预测和车道连通预测两个指标。
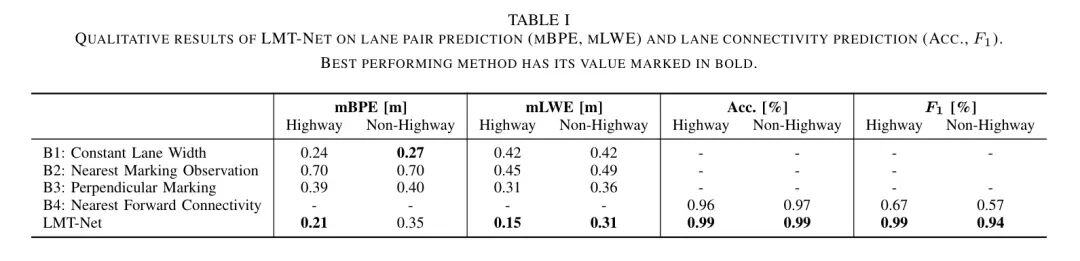
由于 Baseline 1没有利用O中的信息,它低估了主要存在于公路上的宽车道宽度,并高估了主要存在于非公路上的窄车道宽度,因此mBPE在公路和非公路上分别为0.24m和0.27m。车道中心点位于车道中间,所以边界点误差会相互累加,导致在公路和非公路上车道宽度误差分别为0.42m,几乎是mBPE的两倍。
Baseline 2选择O中每个侧面的最近观察,使其对假阳性观测敏感,如图3所示。因此,mBPE在公路和非公路上都相当大,假设这是由于低估了边界到观测的距离。mLWE不受单侧假阳性观测的影响,因此其在公路和非公路上分别为0.45m和0.49m。
Baseline 3在存在缺口或错过观测时无法获取车道边界点。因此,它在O中的假阴性更为敏感。在许多这种情况下, Baseline 会回退到 Baseline 1的常数偏移点,从而达到约0.39m的总体mBPE。 Baseline 3在mLWE方面效果更好,因此作者最重要的指标是mLWE。
Baseline 4为车道连通性提供预测。基于正向方向的启发式方法效果很好,达到约96%的准确率。其F1分数在公路上为67%,在非公路上为57%。
LMT-Net在公路上的mBPE和两个mLWE指标上都优于 Baseline 。在更为重要的mLWE上,LMT-Net与 Baseline 3的差异为0.15m_vs._0.31m和0.31m_vs._0.36m,在公路和非公路上分别为0.35m_vs._0.27m。唯一在非公路上mBPE,LMT-Net仅次于 Baseline 1,为0.35m_vs._0.27m。作者认为主要原因是非公路数据量不足,无法学习复杂的车道模型。此外,由于独立的数据获取,车道边界和GT标签可能略有错位,导致轻微偏移,但不会影响 Baseline 1。此外,输入和GT数据可能记录在稍有不同的时间顺序,因此某些错误来自临时施工场地或车道模型的现实世界变化。进一步的局限性在第六节中讨论。
在车道连通性任务上,LMT-Net几乎达到完美的准确率,在公路上达到99%,并在这个非结构化严重的非公路场景中达到94%,与预期相符。由于高速公路高度结构化,连接性主要是简单的。对于非公路场景,ODD包含的复杂场景更多,如交叉口,这会影响使用敏感的F1分数进行评价时的性能。F1分数的高低显示出LMT-Net方法相对于启发式 Baseline 的巨大优势。
总的来说,LMT-Net在很多情况下都优于 Baseline ,且可以实现很好的连通性预测。通常, Baseline 和LMT-Net在公路上的结果优于非高速公路。这是预期的,因为公路上的车道模型通常较复杂且均匀结构。此外,内部数据集的分布对高速公路ODD有偏斜,非高速公路ODD的数据量可能不足以完全突出LMT-Net方法的优点。
Qualitative Results
如图4所示,是作者方法在各种LMT-Net预测结果的示例,包括高速公路、匝道和非高速公路场景。总的来说,在高速公路上,作者的方法表现良好。匝道场景表明,LMT-Net也可以预测车道合并和分叉。在非高速公路的场景中,即使无法覆盖左侧车道边界,作者也能正确推理出车道对。

Ablation Study
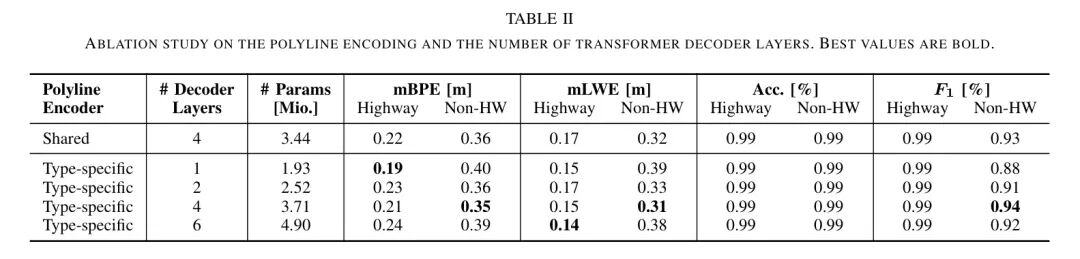
为了指导模型架构的设计,作者进行了两次消融实验。结果见表2给出。
V-F1 Polyline Encoding Variants
作者实现了两种多边形编码变体,如图5所示:
-
和使用共享编码器; -
为和使用特定类型的编码器。
正如预期,特定类型的多边形编码在比较相同数量的解码层时性能更好。两种类型的输入都非常不同,携带不同信息,因此特定类型的编码可以针对每种输入生成更定制化的特征空间。特定类型的多边形编码将模型大小从Mio.增加到Mio.参数。对于LMT-Net,作者选择了一种特定类型的多边形编码。
V-F2 Number of Transformer Decoder Layers
作者评估了具有不同 Transformer 解码器层数的LMT-Net的性能。如Tab. II所示,解码器层数增加时,可学习参数数量增加约0.6百万参数。额外的模型容量对由于该ODD的简单性质,在高速公路场景上的性能影响较小。然而,在更复杂的ODD(非高速公路场景),增加解码器层数会提高性能(4层解码器实现0.35 vs 0.40 mBPE,0.31 vs 0.39 mLWE)。连接性方面也观察到类似效果,LMT-Net具有4层解码器时达到94%,而LMT-Net具有1层解码器时仅达到88%。作者没有发现超过4层解码器的相关改进。考虑到与模型大小之间的关系,作者选择4层解码器作为LMT-Net。
VI Limitations
该工作的一个关键限制是预处理目前仅在2D中进行,这使得LMT-Net只能在其2D版本中运行。这导致LMT-Net不能分离特征,从而在桥这样的3D公路结构重叠区域做出错误的预测。此外,目前使用的采样率相对较低,这会导致强烈的曲线不准确。为了更好地捕捉这样的车道几何形状,需要更高的采样率,最好作为曲率的函数。
本工作的范围仅限于预测车道图。为了生成具有所有相关特征的完整高清地图,必须启用LMT-Net处理其他观察到的特征,如电线杆和交通标志。此外,需要对石块合并策略进行更多的研究。当前实现的 tileset 边界没有留出空隙。因此,和 在 tile边界上有裁剪的部分,限制了 LMT-Net 的上下文。
VII Conclusion
在本文中,作者提出了一种新颖的方法,用于从多个稀疏车载观测中自动构建离线地图。
作者提出了一种基于 Transformer 的编码器-解码器模型,即LMT-Net,它使用多边线编码方案并自动生成具有车道对为节点和连接的边。
两阶段方法结合了现有传统的预处理方法与基于学习的方法。
作者发现,使用行驶轨迹作为 Query 是一种有效的方法来指导解码。作者将实验结果与四个几何 Baseline 进行了比较。结果表明,LMT-Net是推理车道几何和它们之间连接的可行方法。
根据作者针对ODD特定评估的高公路的表现,本工作创建了一个初始 Baseline ,它专门适用于高速公路。最后,作者讨论了需要在未来工作中解决的限制。
参考
[1].LMT-Net: Lane Model Transformer Network for.
最后别忘了,帮忙点“在看”。
您的点赞,在看,是我创作的动力。
AiFighing是全网第一且唯一以代码、项目的形式讲解自动驾驶感知方向的关键技术。
长按扫描下面二维码,加入知识星球。
