
“Financial News-Driven LLM Reinforcement Learning for Portfolio Management”


论文地址:https://arxiv.org/pdf/2411.11059
摘要
强化学习(RL)在金融交易中实现动态策略优化。本研究将大语言模型(LLM)衍生的情感分析整合进RL框架,以提升交易表现。实验对象包括苹果公司(AAPL)单股交易和ING Corporate Leaders Trust Series B(LEXCX)组合交易。情感增强的RL模型在净资产和累计利润上优于不含情感的RL模型。在组合交易实验中,情感增强模型超越了LEXCX的买入持有策略。结果表明,结合定性市场信号可改善决策,弥合定量与定性交易方法的差距。
简介
强化学习(RL)在金融交易中逐渐受到重视,能够根据序列决策优化交易策略,但缺乏对市场情绪等定性因素的考虑。整合情感分析与RL可弥补这一缺陷,利用大型语言模型(LLMs)提取金融新闻中的情感信息,转化为RL模型可用的结构化数据。本研究旨在证明情感分析能提升RL算法在交易和投资组合管理中的表现。初步开发了基于单一股票(AAPL)的基线RL交易算法,并与加入情感输入的模型进行比较。进一步扩展至基于ING Corporate Leaders Trust Series B(LEXCX)股票的多元化投资组合,比较情感增强的RL模型与标准RL模型及原LEXCX投资组合的表现。
相关研究
强化学习(RL)在金融交易中表现出色,能够在动态市场条件下优化交易策略,已在单一股票和多元化投资组合管理中取得成功。RL方法如深度Q学习和策略梯度法已被应用于模拟真实交易场景,但通常仅依赖价格和成交量数据,限制了对市场信号和情绪变化的考虑。情绪分析通过量化新闻、社交媒体和分析师报告中的情绪,增强了交易策略的有效性,能够预测短期价格波动并与市场波动性相关联。大型语言模型(LLMs)如GPT和BERT提升了情绪分析的准确性,能够提取与金融相关的上下文特定情绪。目前文献中缺乏将LLM驱动的情绪分析与RL模型结合用于投资组合管理的研究,本研究旨在填补这一空白,探讨如何通过情绪分析提升RL模型的表现。
方法
交易强化学习算法
交易强化学习(RL)算法旨在平衡灵活性、奖励优化和交易成本,模拟交易决策。自定义环境与OpenAI Gym兼容,定义了动作空间(买、卖、持有)和观察空间(金融信息)。
动作空间为连续二维,包含:
-
动作类型:0-2的标量,<1为买,1-2为卖,=1为持有。
-
动作量:0-0.5的标量,表示交易的比例。
动作选择后,算法根据当前余额和持股量计算买卖数量,动态调整市场暴露。
奖励函数包括:
-
利润奖励:基于账户余额变化。
-
稳定性惩罚:鼓励账户余额稳定,减少波动。
-
交易成本惩罚:模拟交易费用,减少不必要交易。
最终奖励结构促进盈利、稳定和成本最小化,帮助代理学习负责任的交易策略。
结合情感分析
将情感分析融入强化学习算法,使交易代理考虑市场情感,增强决策过程的定性维度。情感数据从金融新闻中提取,映射为[-1,1]的量化值,附加到观察空间中,与传统金融指标结合。情感分数影响交易行为:正面情感增加买入量,负面情感增加卖出量,调整幅度为0.1倍情感分数。奖励函数调整:增加情感对齐奖励,若情感分数与价格走势一致,代理获得额外奖励;在高波动期减少此奖励。该机制鼓励代理在情感驱动市场中进行与情感一致的交易,优化盈利能力和情感敏感性。
项目组合管理的扩展
强化学习(RL)算法扩展至投资组合管理,需考虑个别资产情绪和市场条件,优化整体净值。
观察空间为矩阵形式,包含每个资产的价格数据、账户信息和情绪数据。
-
价格数据:最近五个时间步的开盘、最高、最低、收盘价和成交量,经过归一化处理。
-
账户信息:当前持仓、余额和成本基础。
-
情绪数据:每个股票的情绪评分,范围[-1,1]。
动作空间允许对每个资产独立操作,动作值范围为0到2,分别表示“买入”和“卖出”。情绪数据影响买卖决策,正面情绪增加买入量,负面情绪增加卖出量。
奖励函数优化投资组合净值,包含:
-
投资组合净值变化作为主要奖励。
-
情绪一致性奖励,鼓励与情绪和价格趋势一致的交易。
-
波动性调整,降低在高波动市场中情绪的权重。
多部分奖励结构促进最大化净值,同时考虑情绪洞察和交易成本。
实验
数据预处理
数据预处理包括收集定量股市数据和定性情绪数据,应用于单只股票交易(苹果公司AAPL)和投资组合交易(ING Corporate Leaders Trust Series B)。单只股票交易模型获取了AAPL的历史日交易数据(开盘、最高、最低、收盘、成交量),投资组合交易则收集了LEXCX中各股票的数据。使用Yahoo Finance API收集2023年11月16日至2024年11月10日的数据,保存为单独的CSV文件。通过Finnhub API获取每日相关新闻,使用OpenAI的LLM生成每日情绪评分,分类为五种情绪(极度负面、负面、中性、正面、极度正面)。将价格数据和每日情绪评分按日期合并,缺失情绪值用中性评分填充,形成RL模型的输入数据集。该数据集结合了定量价格数据和定性情绪信息,增强了RL代理的市场响应能力。
实验设计
实验设计评估强化学习(RL)代理在模拟股票交易环境中的表现。测试了两种设置:单一股票交易模型(苹果公司AAPL)和基于投资组合的交易模型(LEXCX),后者结合了情感分析。成功指标包括净值、余额和多轮次的累计利润,比较了有无情感整合的效果。投资组合实验与实际LEXCX投资组合表现进行基线比较,使用相同的初始投资额。评估RL算法相对于标准买入持有策略的整体有效性。
个股投资实验
开发了一个自定义环境,使用OpenAI Gym模拟苹果公司(AAPL)的交易条件,目标是最大化净资产。环境初始化包含AAPL的历史日交易数据,观察空间包括股票的开盘、最高、最低、收盘价和成交量,以及账户余额、成本基础和净资产。动作空间为二维连续空间,允许代理决定买入/卖出/持有及交易数量,灵活调整投资规模。奖励函数鼓励盈利和稳定,考虑净资产增长并惩罚过度波动,交易时收取小额费用以抑制高频交易。模型使用近端策略优化(PPO)训练20,000个时间步,评估100个回合,每个回合2,000个时间步,记录最终净资产、余额和累计利润,计算平均表现以评估模型的稳健性。
投资组合实验
实验将单一股票交易扩展至多元化投资组合,聚焦于ING Corporate Leaders Trust Series B (LEXCX),并结合情感分析。环境设置允许RL代理对LEXCX组合中的每只股票独立做出买入、持有或卖出的决策,观察空间包括每只股票的五天交易数据和账户指标。RL代理的观察空间包含价格和情感信息,行动空间允许对每只股票进行灵活操作,基于市场环境和情感变化动态调整持仓。奖励函数鼓励稳定的投资组合增长,惩罚高频交易,并根据情感与实际价格趋势的对齐进行额外奖励调整。基准比较通过计算LEXCX组合的实际表现,评估RL代理的主动交易决策相对于被动投资的增值潜力。RL模型使用近端策略优化(PPO)训练20,000个时间步,评估100个回合,每个回合2,000个时间步,收集关键绩效指标以评估策略适应性。
结果
实验结果分为两个部分:单一股票交易实验(AAPL)和投资组合交易实验(ING Corporate Leaders Trust Series B)。每部分分析了不含情感整合的RL模型和情感增强RL模型。评估关键指标包括净值、累计利润和余额,跨越多个回合和时间步。投资组合实验中,RL模型的表现与LEXCX投资组合的实际表现进行比较。可视化展示了模型适应市场动态和利用情感数据改善决策的能力。
个股投资
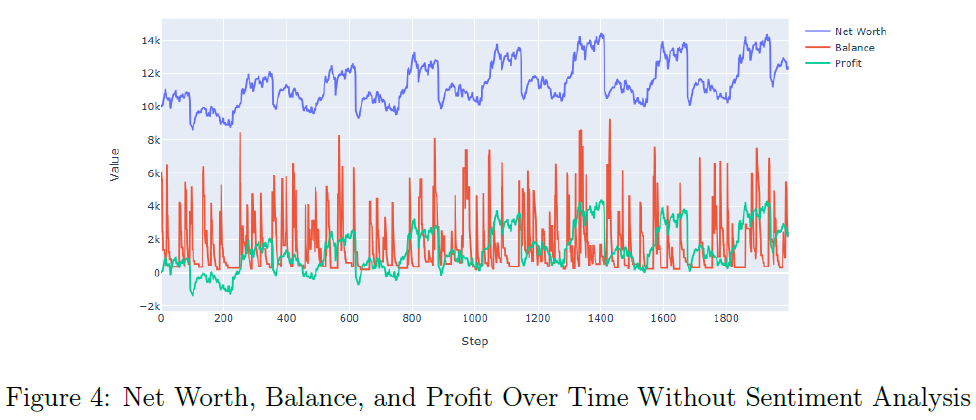
无情感分析的RL模型在100个评估回合中,平均净值为$10,825.41,平均利润为$825.41,显示出其在单一股票交易中的有效性。RL模型的净值、余额和利润在单一回合中表现稳定,显示出资本的有效利用。无情感分析的RL代理的净值和利润分布较窄,表明其决策能力强且表现可靠。
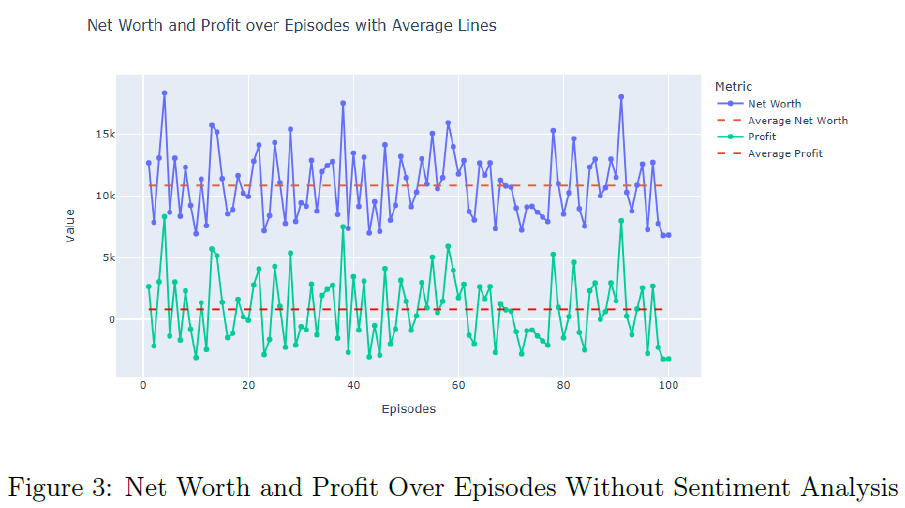
加入情感分析后,RL模型的平均净值提升至$11,259.51,平均利润为$1,259.51,显示出利用定性数据的优势。情感增强的RL代理在单一回合中表现更佳,能够更好地与市场情感对齐,获得更高的累计收益。情感增强的RL代理的净值和利润分布中位数明显提高,强调了情感数据在交易策略中的价值。
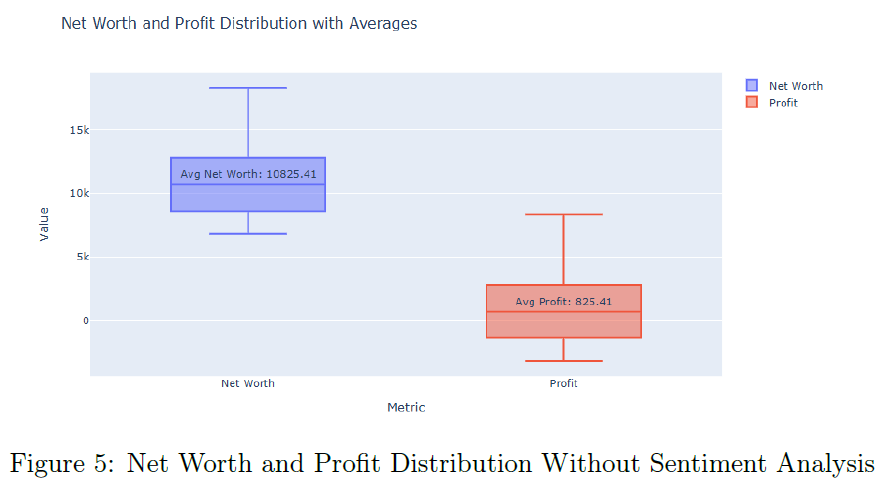

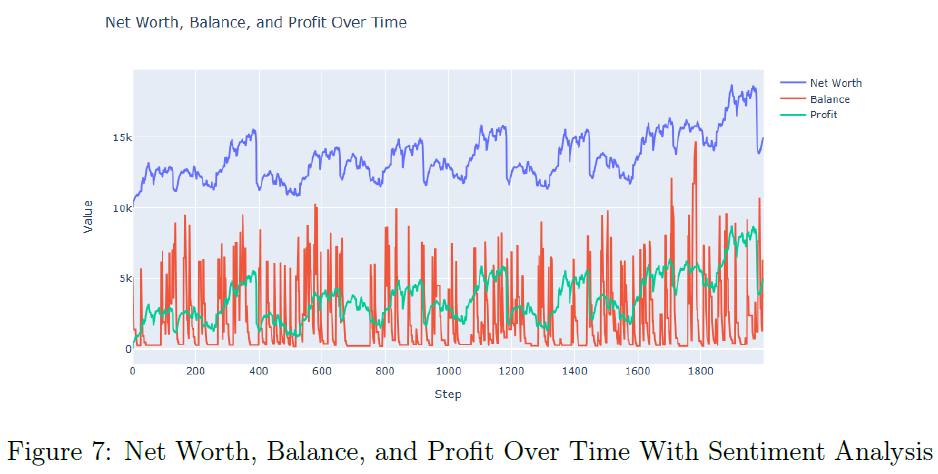
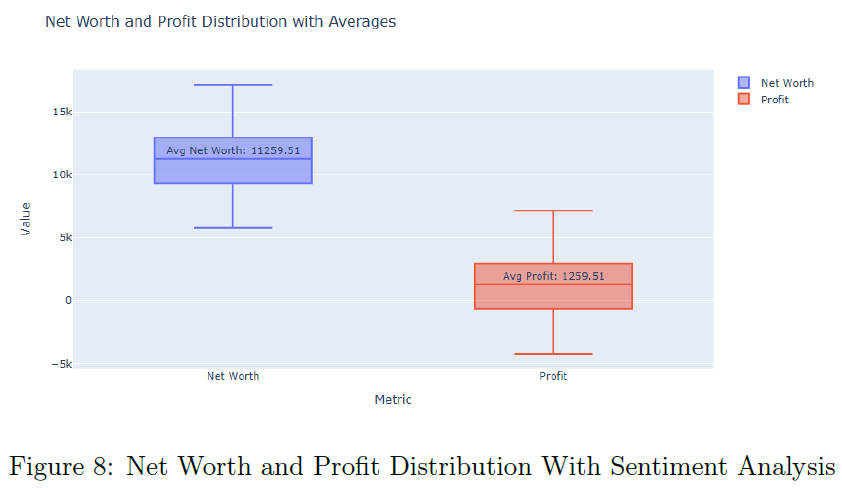
表1总结了三种场景下的平均利润和净值,显示出RL代理在整合情感数据后的优越表现。

投资组合
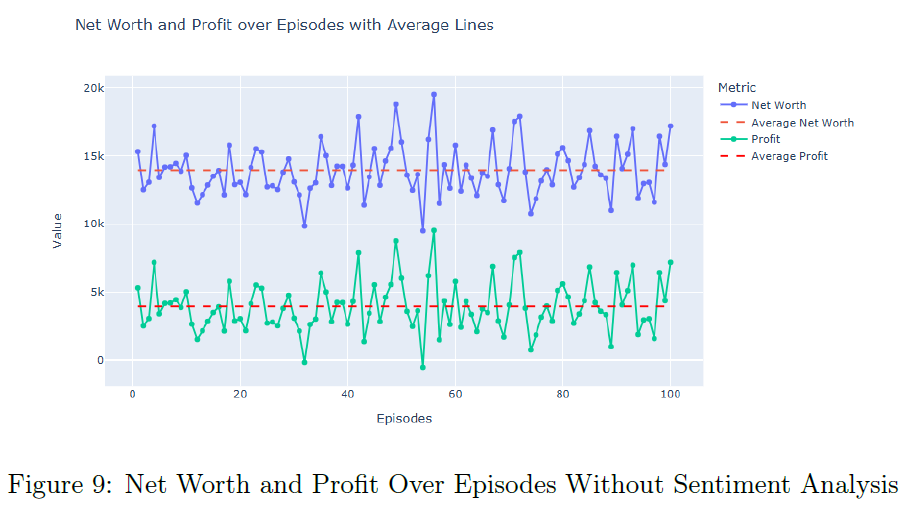
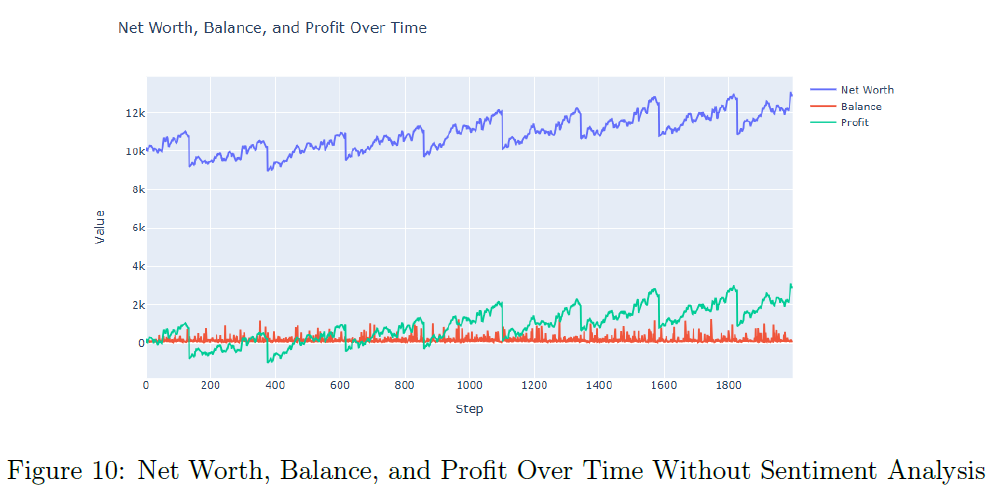
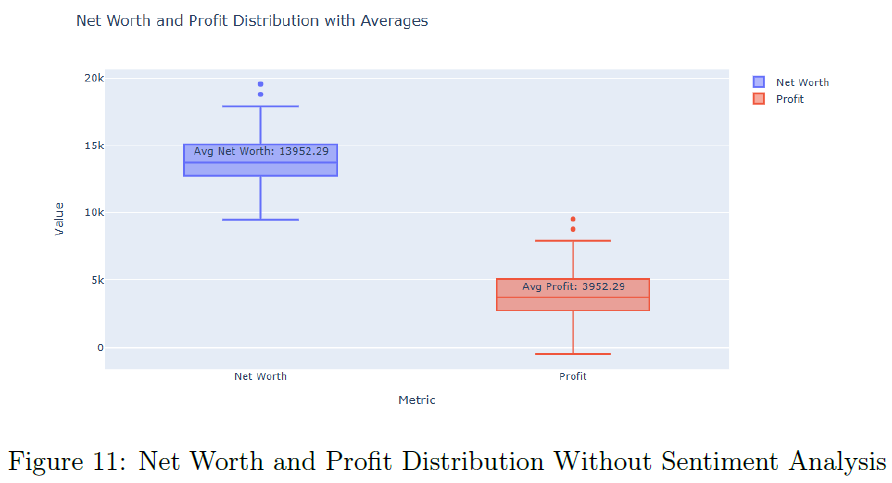
无情感分析的RL模型在100个评估回合中,平均净值为$13,952.29,平均利润为$3,952.29,表现稳定。单个回合中,RL代理的净值持续增长,保持稳定的余额和累积利润。净值和利润的箱形图显示,所有评估回合的中位数与平均值接近,表现稳定。
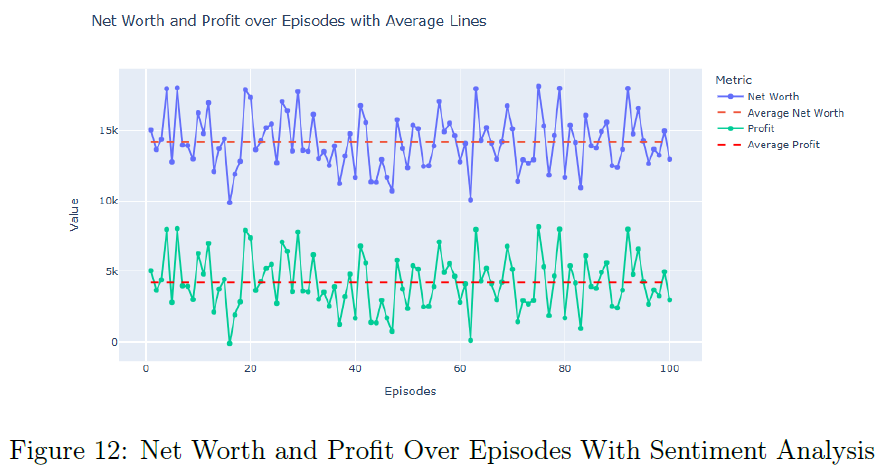
加入情感数据的RL模型平均净值为$14,201.94,平均利润为$4,201.94,显示出情感数据的价值。情感增强的RL模型在单个回合中表现更强,能够更好地把握盈利交易。情感增强模型的净值和利润分布显示出更高的中位数,强调情感数据的优势。与实际LEXCX投资组合相比,RL代理的表现更优,特别是情感增强模型,显示出其动态投资管理的潜力。
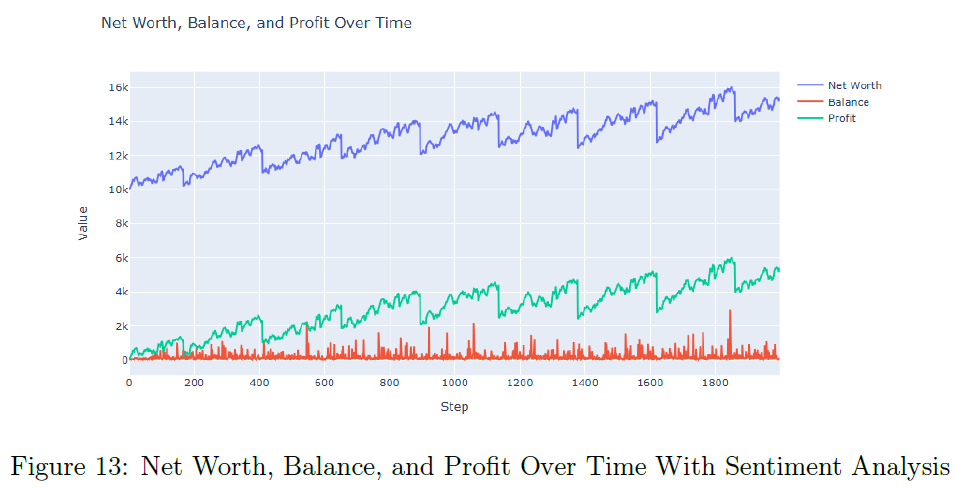
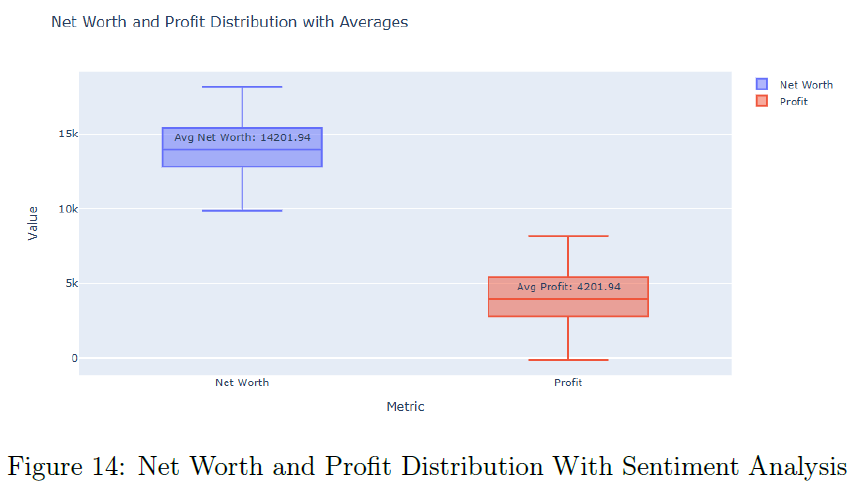
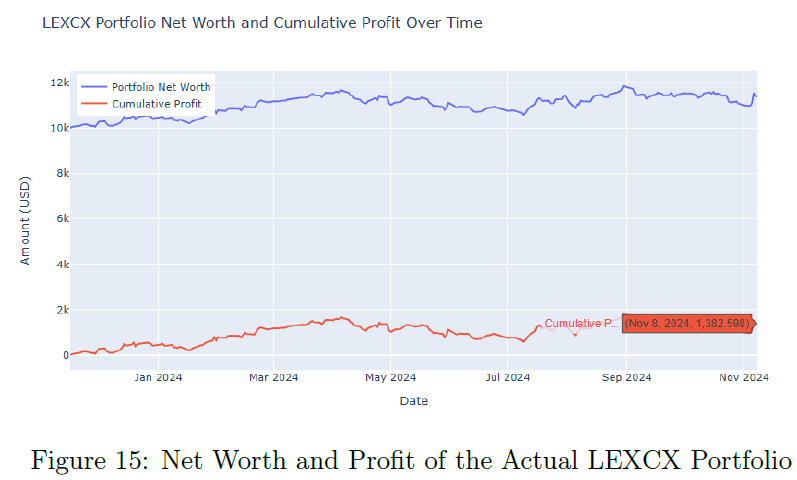
表2总结了三种场景下的平均利润和净值,强调RL代理的优越表现。

讨论
强化学习(RL)在金融交易中表现出色,尤其是结合情感分析时,能有效提升交易结果。在苹果公司(AAPL)的单股实验中,RL代理在市场动态中表现稳定,情感分析进一步提高了平均净值和利润。在投资组合实验中,情感增强的RL模型超越了实际的LEXCX投资组合,显示出主动交易的优势。结合定量和定性数据的情感增强RL模型,能够更好地把握市场趋势,适应变化。
研究表明市场情感影响资产价格和波动,情感数据帮助RL代理捕捉更广泛的市场动态。尽管结果乐观,但实验使用历史数据,未完全模拟真实市场条件,未来需考虑滑点和交易成本。当前情感数据依赖于聚合情感评分,未来可探索更复杂的情感提取技术。未来研究可扩展至更大和多样化的投资组合,以验证情感驱动交易策略的普适性。
总结
本研究探讨了强化学习(RL)在金融交易中的应用,分别针对单只股票(苹果公司AAPL)和投资组合(ING Corporate Leaders Trust Series B,LEXCX)进行实验。通过整合来自金融新闻的情感分析,RL模型在交易表现上显著优于仅依赖定量数据的模型,显示出定性市场信号的潜力。
单只股票实验中,情感增强的RL模型实现了更高的净值和累计利润,证明情感数据在提高交易准确性方面的价值。投资组合实验中,情感增强模型超越了不含情感的RL模型和实际LEXCX投资组合,展现了其适应性和盈利能力。RL代理,尤其是结合情感分析的模型,持续超越被动投资策略,显示出动态投资组合管理的潜力。
研究指出未来工作需解决的局限性,包括情感分析依赖于聚合新闻数据,建议引入实时社交媒体情感分析。未来研究可探索超参数调优、迁移学习及模型在不同市场周期的鲁棒性。研究强调结合RL与情感分析在金融交易中的变革潜力,为投资者优化交易策略提供了强大工具。
我们致力于提供优质的AI服务,涵盖人工智能、数据分析、深度学习、机器学习、计算机视觉、自然语言处理、语音处理等领域。如有相关需求,请私信与我们联系。
请加微信“LingDuTech163”,或公众号后台私信“联系方式”。
关注【灵度智能】公众号,获取更多AI资讯。