
收录于话题
2024年11月28日arXiv cs.CV发文量约150余篇,减论Agent通过算法为您推荐并自动化整理为卡片供您参考,预计为您节省65分钟浏览arXiv的时间。
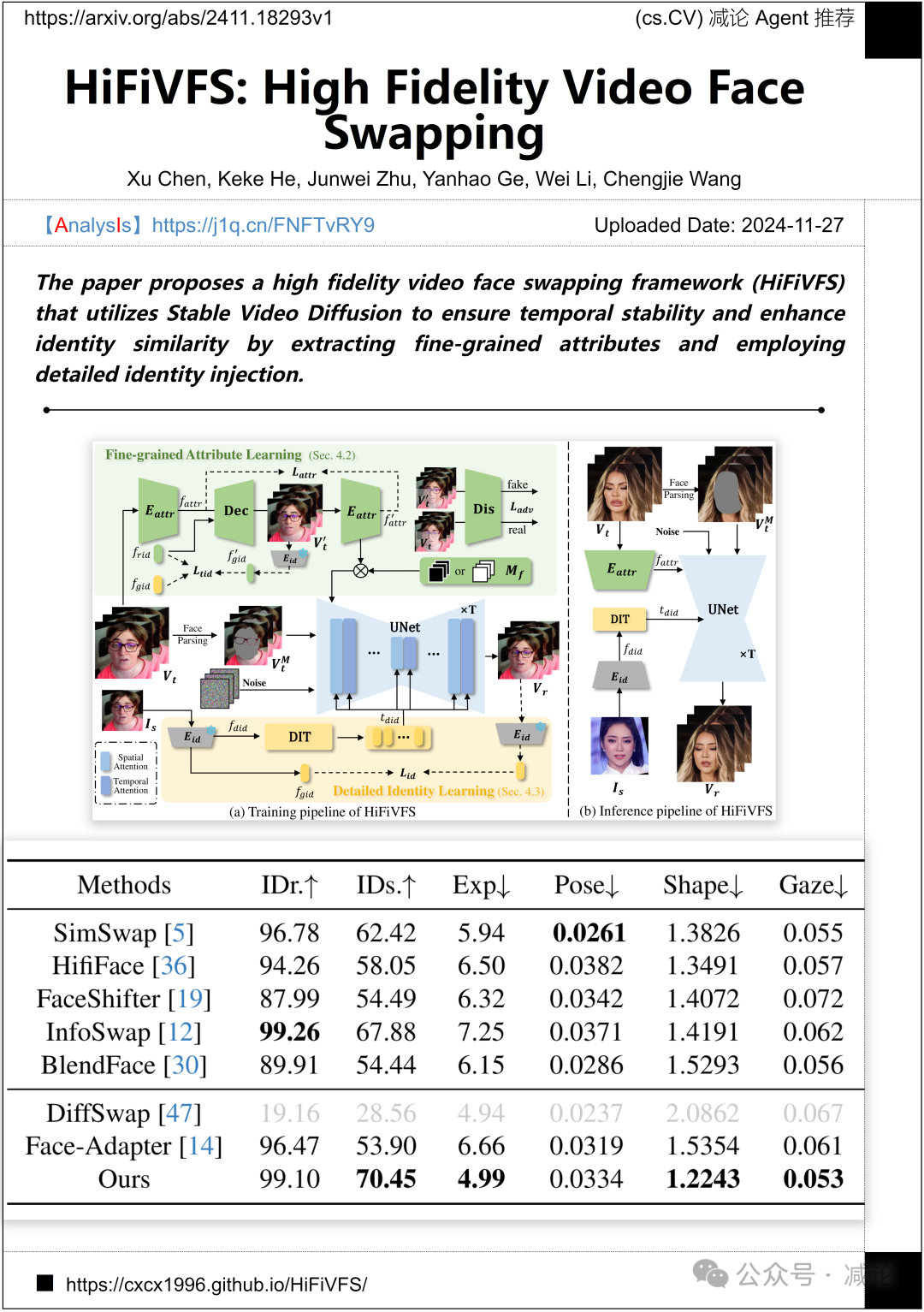

腾讯和VIVO提出了一种高保真视频人脸交换框架(HiFiVFS),该框架利用稳定视频扩散技术确保时间稳定性,同时通过提取细粒度属性和详细身份注入增强身份相似性。
【Bohr精读】
https://j1q.cn/FNFTvRY9
【arXiv链接】
http://arxiv.org/abs/2411.18293v1
【代码地址】
https://cxcx1996.github.io/HiFiVFS/
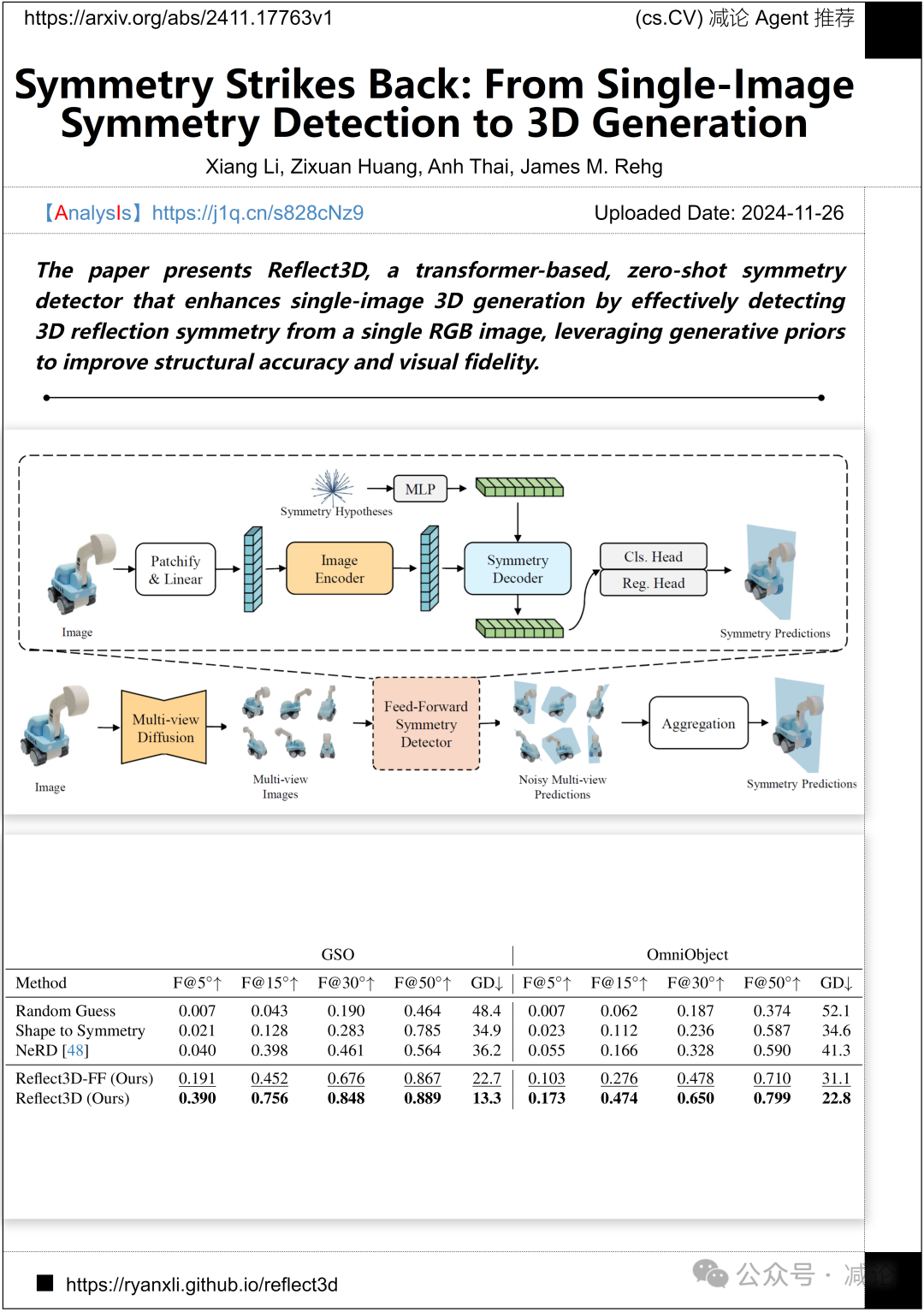
伊利诺伊大学厄本那–香槟分校与乔治亚理工学院联合提出了Reflect3D方法,这是一种基于transformer的零样本对称检测器。该方法通过单个RGB图像有效检测3D反射对称性,利用生成先验提高结构准确性和视觉逼真度,从而增强单图像3D生成。
【Bohr精读】
https://j1q.cn/s828cNz9
【arXiv链接】
http://arxiv.org/abs/2411.17763v1
【代码地址】
https://ryanxli.github.io/reflect3d

上海人工智能实验室与北京大学提出了GeneMAN框架,通过结合特定于人的扩散模型、几何初始化与雕刻流程以及多空间纹理优化流程,从单张自然环境图像中重建高保真3D人体模型。该方法有效解决了身体比例、个人物品和纹理不一致等问题。
【Bohr精读】
https://j1q.cn/dpHBK5GU
【arXiv链接】
http://arxiv.org/abs/2411.18624v1
【代码地址】
https://roooooz.github.io/GeneMAN/
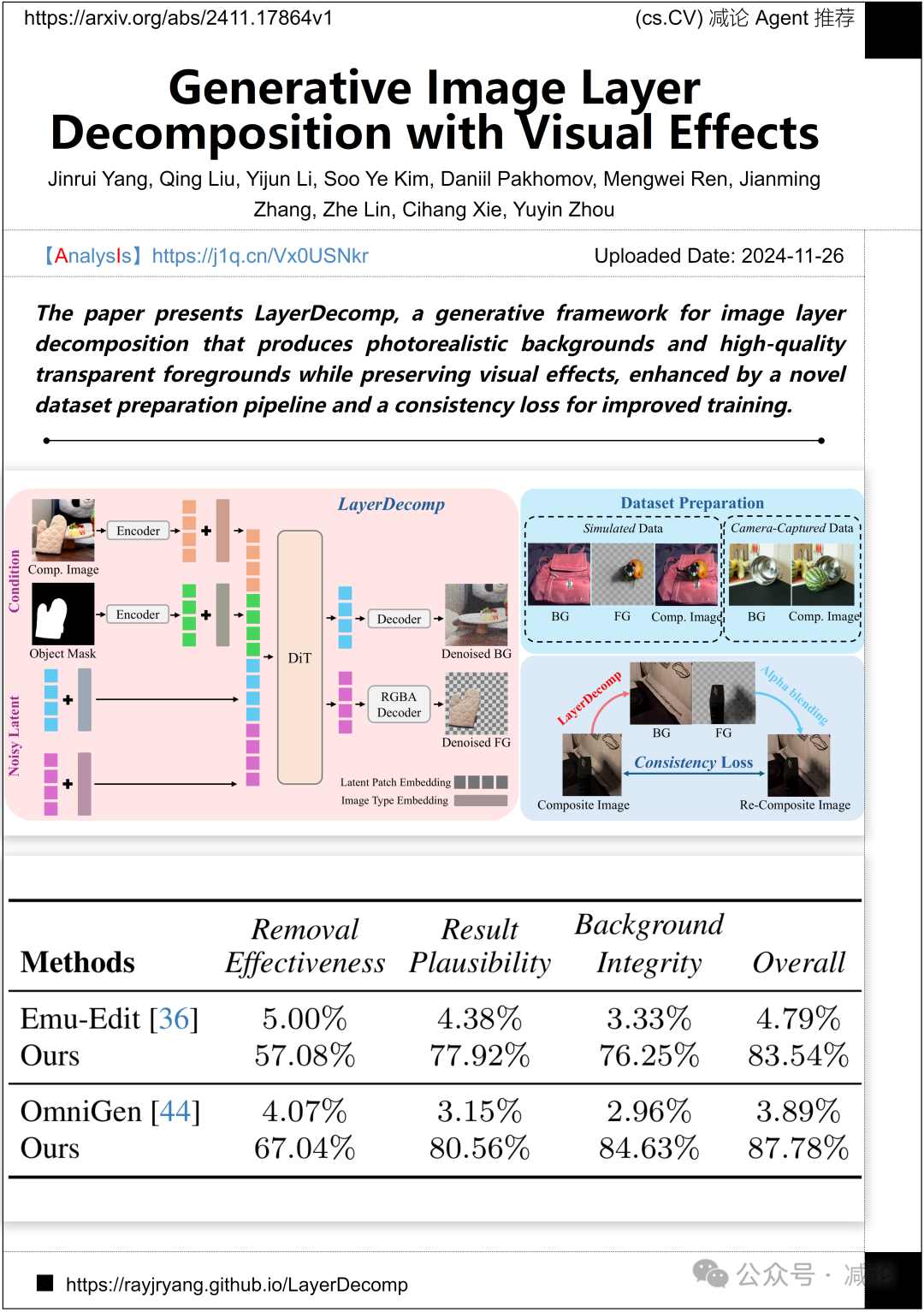
加州大学圣克鲁兹分校与Adobe研究提出了LayerDecomp方法,用于图像层分解。该方法生成逼真的背景和高质量的透明前景,保持良好的视觉效果。论文中还引入了新颖的数据集准备流程和一致性损失,以增强训练效果。
【Bohr精读】
https://j1q.cn/Vx0USNkr
【arXiv链接】
http://arxiv.org/abs/2411.17864v1
【代码地址】
https://rayjryang.github.io/LayerDecomp

斯坦福大学提出了扩散自蒸馏方法,利用预训练的文本到图像扩散模型生成数据集,用于文本条件的图像到图像任务,实现了无需测试时优化的微调身份保留生成。
【Bohr精读】
https://j1q.cn/0IavttAl
【arXiv链接】
http://arxiv.org/abs/2411.18616v1
【代码地址】
primecai.github.io/dsd
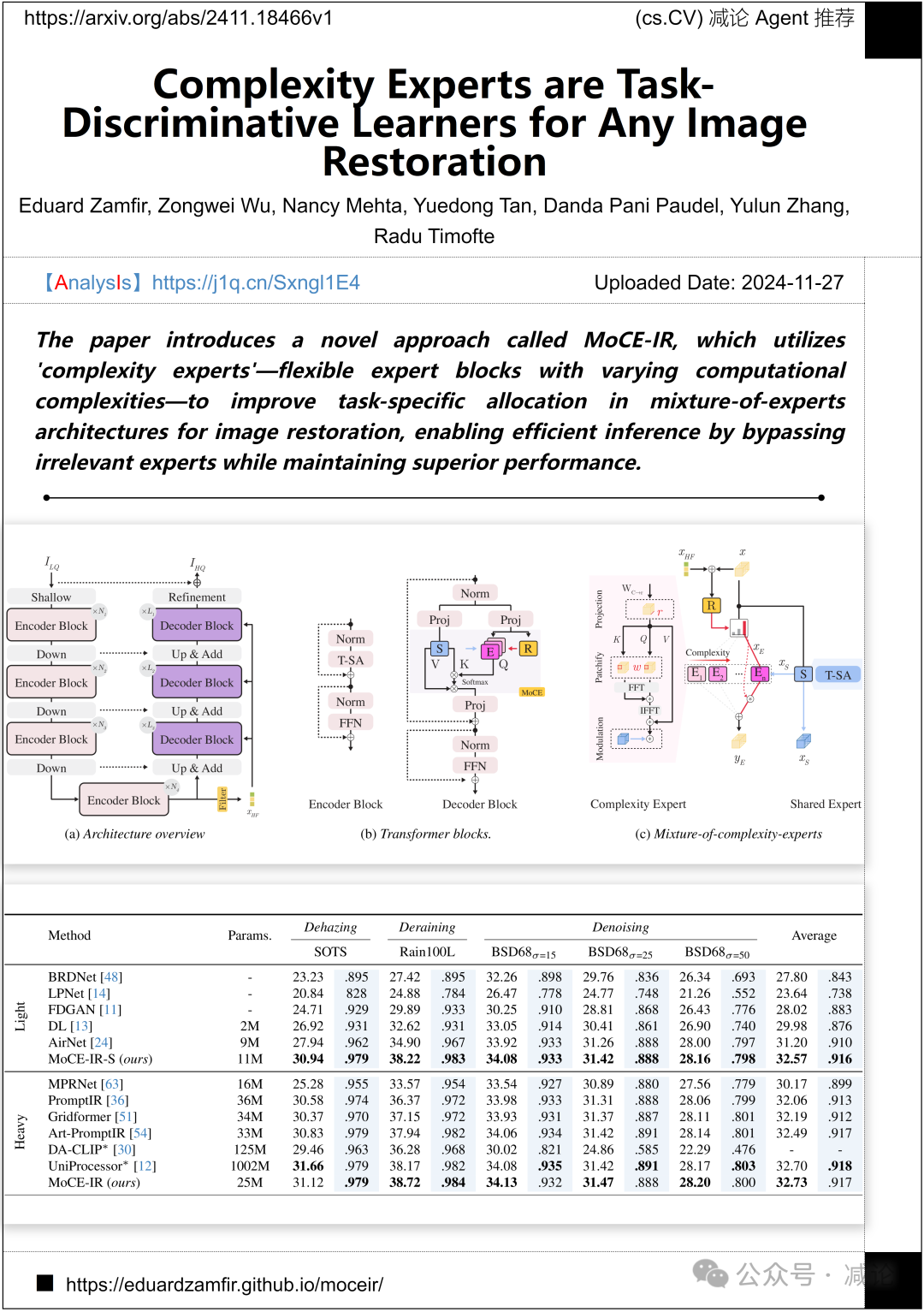
维尔茨堡大学、索非亚大学和上海交通大学联合提出了MoCE-IR方法。该方法利用具有不同计算复杂性的灵活专家模块,改进图像修复中的混合专家架构,实现任务特定分配。通过绕过无关专家,MoCE-IR实现了高效推理,并保持了卓越的性能。
【Bohr精读】
https://j1q.cn/Sxngl1E4
【arXiv链接】
http://arxiv.org/abs/2411.18466v1
【代码地址】
https://eduardzamfir.github.io/moceir/

伦敦帝国学院推出了Signs as Tokens (SOKE)方法,这是一种多语言手语模型。该方法通过将解耦的手语tokenizer集成到预训练语言模型中,从文本输入自回归生成3D手语头像。
【Bohr精读】
https://j1q.cn/CF4G6vsN
【arXiv链接】
http://arxiv.org/abs/2411.17799v1
【代码地址】
https://2000zrl.github.io/soke/

伊利诺伊大学厄本那–香槟分校、德克萨斯大学奥斯汀分校和北卡罗来纳大学教堂山分校提出了DiffVax方法。DiffVax是一个可扩展、轻量级的图像免疫框架,通过嵌入不可察觉的噪声,有效防止基于扩散的编辑,实现免疫时间的25万倍加速。
【Bohr精读】
https://j1q.cn/bs6eC6ON
【arXiv链接】
http://arxiv.org/abs/2411.17957v1
【代码地址】
DiffVax.github.io

上海人工智能实验室、罗切斯特理工学院和中国科学技术大学联合提出了GATE OpenING,这是一个包含5,400个人工标注实例的基准,用于评估交错图文生成方法。此外,论文还引入了IntJudge模型,以评估多模态生成质量。
【Bohr精读】
https://j1q.cn/SAH4EJOf
【arXiv链接】
http://arxiv.org/abs/2411.18499v1
【代码地址】
https://opening.github.io

北京大学与加州大学默塞德分校联合推出了OpenAD方法,这是一个开放世界自动驾驶的基准。该论文通过多模态大型语言模型的极端案例发现和标注流程,增强了在不同场景和语义类别中的3D目标检测能力。
【Bohr精读】
https://j1q.cn/73VtDtFP
【arXiv链接】
http://arxiv.org/abs/2411.17761v1
【代码地址】
https://github.com/VDIGPKU/OpenAD

香港大学与中国电信联合提出了G3Flow方法,这是一个新颖的框架,结合了实时语义流与基于扩散的策略,实现动态、以物体为中心的语义理解。该方法增强了3D机器人操作,并在终端受限任务和跨物体泛化中提升了性能。
【Bohr精读】
https://j1q.cn/YxuFzmFC
【arXiv链接】
http://arxiv.org/abs/2411.18369v1
【代码地址】
https://tianxingchen.github.io/G3Flow

首尔国立大学开发了PersonaCraft,一种将扩散模型与3D人体建模相结合的方法。该方法通过有效管理遮挡和支持用户自定义体型调整,生成高质量的多人物个性化图像。
【Bohr精读】
https://j1q.cn/Ea4Miu0V
【arXiv链接】
http://arxiv.org/abs/2411.18068v1
【代码地址】
https://gwang-kim.github.io/persona_craft

国际数字经济学院推出了多模态大语言模型ChatRex。该模型采用解耦设计,将检测转化为检索任务,从而增强感知能力,并通过Rexverse-2M数据集进行感知与理解的联合训练。
【Bohr精读】
https://j1q.cn/tE4gD50g
【arXiv链接】
http://arxiv.org/abs/2411.18363v1
【代码地址】
https://github.com/IDEA-Research/ChatRex
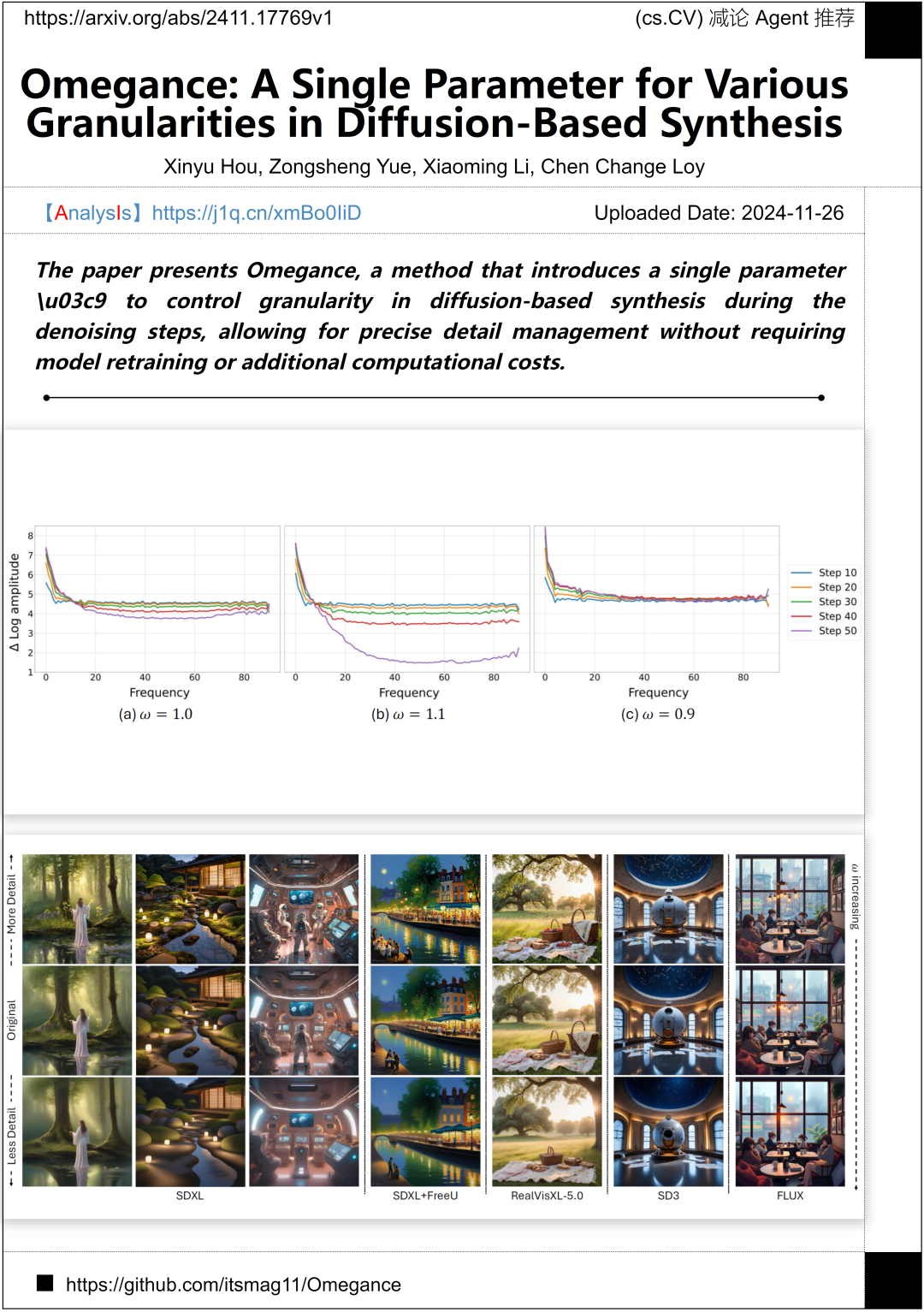
南洋理工大学提出的Omegance方法通过引入单一参数ω,在去噪步骤中控制基于扩散的合成粒度。这一创新方法实现了精确的细节管理,无需重新训练模型或增加计算成本。
【Bohr精读】
https://j1q.cn/xmBo0IiD
【arXiv链接】
http://arxiv.org/abs/2411.17769v1
【代码地址】
https://github.com/itsmag11/Omegance
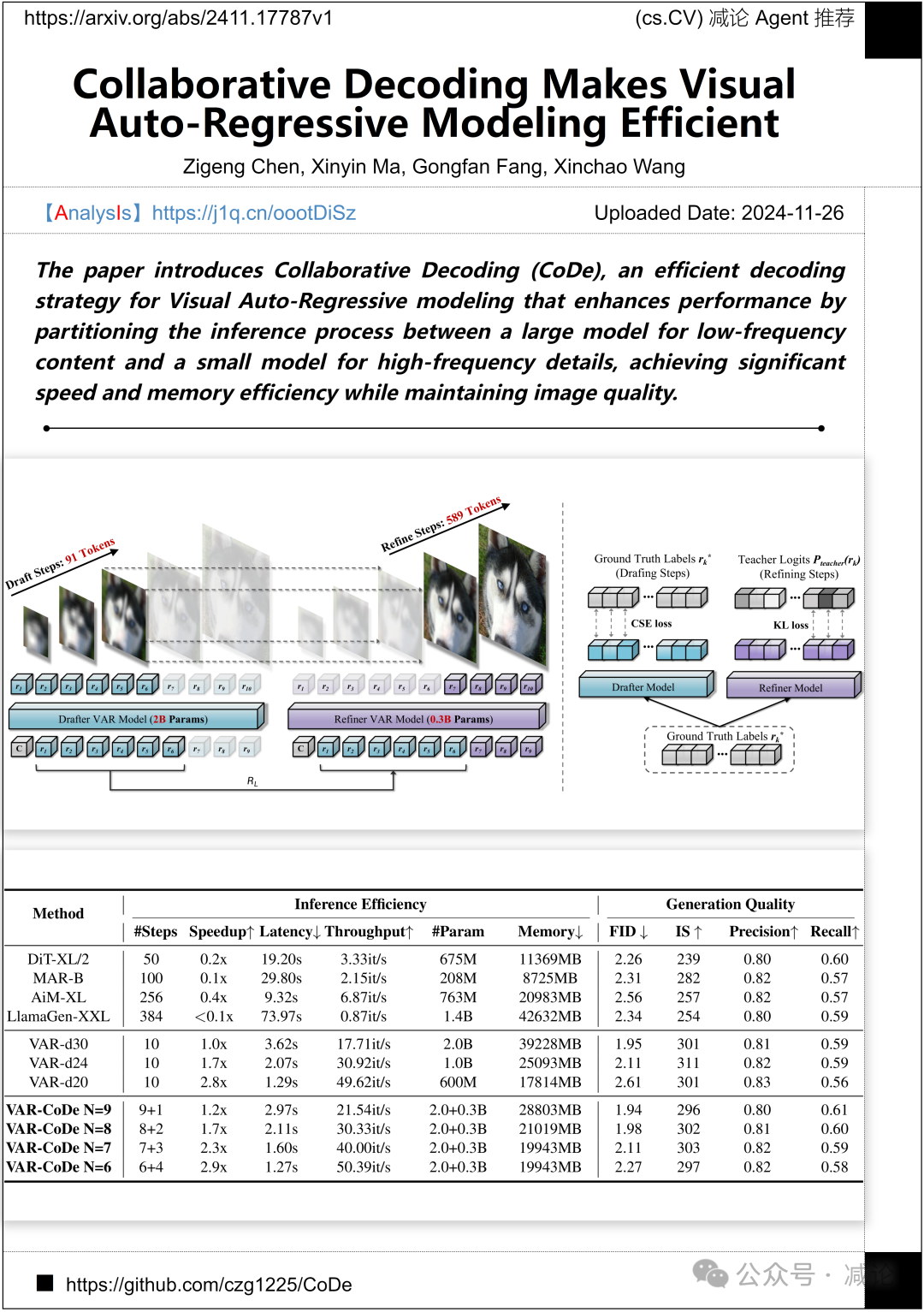
新加坡国立大学提出了一种协作解码(CoDe)方法,用于视觉自回归建模。该方法将推理过程分为大模型处理低频内容和小模型处理高频细节,显著提升了性能,保持了图像质量,同时提高了速度和内存效率。
【Bohr精读】
https://j1q.cn/oootDiSz
【arXiv链接】
http://arxiv.org/abs/2411.17787v1
【代码地址】
https://github.com/czg1225/CoDe
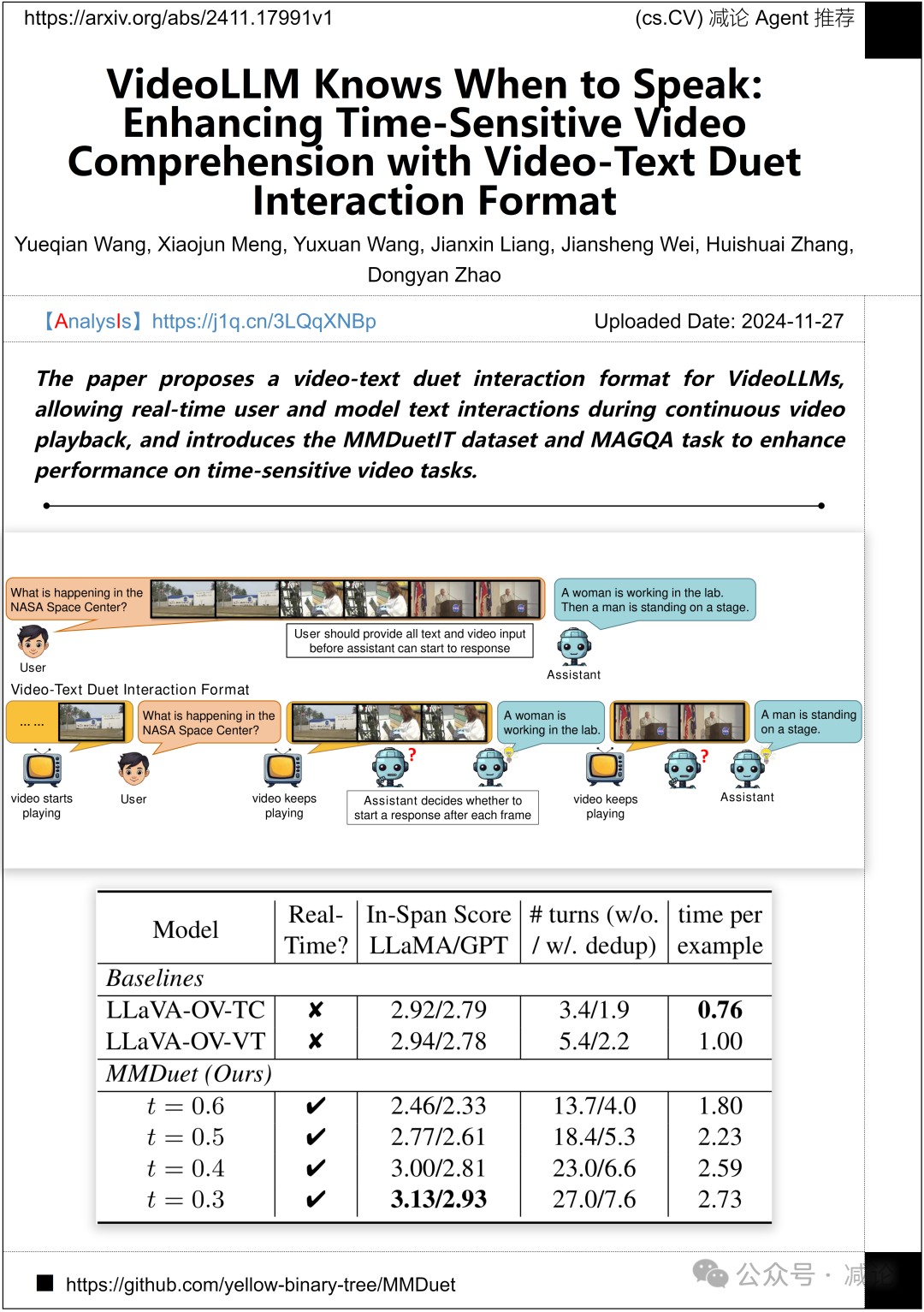
北京大学、华为诺亚方舟实验室和北京通用人工智能研究院提出了一种用于VideoLLMs的视频–文本二重奏交互格式,支持在连续视频播放期间进行实时用户与模型的文本交互。同时,研究团队引入了MMDuetIT数据集和MAGQA任务,以提升时间敏感视频任务的性能。
【Bohr精读】
https://j1q.cn/3LQqXNBp
【arXiv链接】
http://arxiv.org/abs/2411.17991v1
【代码地址】
https://github.com/yellow-binary-tree/MMDuet

新加坡国立大学、Meta和麻省理工学院联合提出的ROICtrl方法是一种用于预训练扩散模型的适配器。该方法通过ROI-Align和ROI-Unpool操作,增强了视觉生成中的区域实例控制,实现了对具有边界框和自由形式字幕的多个实例的高效且准确操控。
【Bohr精读】
https://j1q.cn/5wrdi14j
【arXiv链接】
http://arxiv.org/abs/2411.17949v1
【代码地址】
https://roictrl.github.io/

字节跳动与中国科学院自动化研究所联合推出I2VControl方法,构建了一个用于图像到视频合成的统一框架。该方法将视频划分为由解耦控制信号表示的独立运动单元,实现灵活的运动控制,支持用户创意组合,并与预训练模型集成。
【Bohr精读】
https://j1q.cn/4Odza8y5
【arXiv链接】
http://arxiv.org/abs/2411.17765v1
【代码地址】
https://wanquanf.github.io/I2VControl
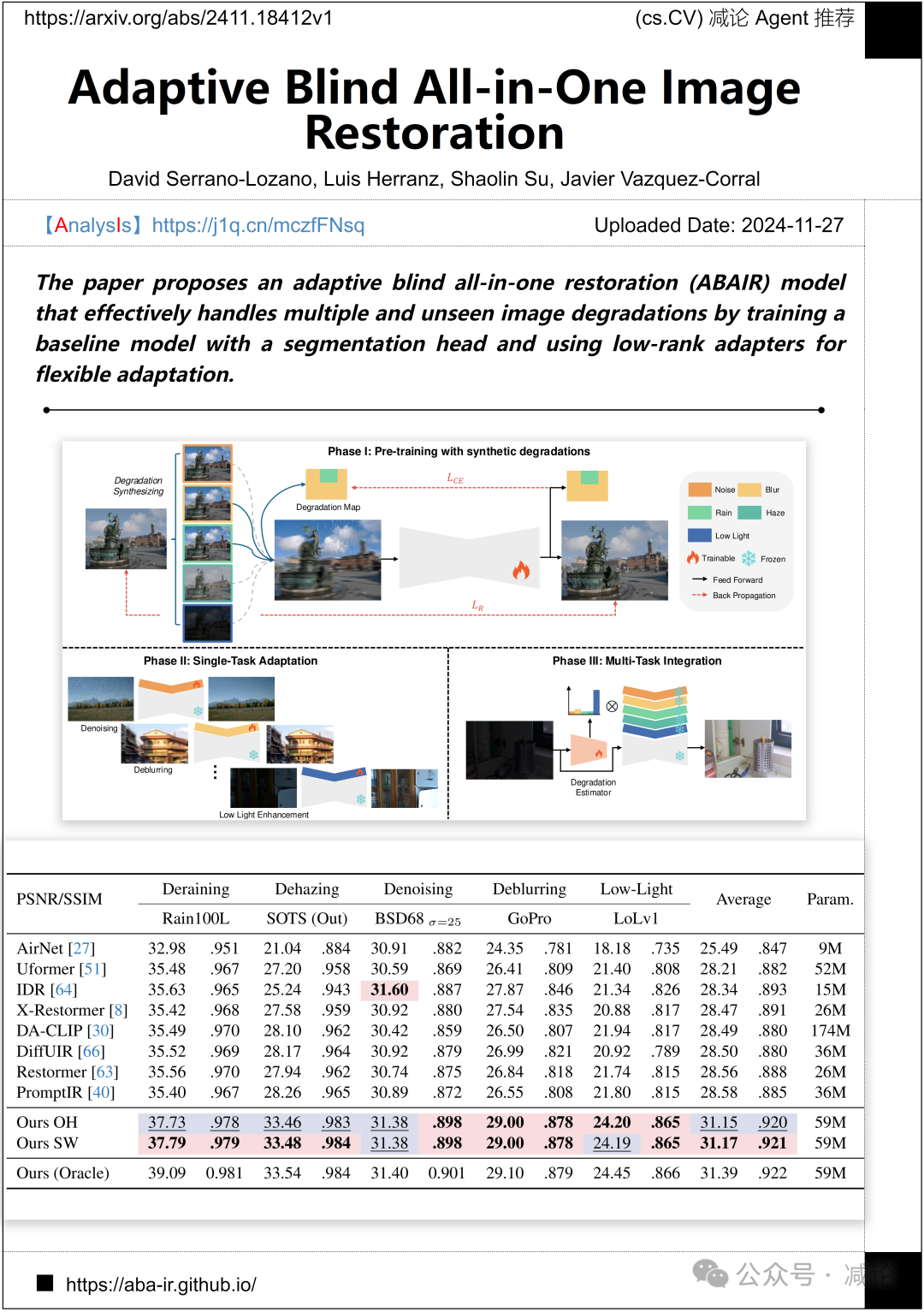
马德里自治大学计算机视觉中心提出了一种自适应盲全能修复(ABAIR)模型。该模型通过训练一个带有分割头的基线模型,并使用低秩适配器实现灵活适应,有效处理多种和未见的图像退化。
【Bohr精读】
https://j1q.cn/mczfFNsq
【arXiv链接】
http://arxiv.org/abs/2411.18412v1
【代码地址】
https://aba-ir.github.io/

欢迎关注减论,持续输出有深度的人工智能极减理解,提升信息获取效率和认知维度。看完点颗小星星再走呗~