
转自公众号:大模型新视界
http://mp.weixin.qq.com/s?__biz=MzkxOTcxNjk2Mw==&mid=2247486225&idx=1&sn=e6ce45c6c0e8cf892b909f8dc987d5ab
原文:https://zhuanlan.zhihu.com/p/717133251
论文题目:Direct Preference Optimization: Your Language Model is Secretly a Reward Model
论文链接:https://https://arxiv.org/abs/2305.182900
【还在持续更新中】
直接偏好优化 DPO (Direct Preference Optimization)& 基于人类反馈的强化学习 RLHF (Reinforcement Learning from Human Feedback) 的区别
DPO(Direct Preference Optimization)和RLHF(Reinforcement Learning from Human Feedback)是两种不同的方法,用于优化机器学习模型,特别是在自然语言处理和生成任务中。以下是它们的主要区别:
1. DPO(Direct Preference Optimization)
概念:DPO是一种直接优化用户或专家偏好的方法。它通过收集用户对模型输出的偏好数据,直接优化模型的参数,使得模型输出更符合用户的偏好。
方法:DPO通常涉及构建一个偏好模型,该模型能够预测用户在给定选择中的偏好。然后,使用这些偏好数据来优化生成模型的参数。这种方法不依赖于强化学习,而是直接利用偏好数据进行优化。
优点:(简单直接)不需要复杂的强化学习算法,直接使用偏好数据进行优化;(更少的计算资源)由于不需要模拟环境和大量的探索,计算资源需求相对较低。
缺点:(数据依赖性)需要大量的高质量偏好数据,收集这些数据可能成本较高;(适用范围有限)对于一些需要复杂策略和长时间决策的任务,DPO可能不如RLHF有效。
欢迎加入自动驾驶实战群


2. RLHF(Reinforcement Learning from Human Feedback)
概念:RLHF是一种利用人类反馈进行强化学习的方法。它通过收集人类对模型行为的反馈,使用这些反馈来指导强化学习过程,从而优化模型的性能。
方法:RLHF通常涉及两个主要步骤:首先,收集人类反馈数据,这些数据可以是对模型输出的评分或直接的行为建议。然后,使用这些反馈数据来训练一个奖励模型,该模型用于指导强化学习过程。通过强化学习算法(如策略梯度、Q-learning等),模型在模拟环境中不断探索和改进,最终优化其行为以最大化人类反馈的奖励。(也有papers说RLHF分三个阶段,SFT,Preference sampling and reward learning, RL optimization)

优点:适用于各种复杂任务,特别是那些需要长期策略和决策的任务;通过人类反馈,可以有效处理稀疏奖励问题,使得模型更快收敛。
缺点:强化学习通常需要大量的计算资源和时间,特别是在复杂环境中;人类反馈数据可能带有噪声或偏见,需要有效的处理和过滤机制。
KL散度,哪都有你?
KL散度(Kullback-Leibler Divergence),也称为相对熵,是一种用于衡量两个概率分布之间差异的非对称度量。具体来说,KL散度衡量的是从分布 Q 到分布 P 需要多少额外的信息。
KL散度的定义

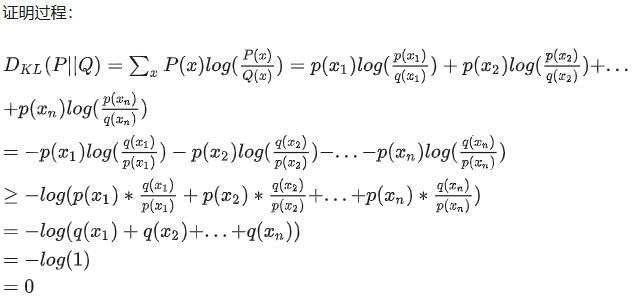
Bradley-Terry 模型
Bradley-Terry 模型是一种用于比较成对对象的概率模型,广泛应用于各种排名和比较问题中,如体育比赛、产品比较和投票系统。以下是对Bradley-Terry模型的详细解读:
模型概述
Bradley-Terry模型主要用于估计在成对比较中某一对象胜过另一对象的概率。假设我们有一个对象集合 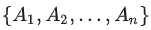 ,每个对象
,每个对象 具有一个正的能力参数
具有一个正的能力参数 。
。
模型公式

模型假设
1. 独立性:每对对象的比较结果是独立的。
2. 正参数:每个对象的能力参数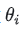 都是正数。
都是正数。
3. 比例性:胜利的概率由对象的能力参数之比决定。
参数估计

从RLHF的目标函数进行推导:

基于Bradley-Terry模型的DPO推导

先来解释下上述公式的推导:
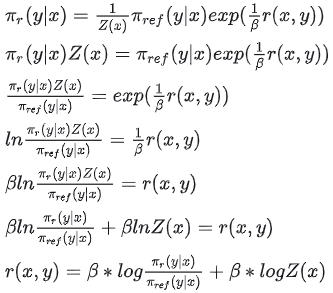

DPO训练语料
{
"prompt": "What is the capital of China?",
"chosen": "The capital of China is Beijing.",
"rejected": "The capital of China is Shanghai."
}chosen符合用户偏好的答案,rejected则相反,目前DPO算法已封装在trl(transformer reinforcement learning)包中DPOTrainer
最后别忘了,帮忙点“在看”。
您的点赞,在看,是我创作的动力。
AiFighing是全网第一且唯一以代码、项目的形式讲解自动驾驶感知方向的关键技术。
长按扫描下面二维码,加入知识星球。
