
Abstract
自动驾驶需要良好的道路条件,但巴西有85%的道路存在损坏,而现有的深度学习模型可能无法很好地应对这一情况,因为大多数语义分割数据集针对的是高分辨率且维护良好的城市道路图像。一个针对新兴国家的代表性数据集由低分辨率的维护不善的道路图像构成,并包含损坏类别的标注。在这种场景下,会面临三个挑战:像素少的目标、不规则形状的目标,以及高度不均衡的类别分布。为应对这些挑战,本文提出了语义分割性能提升策略(PISSS),通过14组训练实验来提升模型性能。通过PISSS,我们在Road Traversing Knowledge (RTK) 和 Technik Autonomer Systeme 500 (TAS500) 测试集上分别达到了79.8和68.8的mIoU(平均交并比),实现了最新的研究成果。此外,本文还分析了DeepLabV3+在小目标分割任务中的不足。
代码获取:https://github.com/tldrafael/pisss
欢迎加入自动驾驶实战群


Introduction
当前的自动驾驶研究主要基于发达国家的良好基础设施,这些国家的数据集大多来自欧洲城市街道的高分辨率图像,例如Cityscapes、CamVid 和 KITTI数据集。而在巴西,85%的道路存在疲劳、裂缝、坑洼、修补痕迹以及起伏不平的表面。这种糟糕的道路状况对自动驾驶感知提出了调整的需求。此外,新兴国家的计算资源限制可能会约束深度学习模型的输入图像大小,从而限制高分辨率图像的使用,迫使研究者为低分辨率图像开发适应性解决方案。
一些数据集,如RTK数据集特别捕捉了巴西乡村道路的不同维护状况和表面类型。RTK数据集包含701张分辨率为352×288的标注图像,分为12个类别。这些类别包括路面(如沥青、铺装路面和未铺装路面)、标志(如标线、反光猫眼、减速带和排水口)以及损坏(如修补痕迹、积水坑、坑洼和裂缝)。见图1。

在对低分辨率图像进行深度学习模型训练时,本研究提出了三大挑战:
1.像素较少的目标:低分辨率图像中不仅目标相对于其他对象显得较小,其像素数量也很少。例如,70%的反光猫眼的边缘像素数量小于等于5,甚至有15%的路面标线只有一个像素的边缘。这些微小目标容易在卷积和池化层的前向传播初期消失。这种现象成为DeepLabV3+模型的问题,如第4.2节所述。
2.形状不规则的目标或多尺度元素:例如,路面通常宽阔且形状规则,而修补痕迹则没有明确的形状和大小。这一问题因类内形状的变化而更加复杂,比如同一图像中的坑洼和裂缝可能具有多种形式。
3.高度不均衡的类别分布:小型损坏和标志类像素数量极少,例如背景和路面像素占据了98.5%,而反光猫眼和排水口仅占0.02%。这一失衡场景增加了小目标类别被忽略的风险。
为应对上述挑战,我们设计了语义分割性能提升策略(PISSS),该策略结合了应对不平衡数据集、小目标以及多尺度分割挑战的最新研究中的一系列最佳训练实践。通过PISSS,我们将RTK基准测试提升至79.8 mIoU,TAS500提升至68.8 mIoU,创造了目前已发布的最佳结果。此外,我们还提出去除ResNet中的最大池化(MP)层,以保留小目标的分割能力。
3 PISSS – 语义分割性能提升策略
PISSS是一种由一系列叠加的消融实验组成的方法论。每个实验会验证一组假设中哪一种能达到最佳性能,例如,针对RTK数据集,哪种数据增强操作效果更好?是几何操作?颜色操作?还是两者结合?每种选择被称为一个假设。消融实验通过比较不同假设的效果,确定训练配置的最佳选项。接下来的消融实验将在当前最佳配置的基础上进行迭代。
PISSS在RTK数据集上的应用共包含14个消融实验,分为四类:基线(Baseline,B)、预测(Prediction,P)、技术(Technique,T)和架构(Architecture,A)。基线实验验证RTK作者的训练方案[18],预测实验探讨预测集成的使用,技术实验测试训练配置的细节,架构实验则检验神经网络结构的调整。图2展示了各类实验的尝试内容。

PISSS的实验顺序以基线工作为起点,采用了不同的评估策略,以下是具体讨论。
3.1 基线
我们以RTK作者的解决方案为实验的起点,称之为基线。其配置为:使用ResNet-34的U-Net,Adam优化器(学习率为1e-4),批量大小为8,数据增强包括透视变形和水平翻转(称为GeomRTK),采用两阶段训练策略,首先用交叉熵(CE)运行100个epoch,然后用加权交叉熵(WCE)再运行100个epoch,总共14k次迭代。
3.2 评估方法
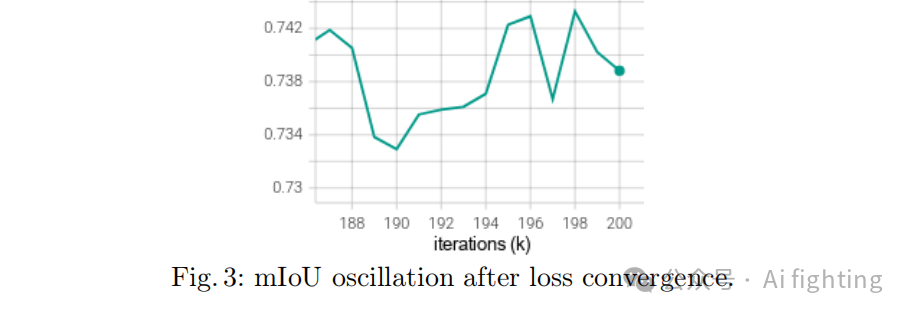
在监控训练实验时,我们注意到损失收敛后mIoU会有轻微波动。例如,图3显示,mIoU在[0.733, 0.743]范围内波动,这占mIoU尺度[0,1]的1%;这种波动足以导致在比较假设时得出错误结论。为减少这种噪声波动,我们采用了一种折中方法,取验证集最后十次结果的平均值进行评估。
4 PISSS在RTK上的应用
本节展示了PISSS在RTK上的应用,分为五个主要部分,按时间顺序介绍:
1.超越基线;
2.调试DeepLabV3+;
3.新方法与Cutmix;
4.损失函数;
5.预测集成。
4.1 第一部分 – 超越基线
第一部分包含五个实验:迭代次数(B)、单阶段训练(B)、数据增强(T)、编码器深度(A)以及ResNet变体(A)。见表1,实验顺序从上到下,每次实验都基于当前最佳假设的配置(若无特别说明),最佳假设的mIoU值以粗体标出。
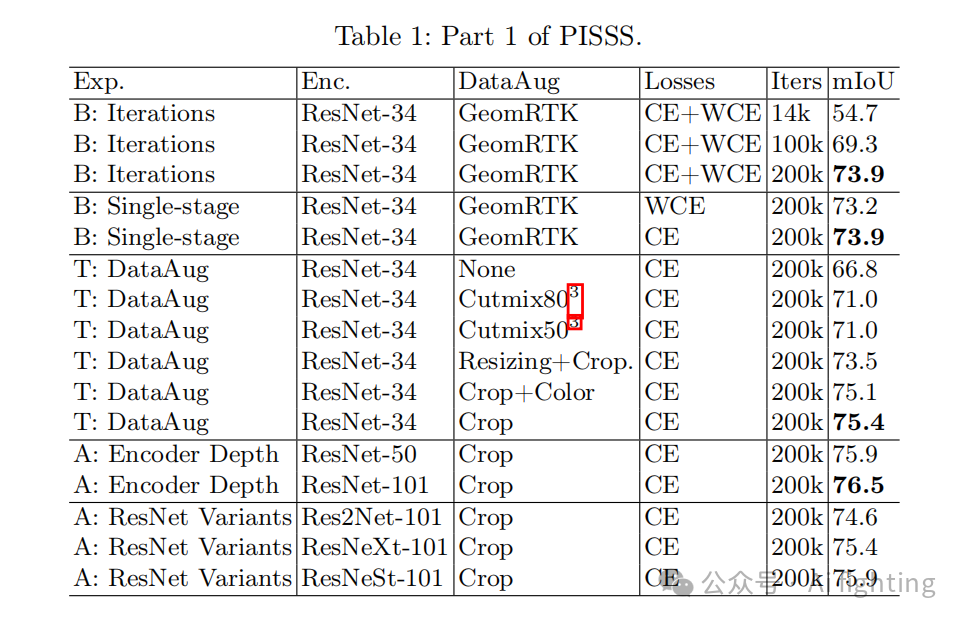
(1) 迭代次数实验:验证14k次迭代时间过短,需将迭代次数增加至200k次。
(2) 单阶段训练实验:发现两阶段训练或加权交叉熵(WCE)并无优势。
(3) 数据增强实验:采用裁剪(224×224)、随机边缘缩放(比例为[0.78, 2])、灰度和色彩扰动(抖动值为0.27)。单独使用裁剪效果最佳,加入缩放或色彩增强会降低效果,Cutmix单独使用影响不大,但不使用任何增强策略的效果非常差,表明数据增强是必要的。
(4) 编码器深度实验:尝试更深的ResNet版本,发现效果更佳。
(5) esNet变体实验:尝试了不同变体,包括Res2Net(在ResNet模块中使用不同尺度)、ResNeSt(增加注意力机制)以及ResNeXt(采用分组卷积)。但这些变体均未提升性能。
4.2 第二部分 – 调试DeepLabV3+
本部分覆盖了七个实验:模型架构(A)、输出步长(A)、最大池化移除(A)、转置卷积(A)、混合局部特征提取器(A)、Cutmix(T)和优化器(T)。见表2,表2的实验基于表1的最佳配置。
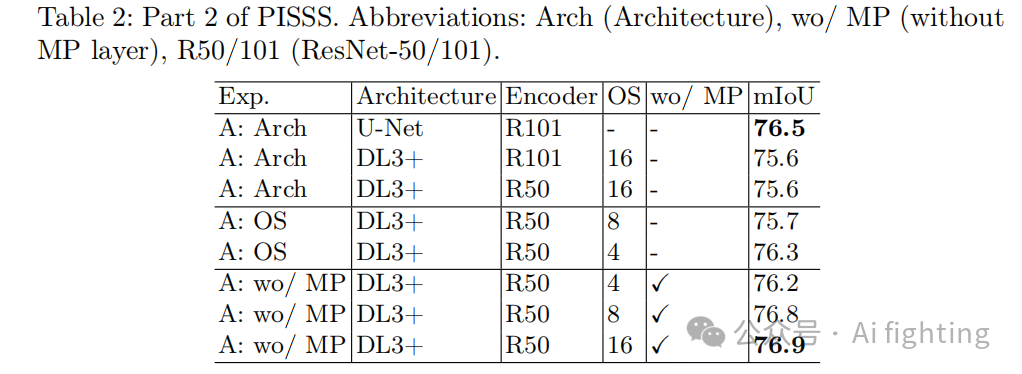
(1) 模型架构实验:首次尝试DeepLabV3+(DL3+)未能超越U-Net。然而,在控制最大池化(MP)层的使用和输出步长(OS)后,性能得到了提升。
(2) 输出步长实验:控制输入与编码器输出的维度比,发现减小OS会提高性能。但在移除MP层的实验中,趋势发生了逆转,更高的OS反而取得了最佳性能。
(3) MP层移除实验:发现低级特征(LL)步长比高级特征(HL)步长更为重要。将更小的LL步长与更高的HL步长结合,可以实现两者的优势互补。
DeepLabV3+模式分析。DL3+的解码器将ASPP模块的高级特征(HL)与ResNet主干的低级特征(LL)拼接。查看图4,了解架构和尺寸控制的典型例子。OS实验参数控制HL特征的最终维度,而MP层则控制LL特征的维度。例如,移除MP层后,LL特征直接来自于7×7卷积层(步长为2),否则来自于MP层之后(步长为4)。
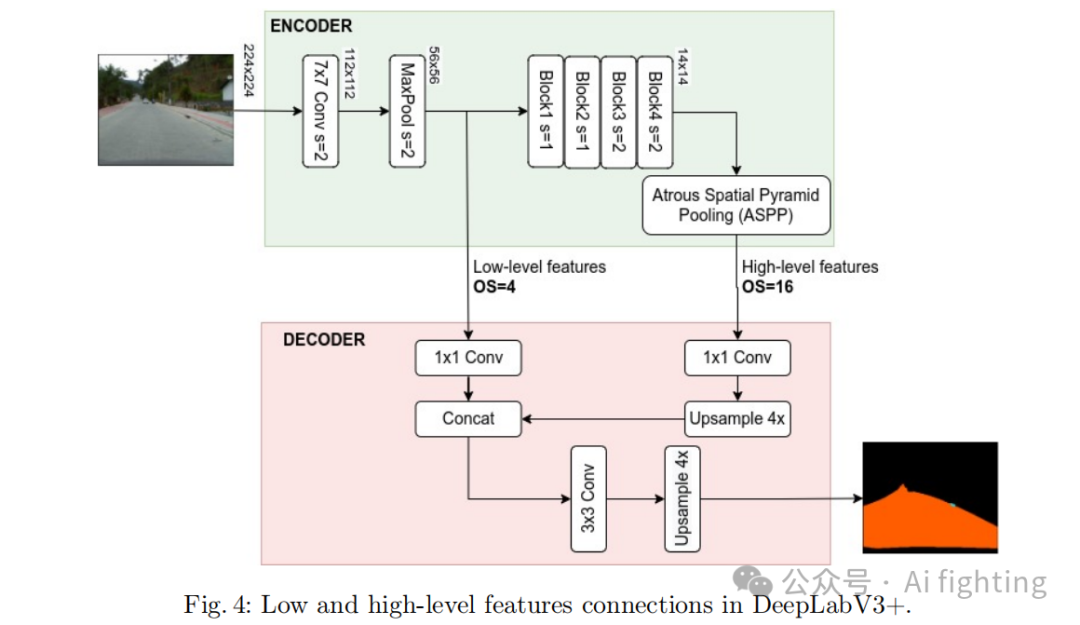
移除MP层对OS为8和16的配置有积极影响,但对OS为4的配置无明显作用。这种组合解释了表2的结果。此外,更高OS下随机预测小背景块或小道路块的问题在减少OS到4时逐渐消失,移除MP层也解决了这一问题,见图5和图6。
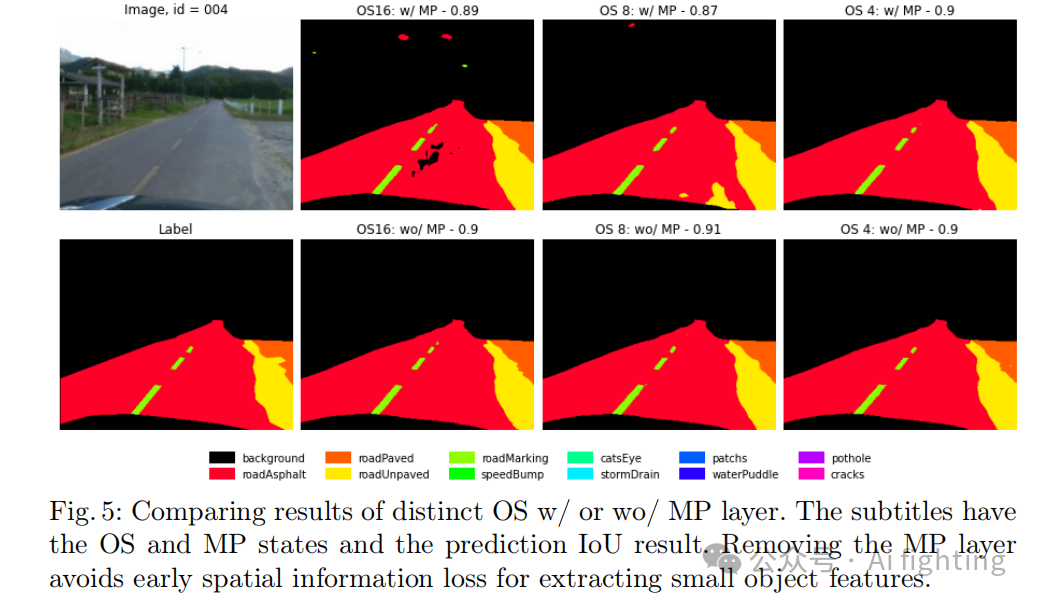
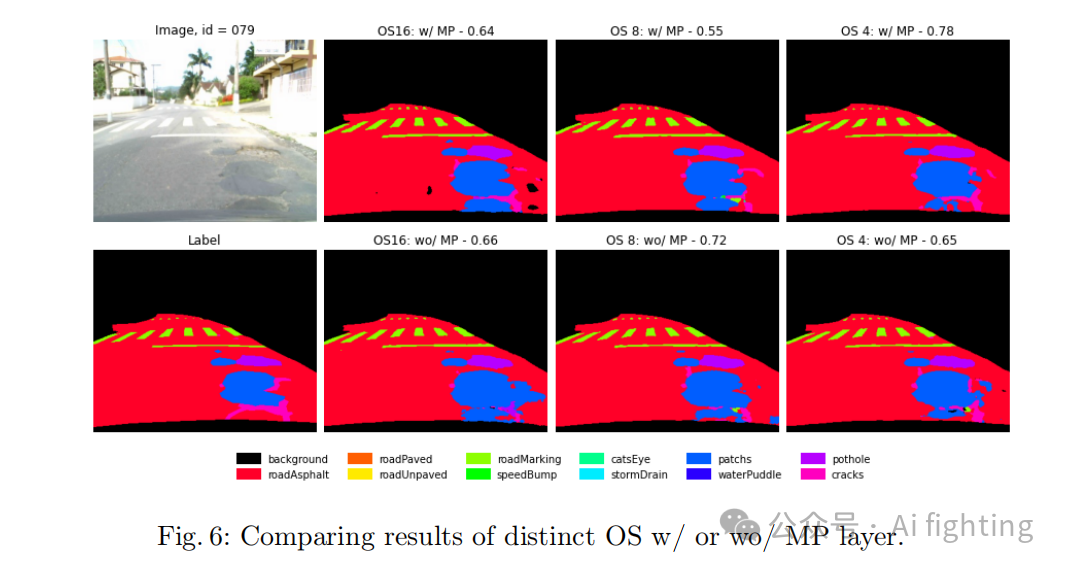
4.3 第三部分 – 高级方法和Cutmix
在本节中,我们涵盖了四个实验:转置卷积(A)、混合局部特征提取器(A)、Cutmix(T)和优化器(T)。详见表3。
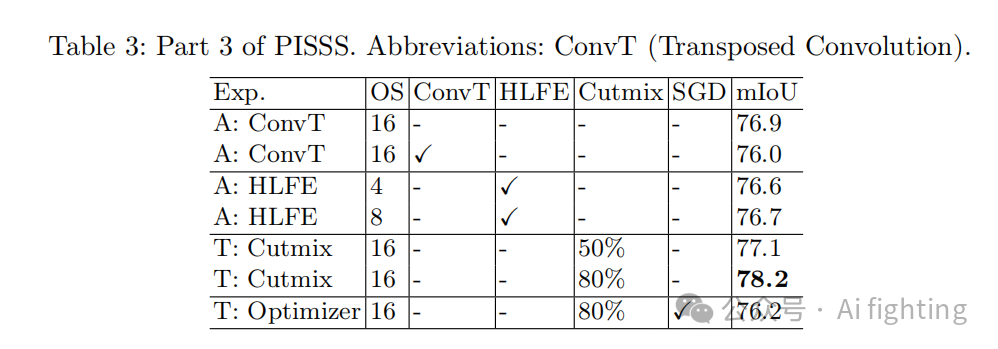
我们尝试了两种高级方法,但均未提升性能。首先,我们将非参数上采样替换为转置卷积层。接下来,我们实现了一种混合局部特征提取器(Hybrid Local Feature Extractor, HLFE),它结合了递减膨胀率和混合膨胀率。对于HLFE,我们在ResNet的第3模块中使用了膨胀率[1, 3, 5, 5, 3, 1],在第4模块中使用了膨胀率[1, 3, 1]。由于OS为16时没有膨胀率,因此无法尝试HLFE。
我们还尝试了使用SGD替代Adam优化器,但没有带来性能提升。SGD设置包括学习率为1e-2、5000次迭代的线性预热、带动量(0.9)的多项式学习率衰减。而在数据增强方面,Cutmix与裁剪结合的效果显著,将mIoU从76.9提升到78.2。我们测试了Cutmix的发生概率为50%和80%的效果。
4.4 第四部分 – 损失函数
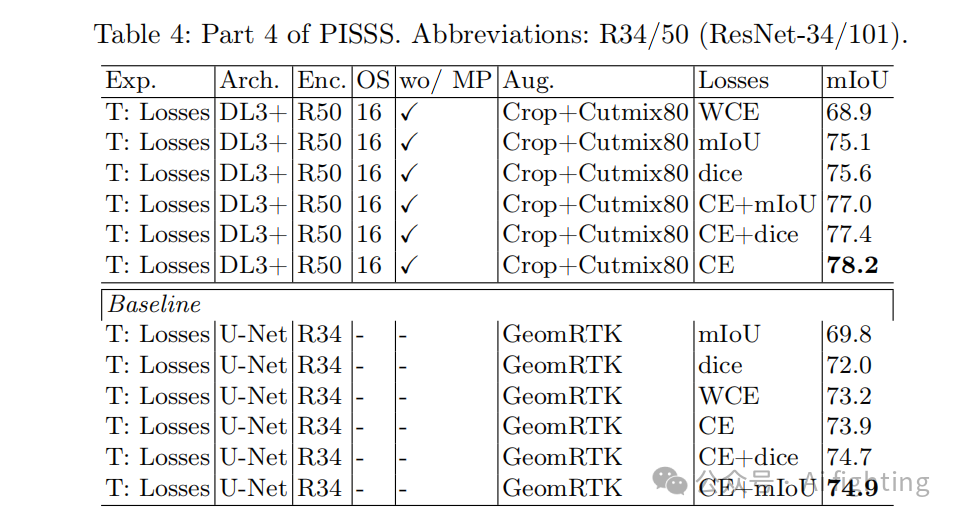
我们尝试了mIoU和Dice的替代损失函数,但在经过良好校准的训练设置下,它们并未表现出任何优势。然而,在较为简单的基线训练设置中,这些替代损失函数表现出了帮助作用(详见表4)。我们发现,仅使用替代损失函数会降低性能,而交叉熵(CE)损失实际上充当了mIoU的代理,比直接优化mIoU损失的效果更好。
4.5 第五部分 – 预测集成
与此前的评估方法不同,本实验使用单一检查点(ckpt)的评估指标,无论是来自最后的训练步骤,还是验证结果最佳的步骤。因此,表5中的数值与之前报告的有所不同。我们采用了288×224和448×352的多尺度预测分辨率,此外还有原生分辨率352×288。最终,翻转集成获得了最佳结果,在最后和最佳检查点分别达到了78.9和79.8的mIoU。

5 RTK实验分析
本节首先分析了类别的大小和像素数量如何影响性能,然后展示了训练模型对每个类别的关注点。以下结果基于PISSS的最佳假设,即Cutmix(T)实验的检查点。
5.1 按类别和组别的性能
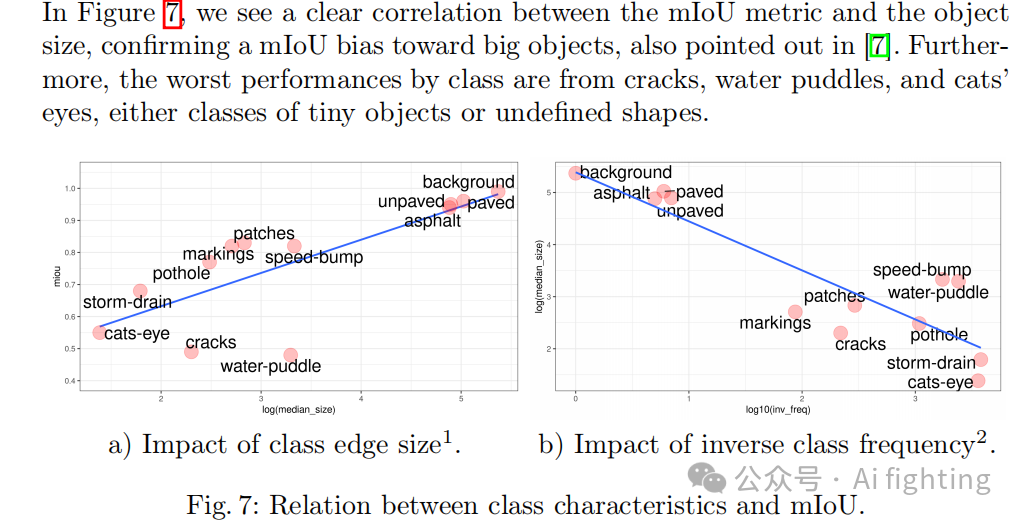
从图7可以看出,mIoU指标与目标物体大小之间存在明显的相关性,证实了mIoU对大目标的偏好,这一点在文献中也有所提及。此外,类别中表现最差的是裂缝、水坑和猫眼,这些通常是较小或形状不规则的目标类别。
5.2 神经网络关注的内容
理解神经网络如何感知数据集类别的一种方法是优化输入神经元,以最大化输出概率。我们通过梯度上升优化了网络输入,结果如图8所示。网络对不同类别的纹理、颜色分布和几何模式具有高度敏感性。例如,storm-drain(排水孔)显示为黑洞,road-paved(铺装道路)展示了多边形结构的存在,而road-asphalt(沥青路面)似乎捕捉到了路面裂缝的特征。

6 在TAS500数据集上应用PISSS
TAS500数据集是2021年发布的数据集,专注于非结构化环境,提供细粒度植被和地形类别的标注,以区分可行驶表面和自然障碍。TAS500包含高分辨率(HR)图像,分辨率为2026×620,这使得MP层移除和转置卷积的实验因GPU内存仅有16GB而无法进行。此外,批量大小被迫减少至4。同时,训练使用了裁剪后的1024×512图像,这是训练高分辨率图像的常规做法。
此外,我们跳过了基线实验,只在RTK实验的PISSS假设中选择了一部分应用。因此,实验设置从DeepLabV3+、ResNet50、OS 16、学习率为5e-5(相比RTK实验中的1e-4因批量大小减少而降低)的Adam优化器开始。在验证评估中,我们采用了与RTK实验相同的方法,即平均最后十步的结果(详见表6和表7)。
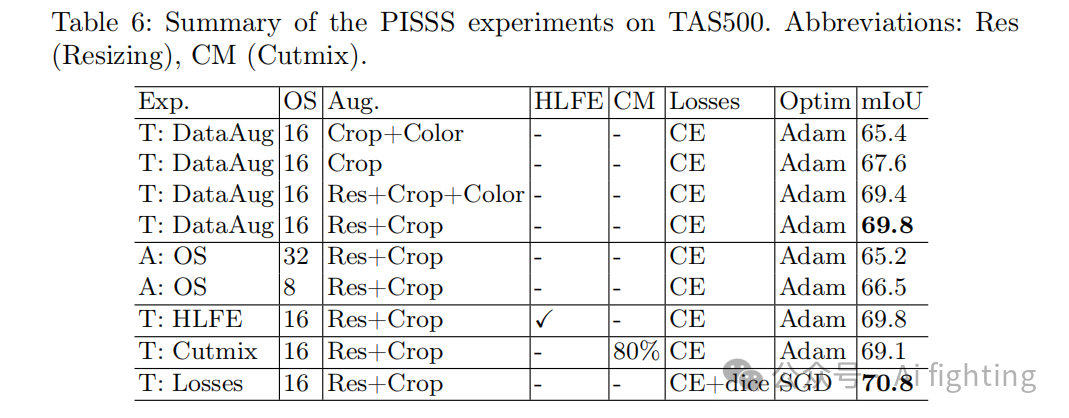
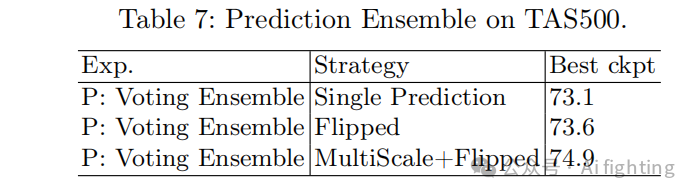
结果显示,数据增强中的图像缩放、CE+dice损失函数、SGD优化器和多尺度集成预测对于提升TAS500基准非常关键。通过PISSS,我们将验证集的mIoU从65.4提高到了74.7。此外,我们将最佳假设模型用于户外语义分割挑战赛,取得了68.84的mIoU,超过了2021年第一名的67.5 mIoU。
7 讨论与发现
尽管PISSS在RTK和TAS500数据集上均表现出色,但在每个数据集中表现最优的假设子集截然不同。对于RTK数据集,使用MP层、Cutmix、OS 4、CE损失和Adam优化器效果更好;而对于TAS500数据集,图像缩放、OS 16、CE+dice损失和SGD优化器表现更优。这种训练设置的差异性支持了定制化解决方案的必要性。
Cutmix数据增强在RTK数据集中带来了1.3 mIoU的显著提升,但在TAS500数据集中效果不明显。我们推测,Cutmix对存在复杂过渡的场景(如道路表面与损坏类别之间的过渡)更有帮助。
最后,本文总结了以下发现:
1.如果特征维度在生成深层特征之前被缩减,小目标的分割会变得困难;模型往往会过度预测小目标。
2.根据RTK结果,最难分割的损坏类别是裂缝、水坑和猫眼。
我们证实了mIoU对大目标的偏好。
3.CE损失函数在优化mIoU指标方面优于mIoU和dice损失函数。
实验的性能提升取决于测试的初始设置。
4.每个数据集的最佳训练设置高度不同,支持了定制化解决方案的必要性。
5.常规设置通常比高级方法表现更佳,因此应作为优先尝试的方法。
结论
1. PISSS(语义分割性能提升策略)是一种新策略,用于解决不平衡数据集、小目标和多尺度分割的挑战。
2. PISSS在RTK基准测试和TAS500上分别取得了79.8 mIoU和68.8 mIoU的最佳成绩。
3. 研究提出了去除ResNet中的最大池化层以增强小目标分割能力的方法。
文章引用:
A Performance Increment Strategy for Semantic Segmentation of Low-Resolution Images from Damaged Roads
最后别忘了,帮忙点“在看”。
您的点赞,在看,是我创作的动力。
AiFighing是全网第一且唯一以代码、项目的形式讲解自动驾驶感知方向的关键技术。
长按扫描下面二维码,加入知识星球。
