
收录于话题
2024年11月26日arXiv cs.CV发文量约200余篇,减论Agent通过算法为您推荐并自动化整理为卡片供您参考,预计为您节省88分钟浏览arXiv的时间。


南京理工大学、南京大学和北京大学联合提出的ConsistentAvatar方法,通过建模时间表示生成高保真说话头像。该方法确保帧间稳定性,并使用时间一致的扩散模块对齐高频特征,改善外观、3D效果、表情和时间一致性。
【Bohr精读】
https://j1q.cn/0eAuJgCO
【arXiv链接】
http://arxiv.org/abs/2411.15436v1
【代码地址】
https://njust-yang.github.io/ConsistentAvatar.github.io/
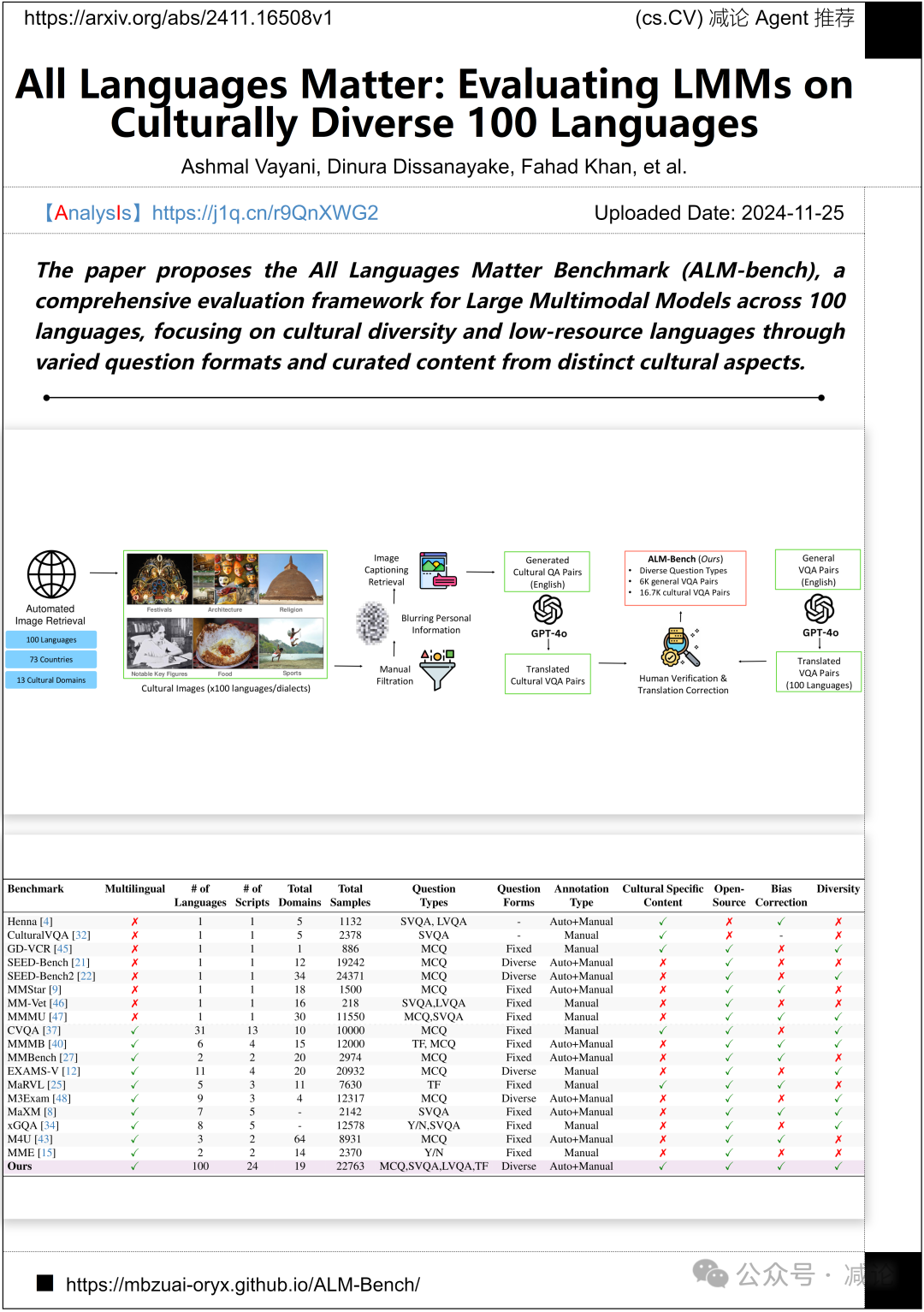
中佛罗里达大学、穆罕默德·本·扎耶德人工智能大学和阿尔托大学联合提出了All Languages Matter Benchmark (ALM-bench)方法。该方法是一个评估框架,针对100种语言中的大型多模态模型,特别关注文化多样性和低资源语言。ALM-bench通过多样化的问题格式和从不同文化角度精心策划的内容,实现了对模型的全面评估。
【Bohr精读】
https://j1q.cn/r9QnXWG2
【arXiv链接】
http://arxiv.org/abs/2411.16508v1
【代码地址】
https://mbzuai-oryx.github.io/ALM-Bench/
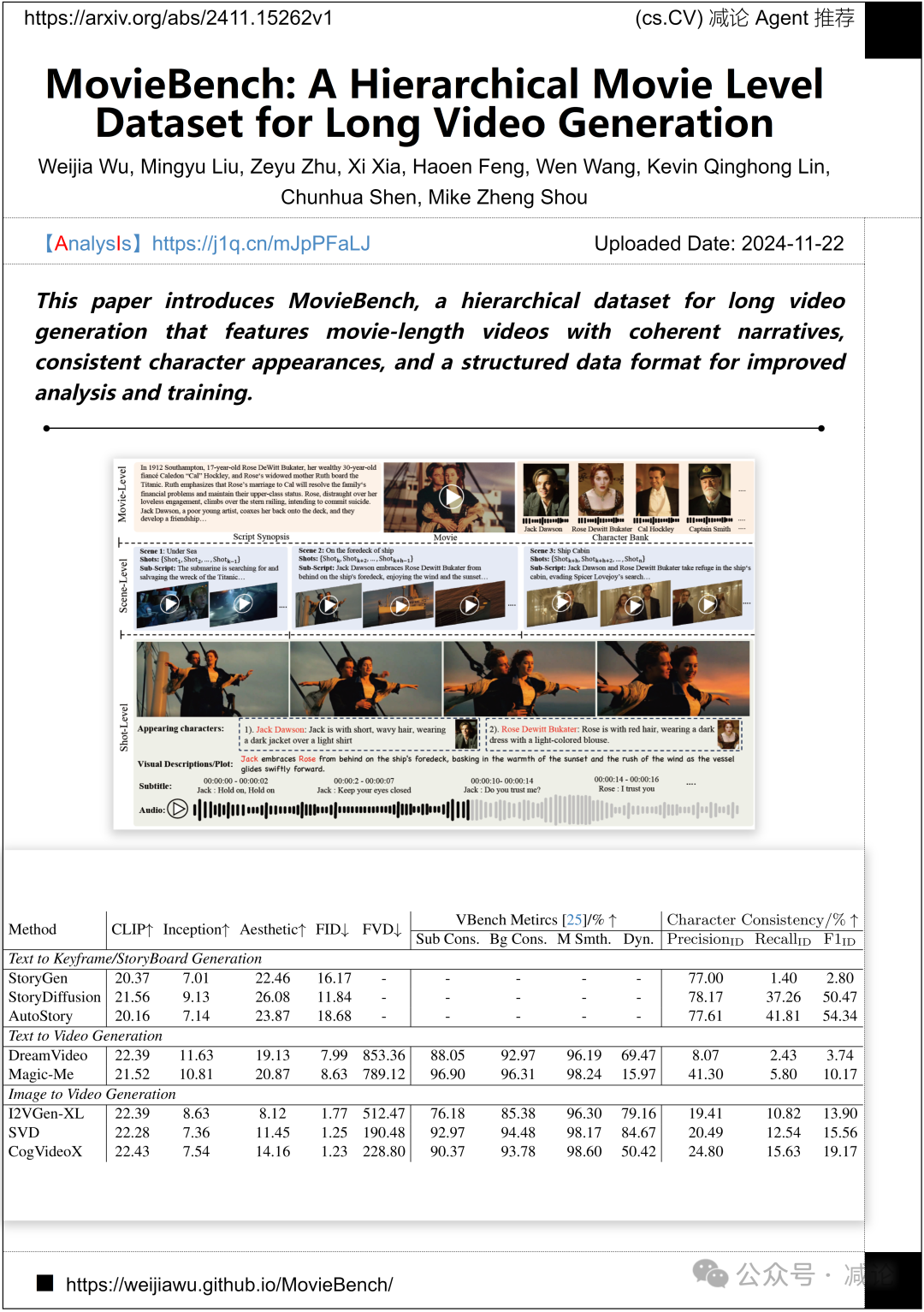
新加坡国立大学与浙江大学联合开发了MovieBench,一个用于长视频生成的分层数据集。该数据集包含叙事连贯、角色一致的电影长度视频,并采用结构化数据格式,以提升分析和训练效果。
【Bohr精读】
https://j1q.cn/mJpPFaLJ
【arXiv链接】
http://arxiv.org/abs/2411.15262v1
【代码地址】
https://weijiawu.github.io/MovieBench/
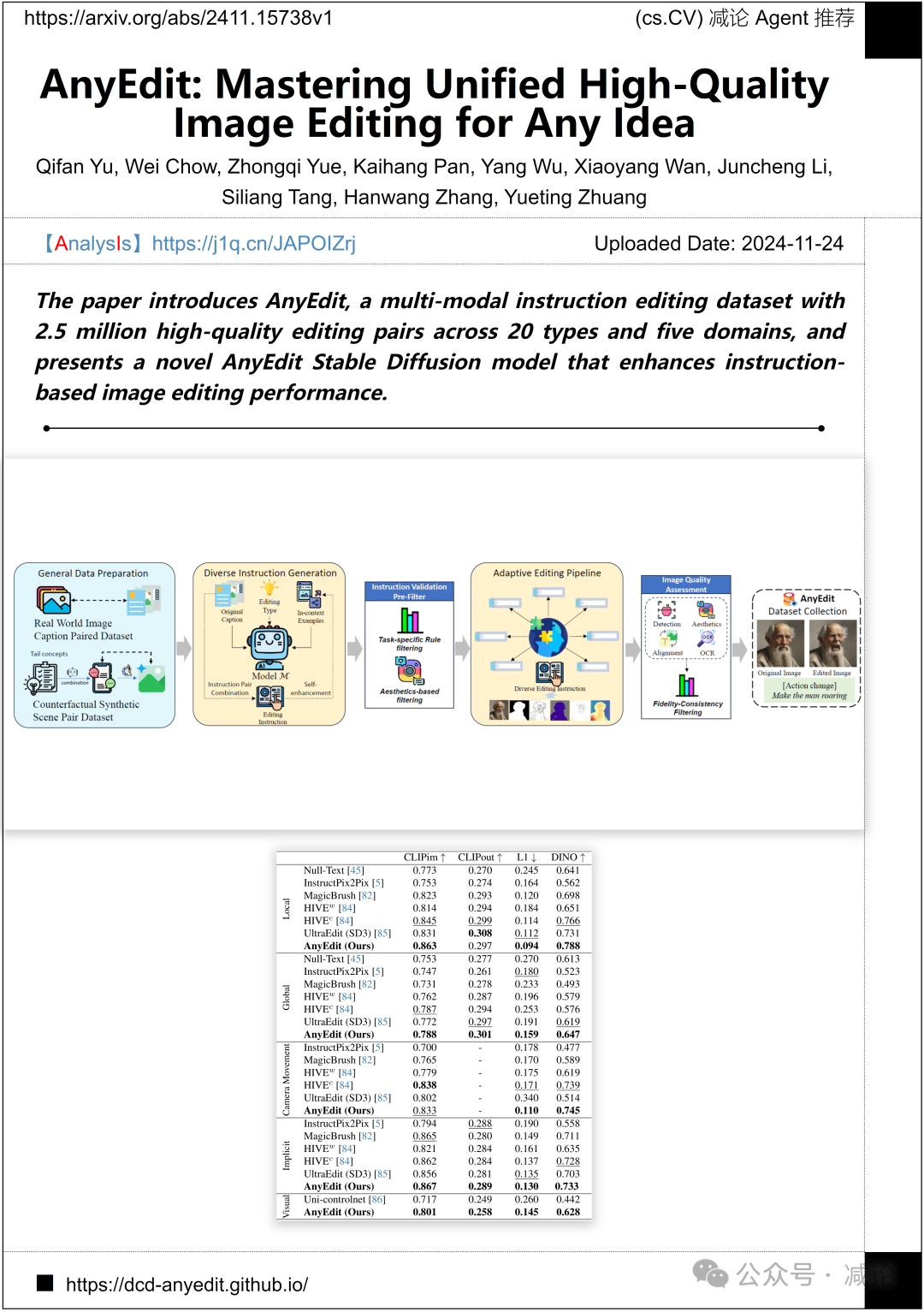
浙江大学、南洋理工大学和阿里巴巴集团联合推出了AnyEdit,一个包含250万高质量编辑对的多模态指令编辑数据集,涵盖20种类型和五个领域。同时,提出了一种新颖的AnyEdit Stable Diffusion模型,以提升基于指令的图像编辑性能。
【Bohr精读】
https://j1q.cn/JAPOIZrj
【arXiv链接】
http://arxiv.org/abs/2411.15738v1
【代码地址】
https://dcd-anyedit.github.io/

上海人工智能实验室与莫纳什大学提出了OphCLIP方法,这是一个分层检索增强的视觉语言预训练框架,用于理解眼科手术流程。该方法利用大规模的视频–文本对数据集,通过将短片段与详细叙述对齐,并从无声手术视频中检索相关内容,增强表示学习。
【Bohr精读】
https://j1q.cn/eVdaqzBZ
【arXiv链接】
http://arxiv.org/abs/2411.15421v1
【代码地址】
https://github.com/minghu0830/OphCLIP

复旦大学、中国科学技术大学和北京交通大学联合提出了SVTRv2方法。这是一种改进的基于CTC的场景文本识别模型,通过引入多尺寸调整策略、特征重排模块和语义引导模块,有效处理文本不规则性,提升了准确性和推理速度。
【Bohr精读】
https://j1q.cn/rxDldLcx
【arXiv链接】
http://arxiv.org/abs/2411.15858v1
【代码地址】
https://github.com/Topdu/OpenOCR

中国科学院自动化研究所与北京大学提出了一种尖峰发放近似(SFA)方法,优化了脉冲神经元在脉冲神经网络(SNNs)中的性能和训练效率。该方法使脉冲神经网络在ImageNet上达到了最先进的准确性,同时保持低功耗。
【Bohr精读】
https://j1q.cn/9N8SianS
【arXiv链接】
http://arxiv.org/abs/2411.16061v1
【代码地址】
https://github.com/BICLab/Spike-Driven-Transformer-V3
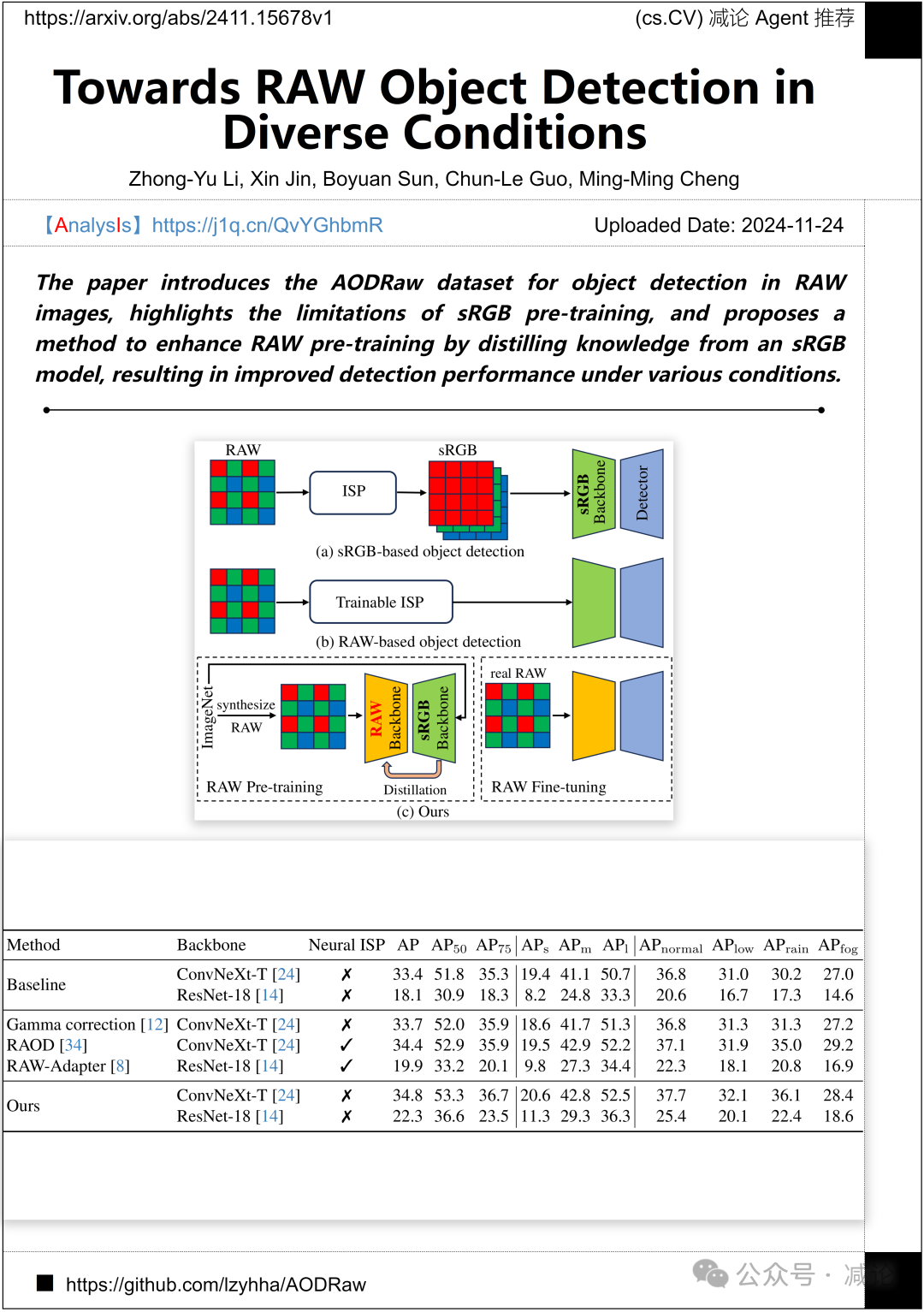
南开大学提出了AODRaw数据集,用于RAW图像目标检测。该研究指出了sRGB预训练的局限性,并提出了一种方法,通过从sRGB模型中提取知识来增强RAW预训练,从而提升在不同条件下的检测性能。
【Bohr精读】
https://j1q.cn/QvYGhbmR
【arXiv链接】
http://arxiv.org/abs/2411.15678v1
【代码地址】
https://github.com/lzyhha/AODRaw
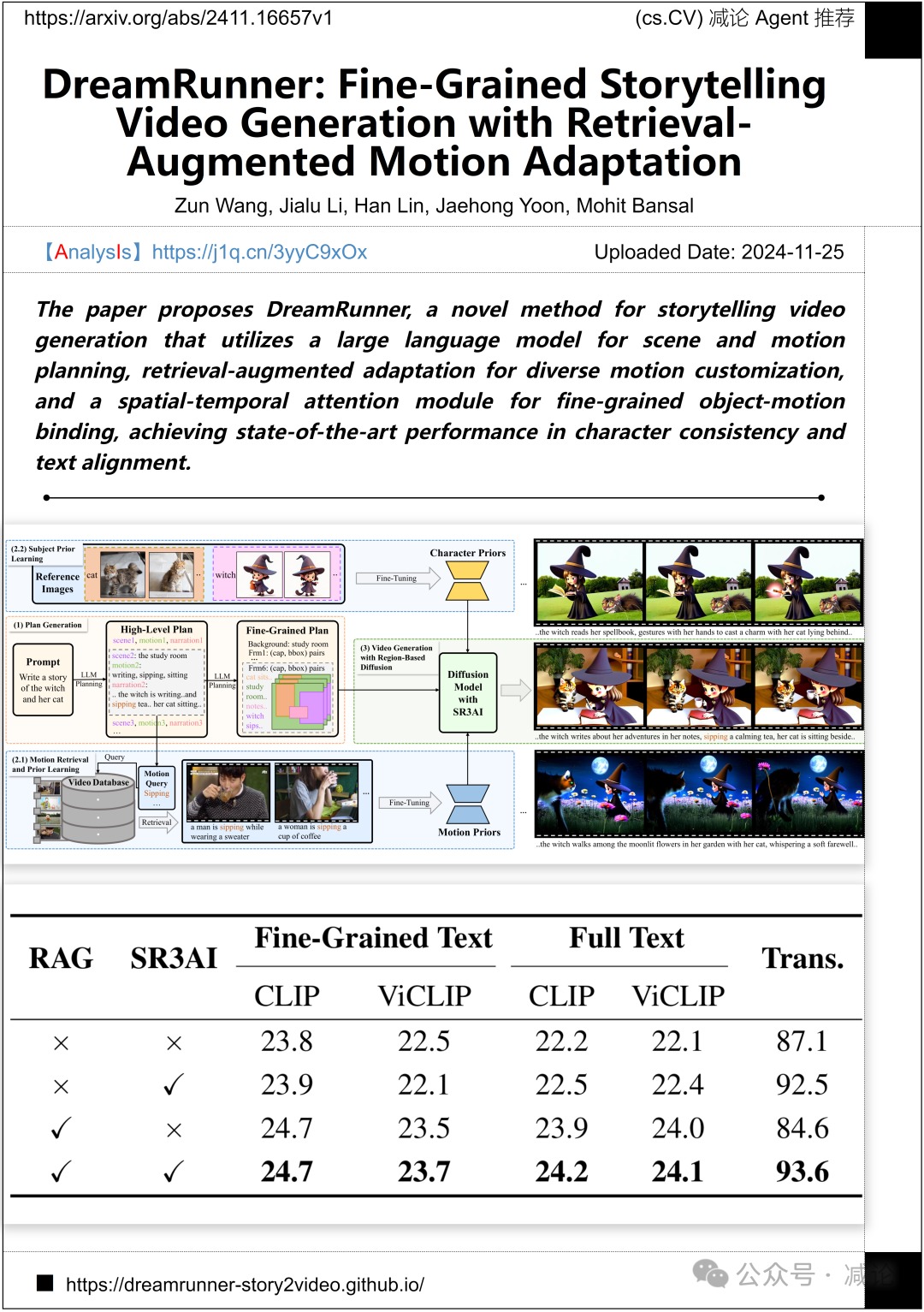
北卡罗来纳大学教堂山分校提出了DreamRunner,一种用于故事视频生成的方法。该方法利用大型语言模型进行场景和运动规划,采用检索增强的适应性实现多样化运动定制,并通过时空注意力模块实现精细的物体运动绑定。在角色一致性和文本对齐方面,DreamRunner表现出色。
【Bohr精读】
https://j1q.cn/3yyC9xOx
【arXiv链接】
http://arxiv.org/abs/2411.16657v1
【代码地址】
https://dreamrunner-story2video.github.io/

谷歌提出了一种新颖的神经算法,利用分层深度图和基于Transformer的架构,从稀疏的RGB输入中重建3D场景,并高效渲染高分辨率图像,实现实时新视图合成。
【Bohr精读】
https://j1q.cn/XYd2fUJS
【arXiv链接】
http://arxiv.org/abs/2411.16680v1
【代码地址】
https://quark-3d.github.io/

上海交通大学与华为技术有限公司联合推出了Human-AGVQA数据集,用于评估AI生成的人类活动视频质量。同时,论文中开发了GHVQ指标,以客观评估视频的视觉质量和语义失真。
【Bohr精读】
https://j1q.cn/Ly1OasUI
【arXiv链接】
http://arxiv.org/abs/2411.16619v1
【代码地址】
https://github.com/zczhang-sjtu/GHVQ.git

汉诺威大学与林雪平大学提出了一种基于normalizing flow的单目3D人体姿态和形状估计方法。该方法通过最小化与2D姿态检测器热图的距离来增强分布学习,并利用人体分割掩码减少无效样本,表现优于现有的概率方法。
【Bohr精读】
https://j1q.cn/qdYfLJHX
【arXiv链接】
http://arxiv.org/abs/2411.16289v1
【代码地址】
https://github.com/twehrbein/humr

西安交通大学、中国科学院和华为技术有限公司联合开发了AeroGen方法,这是一种布局可控的扩散生成模型,专用于遥感图像目标检测。AeroGen可以生成符合特定布局和目标类别要求的高质量合成图像,显著提升在标注数据有限的数据集中的检测性能。
【Bohr精读】
https://j1q.cn/taTUuc11
【arXiv链接】
http://arxiv.org/abs/2411.15497v1
【代码地址】
https://github.com/Sonettoo/AeroGen

新加坡国立大学、复旦大学与亚马逊联合提出了因子化量化(FQ)方法。该方法通过将大型码本分解为独立子码本,增强了基于VQ的分词器的可扩展性和效率。同时,利用解缠结正则化和表示学习,提升了多样性和语义丰富性。
【Bohr精读】
https://j1q.cn/oIEY7C6X
【arXiv链接】
http://arxiv.org/abs/2411.16681v1
【代码地址】
https://showlab.github.io/FQGAN

清华大学、NVIDIA和斯坦福大学联合提出了OVM3D-Det方法,这是一种经济高效的开放词汇单目3D目标检测框架。该框架利用RGB图像,并采用自适应伪LiDAR侵蚀和边界框优化技术,在无需高精度3D传感器数据的情况下,能够有效识别新类别。
【Bohr精读】
https://j1q.cn/LOPLELEf
【arXiv链接】
http://arxiv.org/abs/2411.15657v1
【代码地址】
https://ovm3d-det.github.io

首尔国立大学提出了Diptych Prompting方法,这是一种新颖的零样本文本到图像生成技术。该方法利用参考图像的修复技术,实现精确的主体对齐,增强视觉细节,并有效防止内容泄漏。
【Bohr精读】
https://j1q.cn/5aQeOBUo
【arXiv链接】
http://arxiv.org/abs/2411.15466v1
【代码地址】
https://diptychprompting.github.io/

电子科技大学提出了残差互相关自注意力(RCS)模块和语义反馈优化(SFR)模块。RCS模块通过中间层的互相关注意力增强视觉语言推理,SFR模块则利用语义分割图调整注意力分数。
【Bohr精读】
https://j1q.cn/8j75joys
【arXiv链接】
http://arxiv.org/abs/2411.15851v1
【代码地址】
https://github.com/yvhangyang/ResCLIP

清华大学提出了自校准CLIP(SC-CLIP)方法。这是一种无需训练的方案,通过解决异常token、提高特征可辨性和采用多层次特征融合,显著增强了CLIP的分割能力。在不引入新参数的情况下,SC-CLIP在语义分割任务中取得了最先进的成果。
【Bohr精读】
https://j1q.cn/PpsScsU8
【arXiv链接】
http://arxiv.org/abs/2411.15869v1
【代码地址】
https://github.com/SuleBai/SC-CLIP

香港科技大学与上海交通大学联合推出了SAVEn-Vid大型视听数据集,并提出了基于该数据集微调的时间感知视听大型语言模型SAVEnVideo。此外,研究团队介绍了评估长视频视听理解的基准AVBench,显示出相较于现有模型的显著性能提升。
【Bohr精读】
https://j1q.cn/kEu39aVj
【arXiv链接】
http://arxiv.org/abs/2411.16213v1
【代码地址】
https://ljungang.github.io/SAVEn-Vid/

阿里巴巴集团推出的AnyText2方法是一种新技术,用于在自然场景图像中生成和编辑多语言文本。该方法采用WriteNet+AttnX架构,提升了生成文本的真实感和速度,并配备文本嵌入模块,以自定义文本属性,提高文本的准确性。
【Bohr精读】
https://j1q.cn/i88rcBNz
【arXiv链接】
http://arxiv.org/abs/2411.15245v1
【代码地址】
https://github.com/tyxsspa/AnyText2

AI2、加州大学欧文分校和华盛顿大学提出了OneDiffusion方法。OneDiffusion是一个大规模扩散模型,将所有任务视为具有不同噪声尺度的帧序列,以实现多样化的双向图像合成和理解。该方法支持条件生成和多任务训练,无需专门的架构。
【Bohr精读】
https://j1q.cn/1iljGBSS
【arXiv链接】
http://arxiv.org/abs/2411.16318v1
【代码地址】
https://github.com/lehduong/OneDiffusion

康考迪亚大学提出了BiomedCoOp方法,这是一种提示学习框架,利用语义一致性和知识蒸馏增强BiomedCLIP在小样本生物医学图像分类中的适应性,从而在多个医学数据集上提高了准确性和泛化能力。
【Bohr精读】
https://j1q.cn/UjmaMTPY
【arXiv链接】
http://arxiv.org/abs/2411.15232v1
【代码地址】
https://github.com/HealthX-Lab/BiomedCoOp
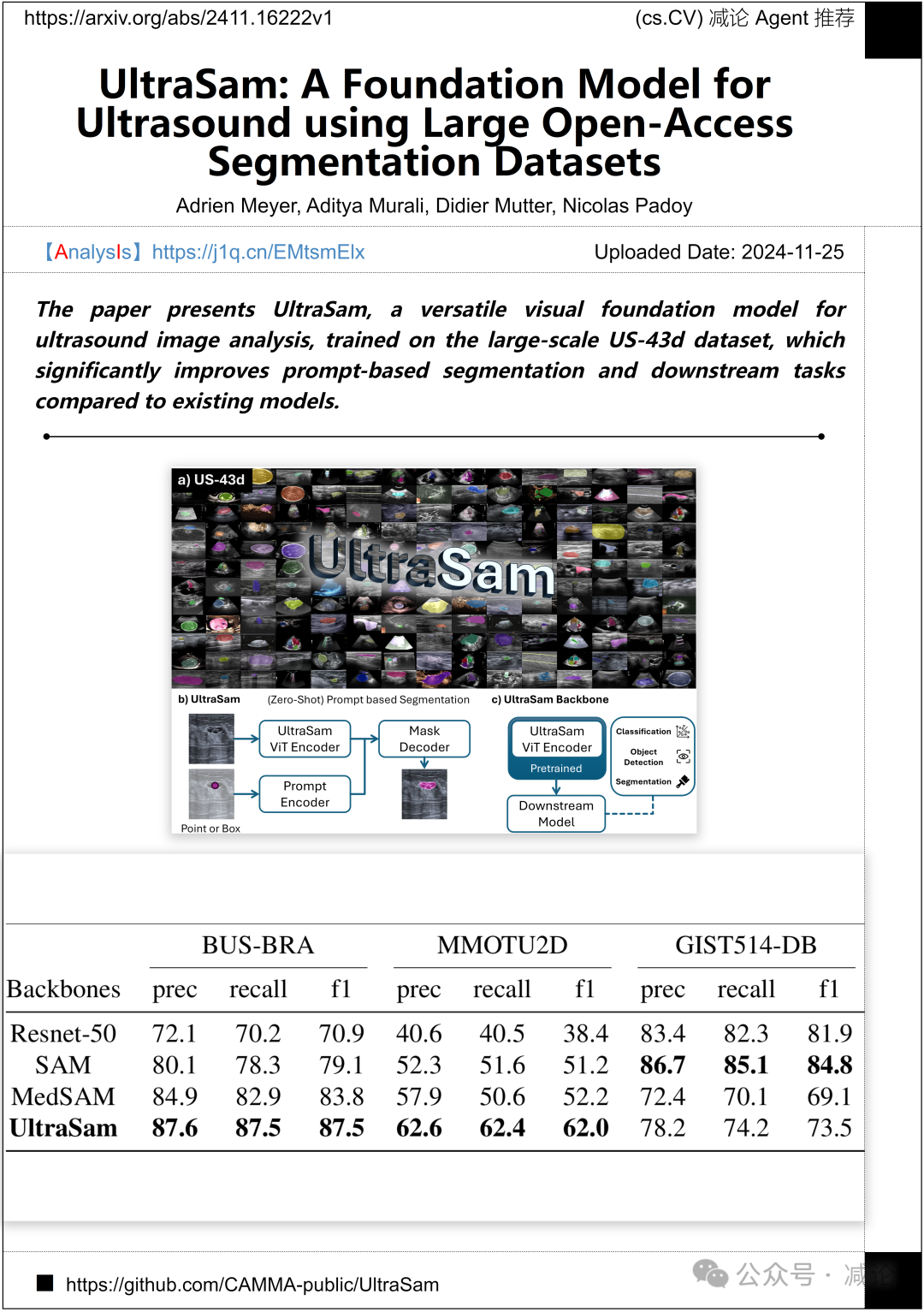
斯特拉斯堡大学、斯特拉斯堡IHU和影像引导外科研究所推出了UltraSam,一种用于超声图像分析的多功能视觉基础模型。该模型基于大规模US-43d数据集训练,显著提升了基于提示的分割和下游任务的性能。
【Bohr精读】
https://j1q.cn/EMtsmElx
【arXiv链接】
http://arxiv.org/abs/2411.16222v1
【代码地址】
https://github.com/CAMMA-public/UltraSam

欢迎关注减论,持续输出有深度的人工智能极减理解,提升信息获取效率和认知维度。看完点颗小星星再走呗~