
收录于话题
2024年11月25日arXiv cs.CV发文量约107余篇,减论Agent通过算法为您推荐并自动化整理为卡片供您参考,预计为您节省44分钟浏览arXiv的时间。
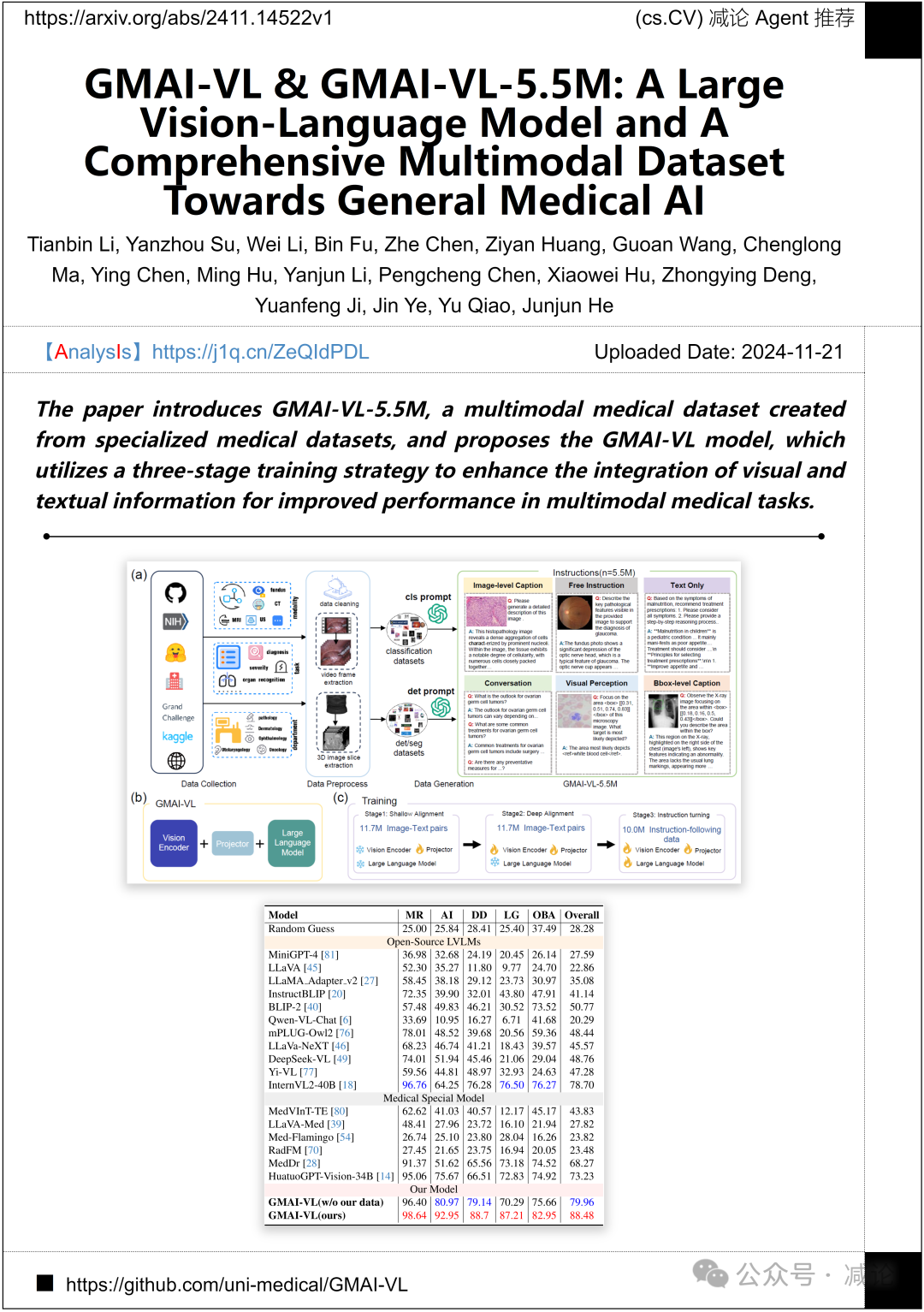

上海人工智能实验室与上海交通大学发布了多模态医学数据集GMAI-VL-5.5M,基于专业医学数据构建。研究团队提出的GMAI-VL模型采用三阶段训练策略,优化视觉与文本信息的整合,提升多模态医学任务的性能。
【Bohr精读】
https://j1q.cn/ZeQIdPDL
【arXiv链接】
http://arxiv.org/abs/2411.14522v1
【代码地址】
https://github.com/uni-medical/GMAI-VL
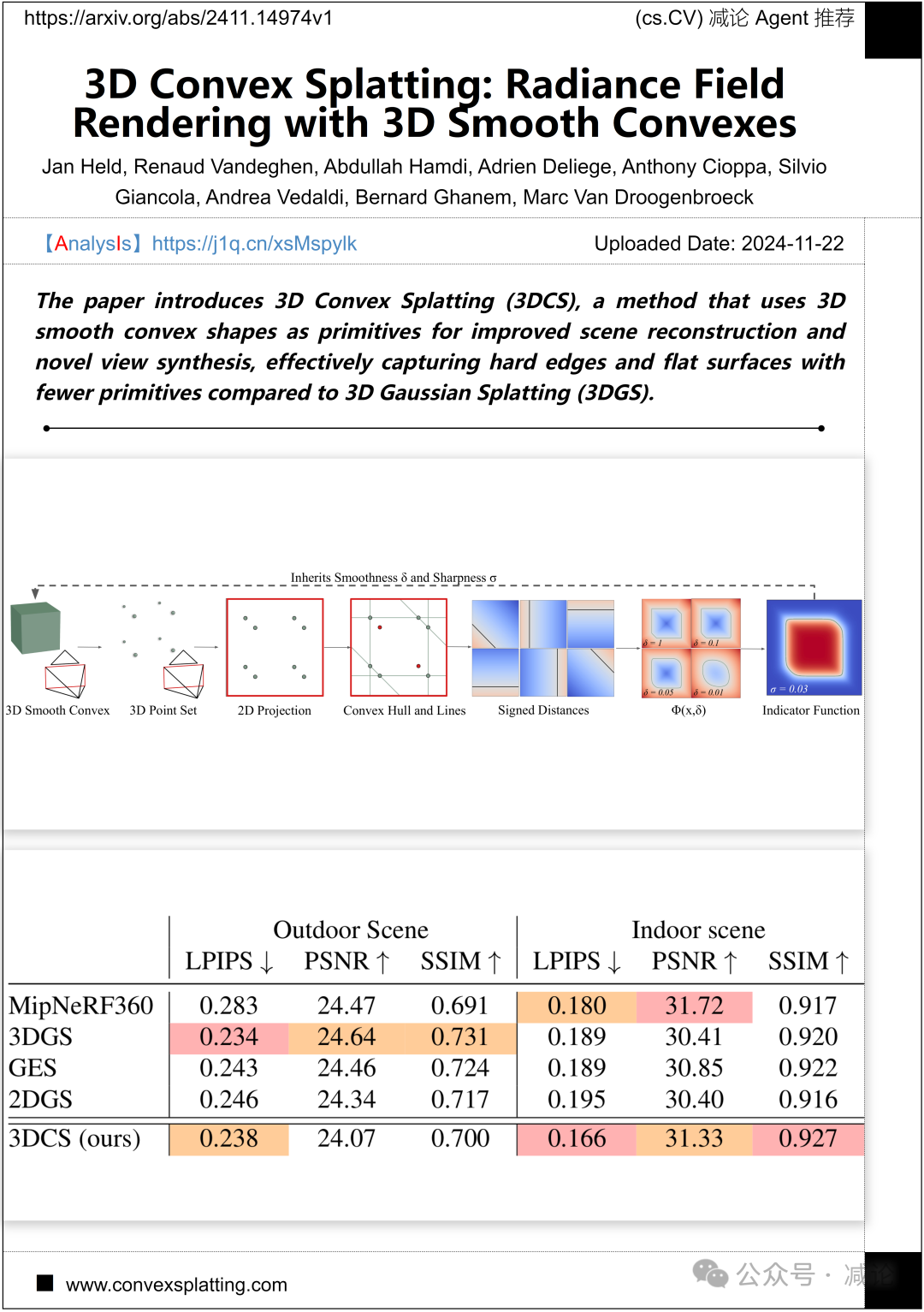
列日大学、牛津大学和沙特阿拉伯科技大学联合提出了3D Convex Splatting (3DCS)方法。这一技术通过使用3D平滑凸形基元,有效改进场景重建和新视图合成。与传统的3D Gaussian Splatting (3DGS)方法相比,3DCS能够以更少的基元准确捕捉硬边缘和平面特征。
【Bohr精读】
https://j1q.cn/xsMspylk
【arXiv链接】
http://arxiv.org/abs/2411.14974v1
【代码地址】
www.convexsplatting.com

北京航空航天大学、香港大学和香港中文大学联合介绍了VideoEspresso,这是一种新颖的VideoQA数据集。该数据集具备多模态注释,并采用混合LVLMs协作框架。通过自适应选择核心帧和使用链式思维推理,VideoEspresso显著增强了视频推理能力。
【Bohr精读】
https://j1q.cn/3NsUKdB7
【arXiv链接】
http://arxiv.org/abs/2411.14794v1
【代码地址】
https://github.com/hshjerry/VideoEspresso

厦门大学推出了XBind,一个通用框架,用于从任意模态生成3D对象。该框架通过跨模态预对齐技术和创新的模态相似性损失,提高了任意模态到3D生成的对齐效果和生成质量,支持文本、图像、音频等多种输入形式。
【Bohr精读】
https://j1q.cn/9KJZBY2X
【arXiv链接】
http://arxiv.org/abs/2411.14715v1
【代码地址】
https://zeroooooooow1440.github.io/
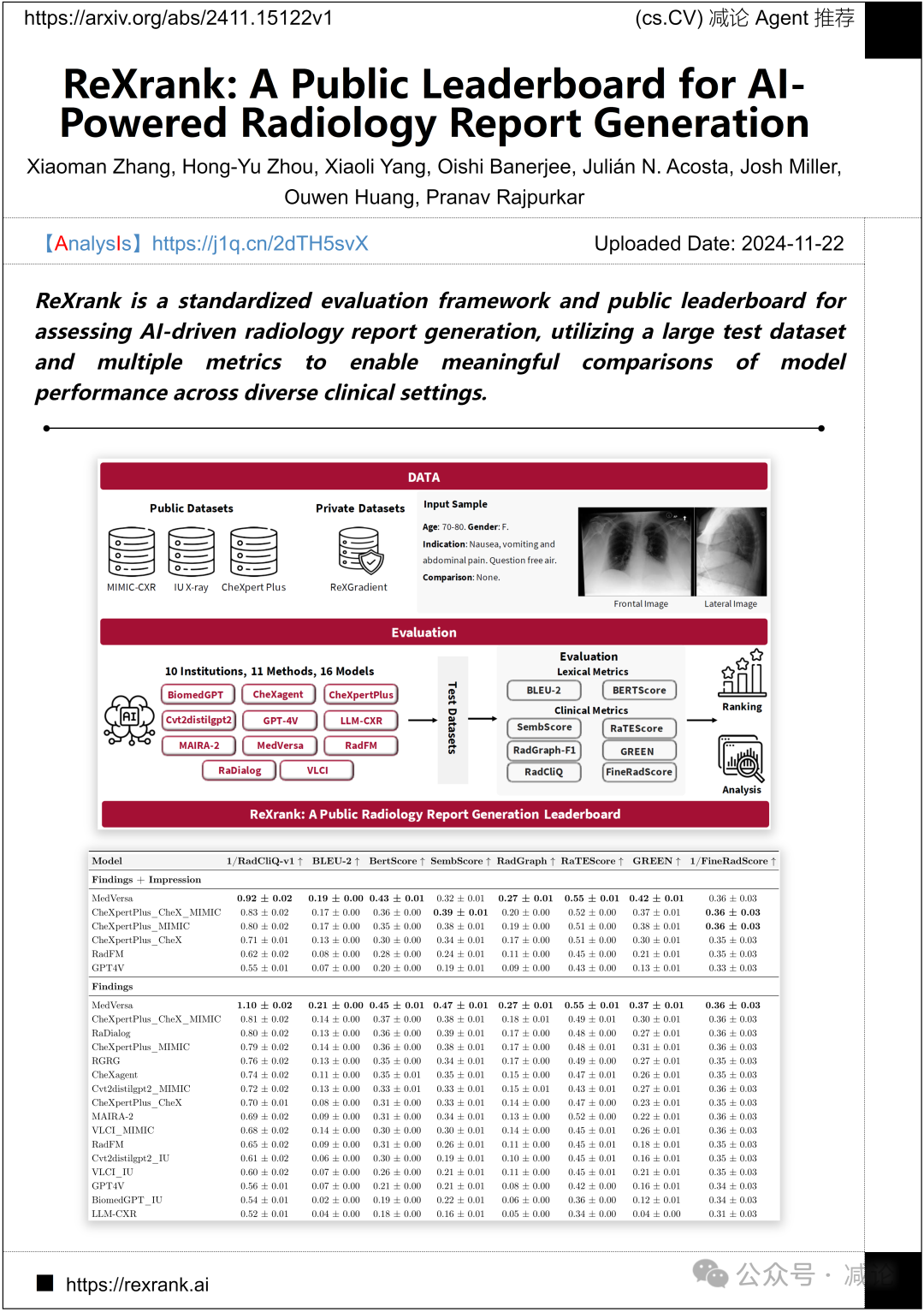
哈佛医学院和Gradient Health联合推出了ReXrank,一个用于评估AI生成放射学报告的标准化框架和公共排行榜。该框架基于大型测试数据集和多种评价指标,支持在不同临床环境中对模型性能进行有效比较。
【Bohr精读】
https://j1q.cn/2dTH5svX
【arXiv链接】
http://arxiv.org/abs/2411.15122v1
【代码地址】
https://rexrank.ai

香港大学、北京航空航天大学和清华大学提出了一种利用大型扩散模型在UV空间生成高分辨率纹理贴图的方法。该模型结合卷积和注意力层的架构,支持通过文本提示和单视图图像生成高质量纹理贴图。
【Bohr精读】
https://j1q.cn/Wx8ROJ0P
【arXiv链接】
http://arxiv.org/abs/2411.14740v1
【代码地址】
http://cvmi-lab.github.io/TEXGen/
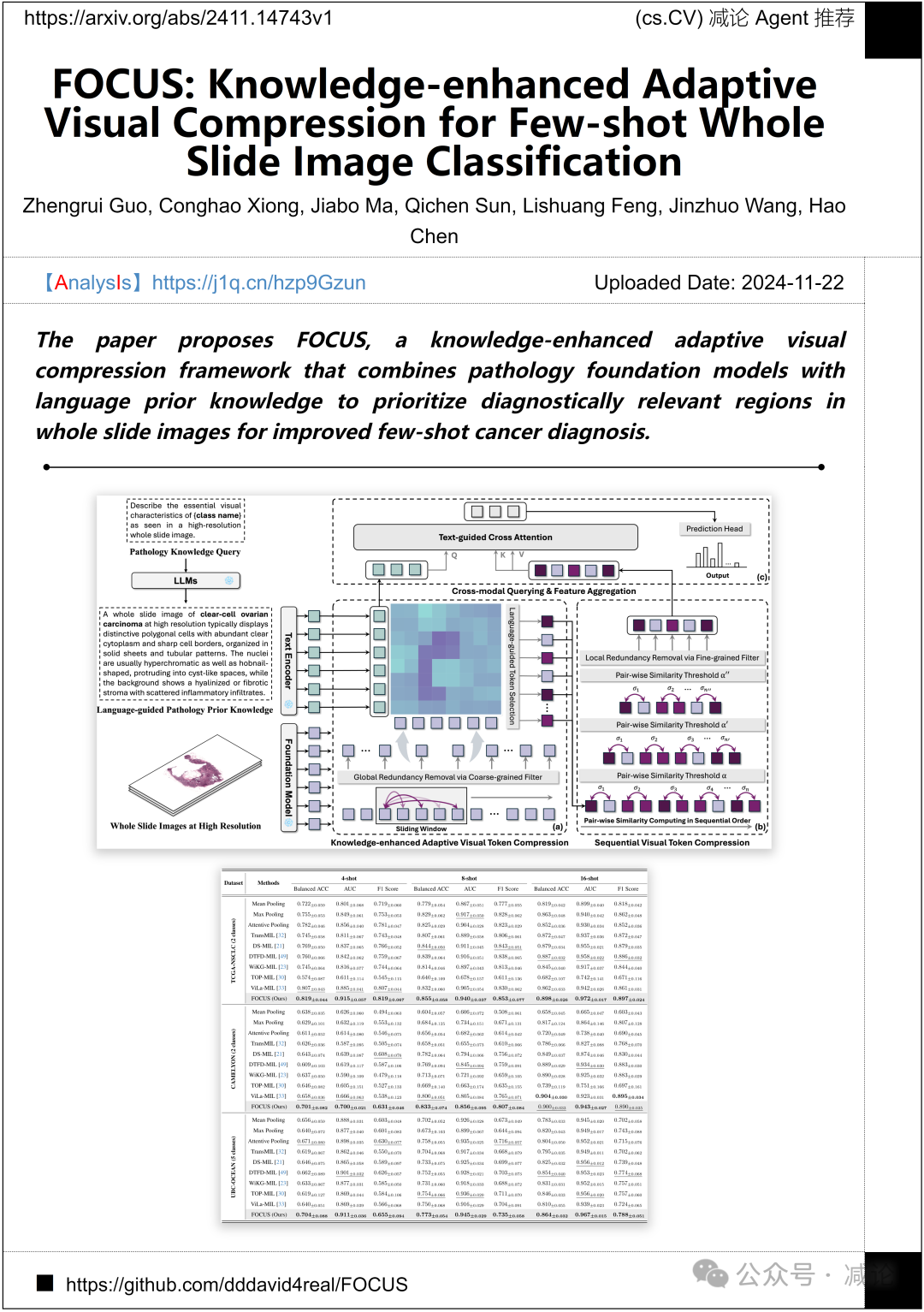
香港科技大学、香港中文大学和北京协同创新研究院联合提出了FOCUS,这是一种知识增强的自适应视觉压缩框架。该框架将病理基础模型与语言先验知识相结合,以优先处理全片图像中与诊断相关的区域,从而改进小样本癌症诊断。
【Bohr精读】
https://j1q.cn/hzp9Gzun
【arXiv链接】
http://arxiv.org/abs/2411.14743v1
【代码地址】
https://github.com/dddavid4real/FOCUS
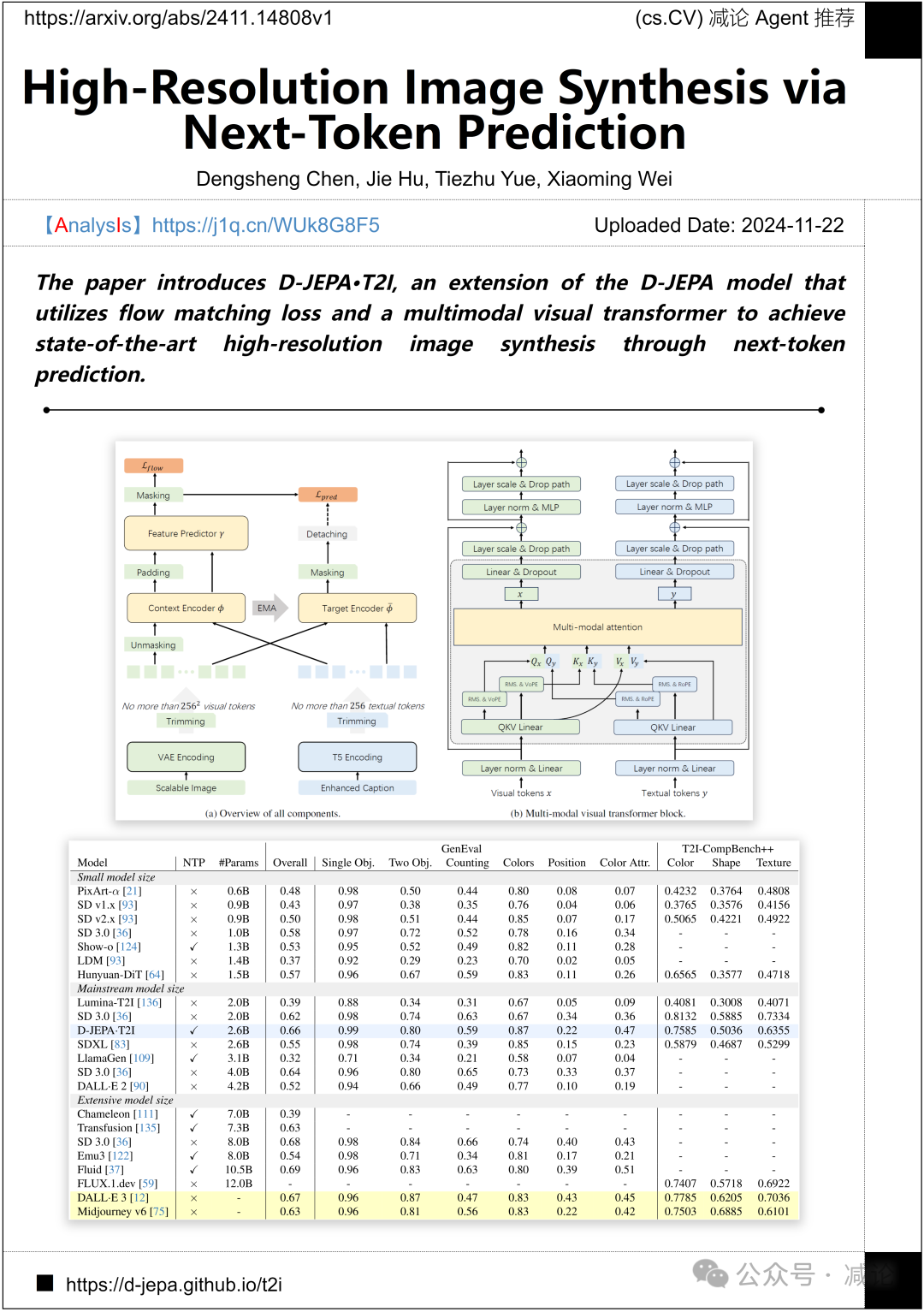
美团介绍了D-JEPA·T2I,这是一种D-JEPA模型的扩展。该论文利用流匹配损失和多模态视觉transformer,通过对下一个token预测,实现了最先进的高分辨率图像生成。
【Bohr精读】
https://j1q.cn/WUk8G8F5
【arXiv链接】
http://arxiv.org/abs/2411.14808v1
【代码地址】
https://d-jepa.github.io/t2i
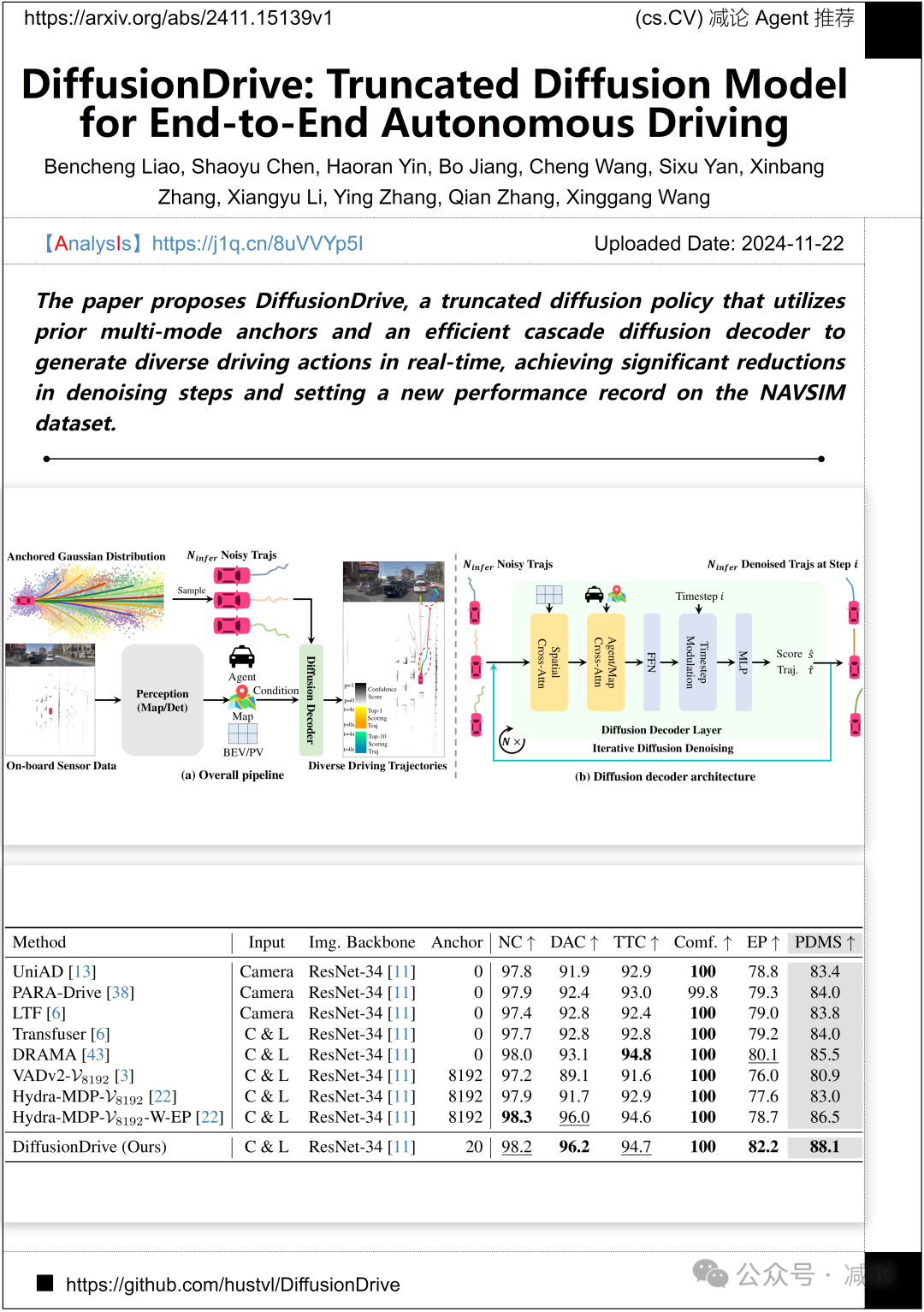
华中科技大学与地平线机器人联合提出了DiffusionDrive,一种基于截断扩散的策略。该方法利用先验多模态锚点和高效的级联扩散解码器,显著减少去噪步骤,实现了实时生成多样化驾驶动作,并在NAVSIM数据集上取得了新的性能记录。
【Bohr精读】
https://j1q.cn/8uVVYp5I
【arXiv链接】
http://arxiv.org/abs/2411.15139v1
【代码地址】
https://github.com/hustvl/DiffusionDrive
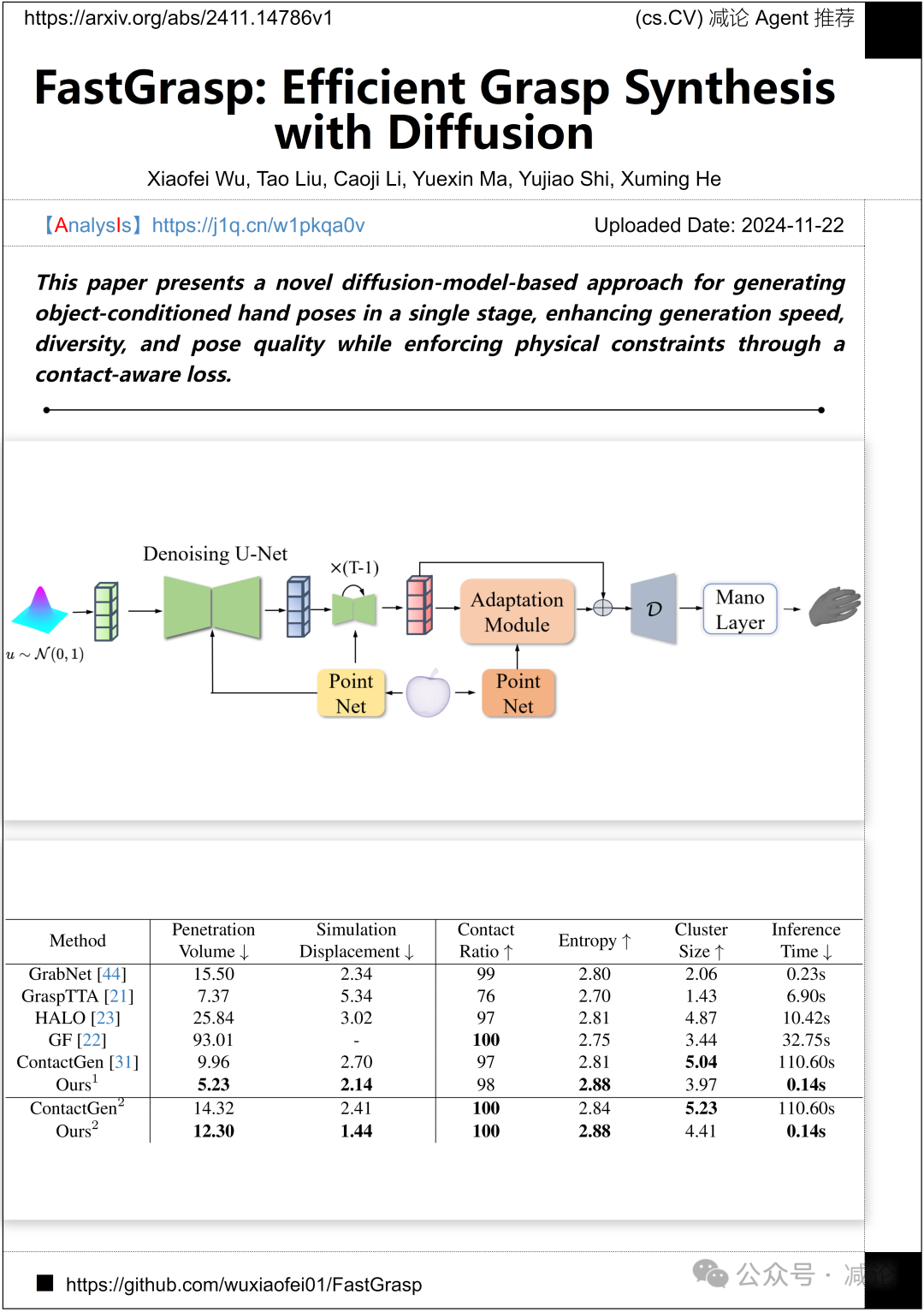
上海科技大学和上海智能视觉与成像工程研究中心提出了一种基于扩散模型的单阶段生成对象条件手部姿势的新方法。该方法通过接触感知损失引入物理约束,显著提升了生成速度、多样性和姿势质量。
【Bohr精读】
https://j1q.cn/w1pkqa0v
【arXiv链接】
http://arxiv.org/abs/2411.14786v1
【代码地址】
https://github.com/wuxiaofei01/FastGrasp

北卡罗来纳大学教堂山分校推出了VideoRepair,一个与模型无关的视频优化框架。该框架通过评估、规划、分解和局部优化四个阶段,识别并纠正文本与视频的不匹配,大幅提升了流行基准上的对齐指标。
【Bohr精读】
https://j1q.cn/D31sncfu
【arXiv链接】
http://arxiv.org/abs/2411.15115v1
【代码地址】
https://video-repair.github.io
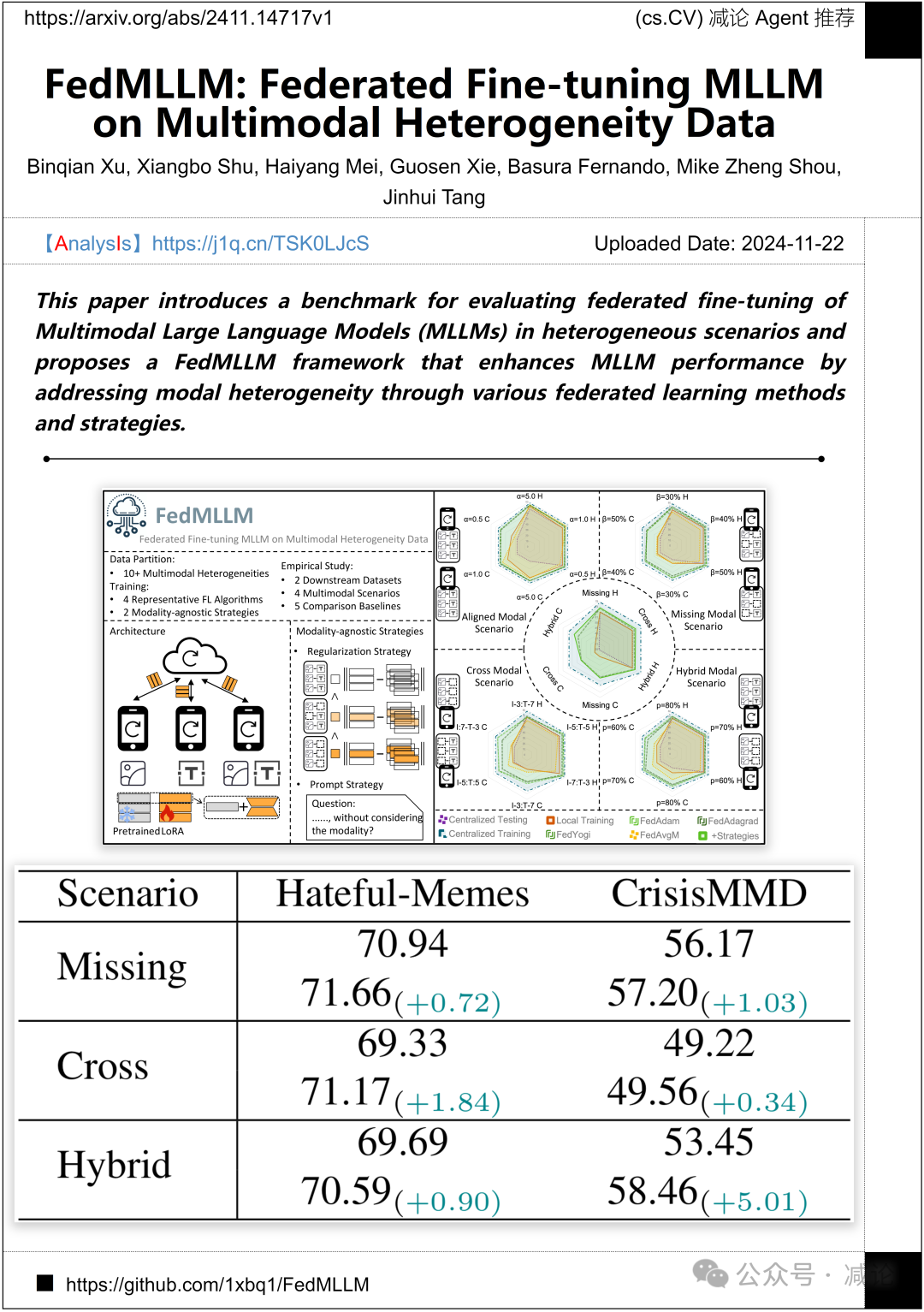
南京理工大学、新加坡国立大学和高性能计算研究所提出了一种用于评估多模态大语言模型(MLLMs)在异构场景下联邦微调的基准。研究团队开发了名为FedMLLM的框架,通过结合多种联邦学习方法与策略,解决了模态异构性问题,显著提升了MLLM的性能。
【Bohr精读】
https://j1q.cn/TSK0LJcS
【arXiv链接】
http://arxiv.org/abs/2411.14717v1
【代码地址】
https://github.com/1xbq1/FedMLLM
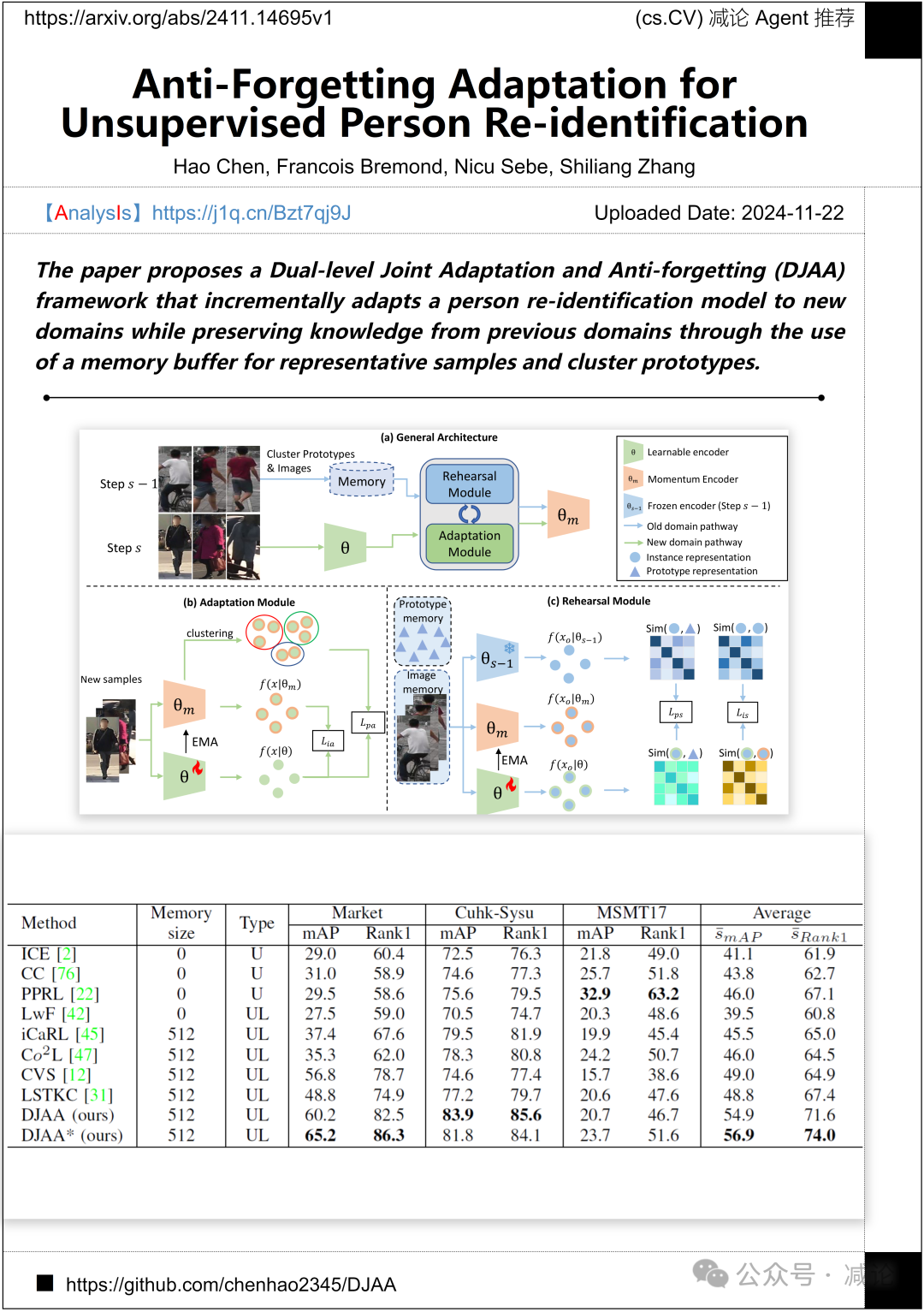
北京大学、Inria和特伦托大学联合提出了双层联合适应和抗遗忘(DJAA)框架。该框架利用包含代表性样本和聚类原型的记忆缓冲区,在逐步适应新领域的同时有效保留先前领域的知识,为领域适应和知识保留提供了高效的解决方案。
【Bohr精读】
https://j1q.cn/Bzt7qj9J
【arXiv链接】
http://arxiv.org/abs/2411.14695v1
【代码地址】
https://github.com/chenhao2345/DJAA
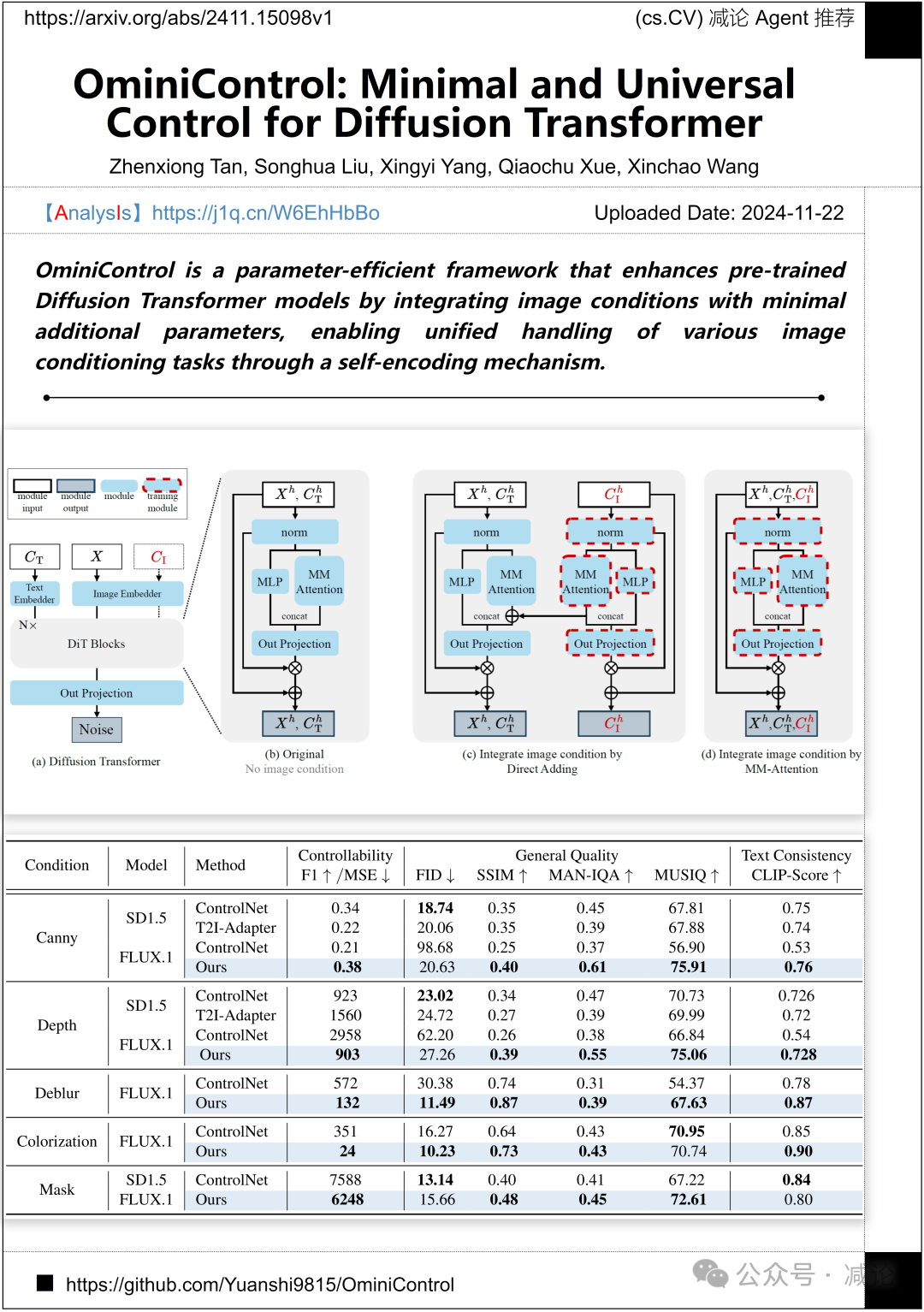
新加坡国立大学推出了OminiControl方法,一个参数高效的框架。该方法通过整合图像条件,仅增加极少的参数,从而增强了预训练的Diffusion Transformer模型,并通过自编码机制实现对多种图像条件任务的统一处理。
【Bohr精读】
https://j1q.cn/W6EhHbBo
【arXiv链接】
http://arxiv.org/abs/2411.15098v1
【代码地址】
https://github.com/Yuanshi9815/OminiControl
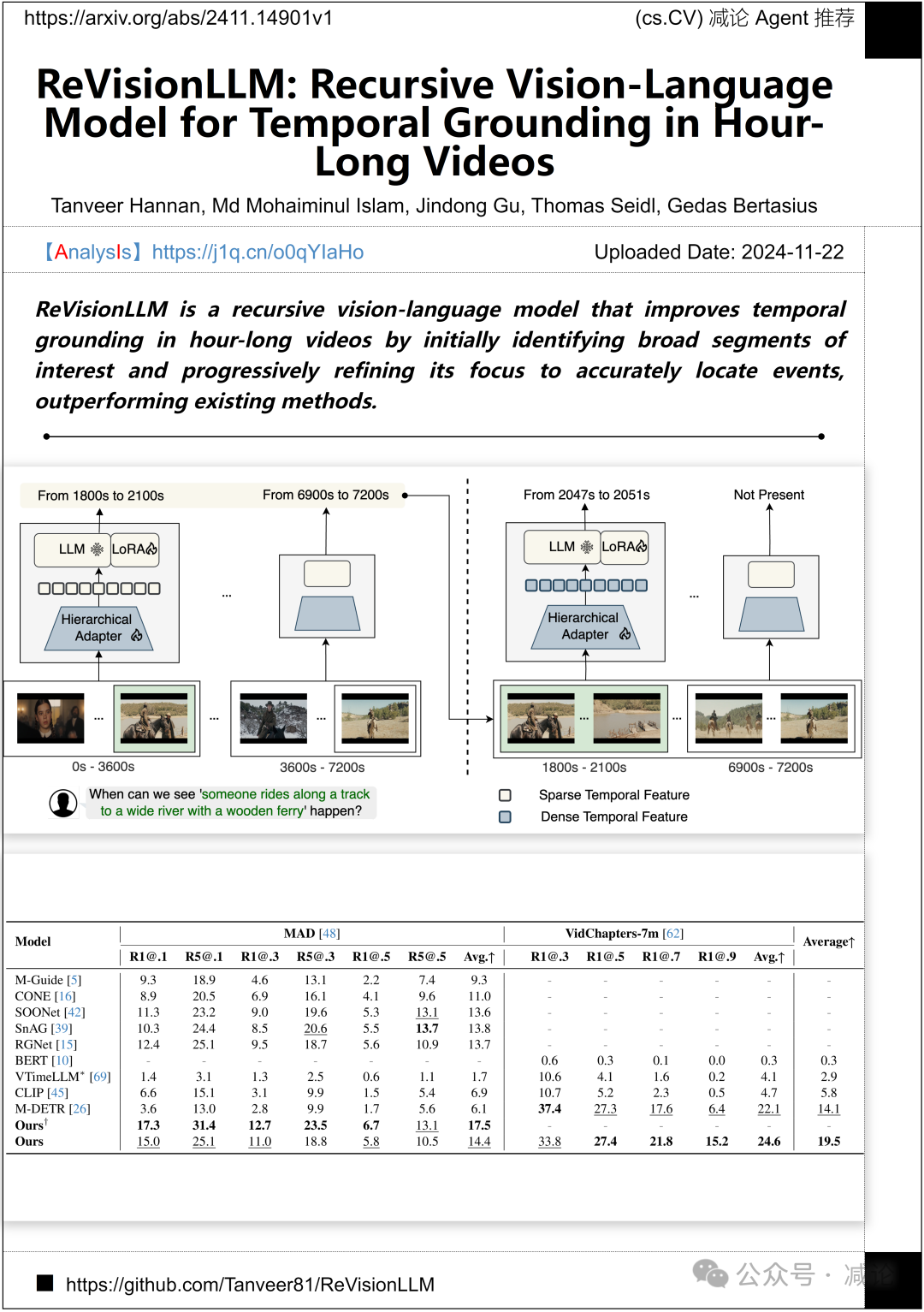
慕尼黑大学、北卡罗来纳大学教堂山分校和牛津大学联合推出了ReVisionLLM,一种递归视觉语言模型。该模型通过先识别广泛感兴趣片段,再逐步细化焦点,实现了在长达一小时的视频中精确定位事件,从而提升了时间定位性能。实验表明,ReVisionLLM在性能上优于现有方法,为视频分析提供了高效的新方案。
【Bohr精读】
https://j1q.cn/o0qYIaHo
【arXiv链接】
http://arxiv.org/abs/2411.14901v1
【代码地址】
https://github.com/Tanveer81/ReVisionLLM

上海海事大学、中国科学院和弗里德里希–亚历山大大学埃尔朗根–纽伦堡提出了CMPAGL,一种用于遥感文本–图像检索的跨模态预对齐方法。该方法通过Gswin Transformer模块捕捉多尺度特征,简化模态融合训练,并结合相似度矩阵重加权算法和增强的三元组损失函数,提高了检索性能。
【Bohr精读】
https://j1q.cn/iFwQN0R5
【arXiv链接】
http://arxiv.org/abs/2411.14704v1
【代码地址】
https://github.com/ZbaoSun/CMPAGL
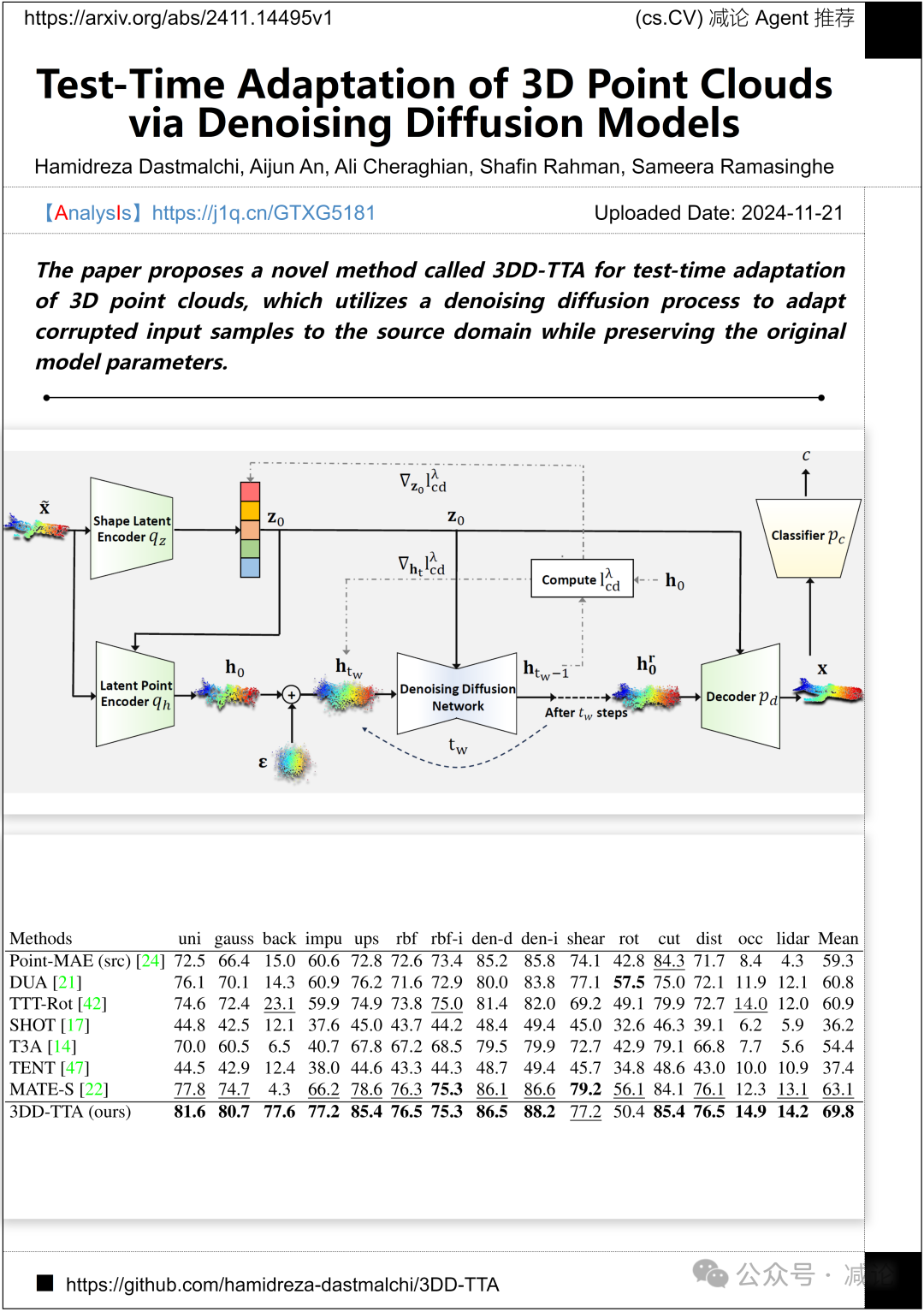
约克大学、数据61-CSIRO和阿德莱德大学联合提出了3DD-TTA,一种用于3D点云测试时自适应的新方法。该方法通过去噪扩散过程将损坏的输入样本适配到源域,同时保留原始模型参数,提升了3D数据处理的效果。
【Bohr精读】
https://j1q.cn/GTXG5181
【arXiv链接】
http://arxiv.org/abs/2411.14495v1
【代码地址】
https://github.com/hamidreza-dastmalchi/3DD-TTA

西湖大学、Salesforce AI研究和莱斯大学联合提出了DyCoke,一种针对视频大语言模型的无训练token压缩方法。DyCoke通过合并跨帧冗余token和选择性修剪空间冗余token,优化了token表示,实现了显著的推理加速和内存占用减少,同时保持了性能。
【Bohr精读】
https://j1q.cn/c67Oz4ii
【arXiv链接】
http://arxiv.org/abs/2411.15024v1
【代码地址】
https://github.com/KD-TAO/DyCoke

欢迎关注减论,持续输出有深度的人工智能极减理解,提升信息获取效率和认知维度。看完点颗小星星再走呗~