
“IMM: An Imitative Reinforcement Learning Approach with Predictive Representation Learning for Automatic Market Making”
市场做市(MM)是通过持续下单以最大化风险调整收益的过程,面临库存风险、逆向选择风险和未执行风险等挑战。传统MM方法依赖强假设的数学模型,而深度强化学习(RL)为适应市场动态的MM策略提供了新思路。
本文提出模仿市场做市者(IMM)框架,结合次优信号专家和直接策略互动的知识,设计基于预测信号的专家策略,通过RL与模仿学习结合进行高效训练。在四个真实市场数据集上的实验结果显示,IMM优于现有RL市场做市策略。


论文地址:https://www.ijcai.org/proceedings/2024/0663.pdf
摘要
通过强化学习(RL)市场做市(MM)在金融交易中受到关注,但现有方法多集中于单一价格层策略,难以应对频繁的订单取消和排队优先权丧失。多价格层策略更符合实际交易场景,但其复杂性使得RL训练面临挑战。
本文提出模仿市场做市者(IMM)框架,结合次优信号专家和直接策略互动的知识。IMM引入有效的状态和动作表述,编码多价格层订单信息,并整合表示学习单元以捕捉市场短期和长期趋势,降低不利选择风险。设计基于预测信号的专家策略,通过RL与模仿学习结合进行高效训练。在四个真实市场数据集上的实验结果显示,IMM优于现有RL市场做市策略。
简介
市场做市(MM)是通过持续下单以最大化风险调整收益的过程,面临库存风险、逆向选择风险和未执行风险等挑战。传统MM方法依赖强假设的数学模型,而深度强化学习(RL)为适应市场动态的MM策略提供了新思路。现有RL研究多集中于单一价格策略,频繁取消订单导致订单优先权损失,实际交易中需采用多价格层次策略。
本文提出模仿市场做市者(IMM)框架,结合状态表示学习单元(SRLU)和模仿RL单元(IRLU),解决多价格层次策略的MM问题。IMM通过收集市场信息预测短期和长期趋势,平衡风险与收益,制定报价策略。
主要贡献包括:将MM过程建模为马尔可夫决策过程(MDP),提出SRLU和IRLU以提取专家交易知识,实验结果显示IMM在风险调整收益和逆向选择比率上优于基线方法。
相关工作
传统的市场制造(MM)方法将其视为随机最优控制问题,通常可解析求解。Avellaneda-Stoikov模型假设中价演变为无漂移扩散过程,利用Hamilton-Jacobi-Bellman方程推导最优报价的闭式近似。Guéant等人考虑了带库存限制的AS模型变体。这些方法依赖于强假设和多个需在历史数据上校准的参数。采用强化学习(RL)等更先进的方法,能够无模型地直接从数据中学习,显得更具前景。
深度强化学习(RL)在量化交易中日益流行,许多市场制造(MM)策略采用单一价格水平策略。一些研究提前定义了动作空间,如Spooner等提出的八元组半价差。半价差策略选择连续的半价差,但频繁的订单取消和重新下单会导致排队位置损失。为解决此问题,采用梯形策略在两个价格区间内放置单位交易量。最新研究使用多价格水平MM策略,DRL OS代理决定是否保留每个价格水平的交易量。多价格水平策略的复杂动作空间导致探索效率低下,尤其在动态复杂的市场环境中。
问题定义
将多价格水平策略的市场制造(MM)问题形式化为马尔可夫决策过程(MDP)。引入稳定的限价单(LOB)参考价格及新颖的状态/动作空间。说明MM程序的转移动态,支持多价格水平的订单堆叠。提出混合奖励函数以降低多样化风险。
稳定的参考价格
市场参与者在发送订单前分析多种量,最重要的是目标价格与参考市场价格(通常是中间价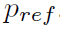 )之间的距离。订单簿(LOB)可表示为2K维向量,K为每侧可用限价的数量,为中心点,决定了限价Q ± i的位置。买入限价在买方,卖出限价在卖方,Q i的队列长度为l i。
)之间的距离。订单簿(LOB)可表示为2K维向量,K为每侧可用限价的数量,为中心点,决定了限价Q ± i的位置。买入限价在买方,卖出限价在卖方,Q i的队列长度为l i。
现有的市场制造方法通常将市场中间价作为,但中间价的频繁波动导致与价格水平i相关的具体价格也频繁变化。的变化使得l i迅速转变为相邻值,影响从LOB中提取有效微观市场信息的能力。需要定义一个稳定的参考价格。
设定参考价格 的方法:
-
当市场价差为奇数时,
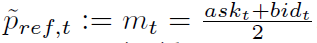 。
。 -
当市场价差为偶数时,
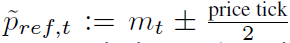 ,符号选择基于与前值的接近度。
,符号选择基于与前值的接近度。
在每个回合开始时,设定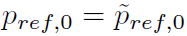 。
。
的更新条件:当中间价格 m_t 增加(或减少)时,只有在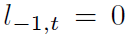 (或 (
(或 (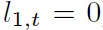 )时更新。
)时更新。
变化的三种事件:
-
在买卖限价单插入时,且
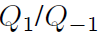 为空。
为空。 -
取消最后一个限价单。
-
市场单消耗最后一个限价单。
LOB(限价单簿)支持空限价单,提供更稳定的,有效编码 LOB 和多价格层次订单。

MDP定义
状态空间
为了降低逆向选择风险,状态空间需包含宏观市场信息。在时间步t,IMM代理观察的状态为
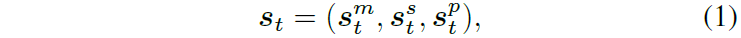
-
s_t^m:市场变量,表示当前市场状态。
-
s_t^s:信号变量,包括多层次辅助预测信号。
-
s_t^p:私人变量,包括当前库存z_t、队列位置和订单量。
队列位置值定义为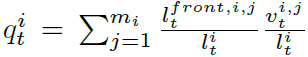 ,表示在价格水平i的订单的加权平均队列位置。IMM通过当前报价信息学习,避免频繁取消和替换订单。
,表示在价格水平i的订单的加权平均队列位置。IMM通过当前报价信息学习,避免频繁取消和替换订单。
行动空间
通过在最佳买卖价水平之外预留良好的排队位置,可以控制不利选择和未执行风险。实践者通常采用多价格水平的限价单堆叠策略。IMM引入了一种动作编码,能够在低维空间中表达复杂的多价格水平策略。动作a_t包括目标报价中间价m*_t、价差δ*_t、买入价格?_bid_t和卖出价格?_ask_t。代理可以灵活调整报价的宽度和不对称性,以适应参考价格。
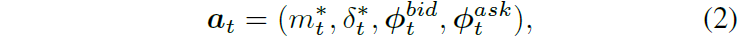

转移过程
将MM视为一个情景强化学习任务。过程步骤:
-
随机选择开始时间,初始化环境和模拟器。
-
代理选择希望在限价单簿(LOB)中的交易量和价格水平。
-
将期望位置转化为订单,取消过量订单并下新限价单。
-
在市场重放模拟器中按价格时间优先匹配订单。
-
更新代理的现金和资产库存,跟踪盈亏。
-
重复选择和匹配,直到情景结束。
不同效用的奖励功能
市场做市商的决策过程涉及执行概率、价差、库存风险和交易所补偿等权衡。利润与损失(PnL)由已实现和浮动PnL组成,公式中涉及市场中价、成交价格和当前库存。为减轻库存风险,采用截断库存惩罚,仅在库存超过常数C时施加惩罚。市场做市商的主要收入来源是交易所补偿,鼓励交易的奖金项被纳入奖励机制。最终奖励函数结合PnL、补偿和库存惩罚,以满足市场做市商的多样化需求。
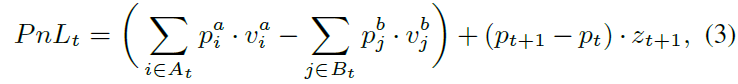
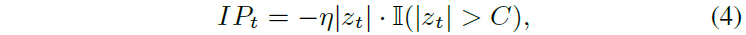
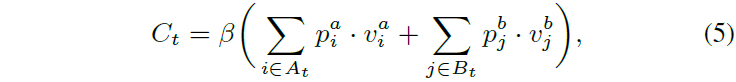
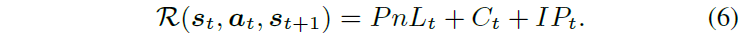
模仿做市商(IMM)
IMM方法包括两个组成部分:
-
SRLU:旨在预测多粒度信号并从嘈杂市场数据中提取有价值的表示。
-
MM政策学习:结合强化学习和模仿学习目标。
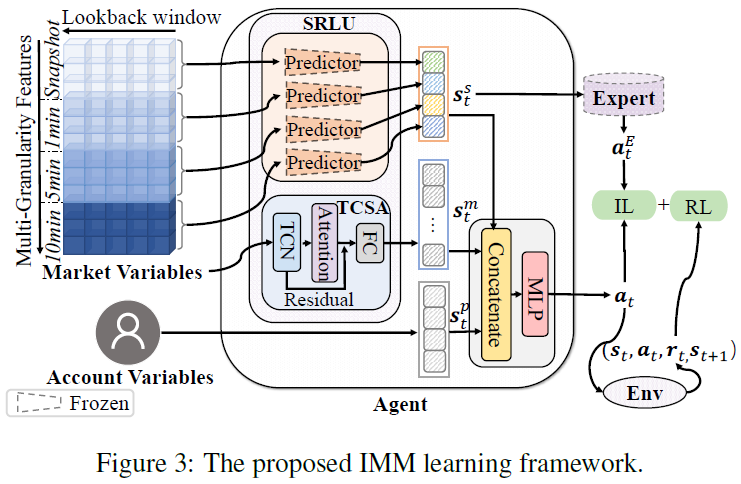
状态表示学习单元(SRLU)
信号生成
IMM通过预训练监督学习模型生成短期和长期趋势信号,采用LightGBM模型。生成四个多粒度趋势信号:y20(1/6分钟)、y120(1分钟)、y240(2分钟)、y600(5分钟)。在训练强化学习策略时,预训练预测器的参数被冻结,输出作为辅助信号变量。
基于注意的表征学习
深度强化学习算法数据效率低,提出了时序卷积和空间注意力(TCSA)网络以提取市场数据中的有效特征。TCSA结构包括时序卷积网络(TCN)用于提取时间轴关系,具有并行计算和长效记忆的优点。TCN处理后得到的输出张量为H?∈RF×L,F为特征维度,L为时间维度。采用注意力机制处理特征间的空间关系,计算空间注意力权重S?,并通过行归一化表示特征间的相关性。使用ResNet结构解决深度学习中的梯度消失问题,最终表示为H=S×H?+x。最终表示s m通过全连接层转换为维度F′,并与信号状态ss和私有状态sp进行拼接。
模仿强化学习单元(IRLU)
基于信号的专家
LTIIC策略是一种基于库存水平和趋势预测信号的市场报价调整策略。当库存z_t在[-d, d]范围内时,报价公式为:
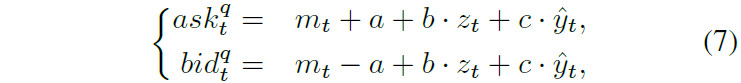
在短期上涨趋势中,ask限价单更易执行,因此在bid侧采用窄价差,ask侧采用宽价差以降低逆向选择风险。参数b用于调节库存水平,参数a决定报价差距。当库存z_t达到或超过d时,仅在相反侧发布订单。
策略学习
使用actor-critic RL框架,critic评估actor的动作,通过价值函数优化actor以最大化critic输出的值。基于TD3方法,使用离线策略学习,优化价值函数Q,采用双延迟方式从重放缓冲区和专家数据集中采样。在高维状态空间和复杂动作空间中,单纯的RL目标难以学习,因此引入模仿学习目标以增强策略学习。通过模仿专家数据集中的行为,代理能够更有效地探索和学习策略,提升在高度随机市场环境中的表现。
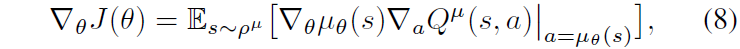
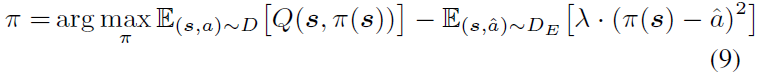
实验
实验设置
实验数据来源于上海期货交易所的FU、RB、CU和AG期货的现货月合约,包含5深度的限价订单簿和500毫秒的实时交易信息。数据时间范围为2021年7月至2022年3月(126个交易日),训练集占80%,验证集占20%;测试集为2022年4月至7月(60个交易日)。代理每500毫秒调整2级买卖报价,总交易量固定为N=20单位,单个回合长度为1.5小时,共T=10800步。
基线
比较IMM与三种基于规则的基准和两种最先进的RL方法。
-
FOIC:固定偏移与库存约束策略,遵循库存限制d进行报价。
-
LIIC:基于库存的线性报价策略,报价根据库存水平调整。
-
LTIIC:IMM采用的专家策略。
-
RL DS:单一价格水平的RL策略。
-
DRL OS:多价格水平的RL策略,决定是否在每个价格水平保留一单位交易量。
评估指标
采用四个财务指标评估市场做市(MM)策略表现:
-
Episodic PnL (EPnL):评估MM代理的盈利能力,计算公式为
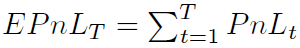 。
。
-
Mean Absolute Position (MAP):衡量库存风险,定义为
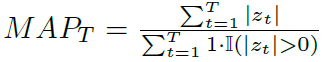
-
Return Per Trade (RPT):评估捕捉价差的能力,标准化处理。
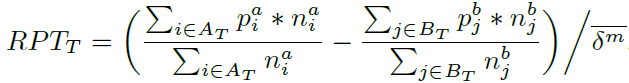
-
PnL-to-MAP Ratio (PnLMAP):同时考虑盈利能力和库存风险,计算公式为
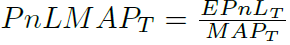
结果

为了公平比较,调优了方法的超参数以最大化PnLMAP T值,结果显示IMM在盈利和风险管理方面显著优于基准。
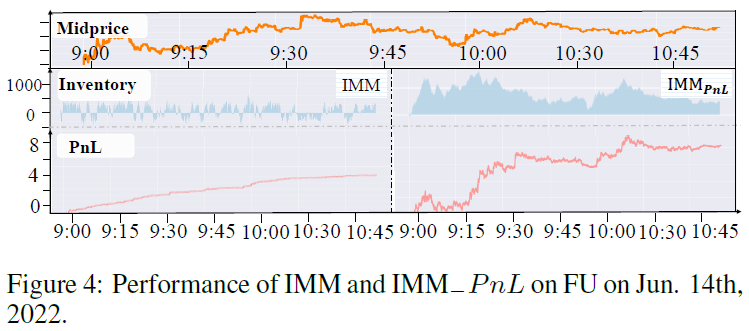
在RB数据集上,IMM获得最高终端财富和风险调整回报,尽管MAP略高于专家和两种RL方法。多价格水平的RL代理DRL OS和IMM优于单价格水平的RL DS,显示多价格策略的优势。
在FU数据集上,IMM不仅实现最高终端财富,还展现最佳的回报风险比和捕获价差能力,同时保持较低的库存水平。RL策略表现良好,而基于规则的策略在大多数交易日未能盈利。IMM在波动市场中实现了稳定的利润和可接受的库存控制,库存波动在零附近,表现理想。
在CU和AG市场的MM任务中,IMM在终端财富和风险调整回报方面显著优于基准。
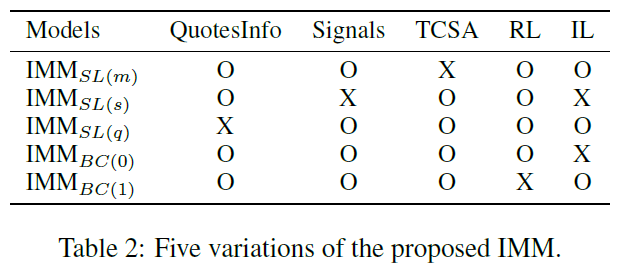
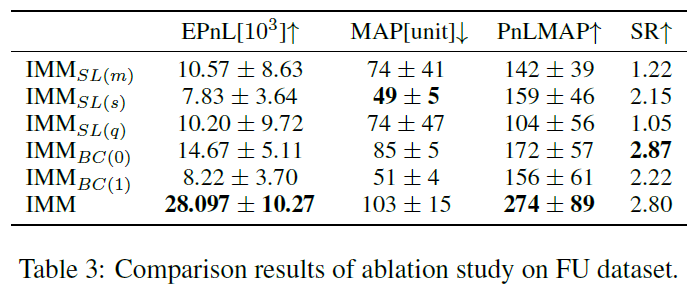
消融分析
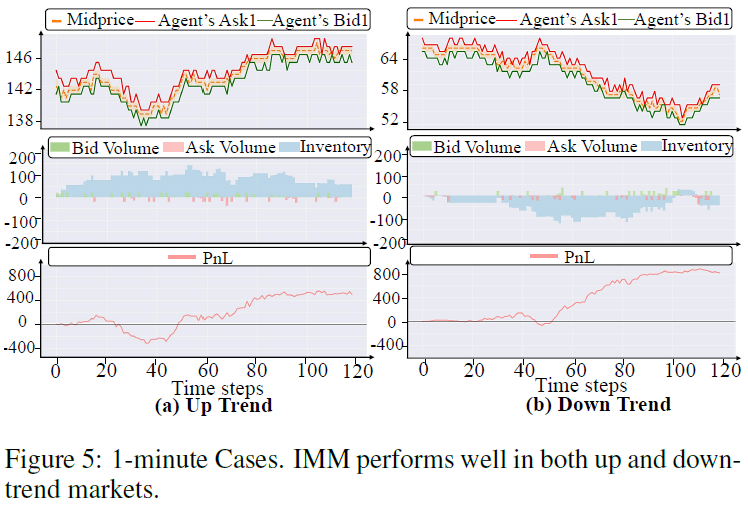
比较了提出的IMM模型与五种变体,结果见表3,表2中定义了各个模型组件的含义。SR(夏普比率)用于评估模型表现,表明引入多粒度信号对MM策略性能提升的重要性。图5展示了IMM在不同市场趋势下的表现,显示其在上涨趋势中提前保持多头头寸,并在下跌市场中有效降低逆向选择风险。
状态表示
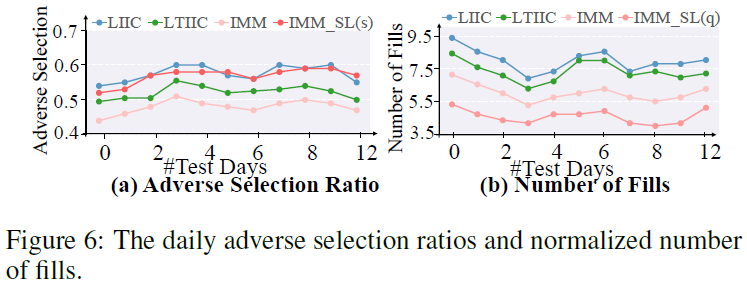
计算不利选择比率(adv ratio)以评估辅助信号对性能的影响,定义为在最后一个时间间隔内的成交数与不利成交数之比。不利成交指在最佳买价下跌前执行的限价买单,或在最佳卖价上涨前执行的限价卖单。多粒度预测信号有助于减轻不利选择,因为它们提供市场状况的有效信息,促进在捕捉价差和追随趋势之间的灵活权衡。多价格层级订单的信息有助于提高成交量,减少频繁取消订单,保持排队位置。
IRLU
IMM BC(·)与IMM的比较结果表明,从专家提取额外知识和高效探索在复杂金融任务中至关重要。IMM显著优于专家LTIIC策略。RL代理在初始训练阶段面临识别和维持可行交易策略的挑战。追求模仿学习目标的训练有助于代理获得良好奖励并从中学习。
奖励函数
研究了三种不同奖励函数对IMM的影响:IMM P NL(仅PnL奖励)、IMM P NL+C(PnL与补偿奖励结合)、IMM P NL+IP(PnL与截断库存惩罚结合)。选择最大PnLMAP值的超参数进行模型训练,结果在FU数据集上验证了不同奖励公式的有效性。IMM P NL策略表现出较大的库存风险,且日常表现波动,倾向于追逐趋势,导致库存过大(>1000),出样本表现差。截断库存惩罚项对抑制盲目追逐趋势的倾向至关重要。
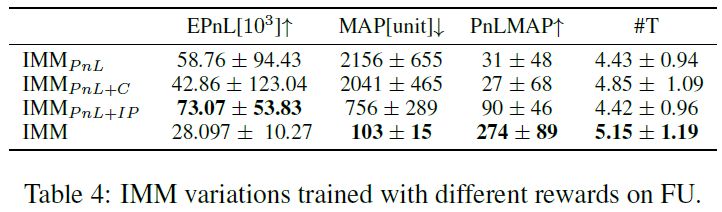
IMM P nL+C策略交易次数#T较IMM P nL多,但面临高库存风险。IMM P nL+IP策略平均终端财富和每笔交易回报最高,但#T最低,对风险厌恶的市场做市商不利。提出的策略在回报风险表现上显著改善,#T较IMM P nL+IP策略多,尽管平均终端财富最低,但稳定性强,适合风险厌恶的市场做市商。提出的策略#T最大,能从交易所获得更多补偿。
总结
本文提出IMM,一种基于强化学习的多价格水平市场制造(MM)策略学习方法。引入高效的状态和动作表示,预训练基于监督学习的预测模型生成多种趋势信号作为辅助观察。使用TCSA网络处理噪声金融数据中的时间和空间关系。从次优专家抽象交易知识,提升状态和动作空间的探索效率。在四个期货市场的实验中,IMM表现优于基准,消融研究验证了各组件的有效性。未来计划考虑订单取消,研究低流动性市场的自动市场制造策略。
我们致力于提供优质的AI服务,涵盖人工智能、数据分析、深度学习、机器学习、计算机视觉、自然语言处理、语音处理等领域。如有相关需求,请私信与我们联系。
请加微信“LingDuTech163”,或公众号后台私信“联系方式”。
关注【灵度智能】公众号,获取更多AI资讯。