收录于话题
本文介绍了一种名为 LlamaLens 的专用大语言模型(LLM),该模型专门针对新闻和社交媒体内容分析任务进行训练和优化。LlamaLens 的目标是辅助记者、事实核查员和社交媒体分析师进行多语言环境下的新闻和社交媒体内容分析。
主要贡献:
-
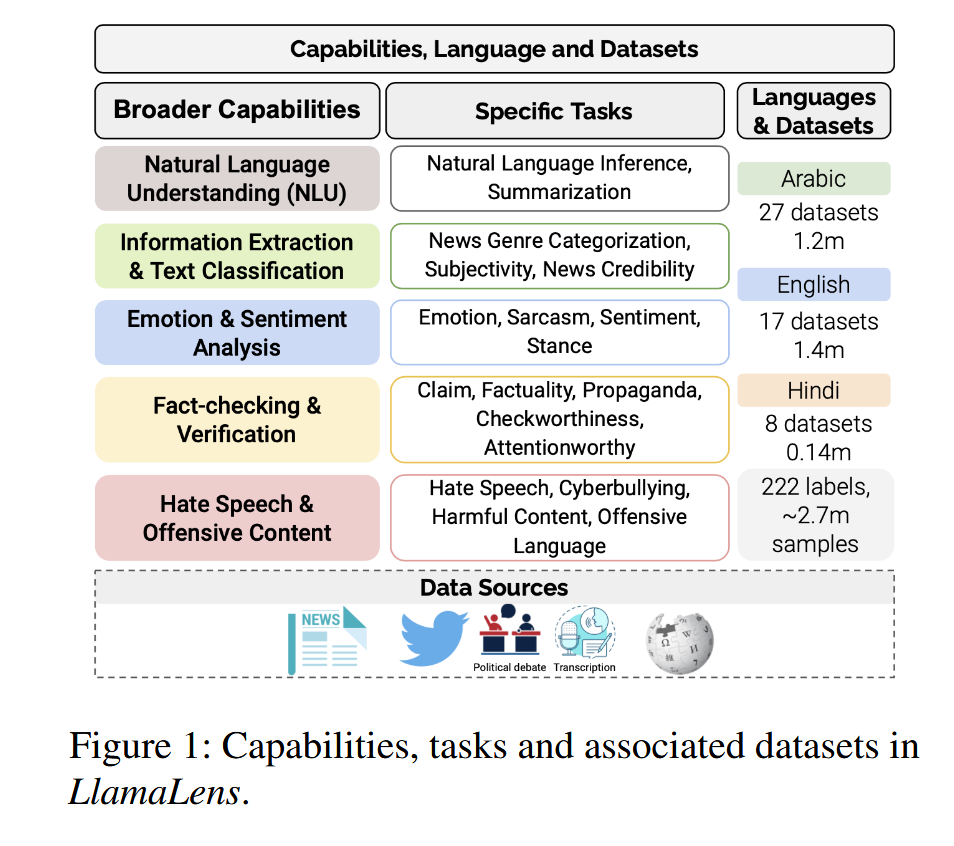
开发并发布 LlamaLens 模型,该模型涵盖 5 个主要能力,对应 19 项任务和 52 个数据集,涉及阿拉伯语、英语和印地语三种语言。 -
利用半监督方法构建并发布一个遵循指令的数据集。 -
在训练过程中探索基于语言、数据集和任务的多种数据打乱技术,并分享研究发现。 -
与 Llama-3.1-8B-Instruct 模型、采用不同打乱方式训练得到的量化模型以及使用数据集特定指标的最先进基线模型进行对比,详细展示实验结果。
1. 引言
大语言模型(LLM)在自然语言处理(NLP)、医疗、金融和法律等多个领域作为通用任务求解器取得了显著成功。然而,在处理特定领域问题时,其能力仍然有限,尤其是在下游 NLP 任务中。研究表明,对指令型下游 NLP 数据集进行微调的模型优于未进行微调的模型。
现有研究主要侧重于资源丰富的语言(如英语)和广泛的领域,而对多语言环境和特定领域的关注较少。为了弥补这一空白,本研究重点开发了一种名为 LlamaLens 的专用 LLM,用于分析多语言环境下的新闻和社交媒体内容。据我们所知,这是首次尝试同时解决领域特异性和多语言性问题,并特别关注新闻和社交媒体。

2. 相关工作
2.1 面向新闻的 LLM
近年来,研究人员探索了 LLM、新闻和社交媒体之间的交叉点,揭示了将 AI 融入新闻报道的机遇和挑战。
-
Brigham 等人和 Breazu 等人研究了 GPT-4 等 LLM 在新闻工作流程中的应用,重点关注伦理、质量影响和叙事生成。 -
LLM 已被应用于新闻制作,聚焦于其优势与伦理挑战。 -
Bloomberg 将 LLM 集成到其新闻制作流程中,旨在提高自动化程度,同时保留准确性、透明性等基本新闻原则。 -
Ding 等人研究了 LLM 在人机协作中的作用,特别是用于生成新闻标题。 -
为了应对 Instagram Reels 和 TikTok 等视觉平台上的内容创作挑战,开发了 ReelFramer(一种多模态写作助手)。 -
Cheng 强调了开发针对新闻报道的定制 LLM 的必要性,并提出了监督微调(supervised fine-tuning)和宪法 AI(constitutional AI)等解决方案。 -
为了促进科学新闻,Jiang 等人提出了一种新方法,利用多个 LLM 之间的协作来提高新闻文章的可读性和清晰度。
2.2 新闻和社交媒体分析
针对新闻和社交媒体分析,研究人员致力于事实核查、有害内容检测和新闻可靠性分类等领域。
-
Quelle 等人证明了 LLM 可以通过检索相关证据和验证声明来进行事实核查。 -
Ibrahim 探索了使用微调后的 LLM(如 Llama-3)来自动分类可靠与不可靠的新闻文章,特别是在西班牙语中。 -
Hsu 等人和 Choi 等人提出的框架通过对话细化方法改进虚假新闻解释,从而解决虚假信息问题。 -
Russo 等人开发的 VerMouth 自动化了社交媒体事实核查,为打击虚假信息的更广泛努力做出了贡献。 -
Zhang 等人提出的专家推荐框架利用多层排名系统与 LLM,在推荐新闻事件专家时平衡可靠性、多样性和全面性。 -
其他举措包括 Botlitica(用于识别政治社交媒体帖子中的宣传性内容)和 JSDRV(专注于立场检测和谣言验证)。 -
Ali 为调查性新闻引入了一种工具,用于检索和总结相关文件,而 Alonso 等人则专注于检测电视节目中框架的使用。 -
Trhlik 等人探索了使用 LLM 进行偏见识别,以解决政治偏见问题。 -
Zeng 等人进行了一项综合研究,突出了 LLM 在社交媒体应用中的使用。
2.3 专用 LLM
Ling 等人强调了开发专用模型的重要性,主要原因在于:
-
获得领域专业知识和能力通常需要多年的培训和经验。 -
因此,用领域知识训练 LLM 对于满足专业级使用至关重要。
Kotitsas 等人探索了微调 LLM 以改进声明检测的方法。
Bao 等人使用精选的知识训练了一个名为 FLLM 的 LLM,重点关注商业和媒体领域。
Wang 等人提出了一个可解释的虚假新闻检测框架,该框架使用 LLM 从对立双方生成和评估理由。
与之前的工作不同,本研究侧重于开发一个针对新闻和社交媒体分析的多任务、多能力专用模型,代表了在这一领域首次尝试,并具备多语言能力。
3. 任务和数据集
3.1 数据收集
-
根据图 1 中所示的关键能力和相关任务选择数据集,并确定与这些任务相匹配的可公开获取的数据集。 -
选择阿拉伯语、英语和印地语三种语言,因为它们在阿拉伯半岛地区占据重要地位,对于分析该地区社交媒体和新闻媒体的语言和文化多样性至关重要。 -
初始收集了 103 个数据集,其中一些由于版本不同而被排除(例如,选择了 ArSarcasm-v2 而不是版本 1)。 -
最终得到 52 个数据集。
数据集来源:
-
社交媒体帖子 -
新闻文章 -
政治辩论和文字记录
数据集规模:
-
约 270 万个样本 -
222 个标签
3.2 预处理
-
对于未预先划分为训练集、开发集和测试集的数据集,按照 70% 训练、20% 测试和 10% 开发进行划分。 -
对于仅包含训练集和测试集的数据集,将训练集进一步划分为 70% 训练、20% 测试和 10% 开发。 -
采用分层抽样方法保持拆分后的类别分布。 -
去除重复项、统一标签(例如,将 check-worthiness 统一为 checkworthiness,将大写转换为小写)并删除少于 3 个字母的条目。 -
最终得到阿拉伯语、英语和印地语的样本数量分别为 120 万、140 万和 14 万。
4. 方法论
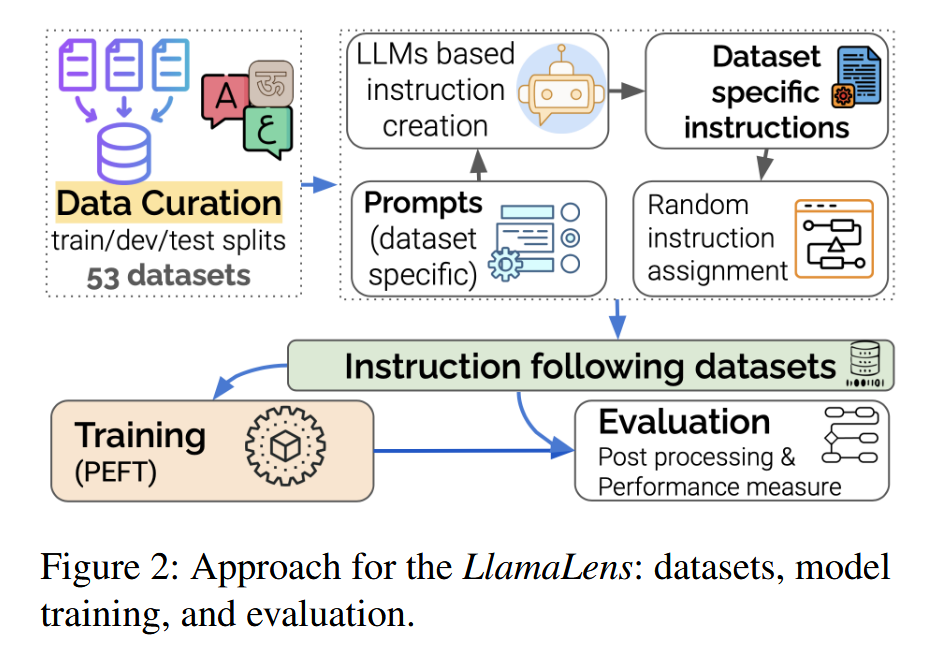
4.1 指令数据集
-
采用 LLM 微调方法,将 LLM 与用户意图和任务进行对齐。 -
指令样本由描述任务的自然语言指令、可选输入和遵循指令的输出组成。 -
为了生成多样化的指令,利用 GPT-4o 和 Claude-3.5 Sonnet 两个高效的闭源 LLM 为每个数据集生成 20 条英语指令。 -
为了确保模型生成符合数据集的指令,向模型提供数据集元数据,包括数据集名称、语言、任务、任务定义和标签空间。 -
为每个数据集的每个训练样本随机选择一条生成的指令,从而保证即使对于同一个输入数据集也能获得多样化的指令风格。 -
最终的指令微调数据集由所有数据集的准备好的指令组成。这些指令将用于创建最终的指令数据集,用于 LLM 微调。
4.2 模型训练
-
本文的实验基于迄今为止最有效的开源 LLM——Llama 3.1,该模型即使在多语言设置下也能表现出良好的性能。 -
考虑到微调更大规模的模型(例如 70B 版本)在时间和计算成本方面开销巨大,并且这些模型可能无法被更广泛的研究社区使用,因此本文选择专注于最小的 Llama 3.1-8B 版本。 -
特别是,本文基于 Llama 3.1-8B 的指令版本构建 LlamaLens 模型,因为它已经与多个用户任务对齐。

4.2.1 训练设置
-
本文采用参数高效微调方法(Parameter-Efficient Fine-Tuning, PEFT)中的低秩适应(Low-Rank Adaptation, LoRA)方法,以全精度(16 位)对 Llama 3.1-8B-Instruct 进行微调。 -
LoRA 是一种用于微调大型预训练模型的参数高效方法,它通过在原始模型的权重矩阵上添加低秩矩阵来学习任务特定的更新,从而减少可训练参数的数量。 -
除了全精度模型之外,本文还旨在训练更小的模型,以实现以下两个目标: -
发布更小但有效的模型,以便在资源受限的环境中可以使用。 -
高效地研究某些参数设置对模型性能的影响,以指导完整模型的训练。 -
因此,本文还使用 QLoRA 对原始 Llama-8B-Instruct 模型进行了微调。 -
QLoRA 是一种量化微调方法,它涉及对模型的权重进行量化,并显著增强了内存优化,同时保持了可接受的性能。 -
QLoRA 将模型权重存储为 4 位格式,但计算是在 BFLOAT16 (bf16) 中进行的,LoRA 等级和 alpha 都设置为 16。
4.2.2 实验设置
-
数据集采样: -
本文实验数据集涵盖 52 个不同的数据集。 -
为了确保多样性,对于一些较大的数据集(例如,阿拉伯语仇恨言论数据集包含 20 万个样本),本文对每个数据集设置了一个 20K 训练实例的阈值。 -
对于超过该限制的数据集,采用分层抽样方法保持数据集标签分布。 -
最终的训练数据集包含 196 万个样本中的 60 万个样本。 -
数据集打乱: -
训练数据集中指令的顺序可能会显著影响模型性能。 -
本文研究了不同的样本顺序对 LlamaLens 性能的影响,采用四种不同的数据打乱和排序技术来确定最佳序列: -
实验结果表明,按任务打乱的数据排序方法优于其他配置。 -
按字母顺序排序:语言和数据集按字母顺序排序(阿拉伯语、英语、印地语),不打乱。 -
按语言打乱:随机打乱数据集,同时保持语言的顺序。 -
按任务打乱:按字母顺序组织任务,不考虑语言,随机打乱跨任务的数据集。 -
完全随机化:完全随机化训练数据集中的样本点。 -
参数设置: -
对于所有训练的模型,LoRA 学习率设置为 2e-4,并采用线性学习率调度。 -
使用 AdamW 优化器,批量大小为 16。 -
所有实验均在四块 NVIDIA H100-80GB GPU 上执行。 -
对于全精度模型(16 位),训练两个 epoch,并将 LoRA 等级增加到 512。
4.3 模型评估
-
本文采用零样本学习(zero-shot learning)方法,直接提示模型(原始模型和微调后的模型)执行测试集中的任务。 -
采用的自然指令/提示是每个数据集生成的第一个指令。 -
为了确保可重复性,将 top_p 设置为 1,温度设置为 0。 -
top_p 和 temperature 是生成文本时常用的参数,用于控制生成文本的多样性和确定性。top_p 控制生成文本的概率累积分布,temperature 控制生成文本的随机性。 -
对于分类任务,将模型生成的最大新标记数限制为 20。 -
对于摘要任务,采用基于遇到句号 (.) 或序列结束标记 (eos_token) 的停止标准。
4.4 后处理
-
由于模型可能会生成超出指令所需内容的文本,因此实施了一种后处理方法来从生成的模型响应中提取标签。 -
最初,使用正则表达式准确识别和提取标签。 -
还应用了几种转换,包括将所有文本转换为小写,删除特殊字符,并通过用相应的拉丁字母替换非拉丁字符来处理代码转换。
4.5 评估指标
-
所有模型均使用标准分类指标(包括加权 F1、微平均 F1、宏平均 F1 和准确率)进行评估。 -
使用 ROUGE-2 评估摘要任务。 -
具体来说,使用每个数据集中报告的最先进(SOTA)指标。
5. 结果和讨论
5.1 数据打乱的影响
-
实验结果表明,按任务打乱的数据排序方法优于其他配置。 -
按语言打乱和按字母顺序排序表现出相当的性能。 -
基于该实验,本文选择采用按任务打乱的数据排序方法来训练 LlamaLens 模型。
5.2 LlamaLens 的结果
-
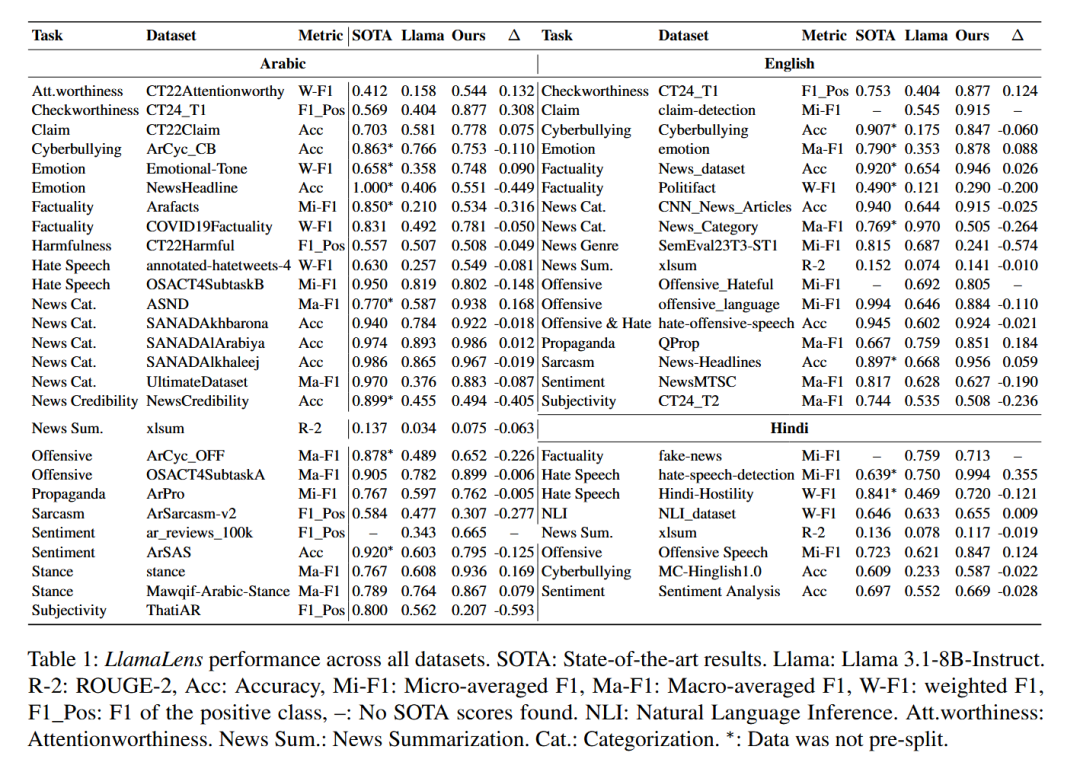
总体而言,LlamaLens 显著优于 Llama-instruct,平均性能提高了 33%。 -
阿拉伯语:平均性能提高了 32.5%。 -
英语:平均性能提高了 32.2%。 -
印地语:平均性能提高了 29.5%。 -
与 SOTA 的平均性能 0.75 相比,LlamaLens 的平均性能为 0.69。 -
需要注意的是,由于 52 个数据集中的 18 个未预先拆分,因此 SOTA 与本文模型在这些数据集上的性能不具有直接可比性。 -
如果排除这些数据集,SOTA 为 0.72,LlamaLens 的性能为 0.67。 -
在 LlamaLens 优于 SOTA 的数据集数量方面,LlamaLens 在 16 个测试集中优于 SOTA,在其他 10 个测试集中具有相当的性能(差异 ≥ 0 且 < 0.03)。 -
特定于数据集的改进: -
英语:例如,可信度、情感、新闻真实性、传播等任务。 -
阿拉伯语:可信度、情感和立场等任务,而新闻分类的性能则喜忧参半,在 5 个数据集中的 2 个数据集上有所改进。 -
印地语:在仇恨言论方面取得了显著改进,其次是自然语言推理和攻击性语言。
5.3 Llama-instruct 模型的错误分析
-
对 Llama-instruct 模型的响应进行了错误分析,以确定在处理低资源语言文本时在某些分类任务中遇到的挑战。 -
这些模型出现了一些常见问题,尤其是在与攻击性语言、仇恨言论检测、真实性和新闻分类相关的任务中。 -
经常无法提供标签,例如回复“我无法提供标签”或“阿拉伯语文本在没有上下文或翻译的情况下不容易分类到类别中”。 -
输出中存在语言混淆。尽管模型被指示仅以英语输出标签,但有时会返回阿拉伯语标签或代码转换响应。 -
与之相反,本文微调后的模型版本没有出现此类问题,模型更一致地遵循指令输出语言。 -
例如,有时模型会生成诸如“actual”(指“factual”,其中阿拉伯字符是字符“f”的音译)和“L”(韩语中“运动”的意思,音译为“seupocheu”,其中字符“~”是字符“s”的音译)的输出,尽管没有涉及韩语的指令。 -
这突出了语音级别的代码转换现象。 -
它也发生在更长的序列上,例如,模型回复“Lucastic”而不是“Sarcastic”,其中“Lu”实际上发音类似于“Sar”。 -
常见问题:
6. 结论和未来工作
-
本文提出了一种名为 LlamaLens 的专用模型,专注于新闻和社交媒体分析,旨在辅助记者、事实核查员和社交媒体分析师。 -
本文收集了 52 个数据集,涵盖阿拉伯语、英语和印地语三种阿拉伯半岛地区主要语言。 -
为了开发 LlamaLens,本文基于这些收集到的数据集构建了一个遵循指令的数据集,并对 Llama 3.1-8B-Instruct 模型进行了微调。 -
实验结果表明,LlamaLens 在 16 个数据集上优于 SOTA,在 10 个数据集上具有相当的性能,而在其余数据集上表现较差。 -
然而,平均而言,LlamaLens 及其量化版本显著优于 Llama-instruct 模型。 -
错误分析结果表明,将特定领域和语言知识注入 Llama-instruct 对于获得所需的结果至关重要。
论文及模型见星球,QuantML星球内有各类丰富的量化资源,包括上百篇论文代码,QuantML-Qlib框架,研报复现项目等,星球群内有许多大佬,包括量化私募创始人,公募jjjl,顶会论文作者,github千星项目作者等,星球人数已经500+,欢迎加入交流
我们的愿景是搭建最全面的量化知识库,无论你希望查找任何量化资料,都能够高效的查找到相关的论文代码以及复现结果,期待您的加入。