
“Reinforcement Learning Framework for Quantitative Trading”
股票市场数据通常以开盘、收盘、高、低和成交量的时间序列格式呈现,技术指标的引入有助于构建更稳健的交策略。金融市场的波动性要求投资者采用全面的风险管理和市场趋势策略。
本文提供了RL框架下金融指标的应用方法,包括数据预处理、回测工具和指标影响分析。旨在将理论模型与实际应用结合,提升RL代理的交易决策准确性。


论文地址:https://arxiv.org/pdf/2411.07585
摘要
金融市场的波动性要求投资者采用综合可靠的方法,结合风险管理、市场趋势和个别证券的动态。当前文献缺乏支持强化学习(RL)代理实际有效性的实证证据,许多模型仅在历史数据回测中成功。存在金融指标有效利用的脱节,成功交易策略的披露受限,导致RL策略文献稀缺。当前研究常忽视与市场趋势相关的金融指标及其潜在优势。本研究旨在提升RL代理区分正负买卖行为的能力,利用金融指标提供更深入的见解,为进一步探索复杂场景奠定基础。
简介
投资者的主要目标是最小化交易风险并最大化利润,需系统性预测证券价格和趋势。自动化交易系统的研究旨在替代传统投资者并提高市场流动性。过去的监督和无监督学习技术效果不佳,强化学习(RL)近年来受到关注,可能提供更准确的价格预测。马尔可夫决策过程(MDP)适用于金融数据的动态特性,但可能无法捕捉历史信息。
股票市场数据通常以开盘、收盘、高、低和成交量的时间序列格式呈现,技术指标的引入有助于构建更稳健的交策略。目前的挑战在于有效利用技术指标预测未来价格,假信号增加了复杂性。采用降维、特征选择和提取等高级技术,如卷积神经网络(CNN)、递归神经网络(RNN)和长短期记忆网络(LSTM)来应对这些挑战。
动机
强化学习可用于个人开发更强大的交易策略,但个体在资源上难以与量化对冲基金竞争。量化对冲基金拥有丰富的资源,便于研究和策略开发。本文旨在填补该领域知识的空白,因相关出版物稀少。量化对冲基金和个人投资者不愿公开交易策略以保持竞争优势。研究重点包括数据预处理、回测(使用Backtesting.py)、奖励函数、归一化方法等。本文不旨在帮助个人获得财务收益,讨论了研究的局限性,鼓励专家进一步发展此工作。
背景
量化交易中的强化学习
强化学习(RL)在量化交易中表现出色,优于其他机器学习方法。RL代理与金融市场环境互动,通过交易行为获得奖励或惩罚,目标是最大化累积奖励。RL能够处理大量金融数据,形成更有效的交易策略,但数据过多可能导致决策效果下降。需要开发先进方法来过滤和优先处理相关信息。RL的有效性依赖于预测未来市场走势和生成盈利策略,引入折扣因子??以平衡短期收益与长期潜力。
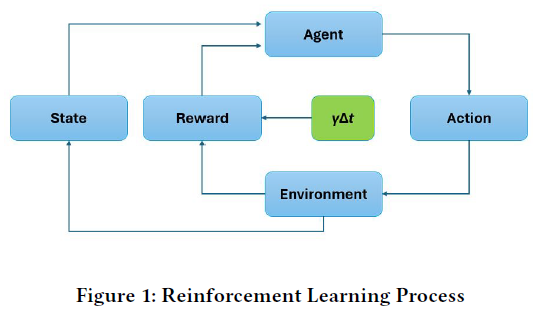
指标
金融指标在强化学习代理中用于预测证券价格,帮助理解市场趋势和波动。当前研究缺乏系统的指标选择方法,导致代理性能受限,观察空间不理想。短期指标对价格变化反应迅速,但波动性大;长期指标平滑波动,难以精确识别趋势。不同时间段的简单移动平均(SMA)对交易策略影响不同,短期交易者关注波动,长期交易者关注趋势。需要结合多种信号以克服单一指标的局限性,确保交易期间的盈利能力。
离散和连续的作用空间
动作空间分为离散和连续,选择取决于目标。离散动作空间如买卖操作,连续动作空间则在0到1范围内表示信心程度或资产分配。当前强化学习股票交易模型多采用0到1的连续动作空间,尤其是深度Q网络和策略梯度方法(如PPO、TRPO)表现更佳。连续动作空间可用于投资组合管理,0表示不买入或卖出,1表示分配一定比例的资产。
文献综述
2016年研究采用深度强化学习,无需传统技术指标,通过重构递归深度神经网络实现实时交易的环境感知与决策,尽管在小范围合约中盈利,但未能证明其在实盘交易中的有效性。另一项研究结合深度强化学习与情感分析,使用DDPG和RCNN提升模型预测能力,尽管未显著提高利润,但分析了代理学习交易策略的能力,奖励函数未考虑风险因素,短期有效性存疑。另一个研究提出了一种新型强化学习框架用于金融投资组合管理,采用EIIE拓扑、PVM和OSBL方案,结合CNN、RNN和LSTM,在加密货币市场进行回测,结果显示良好回报,但未涉及传统金融市场。
本框架评估九个环境变量,定义交易代理的三种状态(买、卖、持),强调双重平均交易策略的有效性,使用短期和长期移动平均确定最佳交易时机,短期交易难以持续优化结果。
注意事项
环境变量的归一化和缩放可能导致模型长期不准确,需确保每个变量对决策过程的贡献相等。变量变化可能影响代理的奖励,需谨慎调整奖励函数。强化学习中的持有状态与无操作状态的区别不明确,代理需明确输入才能理解持有状态。无操作状态可能导致代理无法判断买入或卖出,尤其在没有持有资产时。持有资产的状态与无资产状态的决策复杂性不同,代理需在动态数据集中权衡收益与风险。
方法
探索强化学习代理在环境变化中持续学习和适应的方法,利用金融指标提升交易准确性。研究不同指标之间的相关性,以识别对RL代理提供新信息的指标。数据预处理包括多种归一化方法,帮助缩放状态空间。考虑多种奖励函数(加性奖励、终端奖励、即时奖励、最终奖励),以优化交易决策。目标是分析短期和长期交易视角,聚焦于买入或卖出两个动作。选择三种适合离散动作空间的算法:深度Q网络(DQN)、近端策略优化(PPO)和演员-评论家(A2C)。
状态空间
交易环境的状态空间由历史价格数据和技术指标构成。维度由历史数据窗口的长度和指标数量决定。历史数据窗口通过Yahoo Finance API获取,指定了关注的时间段。
动作空间
gym-anytrading是一个扩展OpenAI Gym的库,用于模拟和测试算法交易策略。默认情况下,该库的动作空间是离散的,动作仅包括买入或卖出。强化学习代理始终处于市场中,必须采取买入或卖出行动,不存在持有或不动作的状态。
奖励函数
奖励函数根据代理采取的行动计算奖励,盈利时为正,亏损时为负。提出了三种奖励函数:
-
即时奖励:计算当前价格与上次交易价格的对数差异,长仓时增加奖励。
-
变动奖励:当前行动与上次不同才计算奖励,奖励为当前价格与初始价格的自然对数比值。
-
最终奖励:即时奖励为零,仅根据初始和最终权益值计算单一奖励。
研究主要集中在即时奖励,以最大化每笔交易的财务收益。
奖励函数限制
第一种奖励函数简单,计算前后价格差,但容易导致模型只关注短期收益。立即奖励可能导致模型过拟合和学习方差大。仅提供最终奖励会使模型难以区分好坏交易,限制学习能力。设计奖励函数时需谨慎,以适应短期或长期交易策略。
技术指标
研究评估了20种技术指标(如SMA、MACD、ATR等)作为强化学习输入,并使用最小/最大缩放进行归一化。使用DummyVecEnv对自定义环境进行向量化,支持多个环境的并行执行,提高收敛速度和效率。
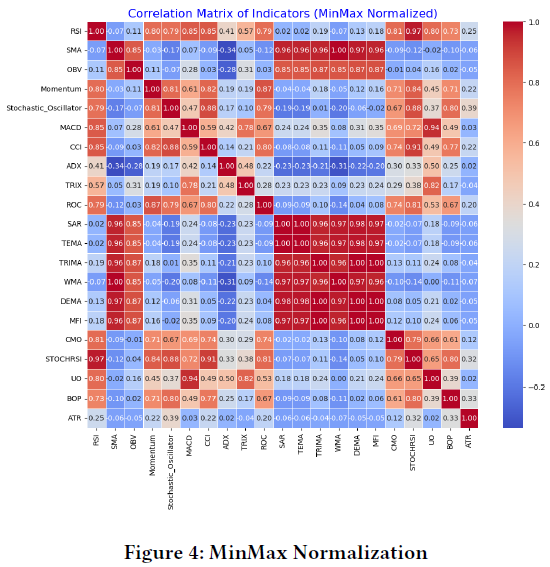
指标相关矩阵
图4的相关性矩阵显示技术指标之间的关系,RSI与动量、随机振荡器、MACD等指标高度相关,表明它们同向移动。ADX、TRIX、SAR等指标与大多数其他指标的相关性较弱。测试了三种归一化方法,结果与MinMax方法相似,但可能不适合所有技术指标的相关性测量。不同类型的指标(如动量与成交量)可能需要不同的归一化方式。
训练数据
使用2020-01-01至2022-01-01的APPL日数据训练三种模型:Actor-Critic、Proximal Policy Optimization和Deep Q-Network。每个模型独立使用不同算法,训练时间为一百万时间步。代理与环境通过时间步交互,代理在每个时间步接收环境状态和与前一动作相关的奖励,然后采取行动。
实验
Actor-Critic
A2C方法使用MlpPolicy在两年内表现不佳,相比DQN和PPO模型。A2C需要大量数据才能有效学习,且容易出现收敛问题。在时间序列数据上,A2C表现不佳,验证了其固有问题。
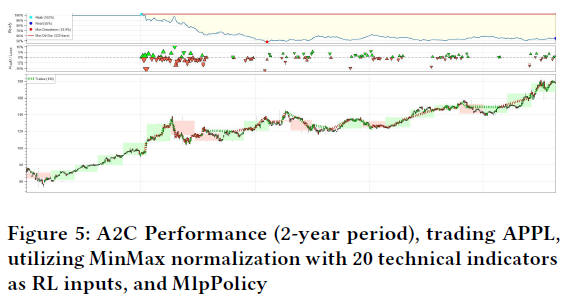
最近邻策略优化
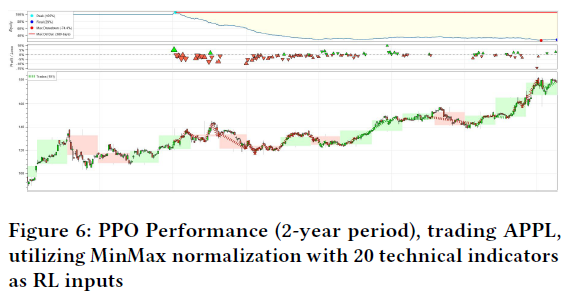
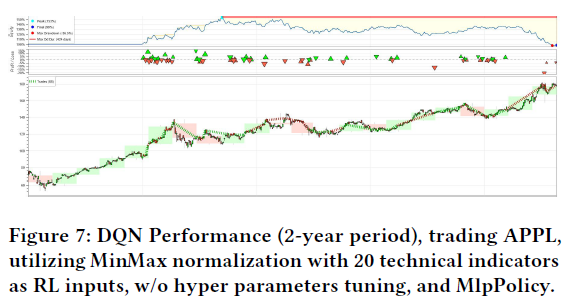
PPO算法在买卖决策上表现不佳,交易次数最多(101次),但胜率仅27%,整体回报为负,年波动率接近10%。DQN模型在几周内表现出色,成功执行了多次盈利交易,但在某些时间段表现不稳定,频繁进行近距离买卖。DQN模型的超参数调优正在进行,降低学习率以稳定模型。
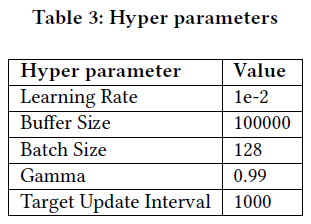
超参数
研究测试了不同的学习率,以评估模型的探索和学习能力。目的是识别训练集性能的模式或变化。
学习率
研究测试了不同的学习率??,主要针对DQN模型,因为其训练稳定性较好。较大的学习率有助于提高代理的整体表现,促进探索。学习率可以在模型稳定后逐渐减小。
超参数结果
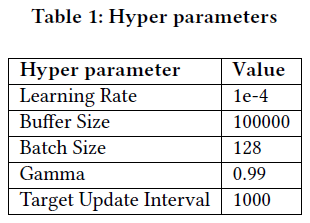
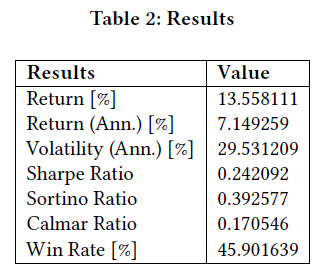
使用DQN时,调整了学习率、缓冲区大小、批量大小、折扣因子和目标更新间隔等参数。批量大小指从缓冲区中抽取的经验数量,用于更新权重。将学习率调整为1e-4后,模型在识别盈利交易方面表现更好。表2显示,经过2年期间,回报率达13.5%。评估中最重要的指标包括回报率、波动率、夏普比率和胜率。
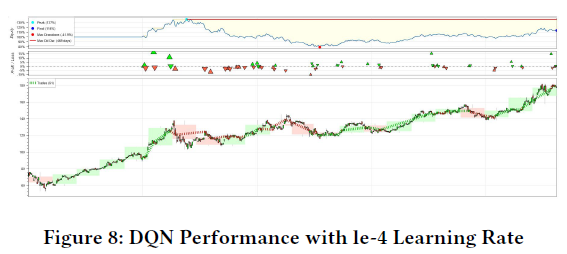
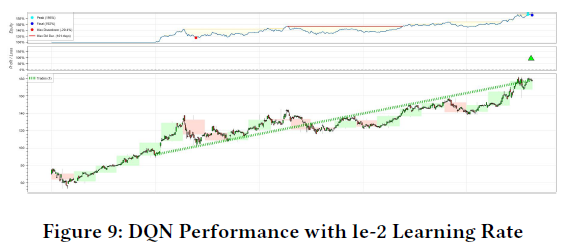
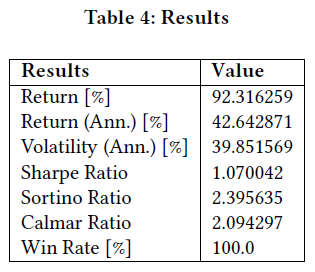
学习率从le-4调整到le-2,前者提供稳定更新,后者加快收敛速度,但可能导致过拟合。表4展示了DQN模型在不同超参数下的表现,关键指标包括胜率、夏普比率、收益和波动率。夏普比率用于衡量风险调整后的收益,计算公式为:
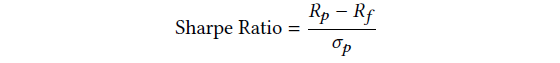
使用较高学习率时,模型交易次数为61次,而较低学习率仅交易一次,胜率和夏普比率均显著提高。超参数(如缓冲区大小和学习率)对模型稳定性和性能有重要影响,未来可进行更多超参数调优实验。
间隔 & 策略退化
数据间隔的细化(如小时、分钟、秒)有助于捕捉更复杂的细节,提升RL代理的性能洞察。在不同市场条件下进行模型比较分析,探讨DQN与PPO在下行趋势中的表现差异及原因。引入Stable-Baselines3的多样化策略和超参数调优、探索/利用策略,以优化模型。随着市场数据的不断更新,模型需持续改进。策略退化是普遍限制,单一算法训练的风险可通过集成方法降低,但无法完全解决策略退化问题。
策略进化
开发强化学习(RL)交易策略时需考虑多个因素。可使用Backtesting.py进行策略开发与测试,设置止损、订单规模等以模拟真实交易环境。可利用200多种技术指标作为输入,需选择合适的归一化方案。不同指标(如MACD)的归一化方式不同,需谨慎选择以避免结果失真。
总结
金融市场的波动性要求投资者采用全面的风险管理和市场趋势策略。强调技术指标在强化学习(RL)代理决策中的重要性,帮助投资者理解市场趋势。RL被视为量化交易的有效工具,能够处理复杂的金融数据,适配马尔可夫决策过程(MDP)。RL面临挑战,如数据过载可能影响模式识别和决策能力,需解决以提升交易策略。
本研究提供了RL框架下金融指标的应用方法,包括数据预处理、回测工具(如Backtesting.py)和指标影响分析。未来方向在于将理论模型与实际应用结合,提升RL代理的交易决策准确性。实验中使用A2C、PPO和DQN三种算法,调优超参数以提高稳定性和性能,需注意策略退化和数据范围的广泛性。
我们致力于提供优质的AI服务,涵盖人工智能、数据分析、深度学习、机器学习、计算机视觉、自然语言处理、语音处理等领域。如有相关需求,请私信与我们联系。
请加微信“LingDuTech163”,或公众号后台私信“联系方式”。
关注【灵度智能】公众号,获取更多AI资讯。