
收录于话题
2024年11月21日arXiv cs.CV发文量约103余篇,减论Agent通过算法为您推荐并自动化整理为卡片供您参考,预计为您节省42分钟浏览arXiv的时间。


南洋理工大学、上海人工智能实验室和香港中文大学推出了一篇论文,介绍了VBench,一个全面的基准套件,用于评估视频生成模型在16个特定维度上的表现,与人类感知相一致,并为未来发展提供见解。
【Bohr精读】
https://j1q.cn/yZyeod1K
【arXiv链接】
http://arxiv.org/abs/2411.13503v1
【代码地址】
https://github.com/Vchitect/VBench
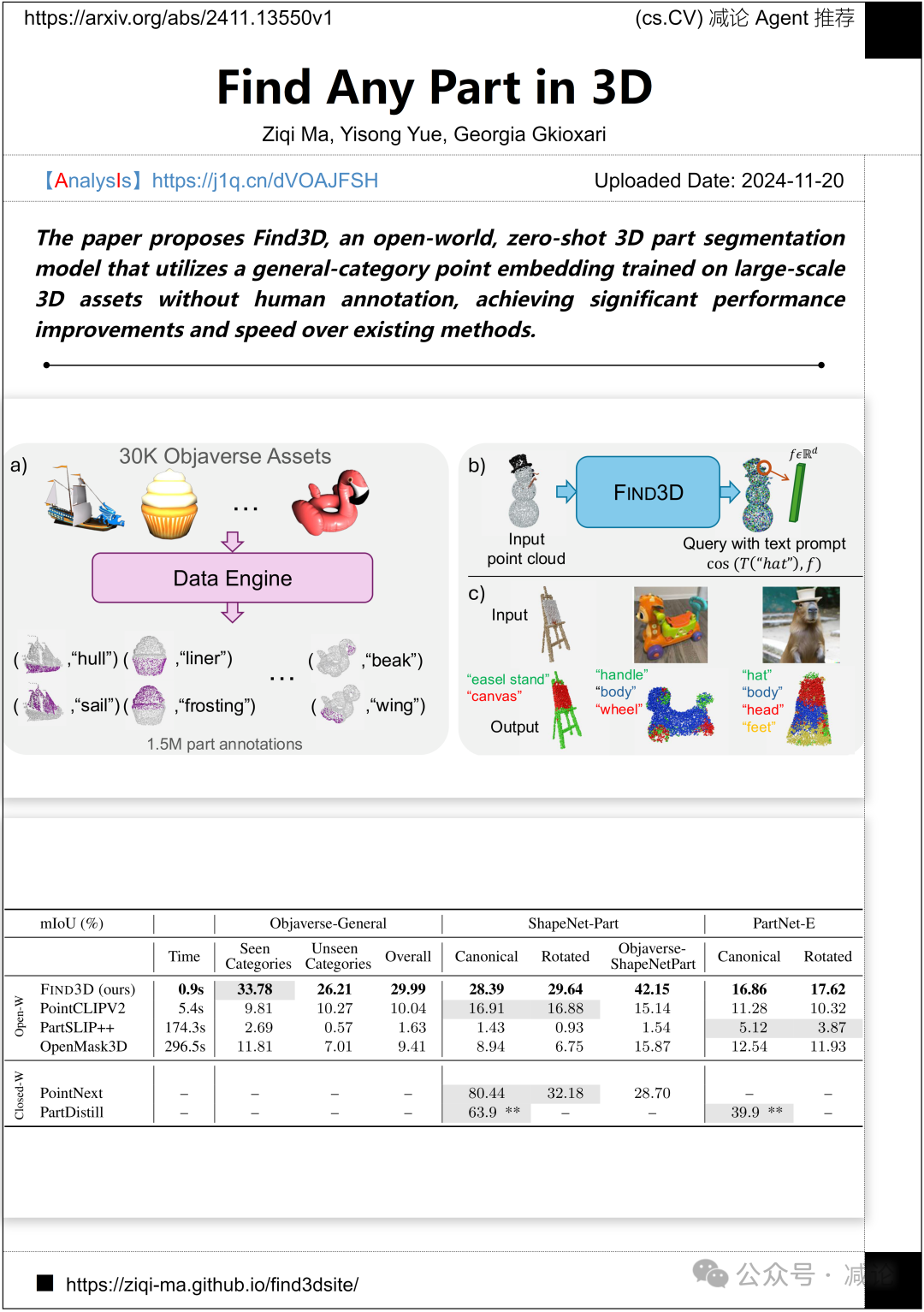
加州理工学院提出了Find3D,一个开放世界的、零样本的3D零件分割模型,利用在大规模3D资产上训练的通用类别点嵌入,无需人工标注,实现了显著的性能提升和速度优势。
【Bohr精读】
https://j1q.cn/dVOAJFSH
【arXiv链接】
http://arxiv.org/abs/2411.13550v1
【代码地址】
https://ziqi-ma.github.io/find3dsite/
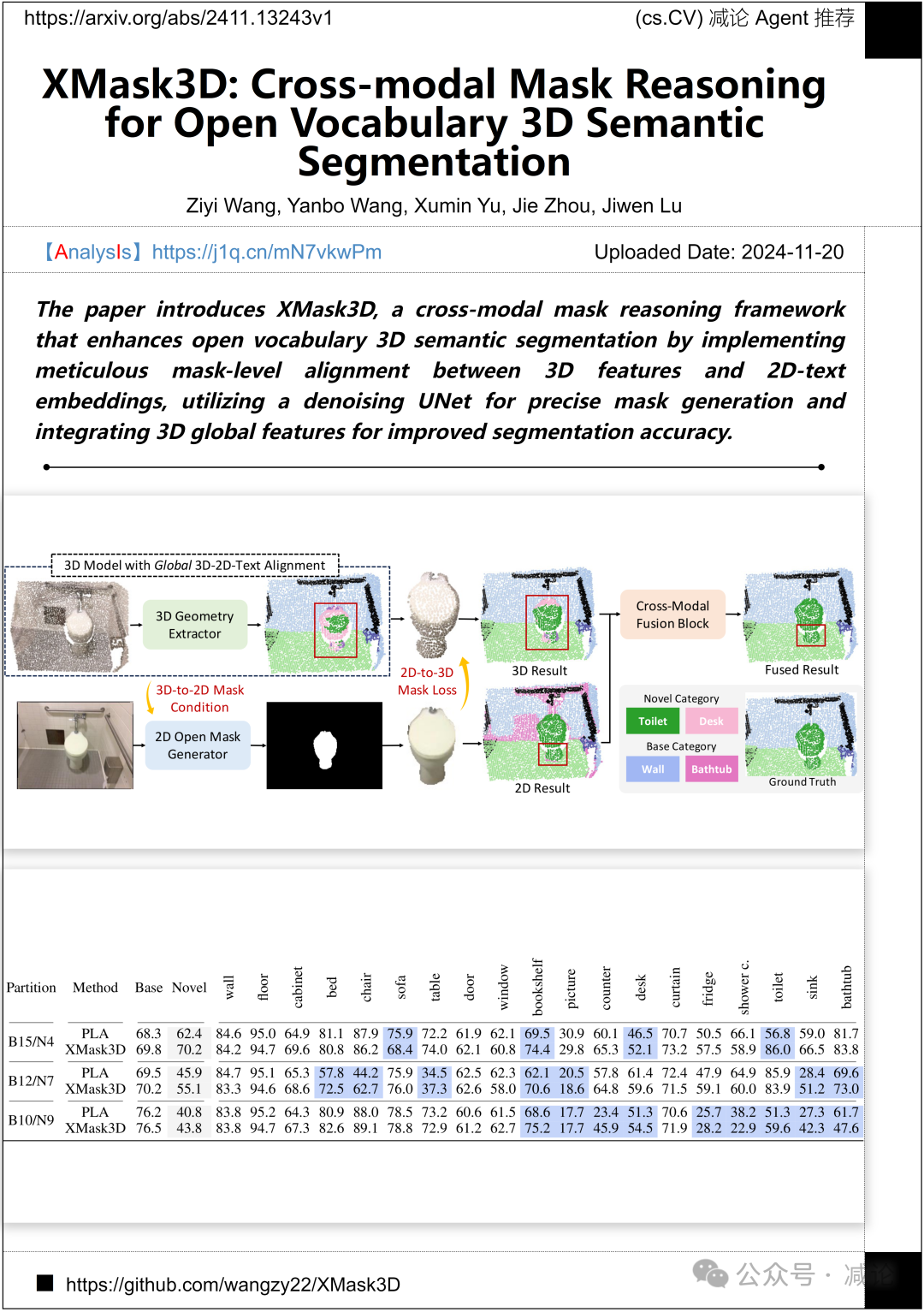
清华大学提出了XMask3D,一种跨模态掩模推理框架,通过在3D特征和2D文本嵌入之间实现细致的掩模级对齐,利用去噪UNet进行精确掩模生成,并集成3D全局特征以提高分割准确性。
【Bohr精读】
https://j1q.cn/mN7vkwPm
【arXiv链接】
http://arxiv.org/abs/2411.13243v1
【代码地址】
https://github.com/wangzy22/XMask3D
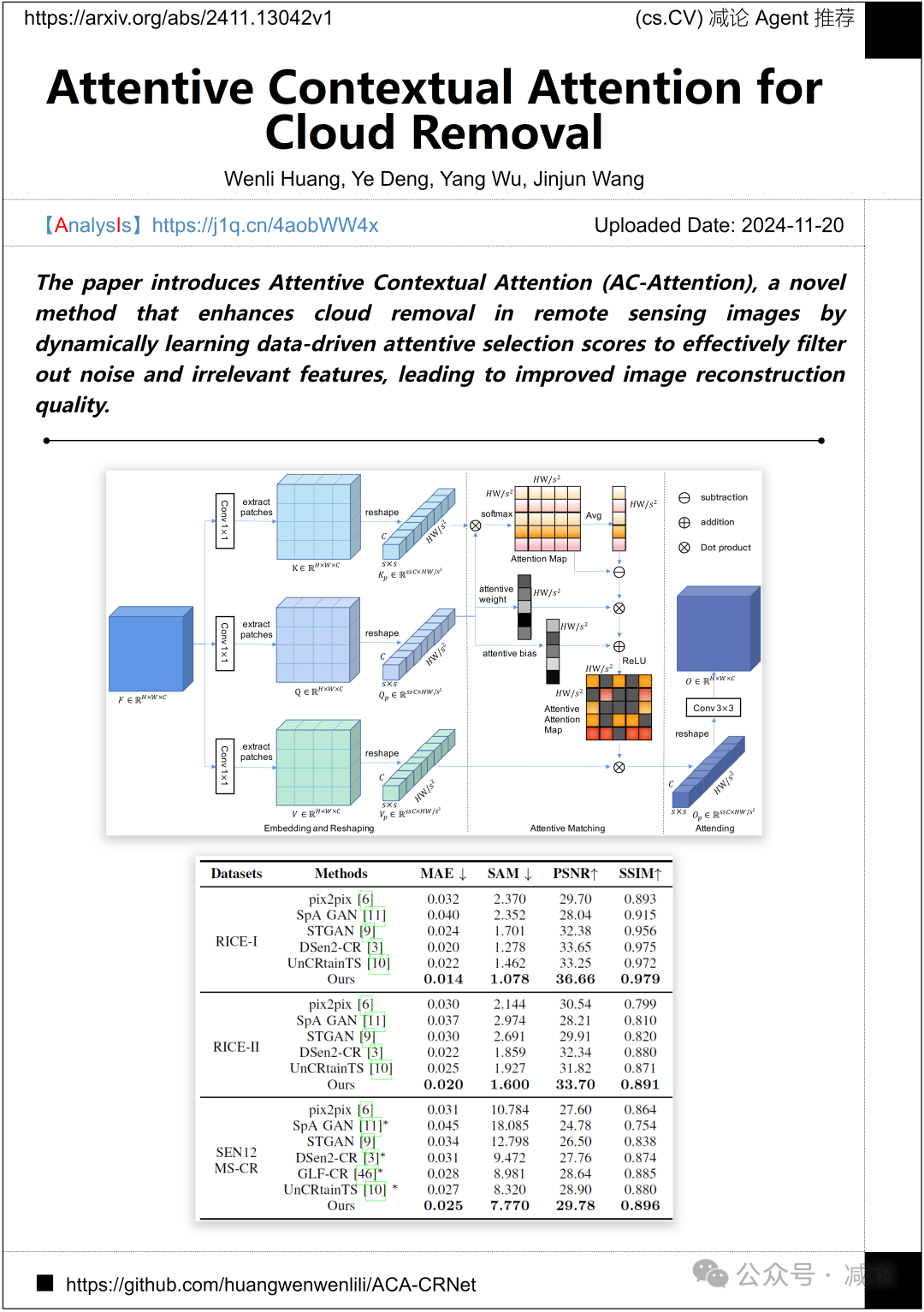
宁波工程学院、西南财经大学和西安交通大学提出了一种新方法——Attentive Contextual Attention (AC-Attention)。该方法通过动态学习数据驱动的注意力选择分数,增强遥感图像中的云去除效果,有效过滤噪声和无关特征,从而提高图像重建质量。
【Bohr精读】
https://j1q.cn/4aobWW4x
【arXiv链接】
http://arxiv.org/abs/2411.13042v1
【代码地址】
https://github.com/huangwenwenlili/ACA-CRNet

武汉大学、中国科学院和中国科学院提出了DriveMLLM,这是一个用于评估自动驾驶中多模态大语言模型空间理解能力的基准,通过多样化的空间推理任务和新颖的评估指标。
【Bohr精读】
https://j1q.cn/TNmCnsya
【arXiv链接】
http://arxiv.org/abs/2411.13112v1
【代码地址】
https://github.com/XiandaGuo/Drive-MLLM
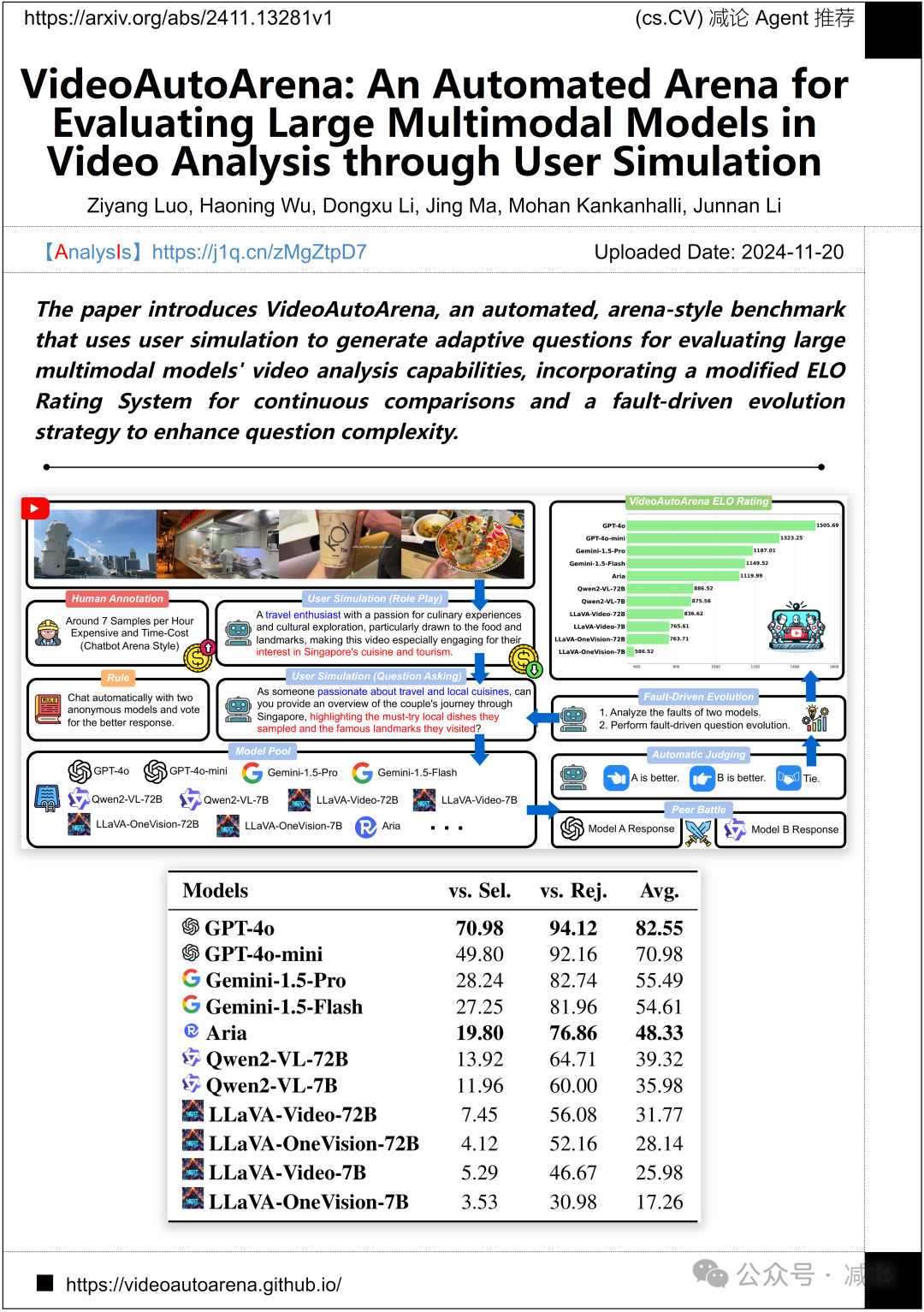
莱姆斯人工智能、香港浸会大学和新加坡国立大学推出了一项名为VideoAutoArena的研究成果。该论文介绍了VideoAutoArena,这是一个自动化的竞技场式基准测试,利用用户模拟生成适应性问题,用于评估大型多模态模型的视频分析能力。论文结合了修改后的ELO评分系统进行持续比较,并采用基于故障驱动的演化策略来增强问题复杂性。
【Bohr精读】
https://j1q.cn/zMgZtpD7
【arXiv链接】
http://arxiv.org/abs/2411.13281v1
【代码地址】
https://videoautoarena.github.io/

厦门大学和罗切斯特大学提出了视频检索增强生成(Video-RAG)方法。这种方法无需训练,经济高效,通过将从视频数据中提取的与视觉对齐的辅助文本集成到现有的大型视频–语言模型中,从而增强长视频理解能力。
【Bohr精读】
https://j1q.cn/eCf9Gi83
【arXiv链接】
http://arxiv.org/abs/2411.13093v1
【代码地址】
https://github.com/Leon1207/Video-RAG-master

多伦多大学提出了Data-to-Model Distillation(D2M)框架,这是一个可以将大型数据集中的知识提炼到预训练生成模型的参数中的方法,从而实现在各种蒸馏比例和深层架构下高效生成信息丰富的训练图像。
【Bohr精读】
https://j1q.cn/D4CYHNtP
【arXiv链接】
http://arxiv.org/abs/2411.12841v1
【代码地址】
https://datadistillation.github.io/D2M/
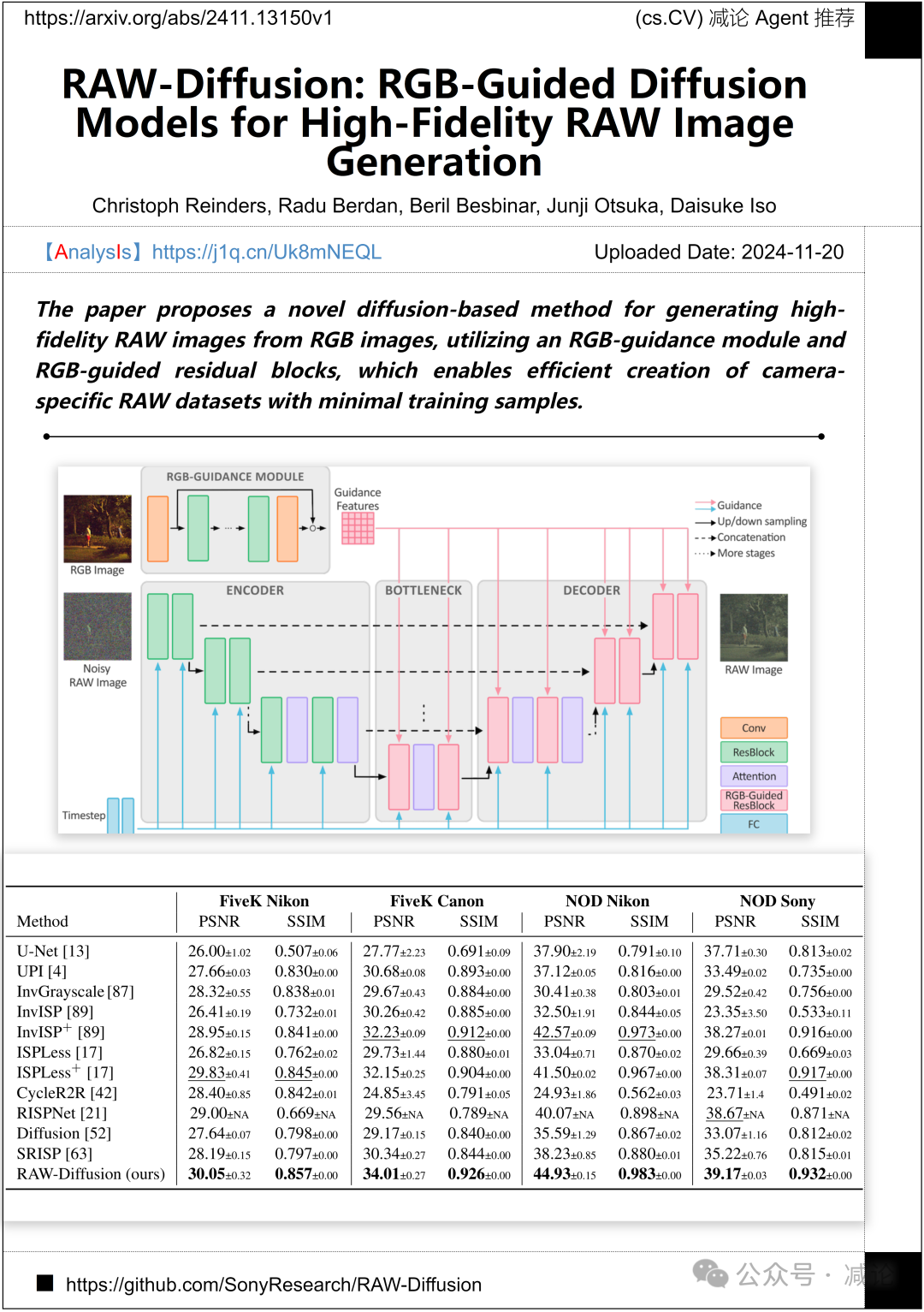
莱布尼兹大学汉诺威和索尼人工智能实验室提出了一种基于扩散的新方法,用于从RGB图像生成高保真度的RAW图像。该方法利用RGB引导模块和RGB引导残差块,能够在利用最少训练样本的情况下高效创建特定相机的RAW数据集。
【Bohr精读】
https://j1q.cn/Uk8mNEQL
【arXiv链接】
http://arxiv.org/abs/2411.13150v1
【代码地址】
https://github.com/SonyResearch/RAW-Diffusion

华南理工大学提出了一个名为全局相关感知硬负样本生成(GCA-HNG)的框架,通过结构化图和迭代消息传播利用全局样本相关性来生成更具信息性和多样性的深度度量学习的硬负样本。
【Bohr精读】
https://j1q.cn/OmrS5nba
【arXiv链接】
http://arxiv.org/abs/2411.13145v1
【代码地址】
https://github.com/PWenJay/GCA-HNG

新墨西哥大学提出了基于可变形Transformer的线段检测(DT-LSD)模型。该模型利用一种名为线对比去噪(LCDN)的新技术,实现了跨尺度交互,显著加快训练速度,提高了线段检测的准确性和效率,优于其前身和基于CNN的模型。
【Bohr精读】
https://j1q.cn/YbGZtuCy
【arXiv链接】
http://arxiv.org/abs/2411.13005v1
【代码地址】
https://github.com/SebastianJanampa/DT-LSD

浙江大学、金山软件提出了特征梯度剪枝(FGP)方法,这是一种结合了基于特征和梯度信息的新方法,能够有效识别和移除冗余的卷积通道,提高模型效率同时保持性能。
【Bohr精读】
https://j1q.cn/CyPRhtng
【arXiv链接】
http://arxiv.org/abs/2411.12781v1
【代码地址】
https://github.com/FGP-code/FGP
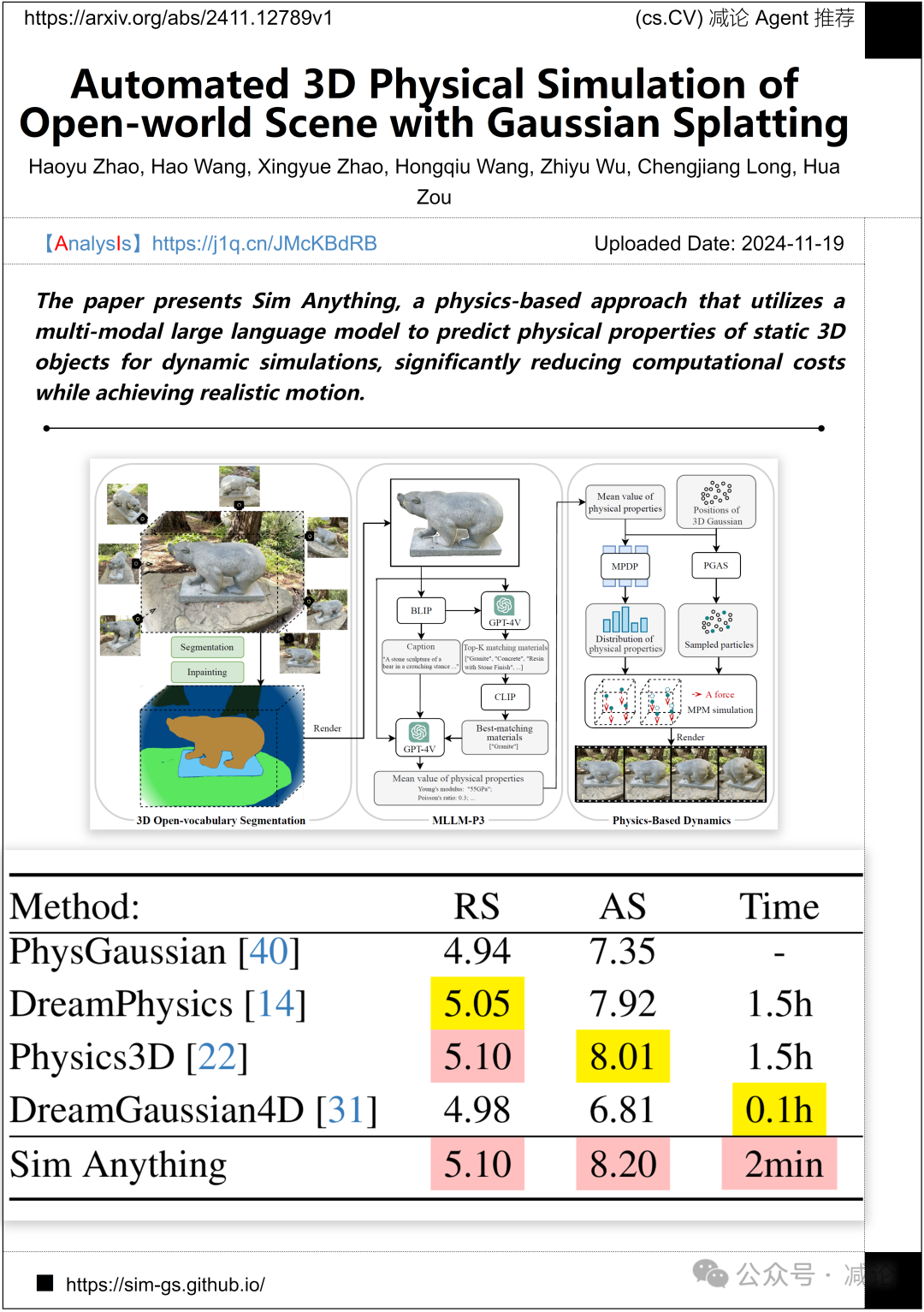
武汉大学,华中科技大学, Meta Reality Lab提出了Sim Anything,这是一种基于物理的方法,利用多模态大型语言模型来预测静态3D对象的物理特性,用于动态模拟,显著降低计算成本同时实现逼真的运动。
【Bohr精读】
https://j1q.cn/JMcKBdRB
【arXiv链接】
http://arxiv.org/abs/2411.12789v1
【代码地址】
https://sim-gs.github.io/

复旦大学和微软研究提出了Reducio-DiT,一种图像条件的VAE,可以将视频表示显著压缩到运动潜空间中,实现了潜空间的64倍减少,同时保持质量,从而提高了视频生成模型在训练和推理中的效率。
【Bohr精读】
https://j1q.cn/aDcejkSp
【arXiv链接】
http://arxiv.org/abs/2411.13552v1
【代码地址】
https://github.com/microsoft/Reducio-VAE
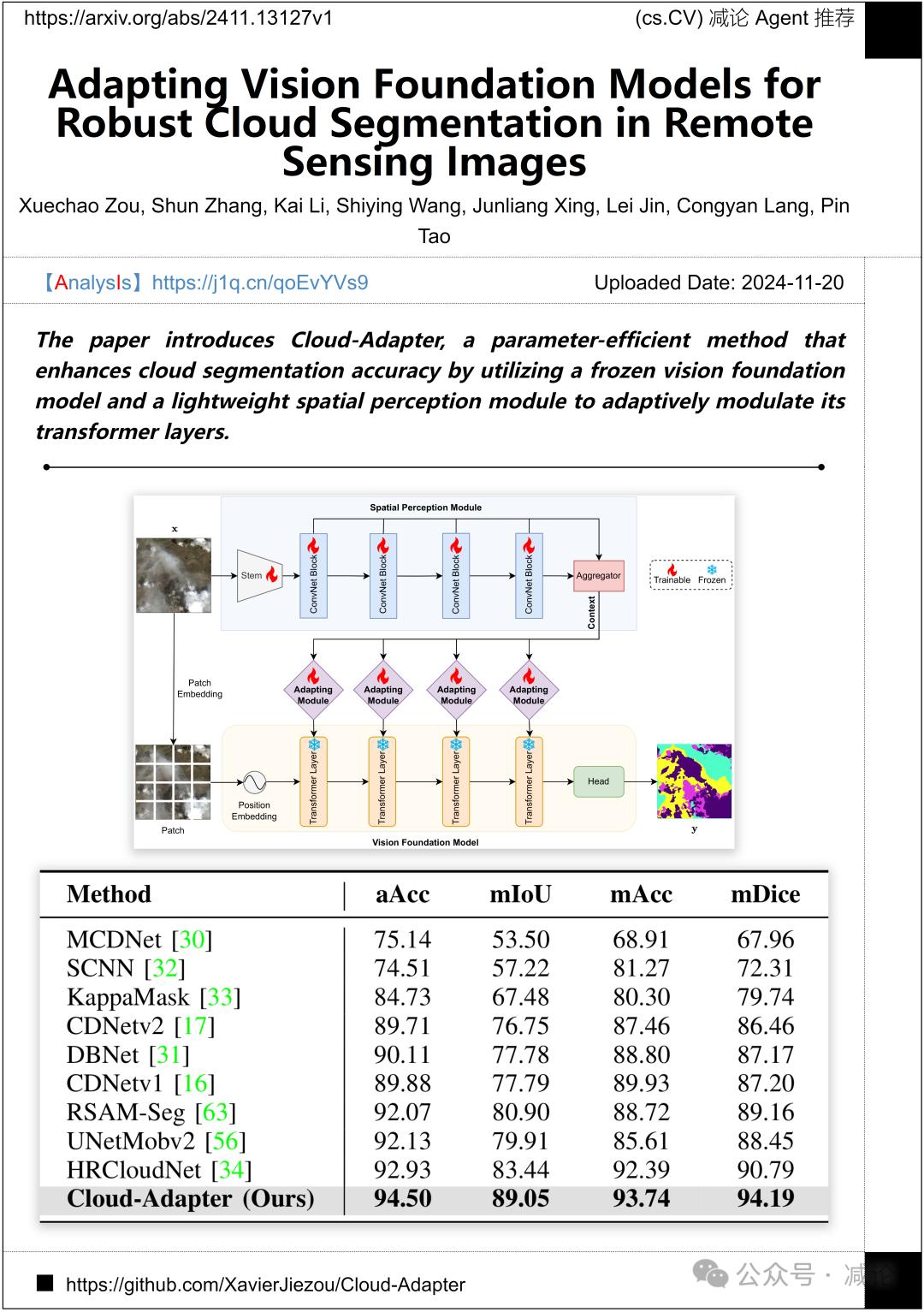
北京交通大学、青海大学和北京邮电大学推出了一项名为Cloud-Adapter的新方法。该方法利用冻结的视觉基础模型和轻量级的空间感知模块,自适应调节其transformer层,以提高云分割的准确性。
【Bohr精读】
https://j1q.cn/qoEvYVs9
【arXiv链接】
http://arxiv.org/abs/2411.13127v1
【代码地址】
https://github.com/XavierJiezou/Cloud-Adapter
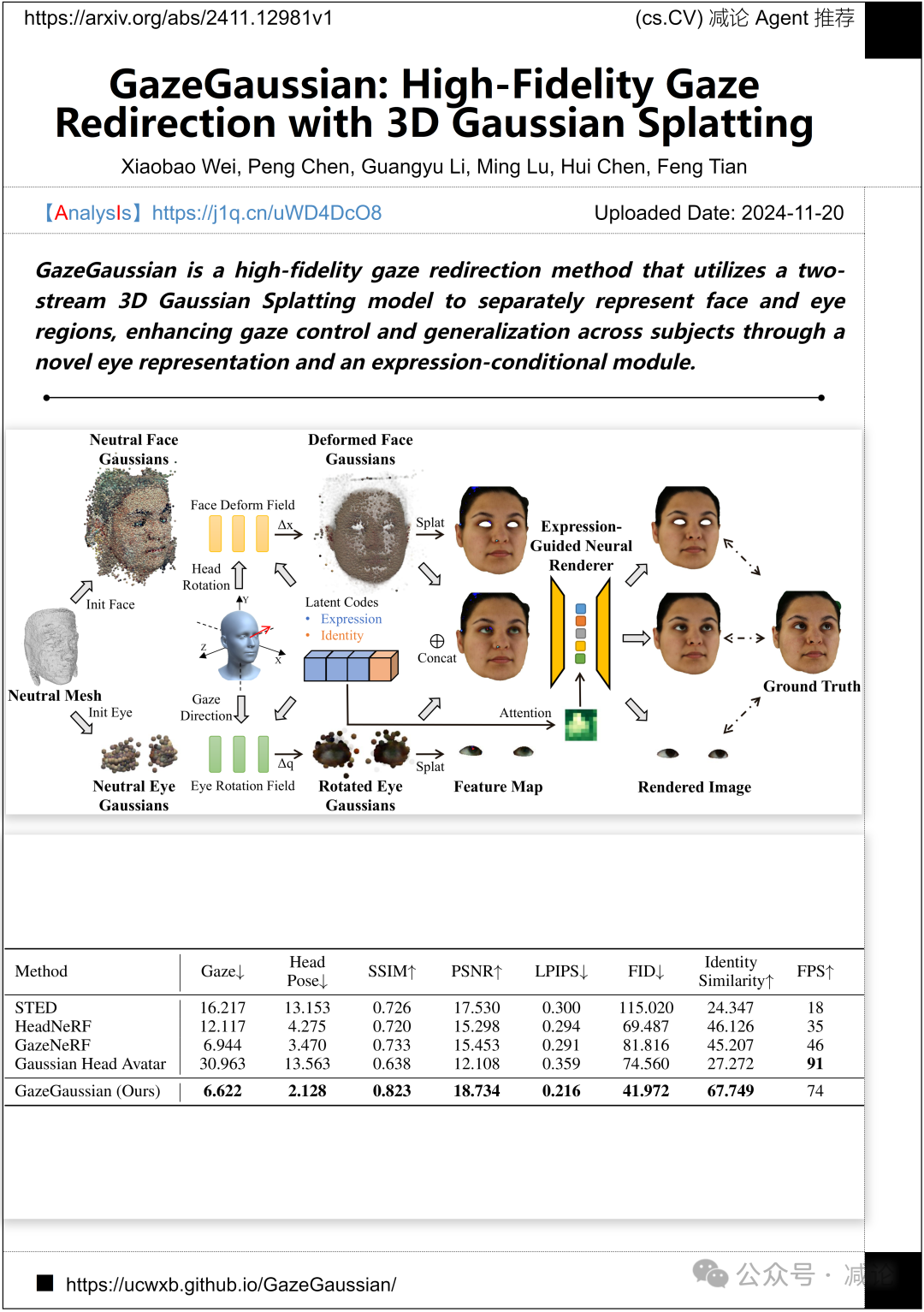
中国科学院软件研究所和英特尔实验室中国推出了一项名为GazeGaussian的高保真度凝视重定向方法。该方法利用双流3D高斯喷溅模型分别表示面部和眼部区域,通过一种新颖的眼部表示和表情条件模块增强凝视控制,并在受试者之间实现泛化。
【Bohr精读】
https://j1q.cn/uWD4DcO8
【arXiv链接】
http://arxiv.org/abs/2411.12981v1
【代码地址】
https://ucwxb.github.io/GazeGaussian/

复旦大学、北京大学和上海人工智能实验室提出了一种新颖的无监督框架,用于单目3D姿势估计。该框架利用多假设检测器和定制的前置任务来解决深度模糊问题,通过利用SMPL模型中的3D人体先验信息,实现了最先进的性能。
【Bohr精读】
https://j1q.cn/bL8HZ2Ur
【arXiv链接】
http://arxiv.org/abs/2411.13026v1
【代码地址】
https://github.com/Charrrrrlie/X-as-Supervision

华南师范大学、香港城市大学和澳门城市大学提出了一个无需训练的去偏见框架,通过对查询图像应用保持语义的扭曲,改进了大型多模态模型中的图像质量评估,使模型能够基于一致的先验条件推断质量。
【Bohr精读】
https://j1q.cn/470eg0vc
【arXiv链接】
http://arxiv.org/abs/2411.12791v1
【代码地址】
https://barrypan12138.github.io/Q-Debias/

欢迎关注减论,持续输出有深度的人工智能极减理解,提升信息获取效率和认知维度。看完点颗小星星再走呗~