
收录于话题
2024年11月19日arXiv cs.CV发文量约194余篇,减论Agent通过算法为您推荐并自动化整理为卡片供您参考,预计为您节省87分钟浏览arXiv的时间。


清华大学团队推出了一种高效的注意力计算方法SageAttention2。使用4位矩阵乘法和自适应量化技术,该方法在保持各种模型准确性的同时,实现了高达5倍的加速。
【Bohr精读】
https://j1q.cn/LU8OJQaj
【arXiv链接】
http://arxiv.org/abs/2411.10958v1
【代码地址】
https://github.com/thu-ml/SageAttention
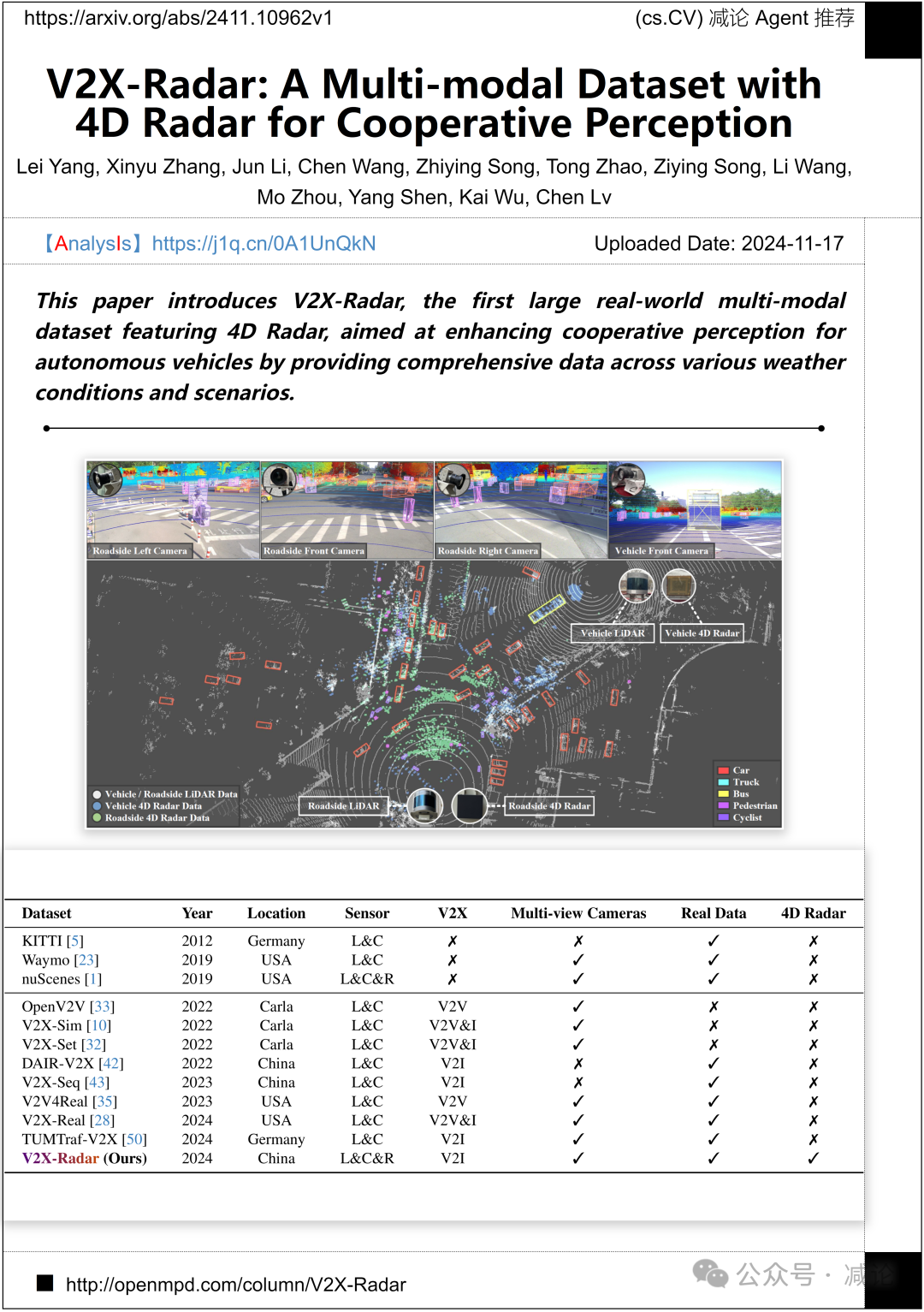
清华大学、中国矿业大学和南洋理工大学的研究团队介绍了V2X-Radar,这是第一个大型真实世界的多模态数据集,包括4D雷达。该数据集旨在通过提供各种天气条件和场景下的全面数据,增强自动驾驶车辆的合作感知。
【Bohr精读】
https://j1q.cn/0A1UnQkN
【arXiv链接】
http://arxiv.org/abs/2411.10962v1
【代码地址】
http://openmpd.com/column/V2X-Radar
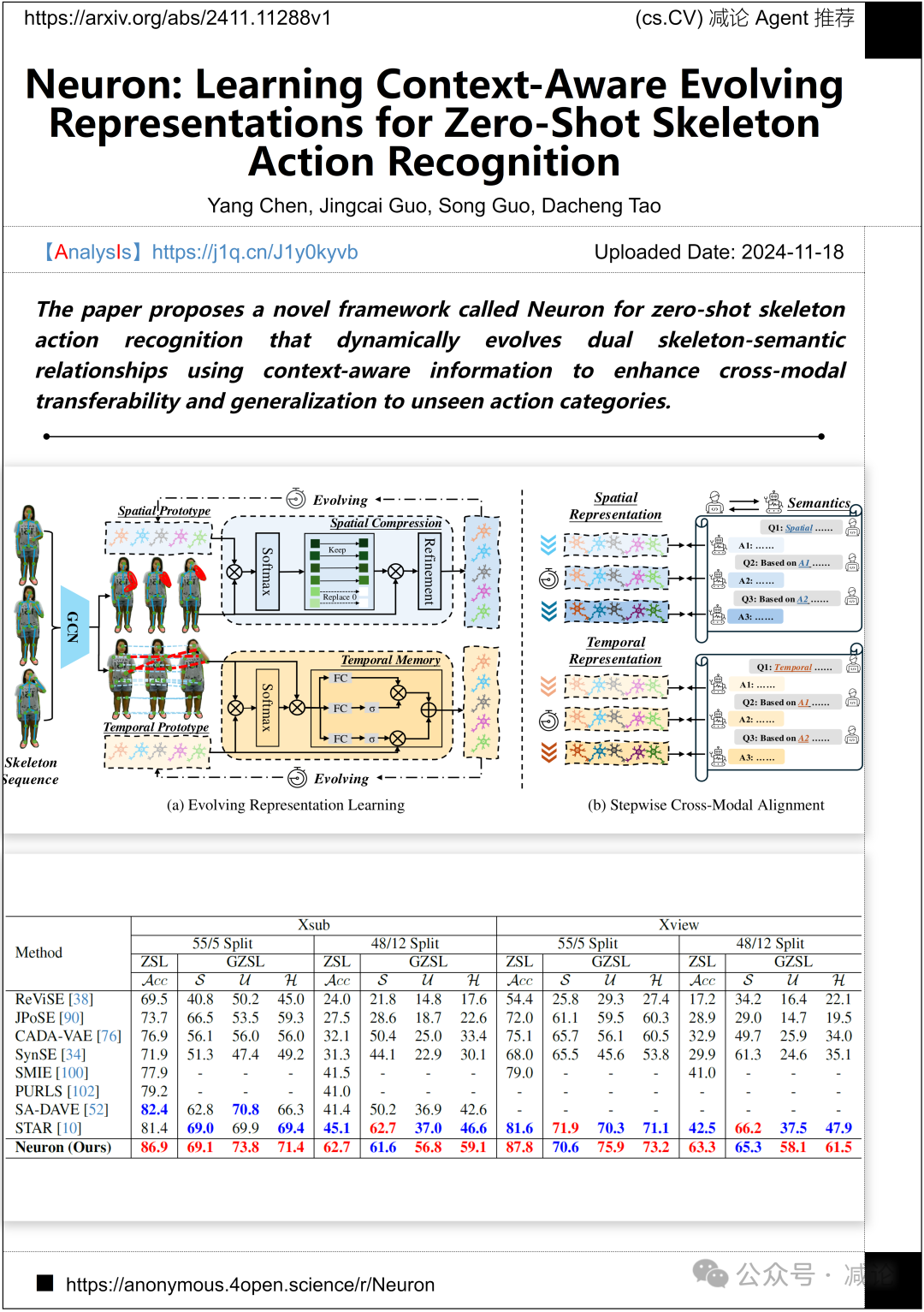
香港理工大学、香港科技大学和南洋理工大学的研究团队提出了一个名为Neuron的新颖框架,用于零样本骨架动作识别。该框架通过使用上下文感知信息动态演化双骨架语义关系,以增强跨模态传递能力,并泛化到未见过的动作类别。
【Bohr精读】
https://j1q.cn/J1y0kyvb
【arXiv链接】
http://arxiv.org/abs/2411.11288v1
【代码地址】
https://anonymous.4open.science/r/Neuron

南卡罗来纳大学,古鲁戈宾德辛格因德拉普拉斯塔大学,亚马逊GenAI团队推出了ViBe方法。该论文介绍了ViBe,一个用于评估由文本到视频模型生成的虚构视频的大规模基准,对幻觉进行了五种类型的分类,并提供了一个包含3,782个带注释视频的数据集,以提高T2V模型的可靠性。
【Bohr精读】
https://j1q.cn/yRLeCJYM
【arXiv链接】
http://arxiv.org/abs/2411.10867v1
【代码地址】
https://vibe-t2v-bench.github.io/

牛津大学,印度信息技术研究所,阿姆斯特丹大学的研究团队提出了一种方法,通过在模拟和视觉数据上训练音高检测模型,从倒水的声音推断液体倾倒的物理特性,如液位和倾倒速率,并通过一个新的真实倒水视频数据集进行验证。
【Bohr精读】
https://j1q.cn/NjPeL4S4
【arXiv链接】
http://arxiv.org/abs/2411.11222v1
【代码地址】
https://bpiyush.github.io/pouring-water-website

上海交通大学和香港理工大学的研究团队提出了一个名为RCMSTR的统一框架,结合了关系对比学习和遮罩图像建模。通过建模丰富的文本关系和通过关系重排和有效的遮罩策略减轻过拟合,以增强场景文本识别中的自监督表示学习。
【Bohr精读】
https://j1q.cn/4OsysuTG
【arXiv链接】
http://arxiv.org/abs/2411.11219v1
【代码地址】
https://github.com/ThunderVVV/RCMSTR

韩国科学技术院的研究团队提出了一个名为平衡对齐和均匀性(BAU)的框架,通过平衡原始和增强图像的对齐和均匀性损失,同时引入领域特定的均匀性损失来增强领域不变特征的学习。
【Bohr精读】
https://j1q.cn/6vpgeyau
【arXiv链接】
http://arxiv.org/abs/2411.11471v1
【代码地址】
https://github.com/yoonkicho/BAU

腾讯,复旦大学的研究团队提出了FitDiT,一种利用扩散Transformer的服装感知增强技术,以提高纹理感知维护和尺寸感知贴合,从而实现高保真度的虚拟试穿。论文在细节和贴合准确性方面取得了优越的结果。
【Bohr精读】
https://j1q.cn/d13Ff129
【arXiv链接】
http://arxiv.org/abs/2411.10499v1
【代码地址】
https://byjiang.com/FitDiT/

罗切斯特大学和亚利桑那州立大学的研究团队提出了VidComposition方法,旨在通过精心策划的视频和详细注释来评估多模态大型语言模型(MLLMs)的视频合成理解能力的基准,揭示了人类和模型理解之间的显著性能差距。
【Bohr精读】
https://j1q.cn/1Twg7eEM
【arXiv链接】
http://arxiv.org/abs/2411.10979v1
【代码地址】
https://yunlong10.github.io/VidComposition/

北京航空航天大学的研究团队提出了CCExpert,这是一个新颖的模型,用于遥感图像变化字幕。该模型利用了一个差异感知集成模块和一个大型、多样化的数据集,以提高多模态大型语言模型在生成双时相遥感图像表面变化的详细自然语言描述方面的性能。
【Bohr精读】
https://j1q.cn/CQVOn2hn
【arXiv链接】
http://arxiv.org/abs/2411.11360v1
【代码地址】
https://github.com/Meize0729/CCExpert
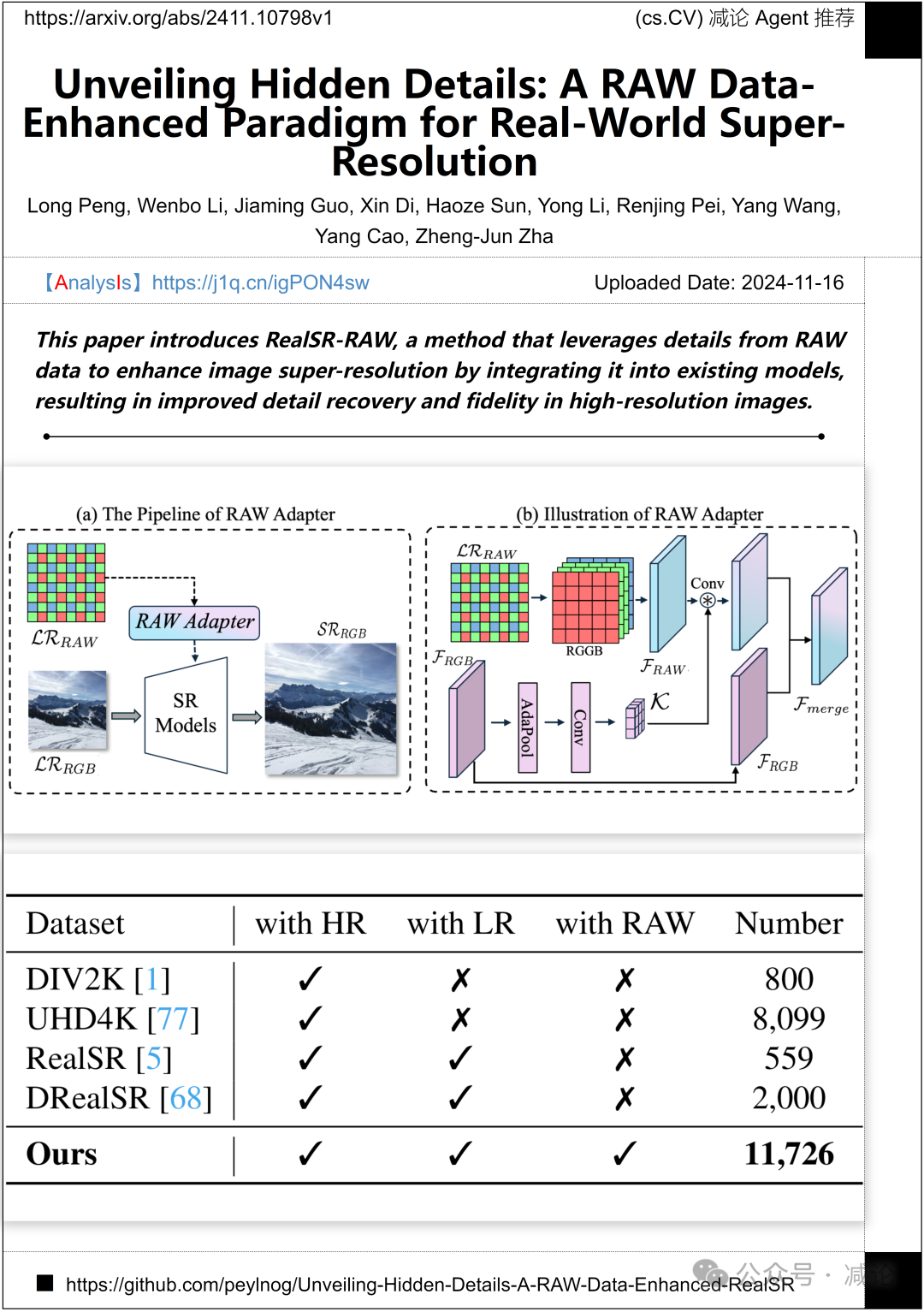
中国科学技术大学、华为诺亚方舟实验室和清华大学的研究团队推出了RealSR-RAW方法,这是一种利用RAW数据中的细节来增强图像超分辨率的创新方法。通过将RealSR-RAW整合到现有模型中,可以显著改善高分辨率图像的细节恢复和保真度。
【Bohr精读】
https://j1q.cn/igPON4sw
【arXiv链接】
http://arxiv.org/abs/2411.10798v1
【代码地址】
https://github.com/peylnog/Unveiling-Hidden-Details-A-RAW-Data-Enhanced-RealSR
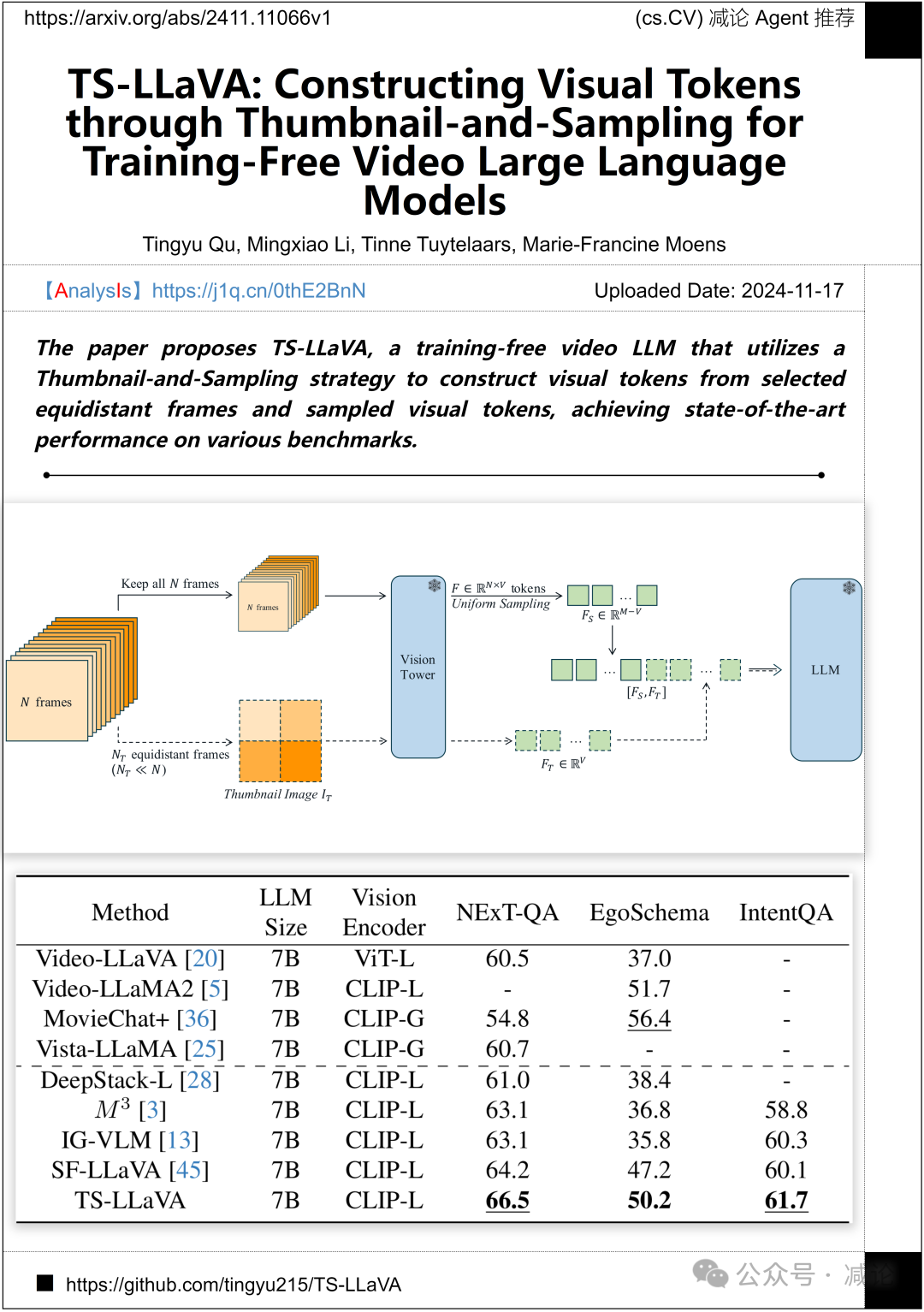
鲁汶大学的研究团队提出了TS-LLaVA,一种无需训练的视频LLM,利用缩略图和采样策略从选定的等距帧和采样的视觉令牌构建视觉令牌,实现了在各种基准测试中的最先进性能。
【Bohr精读】
https://j1q.cn/0thE2BnN
【arXiv链接】
http://arxiv.org/abs/2411.11066v1
【代码地址】
https://github.com/tingyu215/TS-LLaVA

浙江大学、北京航空航天大学、清华大学的研究团队提出了AnimateAnything方法。该方法是一种统一可控的视频生成方法,利用多尺度控制特征融合网络创建共同的运动表示,将控制信息转换为光流来引导视频生成,同时通过基于频率的稳定模块解决闪烁问题。
【Bohr精读】
https://j1q.cn/dZQaD5DD
【arXiv链接】
http://arxiv.org/abs/2411.10836v1
【代码地址】
https://yu-shaonian.github.io/Animate_Anything/
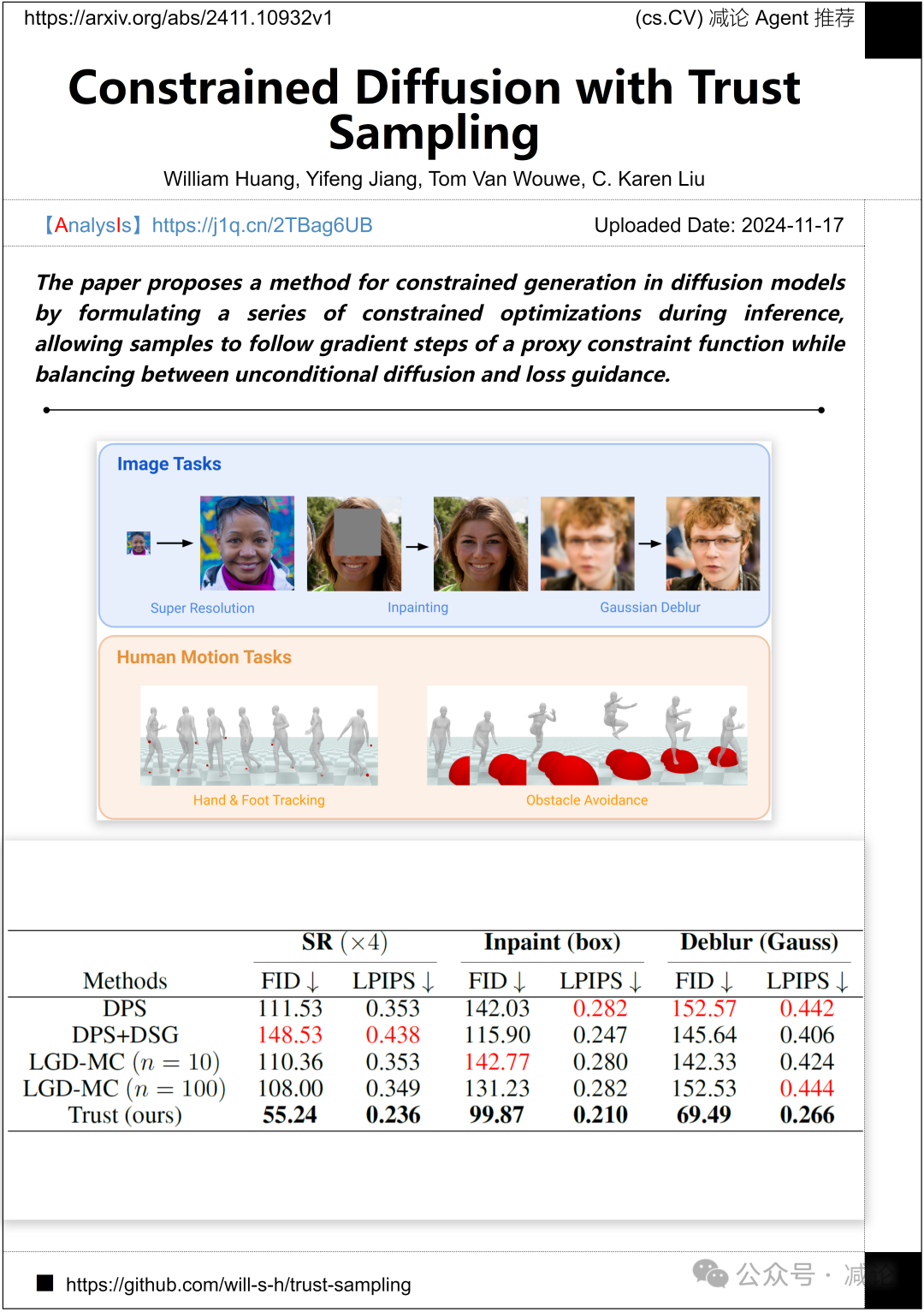
斯坦福大学的研究团队提出了一种在扩散模型中进行受限生成的方法。他们通过在推断过程中制定一系列受限优化,使样本能够遵循代理约束函数的梯度步骤,同时在无条件扩散和损失引导之间保持平衡。
【Bohr精读】
https://j1q.cn/2TBag6UB
【arXiv链接】
http://arxiv.org/abs/2411.10932v1
【代码地址】
https://github.com/will-s-h/trust-sampling
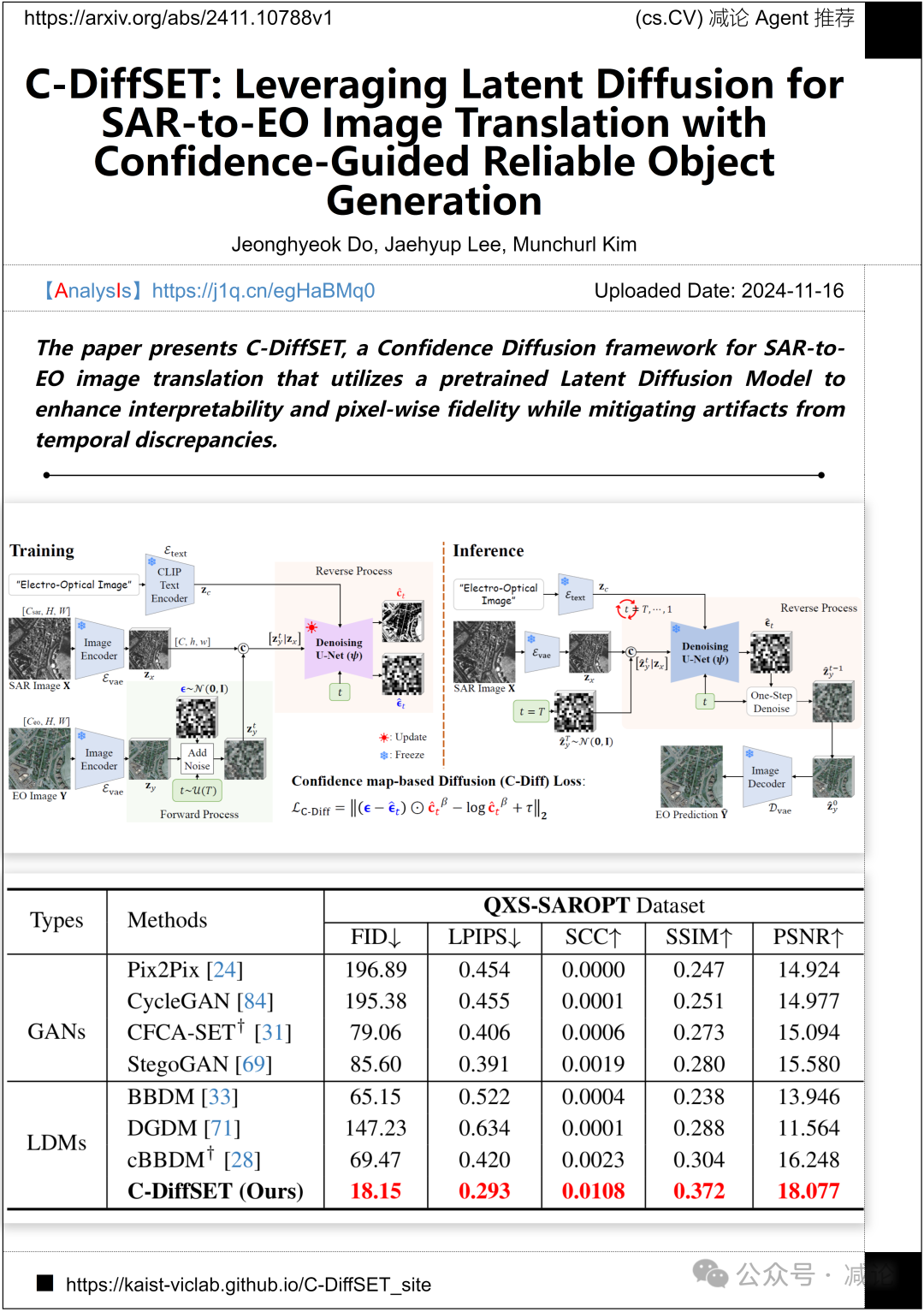
韩国科学技术院和釜山国立大学的研究团队提出了C-DiffSET,一种置信度扩散框架,用于SAR到EO图像翻译。他们利用预训练的潜在扩散模型来增强可解释性和像素级保真度,同时减轻由时间差异引起的伪影。
【Bohr精读】
https://j1q.cn/egHaBMq0
【arXiv链接】
http://arxiv.org/abs/2411.10788v1
【代码地址】
https://kaist-viclab.github.io/C-DiffSET_site
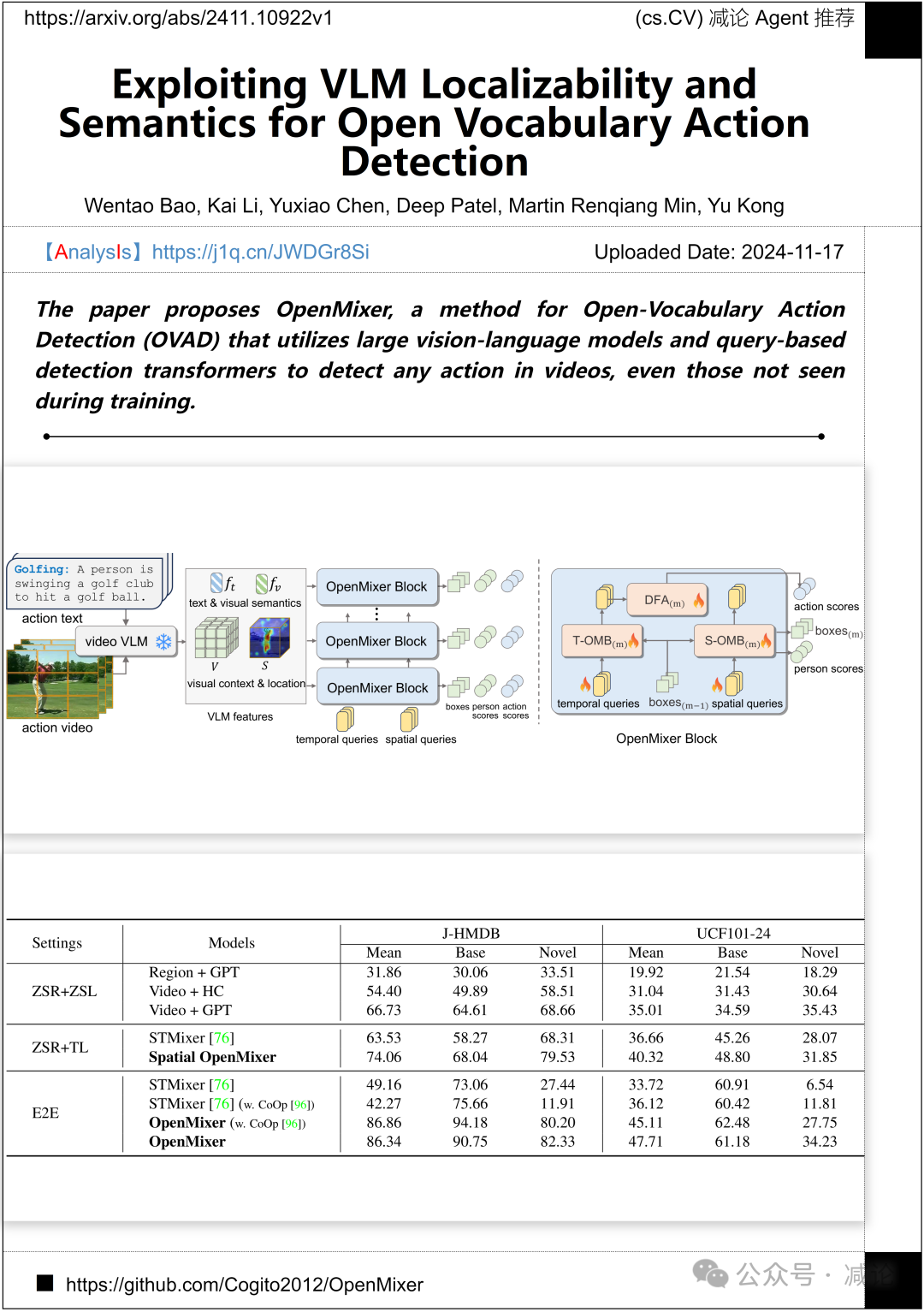
密歇根州立大学,日本电气通信实验室美国分部,罗格斯大学的研究团队提出了OpenMixer方法。该方法用于开放词汇动作检测(OVAD),利用大型视觉语言模型和基于查询的检测transformer来检测视频中的任何动作,甚至是在训练过程中没有见过的动作。
【Bohr精读】
https://j1q.cn/JWDGr8Si
【arXiv链接】
http://arxiv.org/abs/2411.10922v1
【代码地址】
https://github.com/Cogito2012/OpenMixer

武汉大学、中山大学、南洋理工大学的研究团队提出了Stepwise Diffusion Policy Optimization(SDPO)方法,这是一种通过利用每个中间步骤的密集奖励反馈来增强少步扩散模型的方法,以实现一致的对齐和在各种去噪场景下提高性能。
【Bohr精读】
https://j1q.cn/1Or5YGJl
【arXiv链接】
http://arxiv.org/abs/2411.11727v1
【代码地址】
https://github.com/ZiyiZhang27/sdpo
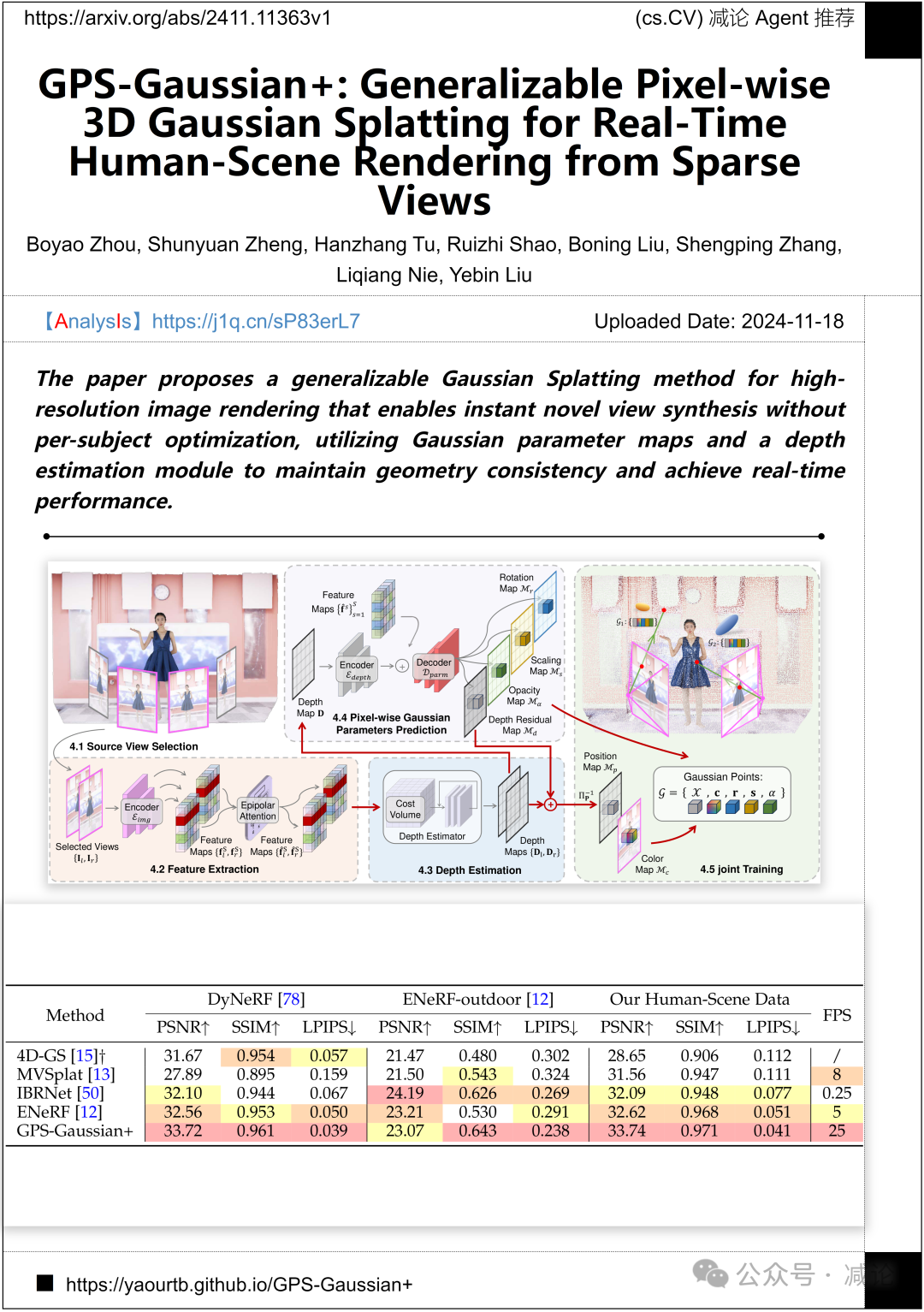
清华大学和哈尔滨工业大学的研究团队提出了一种通用的高斯点渲染方法,用于高分辨率图像渲染。该方法实现了即时的新视角合成,无需每个主体的优化。通过利用高斯参数图和深度估计模块,保持几何一致性并实现实时性能。
【Bohr精读】
https://j1q.cn/sP83erL7
【arXiv链接】
http://arxiv.org/abs/2411.11363v1
【代码地址】
https://yaourtb.github.io/GPS-Gaussian+

三星先进技术研究院的团队提出了MapUnveiler方法,这是一种新颖的剪辑级矢量化高清地图构建方法,通过利用密集图像表示和剪辑间信息传播,增强了对遮挡道路元素的预测,实现了在具有挑战性的驾驶场景中的最先进性能。
【Bohr精读】
https://j1q.cn/9peYqfB4
【arXiv链接】
http://arxiv.org/abs/2411.11002v1
【代码地址】
https://mapunveiler.github.io
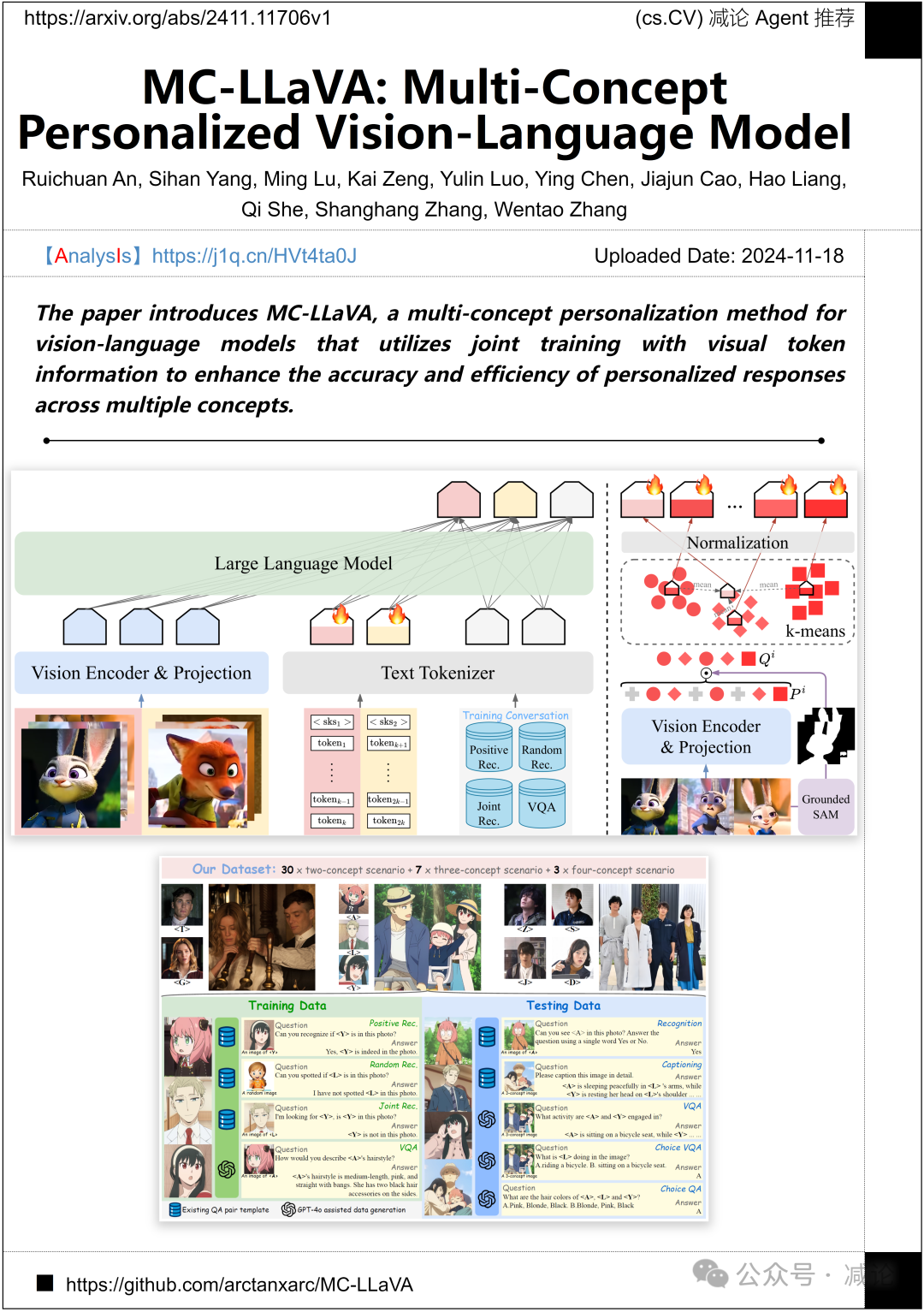
北京大学、西安交通大学、天津大学的研究团队提出了MC-LLaVA方法,该方法是一种多概念个性化方法,用于视觉–语言模型。这种方法利用视觉令牌信息进行联合训练,以提高跨多个概念的个性化响应的准确性和效率。
【Bohr精读】
https://j1q.cn/HVt4ta0J
【arXiv链接】
http://arxiv.org/abs/2411.11706v1
【代码地址】
https://github.com/arctanxarc/MC-LLaVA

欢迎关注减论,持续输出有深度的人工智能极减理解,提升信息获取效率和认知维度。看完点颗小星星再走呗~