
前言,最近经常和朋友讨论英伟达GPU和国产AI芯片的算力情况,无意中发现英伟达GPU卡有“公式”可以进行“峰值算力”的计算,比如A100的FP64、FP32和FP16等主流精度到底和GPU卡本身那些参数有关呢?如何通过“公式”的方式计算出来A100 FP16稀疏稠密的算力呢?我们简单聊聊
一、英伟达GPU A100产品了解
1、英伟达A100彩页参数截图:可以看到PCIe和SXM两版本算力参数一致,不同算力精度对应不同的业务场景,比如面向HPC场景的是FP64,面向AI场景的FP32和FP16,但是算力又分为CUDA core的标准算力和Tenser core加速后是算力。


2、英伟达A100的组成单元:下图是从NVIDIA Ampere产品的白皮书的截图,其中内部密密麻麻的是各种单元,其中GPC是图形处理集群,A100 GPU的GPC具体数量为7个,每个GPC包括8个TPC(纹理处理集群),每个TCP又包括2个 SM (流式多处理器),其中SM有108个;

3、A100 GPU SM内部组成:通过下图可以看到每个SM包括一共64个FP32+64个INT32+32个FP64+4个Tensor Cores,SM的数量是GPU算力计算的参数之一。

二、英伟达GPU A100算力的计算公式
GPU 峰值算力的测算公式为:
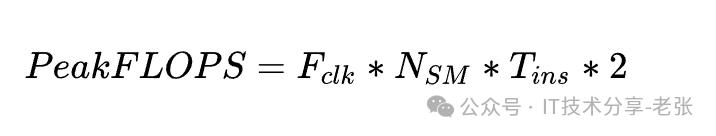
峰值计算能力= GPU Core 的运行频率*GPU SM 数量*单个SM一个时钟周期内特定数据类型的指令吞吐量*2
运行频率的单位为 GHz,一个时钟周期内特定数据类型的指令吞吐量单位为FLOPS/Cycle,其中不太好理解是后面2项;
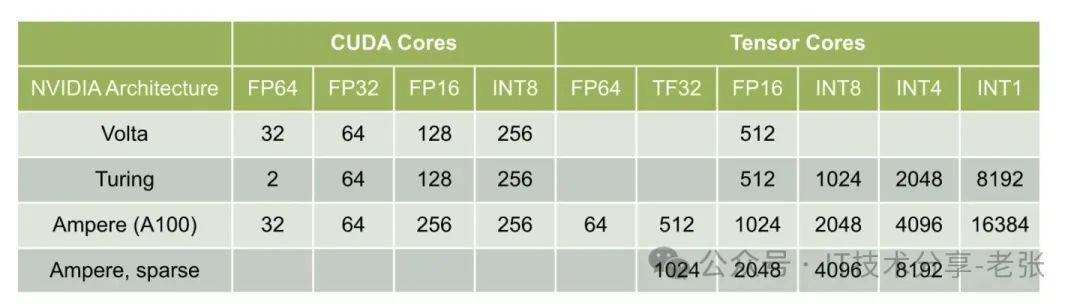
1、单个SM一个时钟周期内特定数据类型的指令吞吐量,与英伟达每一代的GPU架构设计有关,与基于标准CUDA Core还是通过Tenser core加速也有关,在不同精度的表现也都不一样,具体如下(图片来自网络);
2、公式里面的“2”怎么理解,是因为Tensor Core融合了乘和加的指令,每次执行指令会计算一次乘法和一次加法,视作两次浮点运算所以乘以2;
三、英伟达A100算力计算举例
我们以A100的几个常见精度算力进行举例,A100的运行频率1.41 GHz
1、FP64 Tenser core的峰值算力为:1.41x108x64x2≈19492GFlops,换算成T为19.5Tflops,与彩页里的官方公布的算力数值一致。
2、FP16 Tenser core的峰值算力:1.41x108x1024x2≈311869GFlops,换算成T为312TFlops,同样也和彩页里的数值一致。
3、稀疏算力对应的“周期内特定数据类型的指令吞吐量”是标准Tenser core下的2倍,所以算力也是2倍的关系。
因为没有找到H100的“特定数据类型的指令吞吐量”,所以就没用H100举例,如果屏幕前的朋友有这个资料可以私聊发我一下,多谢!
四、资料分享环节
如果你也想要英伟达A100、H100技术架构白皮书,可以帮我公众号“IT技术分享-老张”点个关注,在聊天栏发送“20241119白皮书”,会自动获得百度网盘的下载链接,感谢大家支持!
—-老张会持续通过公众号分享前沿IT技术,创作不易,大家多多点赞和关注!