

 Arvind Jain 阿尔温德·贾恩 CEO
Arvind Jain 阿尔温德·贾恩 CEO
发布时间:2024 年 5 月 15 日。最后更新日期 2024 年 11 月 6 日。

自从生成式 AI 和 LLM 在世界舞台上占据中心位置以来,员工们一直在思考如何最好地将这些变革性的新工具应用于他们的工作流程。然而,他们中的许多人在尝试将生成式 AI 集成到企业环境中时遇到了类似的问题,例如隐私泄露、缺乏相关性以及需要更好的个性化结果。
为了解决这个问题,大多数人得出结论,答案在于检索增强生成 (RAG)。RAG 通过企业搜索等外部发现系统将知识检索与生成过程分开。这使得 LLM 及其提供的响应能够以真实的外部企业知识为基础,这些知识可以很容易地浮出水面、追溯和参考。
来源:
https://www.glean.com/blog/hybrid-vs-rag-vector
企业智能知识库企业Glean利用GraphRAG融资2.6亿美元
仅靠向量或词法搜索是不够的
既然企业明白生成式 AI 解决方案需要单独的检索解决方案,许多人会问 — 为什么我们不将内容放入矢量数据库并实施简单的 RAG 提示呢?遗憾的是,答案并不那么简单,尤其是在提供真正的企业级体验时。
让我们简要探讨一下向量搜索和数据库如何用于数据索引和检索。嵌入模型可以有效地将特定文本映射到固定的数字向量 – 给定一组单词,模型将分配一个数值,在数据库中表示该文本。然后,给定查询的文本,系统可以计算查询中的文本与该向量空间中预先索引的文档文本的“接近”程度,然后将其提取以显示在结果中。
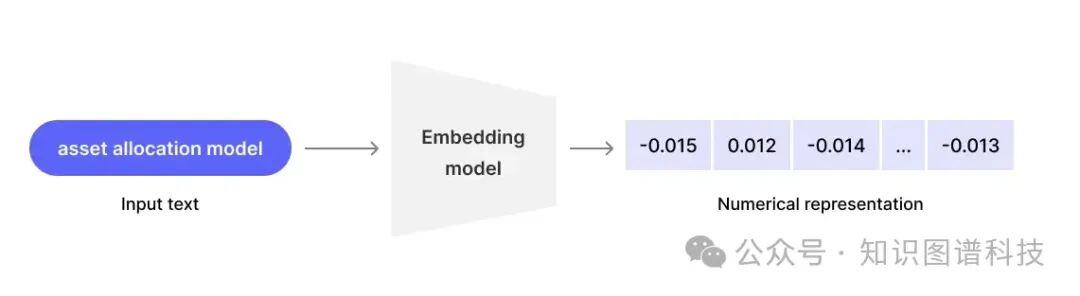
此步骤应仅用作信息检索过程。然后,LLM 被严格用作推理层,最初调用搜索/检索引擎,读取有限的上下文,然后通过向量数据库根据正确的信息提取并生成连贯的响应。
尽管矢量搜索的改进标志着语义理解的根本转变,但它只是为企业搜索提供高质量结果的一小部分拼图。仅靠简单的矢量搜索无法识别组织内所有内容、人员和活动之间更复杂的联系。
更过时的是简单的词法搜索系统,它们直接将查询词与文档内容和元数据词匹配。虽然易于实现,但它们只能利用数据库中单词或短语的精确匹配,这会带来严重的限制,尤其是在提供查询时遇到人为错误时。
通过混合搜索改进结果
相反,利用混合搜索系统的解决方案可以提供世界上最好的。例如,Glean的复杂RAG解决方案具有四个核心技术差异化因素,使其混合搜索和生成式AI解决方案与众不同:
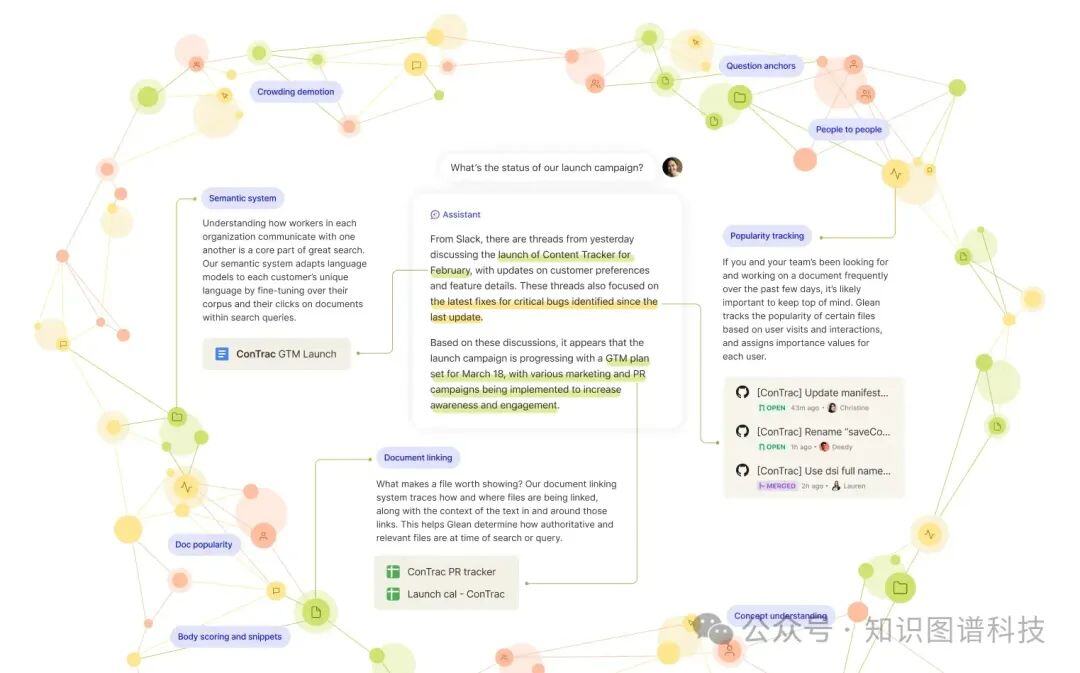
Glean 稳健结果的核心是知识图谱 — 一个由无数信号和锚点组成的网络,它们都致力于解决潜在构建者必须解决的问题。这些因素帮助 Glean 获得组织内所有文档、人员和活动背后的丰富背景,从而帮助模型更好地告知模型交付出色结果所需的信息。简而言之,信号和锚点就像解开谜团所需的线索。解决方案必须使用的越多,结果就越好!
例如,Glean’s signals 正在积极解决单个搜索和个性化问题,例如:
那么,具有复杂 RAG 解决方案的系统与没有 RAG 解决方案的系统之间有什么区别呢?让我们看一下一些生成结果的快速示例。
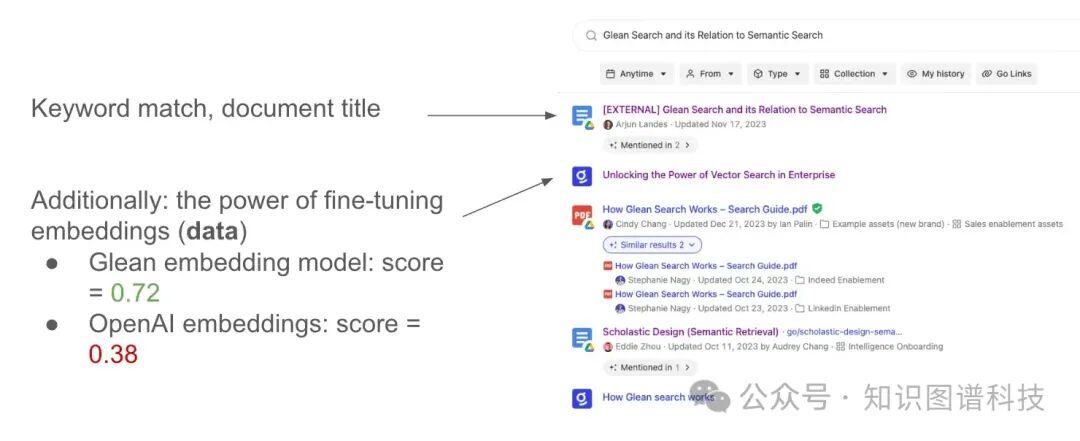
在 Glean,Scholastic 是将语义搜索集成到排名堆栈中的方法,专注于基于标题、锚点和标题的检索和评分。让我们看看当被问及 Scholastic 时,与 Glean 相比,标准的 RAG 解决方案可能会如何回答:
标准回答(Vector、简单 RAG)
Q: What is Scholastic?
Q:什么是 Scholastic?
A: Scholastic, located in New York City, New York, is a publisher and distributor of children’s books, educational technology, and related services…
答:Scholastic 位于纽约州纽约市,是儿童读物、教育技术和相关服务的出版商和分销商……
Glean (Hybrid, complex RAG)
Glean (混合、复杂、Graph RAG)
Q: What is Scholastic?
Q:什么是 Scholastic?
A: Scholastic is our learned vector-based retrieval and scoring system (a play on our keyword-based system, Elastic). It learns item embeddings for documents and messages, and retrieves / scores nearest neighbors for a given query…
答:Scholastic 是我们学习的基于向量的检索和评分系统(我们基于关键字的系统 Elastic 的玩法)。它学习文档和消息的项嵌入,并检索/评分给定查询的最近邻居……
标准响应与工作查询完全无关,而 Glean 的响应理解分配并准确提供用户正在寻找的内容。
无论是生成式 AI 提供的响应,还是在搜索中提供的结果,由信号和锚点网络增强的混合、复杂的 RAG 解决方案都比不完整的词汇或向量搜索解决方案提供更好的结果。利用专有数据作为微调模型的关键和线索的能力为企业环境提供了搜索和生成式 AI 解决方案所需的丰富情境化。
在企业搜索领域,同样明显的是,仅依靠向量或语义搜索可能并不总是产生最佳结果。在需要精确性的情况下尤其如此,例如在搜索特定术语、文档或关键字时。向量搜索具有固有的模糊性,可能并不总是与这些情况下所需的精度一致。
对于 Glean,我们的词汇搜索功能也因数据的稳健性而脱颖而出。这种优势使我们能够不仅能够高精度地匹配查询,还可以在大量潜在匹配中个性化结果。Glean 采用的混合搜索方法结合了两全其美的优势,利用了词汇搜索的精确性和对向量搜索的细致理解——所有这些都由我们知识图谱中的信号和锚点提供的额外上下文和细微差别提供支持。
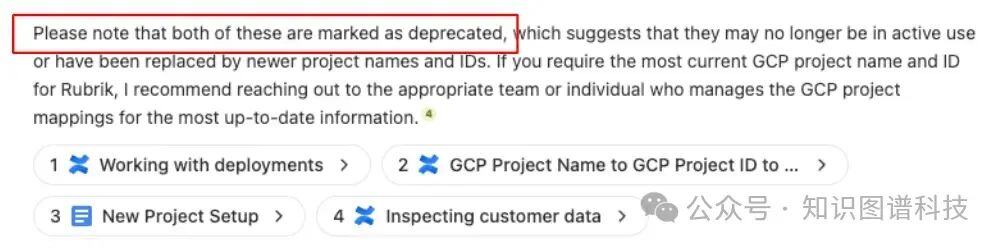
最重要的是,Glean 将 LLM 与我们专有的搜索界面联系起来的能力使我们能够更优雅地处理搜索和检索遗漏。与我们的搜索界面集成的 LLM 可以更有说服力地处理搜索和检索遗漏。例如,大多数第三方解决方案在面对他们无法充分回答的问题时,通常会提供不新鲜或不相关的不良信息。
然而,当涉及到 Glean 时,LLM 获得了他们需要的额外背景信息,以澄清警告和预防措施。这些额外的信息使 AI 能够为员工提供他们所需的额外信息,以便他们执行后续步骤,或者更好地了解他们收到的信息可能不完整的原因。
更好的前进道路
如果您希望通过利用生成式 AI 的潜力在现在和今天保持领先地位,Glean 是最好的方式。Glean 始终具有权限感知能力、相关和个性化、新鲜和最新,并且普遍适用于您最常用的应用程序。
使用真正企业级的生成式 AI 解决方案提高团队的工作效率。

参考文献