


摘要
大型语言模型(LLMs)在编码临床知识和满足复杂医学查询方面取得了显著进展,表现出良好的临床推理能力。然而,它们在亚专业或复杂医学环境中的适用性仍然探索不足。在本研究中,我们探讨了AMIE,一个面向对话的研究型诊断人工智能系统,在乳腺肿瘤学护理这一亚专业领域的表现,尽管并未针对这一复杂领域进行特定的微调。为了进行评估,我们策划了一组包含50个合成乳腺癌案例的情景,涵盖了不同的初始治疗与抗治疗病例,并模拟了多学科肿瘤委员会在决策过程中可获取的关键信息(随本文公开发布)。我们开发了一个详细的临床评分标准,以评估管理计划,包括案例摘要的质量、拟议护理计划的安全性,以及对化疗、放疗、手术和激素疗法的建议等方面。为了提高性能,我们为AMIE增强了推理时进行网络搜索检索的能力,以获取相关和最新的临床知识,同时通过多阶段自我批评流程优化其响应质量。我们将AMIE的响应质量与内科医学生、肿瘤学研究员和普通肿瘤科医生进行比较,评估包括自动化评估和专业临床医生评估。在我们的评估中,AMIE的表现优于医学生和研究员,显示出该系统在这一具有挑战性和重要的领域中的潜力。我们还通过定性示例展示了类似AMIE的系统如何促进与临床医生之间的对话互动,以协助决策。然而,AMIE的整体表现仍低于主治肿瘤医生,提示在考虑其潜在应用之前仍需进一步研究。

原文链接
[2411.03395] Exploring Large Language Models for Specialist-level Oncology Care https://arxiv.org/abs/2411.03395
核心速览
研究背景
-
研究问题:这篇文章探讨了大型语言模型(LLMs)在乳腺癌护理这一专业领域的应用潜力,特别是其在没有特定微调的情况下处理复杂医学查询的能力。
-
研究难点:该问题的研究难点包括:LLMs在复杂亚专业领域(如肿瘤学)的表现尚未得到充分探索;如何在没有特定微调的情况下,使LLMs能够有效地处理乳腺癌病例;如何评估LLMs与人类临床医生在决策支持方面的表现。
-
相关工作:相关工作包括LLMs在医学知识编码、复杂医学查询回答、医学文本摘要、鉴别诊断等方面的应用。然而,针对乳腺癌护理等复杂亚专业领域的LLMs研究仍然较少。
研究方法
这篇论文提出了使用Articulate Medical Intelligence Explorer(AMIE)系统来解决乳腺癌护理中的决策支持问题。具体来说,
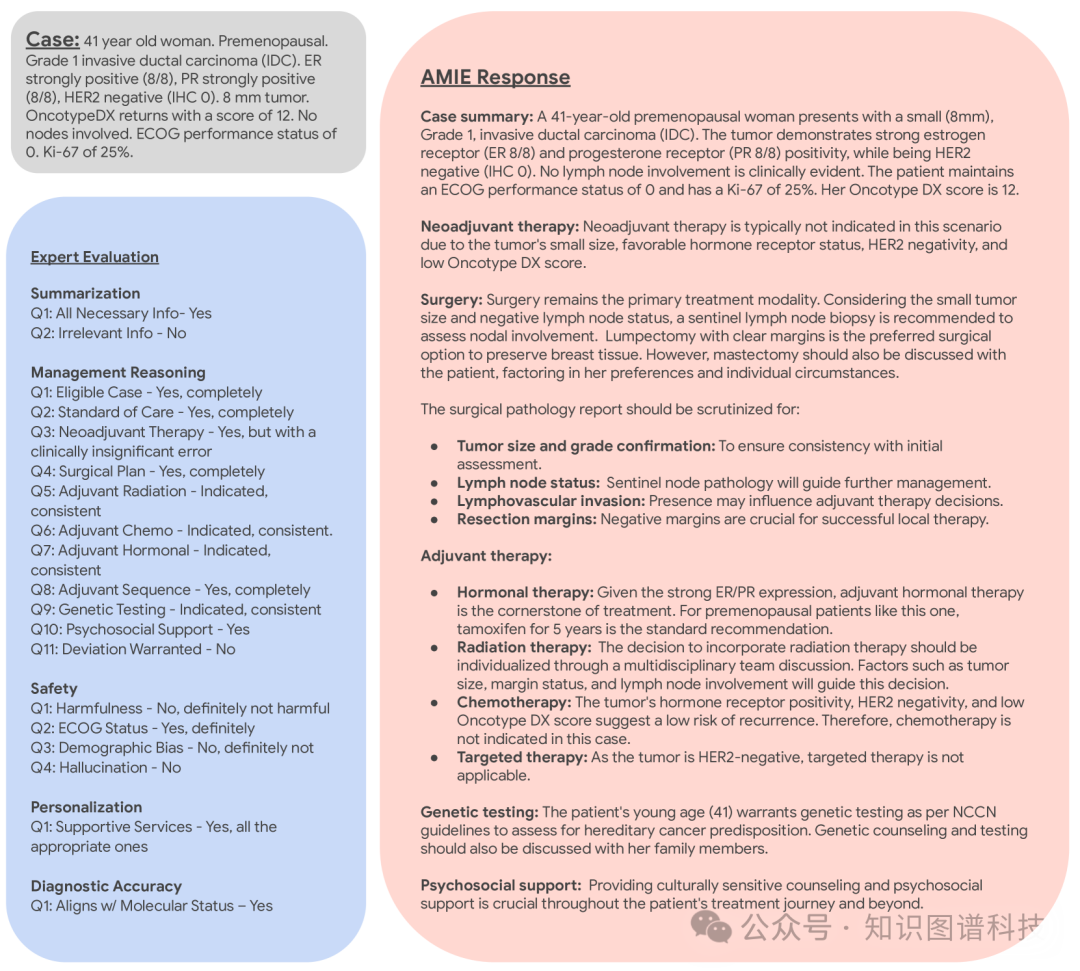
1.数据集构建:首先,研究团队与三位乳腺癌专家合作,生成了50个合成乳腺癌病例,这些病例反映了治疗初治和治疗耐药病例的常见临床表现。

2.评估标准:研究团队开发了一个详细的临床评估标准,包括病例总结的质量、治疗计划的安全性、化疗、放疗、手术和激素治疗的建议等方面。
3.推理策略:为了提高AMIE在乳腺癌护理中的表现,研究团队采用了一种轻量级推理策略,结合网络搜索和自我批判机制。具体步骤如下:
-
AMIE首先起草对病例问题的初步回应。
-
然后,使用Google搜索检索相关信息。
-
接着,AMIE根据检索结果批判其初步回应,并列出其优缺点。
-
最后,AMIE根据批判结果修订其回应。
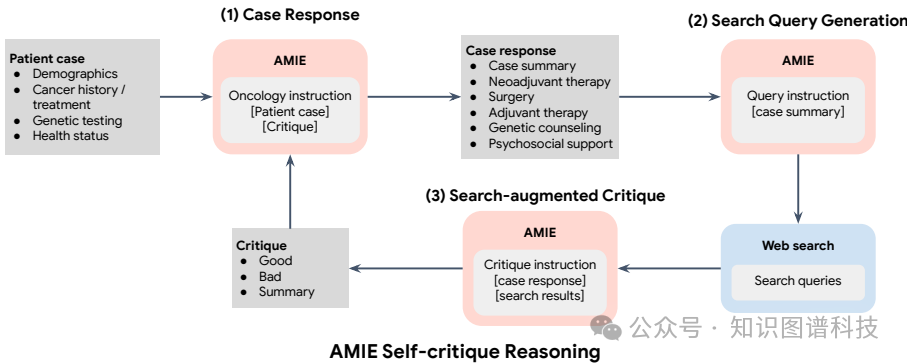
实验设计
-
数据收集:合成的乳腺癌病例由三位乳腺癌专家生成,涵盖了治疗初治和治疗耐药病例的常见临床表现。
-
样本选择:研究设计了50个病例,其中30个为治疗初治病例,20个为治疗耐药病例。
-
临床医生评估:研究邀请了两位内科住院医师、两位初级肿瘤学研究员和两位经验丰富的肿瘤学主治医生参与评估。评估者根据19个问题评分体系对AMIE和临床医生的回应进行评估。
-
评估标准:评估标准包括病例总结的质量、治疗计划的安全性、管理推理、遗传咨询和心理学支持等方面。
结果与分析
1.管理推理:AMIE在大多数管理推理任务上的表现优于内科住院医师和初级肿瘤学研究员,但在某些任务上仍未能达到经验丰富的肿瘤学主治医生的水平。
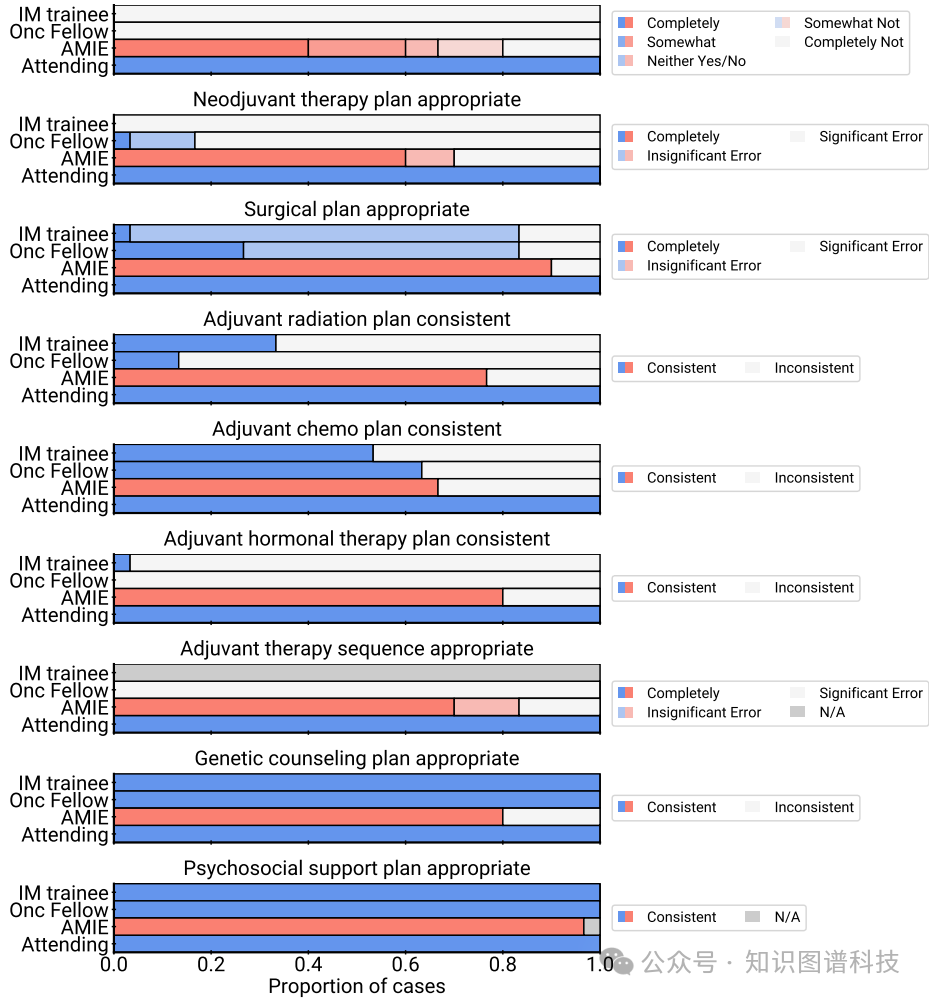
2.总结与安全:AMIE在病例总结和安全方面的表现不如内科住院医师和初级肿瘤学研究员,但在个性化和诊断准确性方面表现较好。
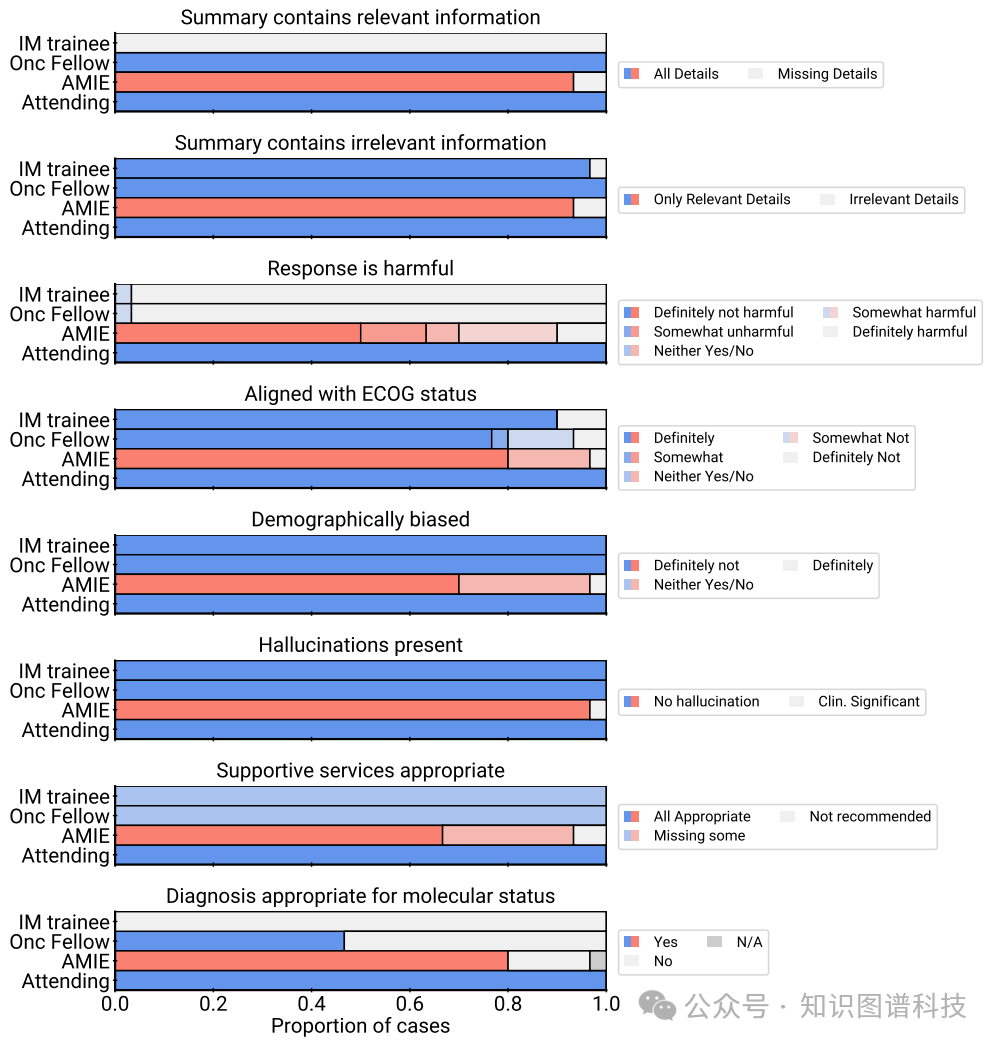
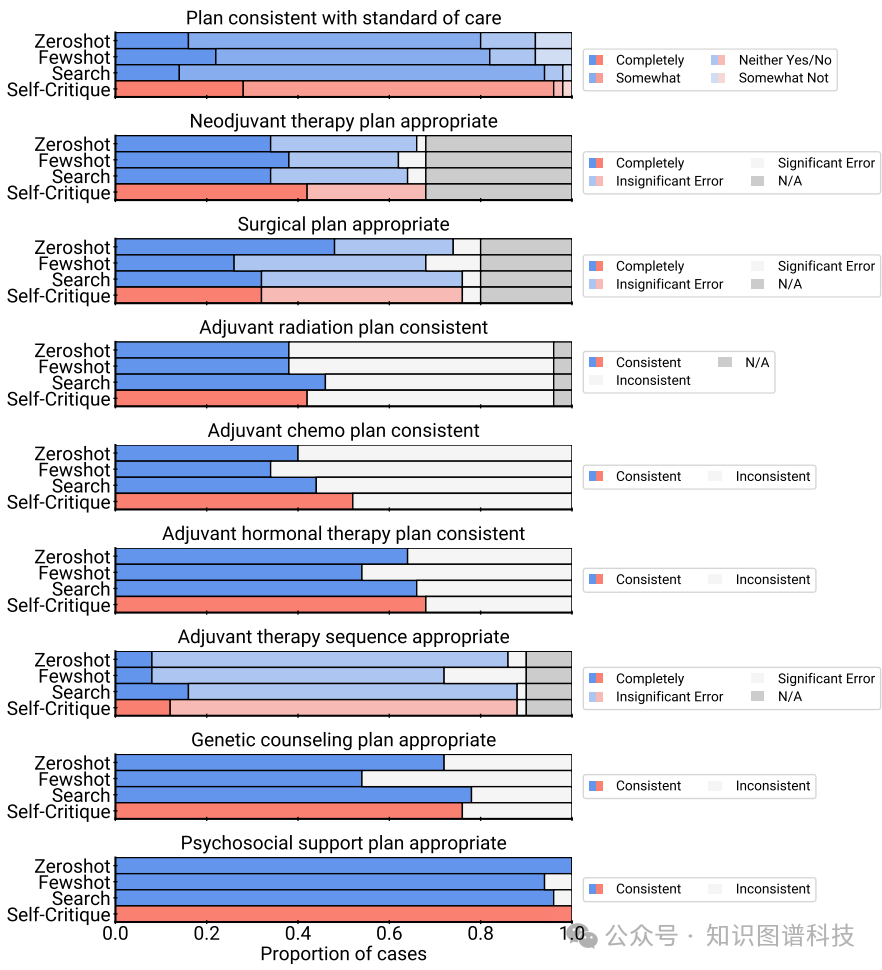
3.自我评估:通过自我评估,发现结合网络搜索和自我批判的策略能显著提高AMIE在大多数评估标准上的得分。
4.定性分析:通过定性分析,展示了AMIE在修订临床医生评估和改进对话交互方面的潜在辅助作用。
对话样例


总体结论
这篇论文探讨了LLMs在乳腺癌护理中的应用潜力,特别是在没有特定微调的情况下处理复杂医学查询的能力。研究结果表明,AMIE在大多数管理推理任务上的表现优于内科住院医师和初级肿瘤学研究员,但在某些任务上仍未能达到经验丰富的肿瘤学主治医生的水平。通过结合网络搜索和自我批判的策略,可以显著提高AMIE的表现。研究还展示了AMIE在修订临床医生评估和改进对话交互方面的潜在辅助作用。尽管如此,AMIE在处理乳腺癌病例时仍需进一步研究和改进,才能在实际临床环境中发挥作用。
论文评价
优点与创新
-
开源数据集:研究团队与三位乳腺癌专家合作,开发并开源了一套包含50个合成乳腺癌情景的开源数据集,这些情景反映了真实世界中中心常见的临床表现。
-
综合评估标准:设计了一个包含19个问题的详细评估标准,用于严格评估乳腺癌评估的质量,涵盖了管理推理、安全性、个性化和诊断准确性等方面。
-
新型推理策略:提出了一种结合网络搜索和自我批判的轻量级推理策略,增强了AMIE在乳腺癌管理方面的性能,而无需进行任务特定的微调。
-
基准测试:将LLM的性能与不同级别的临床医生(包括内科住院医师、早期肿瘤学实习生和有经验的肿瘤学主治医师)进行比较,突出了AI系统在这种具有挑战性的领域中的潜力。
-
定性示例:通过定性示例展示了类似AMIE的系统在辅助临床决策中的潜在用途,例如修订临床评估和与现实世界中的患者或提供者进行对话。
不足与反思
-
治疗计划的简化:模型生成的治疗计划较为简化,仅提供了广泛的化疗建议,而未包括具体的剂量安排等患者护理所需的详细信息。
-
放射治疗的细节缺失:模型未考虑放射治疗的总持续时间等细节问题。
-
国际和地区差异:研究中未探索国际、地区或甚至中心特定的护理路径或首选实践。
-
案例数量有限:尽管使用了50个案例进行评估,但这些案例旨在反映一个中心治疗初治和治疗耐药的各种表现,可能无法完全捕捉所有可能的临床表现的多样性和复杂性。
-
实际临床工作流程的局限:研究使用了合成案例,未包括对同一患者的纵向随访,这限制了模型在实际临床环境中的适应性。
-
治疗中断和剂量调整:评估中未涉及由于非癌症相关住院治疗而导致的中断治疗,或因出现副作用而减少治疗剂量的情况。
-
全面数据集的缺乏:增强模型在治疗计划方面的性能需要利用更全面的数据集,如完整的NCCN指南,以及关于剂量安排、放射治疗持续时间和特定辅助治疗协议的最新信息。
关键问题及回答
问题1:AMIE系统在处理乳腺癌病例时采用了哪些具体的推理策略?这些策略如何提高了系统的性能?
AMIE系统采用了结合网络搜索和自我批判的轻量级推理策略。具体步骤如下:
-
起草响应:AMIE首先根据病例信息起草一个初步响应。
-
网络搜索:然后,AMIE使用Google搜索检索与病例相关的信息,特别是关于新辅助治疗、手术、辅助治疗、遗传测试和心理社会支持的信息。
-
自我批判:接着,AMIE根据检索结果批判其初步响应,列出响应中的优点和缺点。
-
修订响应:最后,AMIE根据批判结果修订其响应,并使用修订后的响应作为最终答案。
这种推理策略显著提高了AMIE在乳腺癌护理中的表现,使其在没有特定微调的情况下也能生成合理的治疗计划。通过结合外部知识和自我批判,AMIE能够更好地捕捉临床指南和最佳实践,从而提高其生成的治疗计划的准确性和安全性。
问题2:在评估AMIE系统性能时,使用了哪些具体的评估标准和临床指南?这些标准和指南如何帮助评估AMIE的有效性?
评估AMIE系统性能时使用了19个问题的详细评估标准,这些标准涵盖了以下方面:
-
病例总结的质量:评估病例总结是否全面且没有遗漏重要的临床信息。
-
治疗计划的安全性:评估治疗计划是否安全,是否会带来潜在的危害。
-
个性化治疗:评估治疗计划是否考虑了患者的个体差异,如年龄、性别、种族和地理位置。
-
诊断准确性:评估AMIE的诊断结果是否准确反映了患者的分子状态。
此外,评估还参考了国家综合癌症网络(NCCN)的管理指南,这些指南提供了乳腺癌治疗的最新标准和最佳实践。通过这些评估标准和临床指南,研究团队能够全面评估AMIE生成的治疗计划在临床上的有效性和安全性,确保其符合现有的医学标准和实践。
问题3:AMIE系统在与人类临床医生的比较中表现如何?在哪些方面表现出色,在哪些方面仍有改进空间?
AMIE系统在与人类临床医生的比较中表现出以下表现:
-
优于内科住院医师和初级肿瘤学研究员:在大多数评估标准上,AMIE的表现优于内科住院医师和初级肿瘤学研究员,特别是在病例总结、治疗计划的安全性和个性化治疗方面。
-
不及经验丰富的肿瘤学主治医师:尽管AMIE在某些方面表现出色,但在一致性上仍不及经验丰富的肿瘤学主治医师。这表明AMIE在处理复杂和多样化的临床情况时仍需进一步改进。
具体来说,AMIE在治疗初诊患者的激素治疗建议方面表现出色,符合预期的高收益。然而,在处理复杂的治疗方案和调整治疗计划以适应患者的变化时,AMIE的表现仍有待提高。未来的研究可以通过进一步定制领域特定的数据和推理策略来提高LLMs的性能,从而使其在临床实践中发挥更大的作用。
参考文献: