
收录于话题
2024年11月13日arXiv cs.CV发文量约87余篇,减论Agent通过算法为您推荐并自动化整理为卡片供您参考,预计为您节省37分钟浏览arXiv的时间。
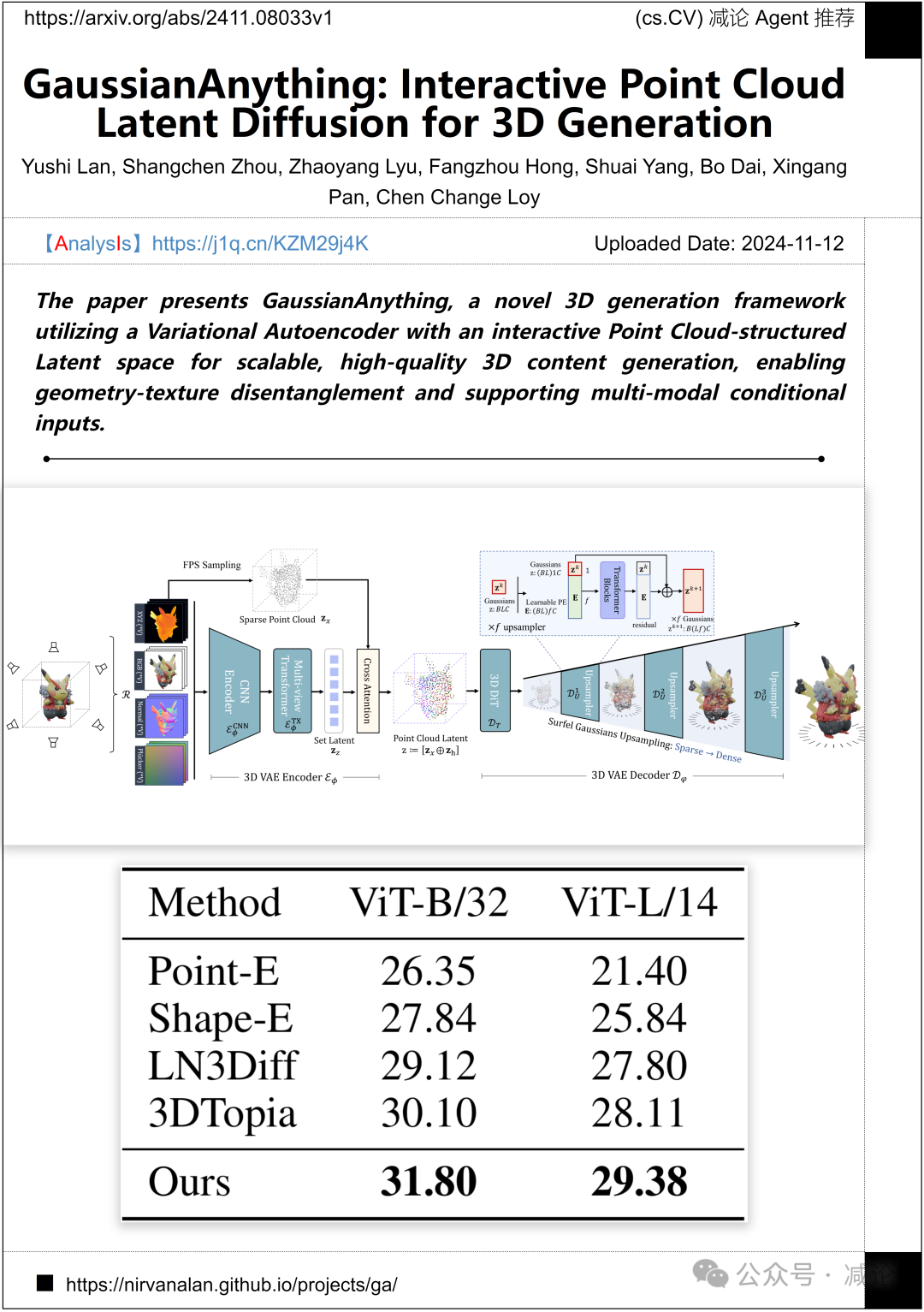

南洋理工大学、上海人工智能实验室、北京大学的研究团队提出了一种新颖的3D生成框架,名为GaussianAnything。该框架利用变分自动编码器和交互式点云结构的潜在空间,实现可扩展、高质量的3D内容生成。这一方法实现了几何纹理的解耦,并支持多模态条件输入。
【Bohr精读】
https://j1q.cn/KZM29j4K
【arXiv链接】
http://arxiv.org/abs/2411.08033v1
【代码地址】
https://nirvanalan.github.io/projects/ga/

西北工业大学的研究团队提出了一种3D聚焦匹配网络,用于多实例点云配准。该网络利用多对象聚焦模块和双掩模实例匹配模块来准确估计模型点云在混乱场景中的姿态。
【Bohr精读】
https://j1q.cn/KJUpa7in
【arXiv链接】
http://arxiv.org/abs/2411.07740v1
【代码地址】
https://github.com/zlynpu/3DFMNet

广东大学和中山大学的研究团队提出了一种新颖的图像恢复架构。该方法在U-Net框架内集成了多维动态注意力和自注意力,有效地恢复受雨、雾和噪声影响的户外图像。在多个恢复任务中实现了性能和计算效率的平衡。
【Bohr精读】
https://j1q.cn/HXmWh9yT
【arXiv链接】
http://arxiv.org/abs/2411.07893v1
【代码地址】
https://github.com/House-yuyu/MDDA-former

Autodesk 团队 提出了Wavelet Latent Diffusion(WaLa)方法,将3D形状压缩为紧凑的基于小波的潜在编码,实现了2427倍的压缩比,同时保持细节,实现了高效训练大规模生成模型的能力,快速生成高质量的3D形状。
【Bohr精读】
https://j1q.cn/VrZPkWK6
【arXiv链接】
http://arxiv.org/abs/2411.08017v1
【代码地址】
https://github.com/AutodeskAILab/WaLa

宁波大学、卡迪夫大学和南洋理工大学的研究团队提出了一种新颖的无参考点云质量评估方法(GC-PCQA)。该方法利用图卷积网络分析多视角投影图像及其空间关系,实现了准确的质量预测。
【Bohr精读】
https://j1q.cn/ozDycj2M
【arXiv链接】
http://arxiv.org/abs/2411.07728v1
【代码地址】
https://github.com/chenwuwq/GC-PCQA

中国科学院自动化研究所的研究团队提出了Rank-Augmented Linear Attention(RALA)方法,该方法通过增强Transformer模型中的线性注意力来与Softmax注意力媲美,同时保持线性计算效率。他们还通过Rank-Augmented Vision Linear Transformer(RAVLT)在各种视觉任务中展示了其有效性。
【Bohr精读】
https://j1q.cn/hwrCmjI1
【arXiv链接】
http://arxiv.org/abs/2411.07635v1
【代码地址】
https://github.com/qhfan/RALA
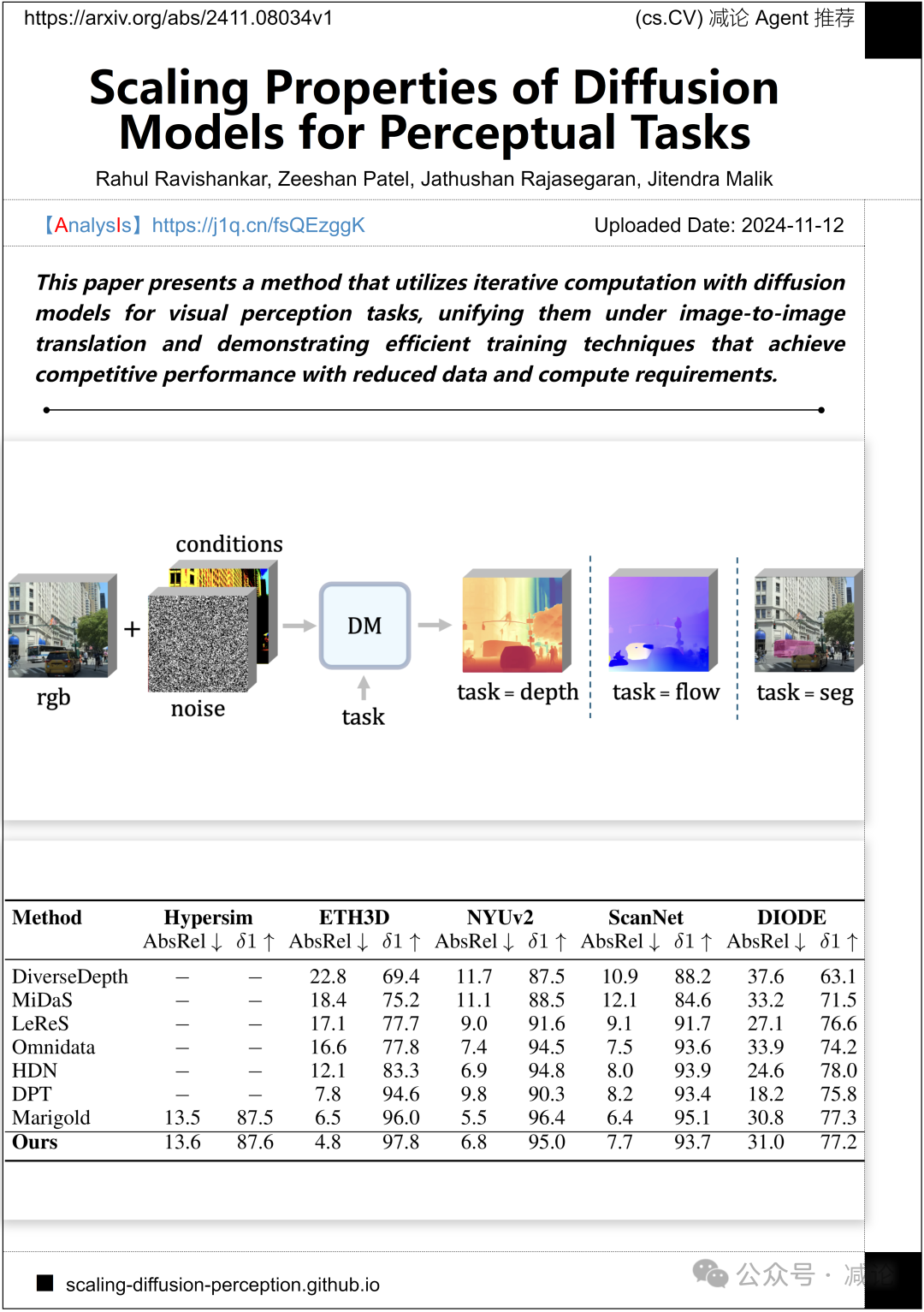
加州大学伯克利分校的研究团队提出了一种利用扩散模型进行迭代计算的方法,用于视觉感知任务,将它们统一在图像到图像的转换下,并展示了高效的训练技术,实现了在减少数据和计算需求的情况下达到竞争性表现。
【Bohr精读】
https://j1q.cn/fsQEzggK
【arXiv链接】
http://arxiv.org/abs/2411.08034v1
【代码地址】
scaling-diffusion-perception.github.io

香港科技大學、香港中文大學、北京大學深圳醫院的研究团队提出了一种层次多实例学习(HMIL)框架,通过整合层次标签相关性、类别注意机制、监督对比学习和动态加权模块,提高了对整张幻灯片图像的细粒度分类,从而改善了癌症诊断的性能。
【Bohr精读】
https://j1q.cn/fkamLR5l
【arXiv链接】
http://arxiv.org/abs/2411.07660v1
【代码地址】
https://github.com/ChengJin-git/HMIL

南京大学和南京理工大学的研究团队提出了一种名为快速解耦瘦张量学习(DSTL)的方法,用于多视角聚类。该方法直接探索多视角潜在语义表示之间的高阶相关性,同时通过解耦和基于张量的正则化来解决特征冗余问题。
【Bohr精读】
https://j1q.cn/6UecTCnx
【arXiv链接】
http://arxiv.org/abs/2411.07685v1
【代码地址】
https://github.com/dengxu-nju/DSTL
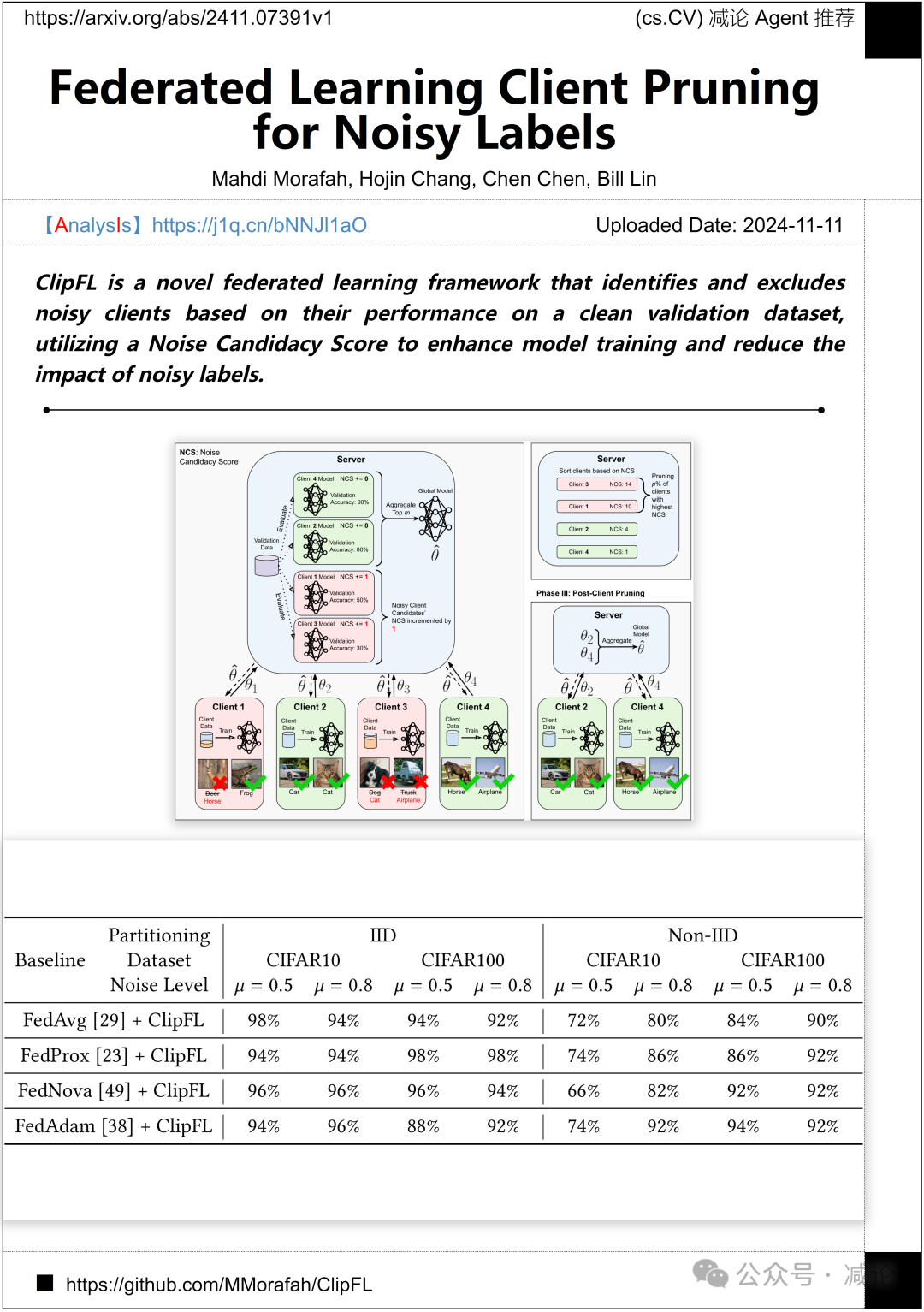
加州大学圣地亚哥分校和中佛罗里达大学的研究团队提出了一种名为ClipFL的新颖联邦学习框架。该框架根据客户在干净验证数据集上的表现来识别和排除嘈杂客户,利用噪声候选分数来增强模型训练,减少嘈杂标签的影响。
【Bohr精读】
https://j1q.cn/bNNJl1aO
【arXiv链接】
http://arxiv.org/abs/2411.07391v1
【代码地址】
https://github.com/MMorafah/ClipFL
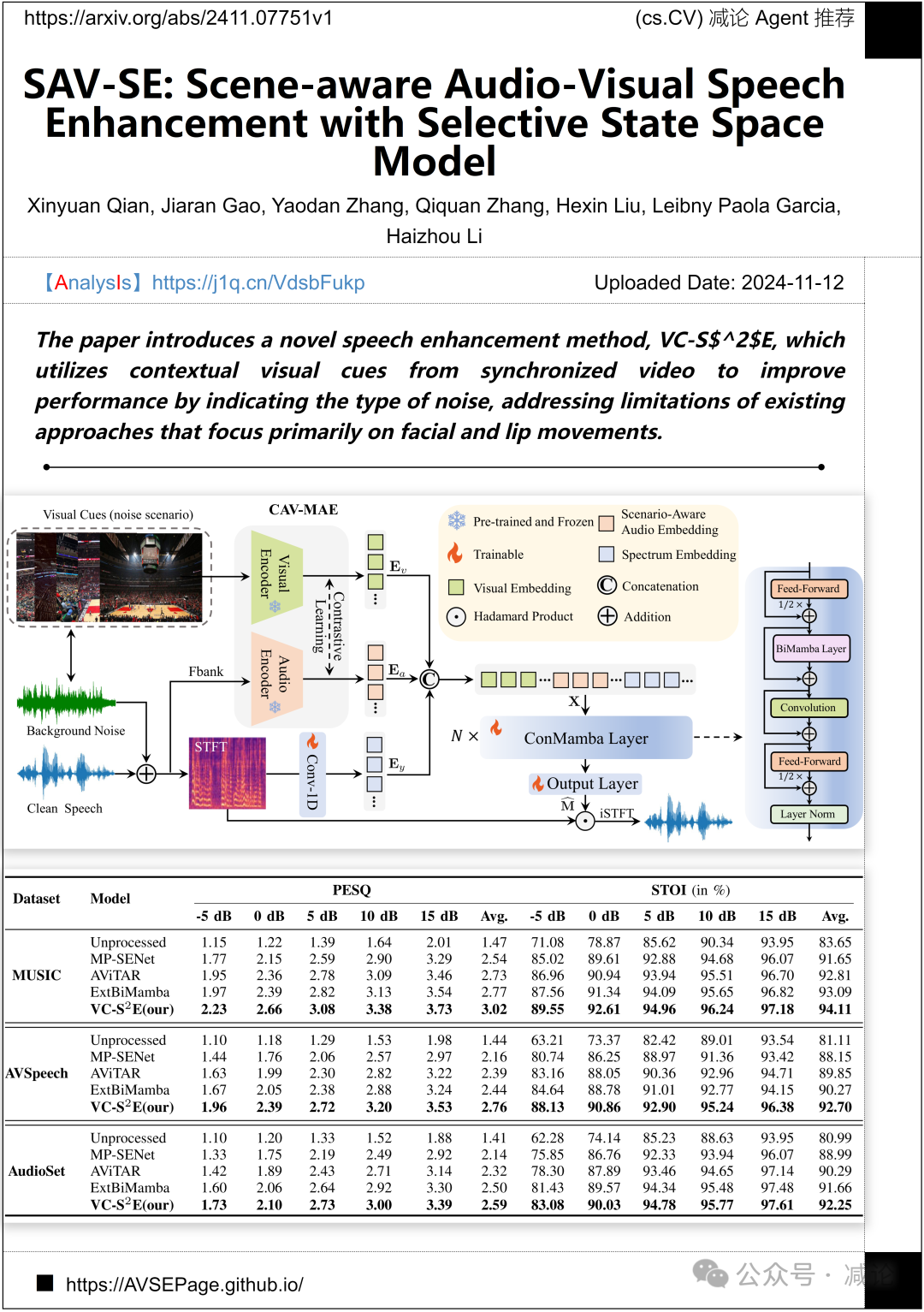
北京科技大学,新南威尔士大学,香港中文大学的研究团队提出了一种新颖的语音增强方法,VC-S2E。该方法利用来自同步视频的上下文视觉线索来改善性能,指示噪声类型,解决现有方法主要关注面部和嘴唇运动的局限性。
【Bohr精读】
https://j1q.cn/VdsbFukp
【arXiv链接】
http://arxiv.org/abs/2411.07751v1
【代码地址】
https://AVSEPage.github.io/

佐治亚理工学院和斯坦福大学的研究团队介绍了SEMI-TRUTHS,这是一个全面的数据集和评估框架,旨在评估人工智能生成的图像检测器对各种增强和扰动的稳健性。
【Bohr精读】
https://j1q.cn/FexgQSdY
【arXiv链接】
http://arxiv.org/abs/2411.07472v1
【代码地址】
https://huggingface.co/datasets/semi-truths/Semi-Truths

浙江大学软件技术学院和广东工业大学的研究团队推出了一种名为CDXFormer的高效变化检测方法。该方法利用基于XLSTM的特征增强层,整合全局上下文,提高性能,同时保持线性计算复杂度。
【Bohr精读】
https://j1q.cn/IzYdS57z
【arXiv链接】
http://arxiv.org/abs/2411.07863v1
【代码地址】
https://github.com/xwmaxwma/rschange

欢迎关注减论,持续输出有深度的人工智能极减理解,提升信息获取效率和认知维度。看完点颗小星星再走呗~