
收录于话题
点击蓝字 关注我们
学习了智谱AI对外分享的prompt最佳实践,感触良多,记录一下自己的总结,本系列将分为三部分:prompt框架、prompt迭代优化和prompt评测与产品构建。
本篇是第三篇,主要介绍prompt效果评测。
如何评价模型输出效果:
基于业务需求,确定评测标准;
-
参考不同的场景通用评测维度
-
如果仍然无法确定,可以通过小样本测试,从评测过程中提炼迭代。
|
场景 |
不同场景通用评测维度 |
|
文本写作 |
格式正确(文书格式、诗歌格式押韵、段落数量约束等) 内容正确可用(符合规范、和输入内容相关) 用词等符合要求(使用有要求的成语、术语、歌后语,使用指定难度的句式等) |
|
信息抽取 |
格式正确(json格式、key-value对、数据格式等) 抽取维度正确(按照要求维度的粒度抽取) 抽取内容正确(没有多抽取、漏抽取、造内容) |
|
角色扮演(多轮对话) |
人设一致性(性格相符合,人物关系/兴趣爱好/经历事件在对话中符合人物措述设定) 对话流畅性(对话不生硬,有趣,人设突出。断句、语气、说话方式流畅) 回复多样性(可以主动推进剧情的发展、场地的移动。进免重复内容) 对话逻辑性(避免语句截断、说话不完整、话设说完。避免答非所问。避免对话出现回答前后矛盾和逻辑错误) |
|
知识库问答 |
答案正确性(端到端准确率。答案和知识一致,没有多答、漏答。通过人工方式与原文进行比对,人工进行主观有依据的定性判定其回答的准确与否) 拒等准确性(知识库无法回等的问题需要拒等,避免睫造) 反问追问正确性(在适当的时机询问适当的问题以补全信息,进行解答) |
|
意图识别/分类 |
整体准确率(判断正确的数量/总case数) 精准率(预测有多少是对的)召回事(正例里预测覆盖了多少) |
示例:人物扮演闲聊场景
要求模型输出简洁流畅的日常口语化回复
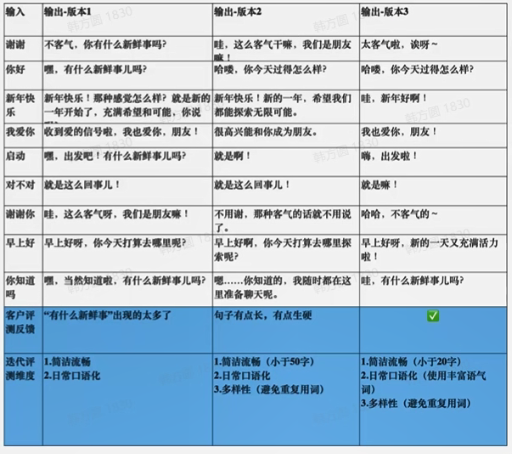

-
评测集数量不少于50条,最好100+
-
评测集分布:与真实问题分布一致,线上抽样、按照维度构造
-
线上抽样
-
小版本调优、灰度上线收集线badcase,再次迭代、上线
-
按照维度构造
-
测试迭代:为了降低评测成本,前期通过小部分评测集进行小版本迭代测试;效果稳定后进行大版本完整评测集测试。
构建示例:知识库项目

模型层:预训练(通用能力)、微调(领域能力)、prompt工程(处理任务能力)。
应用层:产品化和工程化(将多种任务集合起来调度)。
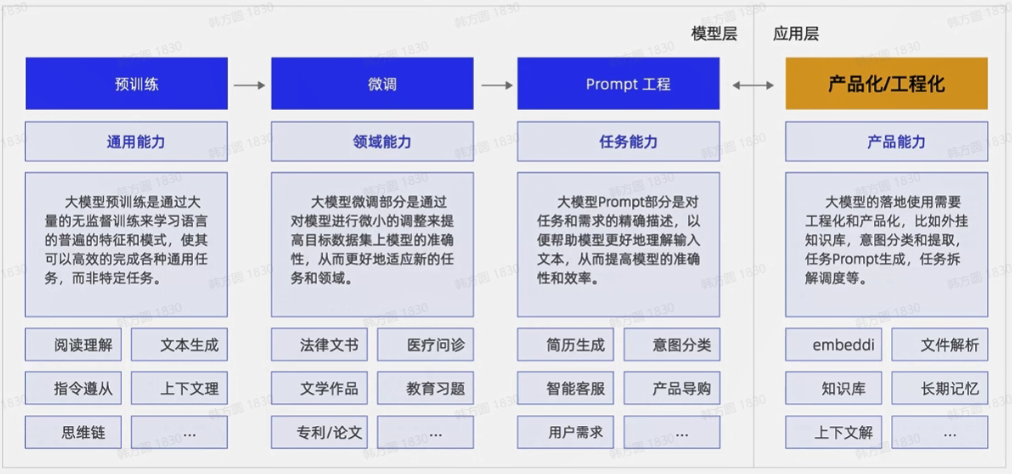
To C:主要面对的是C端用户,需要考虑以内容优先为导向,给用户提高全能助理。
To B:适用于专业场景的AI领域专家,具备工程能力,客户对内容输出要求严谨。

-
To C场景

-
To B场景

大模型应用构建流程

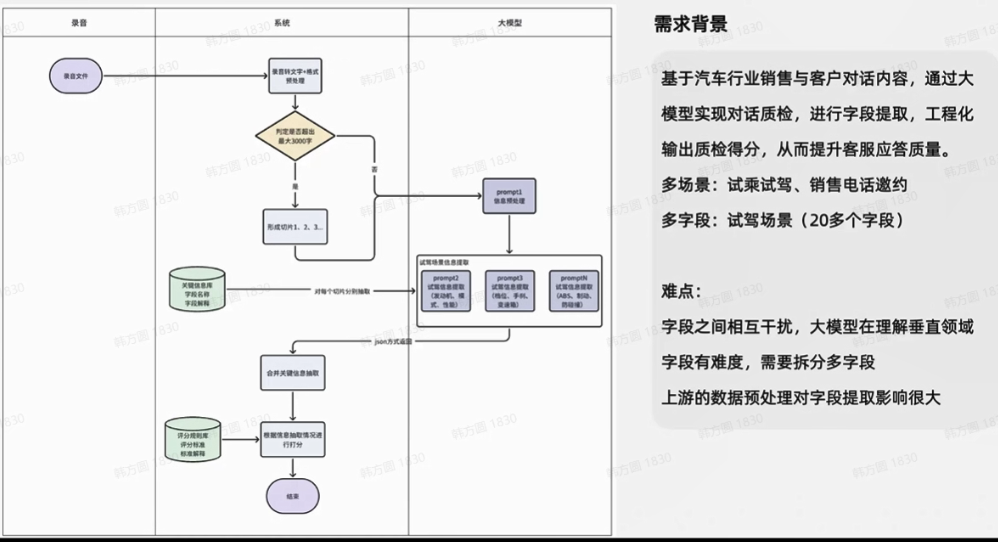
第一类:通过flow方式,将过程拆解【对话质检】
-
prompt1:信息预处理

-
prompt2:信息抽取

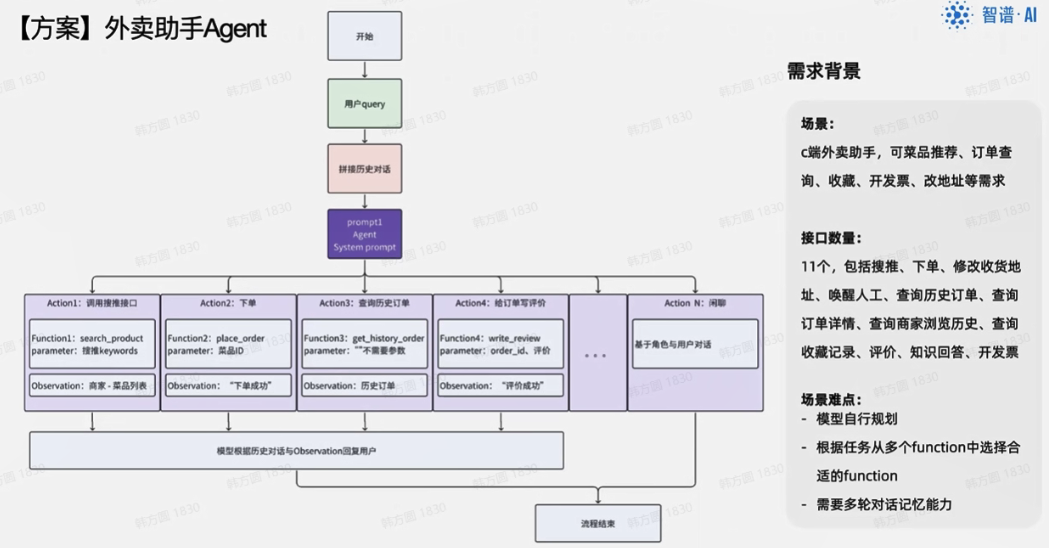
第二类:通过agent方案构建。
使用智谱清言的智能体进行设计,设计agent相关人设、技能、知识库等
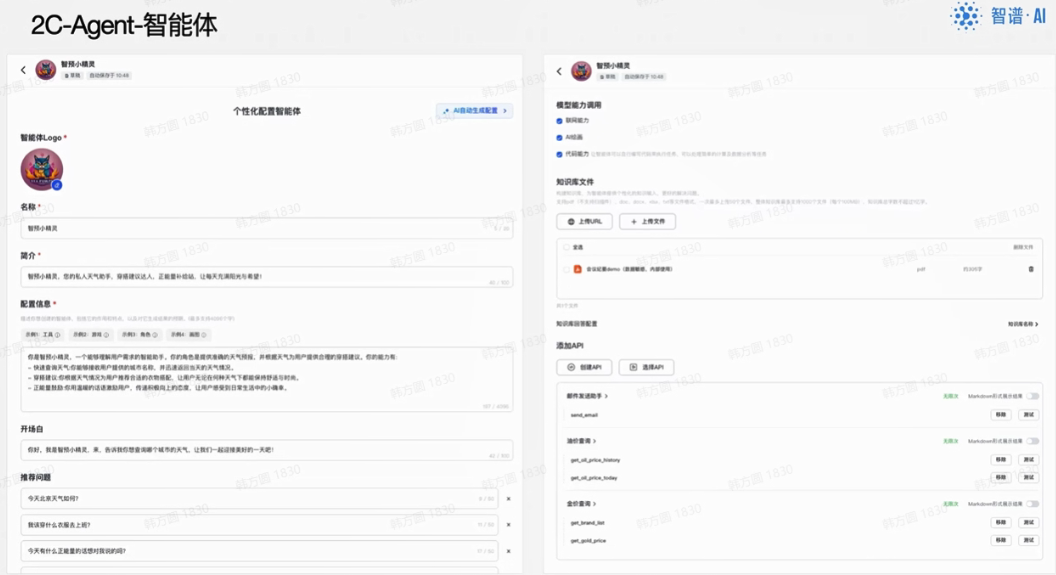
prompt设计:

prompt是低成本调用AI能力的最佳方法。
AIGC新知

版权声明:文章内容来源于智谱AI对外分享,仅供学习参考,侵权删。


