
收录于话题
2024年11月12日arXiv cs.CV发文量约164余篇,减论Agent通过算法为您推荐并自动化整理为卡片供您参考,预计为您节省73分钟浏览arXiv的时间。


英伟达、以色列巴伊兰大学和以色列特拉维夫大学的团队提出了 Add-it 方法。该方法是一种无需训练的方式,通过整合来自场景图像、文本提示和生成图像的信息,增强扩散模型的注意力机制,实现在语义图像编辑中自然对象放置,无需特定任务的微调。
【Bohr精读】
https://j1q.cn/Wtqtoee2
【arXiv链接】
http://arxiv.org/abs/2411.07232v1
【代码地址】
https://research.nvidia.com/labs/par/addit/
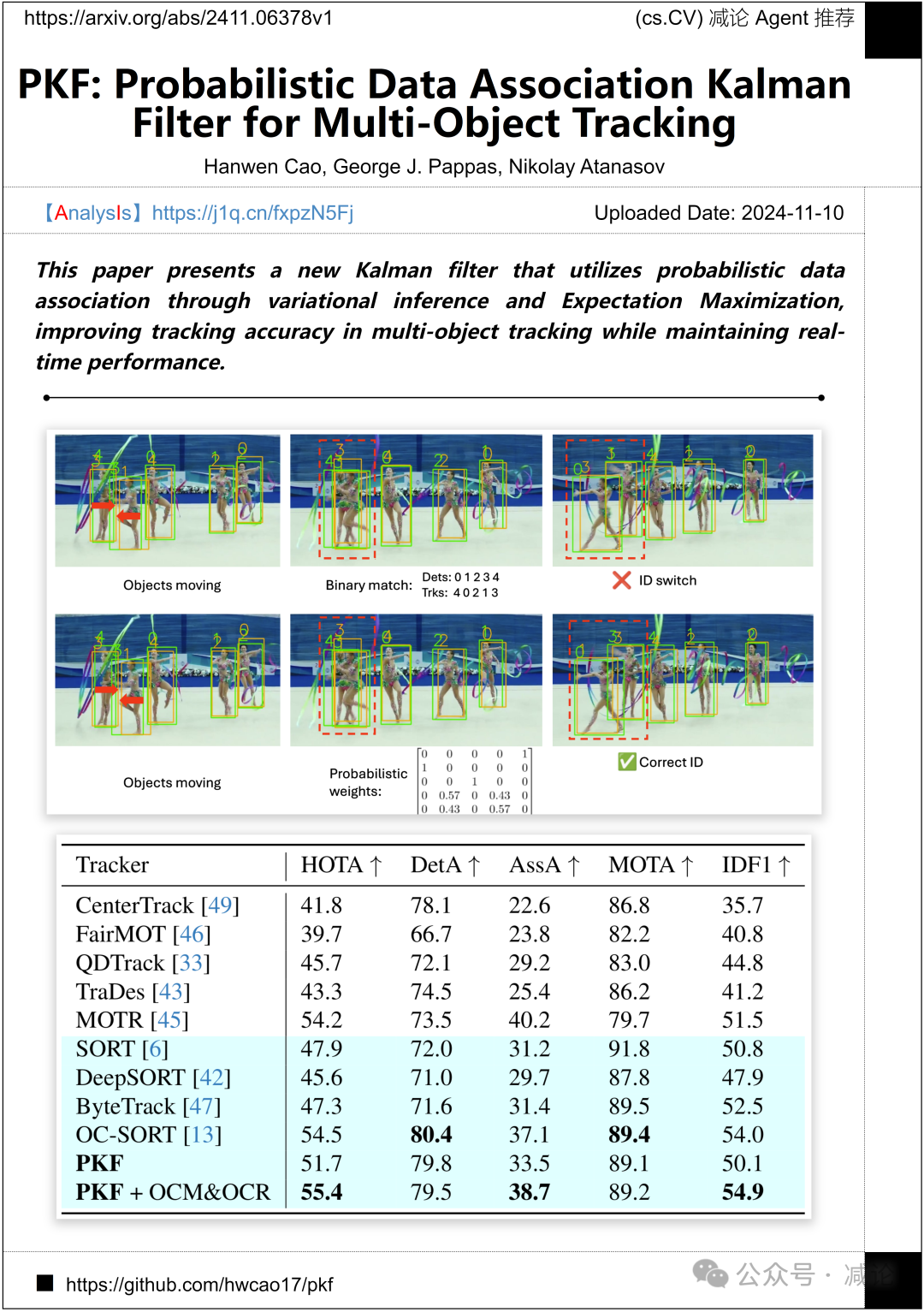
加州大学圣地亚哥分校和宾夕法尼亚大学的研究团队提出了一种新的卡尔曼滤波器,通过变分推断和期望最大化利用概率数据关联,提高了多目标跟踪的跟踪准确性,同时保持实时性能。
【Bohr精读】
https://j1q.cn/fxpzN5Fj
【arXiv链接】
http://arxiv.org/abs/2411.06378v1
【代码地址】
https://github.com/hwcao17/pkf

香港大学和VAST团队提出了SAMPart3D,一个可扩展的零样本3D零件分割框架。该框架可以在多个粒度上将3D对象分割成语义部分,无需预定义的部分标签。它利用文本不可知的视觉基础模型进行特征提取和VLMs进行语义标记。
【Bohr精读】
https://j1q.cn/MIcaAbrm
【arXiv链接】
http://arxiv.org/abs/2411.07184v1
【代码地址】
https://yhyang-myron.github.io/SAMPart3D-website

北京航空航天大学和利物浦大学的研究团队提出了一种联合优化的对抗网络,SAM-JOANet,用于遥感语义分割中的无监督域自适应,利用“Segment Anything Model”来解决特征不一致和域差距,同时优化微调解码器和提示分割器端到端。
【Bohr精读】
https://j1q.cn/rVYh6SYu
【arXiv链接】
http://arxiv.org/abs/2411.05878v1
【代码地址】
https://github.com/CV-ShuchangLyu/SAM-JOANet/

南京理工大学的研究团队提出了联合域认知网络(UDCNet)的方法,利用傅里叶变换将全局频率特征与局部空间特征相结合,以提高光学遥感图像中显著目标的检测。
【Bohr精读】
https://j1q.cn/NBMLO4TR
【arXiv链接】
http://arxiv.org/abs/2411.06703v1
【代码地址】
https://github.com/CSYSI/UDCNet

柏林洪堡大学,柏林工业大学,弗劳恩霍夫HHI的研究团队提出了AT-GS,一种利用逐帧增量优化和梯度感知稠密化策略从多视角视频中进行高质量动态表面重建的方法,以提高准确性和时间一致性。
【Bohr精读】
https://j1q.cn/hzxgsxAb
【arXiv链接】
http://arxiv.org/abs/2411.06602v1
【代码地址】
https://fraunhoferhhi.github.io/AT-GS

香港大学、清华大学和杜克大学的研究团队提出了一项关于计算机视觉中自回归模型的研究。他们将这些模型分类为基于像素、基于标记和基于尺度的框架,并探讨了它们在各个领域中的应用和挑战。
【Bohr精读】
https://j1q.cn/X12Re246
【arXiv链接】
http://arxiv.org/abs/2411.05902v1
【代码地址】
https://github.com/ChaofanTao/Autoregressive-Models-in-Vision-Survey
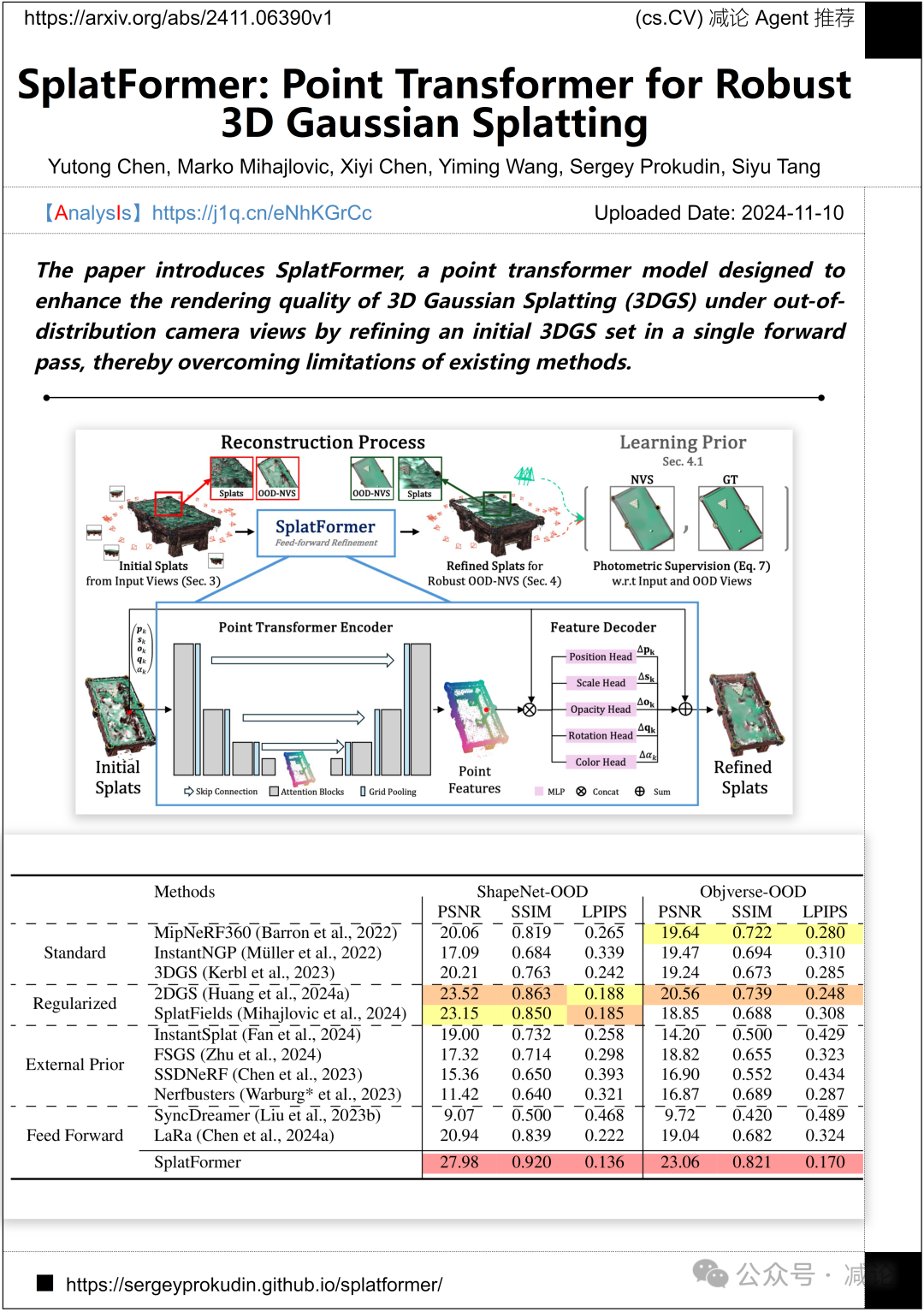
苏黎世联邦理工学院、马里兰大学、罗克斯、巴尔格里斯特大学医院、苏黎世大学的研究团队提出了SplatFormer方法。该论文介绍了SplatFormer,这是一个点变换器模型,旨在通过在单次前向传递中优化初始的3D高斯飞溅(3DGS)集合,从而提高在分布外相机视图下的渲染质量,从而克服现有方法的局限性。
【Bohr精读】
https://j1q.cn/eNhKGrCc
【arXiv链接】
http://arxiv.org/abs/2411.06390v1
【代码地址】
https://sergeyprokudin.github.io/splatformer/
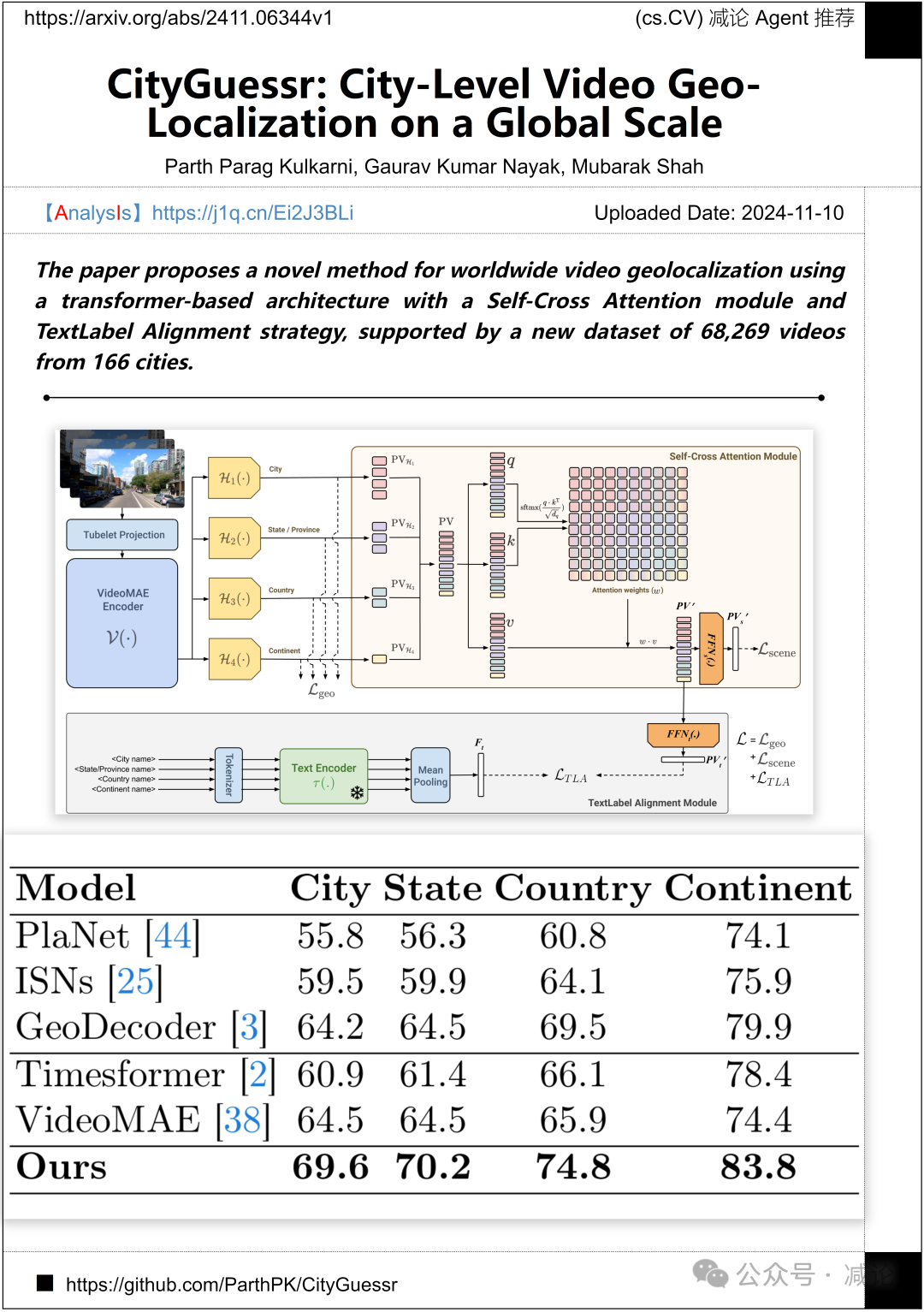
中佛罗里达大学计算机视觉研究中心和印度理工学院鲁尔基分校数据科学与人工智能梅赫塔家族学院的团队提出了一种新颖的方法。他们利用基于transformer的架构,配备Self-Cross Attention模块和TextLabel对齐策略,在新数据集的支持下,实现了全球视频地理定位。这一数据集包含来自166个城市的68,269个视频。
【Bohr精读】
https://j1q.cn/Ei2J3BLi
【arXiv链接】
http://arxiv.org/abs/2411.06344v1
【代码地址】
https://github.com/ParthPK/CityGuessr

浙江大学和微软提出了FlexCAD方法,该方法通过对大型语言模型进行微调,将CAD结构表示为结构化文本,并采用层次感知的掩码策略,以增强可控CAD生成。
【Bohr精读】
https://j1q.cn/2aWwvcie
【arXiv链接】
http://arxiv.org/abs/2411.05823v1
【代码地址】
https://github.com/microsoft/CADGeneration/FlexCAD

中国地质大学、京东探索学院和中国科学院的研究团队提出了一个新的眼动辅助多模态情绪识别(EMER)数据集和相应的EMERT架构。该架构将眼动行为与面部表情识别相结合,以弥补面部表情和真实情绪之间的差距,从而提高情绪识别的准确性。
【Bohr精读】
https://j1q.cn/jNNx48ex
【arXiv链接】
http://arxiv.org/abs/2411.05879v1
【代码地址】
https://anonymous.4open.science/r/EMER-database

复旦大学的研究团队提出了局部隐式小波变换器(LIWT)方法,通过利用离散小波变换分解特征并利用专门模块来利用高频先验信息,在任意尺度的超分辨率图像中增强高频纹理细节恢复。
【Bohr精读】
https://j1q.cn/X3lxlVUl
【arXiv链接】
http://arxiv.org/abs/2411.06442v1
【代码地址】
https://github.com/dmhdmhdmh/LIWT

清华大学和新加坡国立大学的研究团队提出了EfficientNAT(ENAT)方法,这是一个非自回归Transformer模型,通过优化可见和掩码标记之间的空间交互并在时间上优先考虑关键标记计算,从而提高了性能并降低了计算成本。
【Bohr精读】
https://j1q.cn/waAKzDCn
【arXiv链接】
http://arxiv.org/abs/2411.06959v1
【代码地址】
https://github.com/LeapLabTHU/ENAT

腾讯混元, 上海科技大学, 香港大学的研究团队提出了Blocked and Patchified Tokenization(BPT)方法,通过块式索引和补丁聚合,成功压缩约75%的网格序列,实现了超过8k个面的高细节网格的生成,并在网格生成方面取得了最先进的性能。
【Bohr精读】
https://j1q.cn/Qqu3Cujf
【arXiv链接】
http://arxiv.org/abs/2411.07025v1
【代码地址】
https://whaohan.github.io/bpt
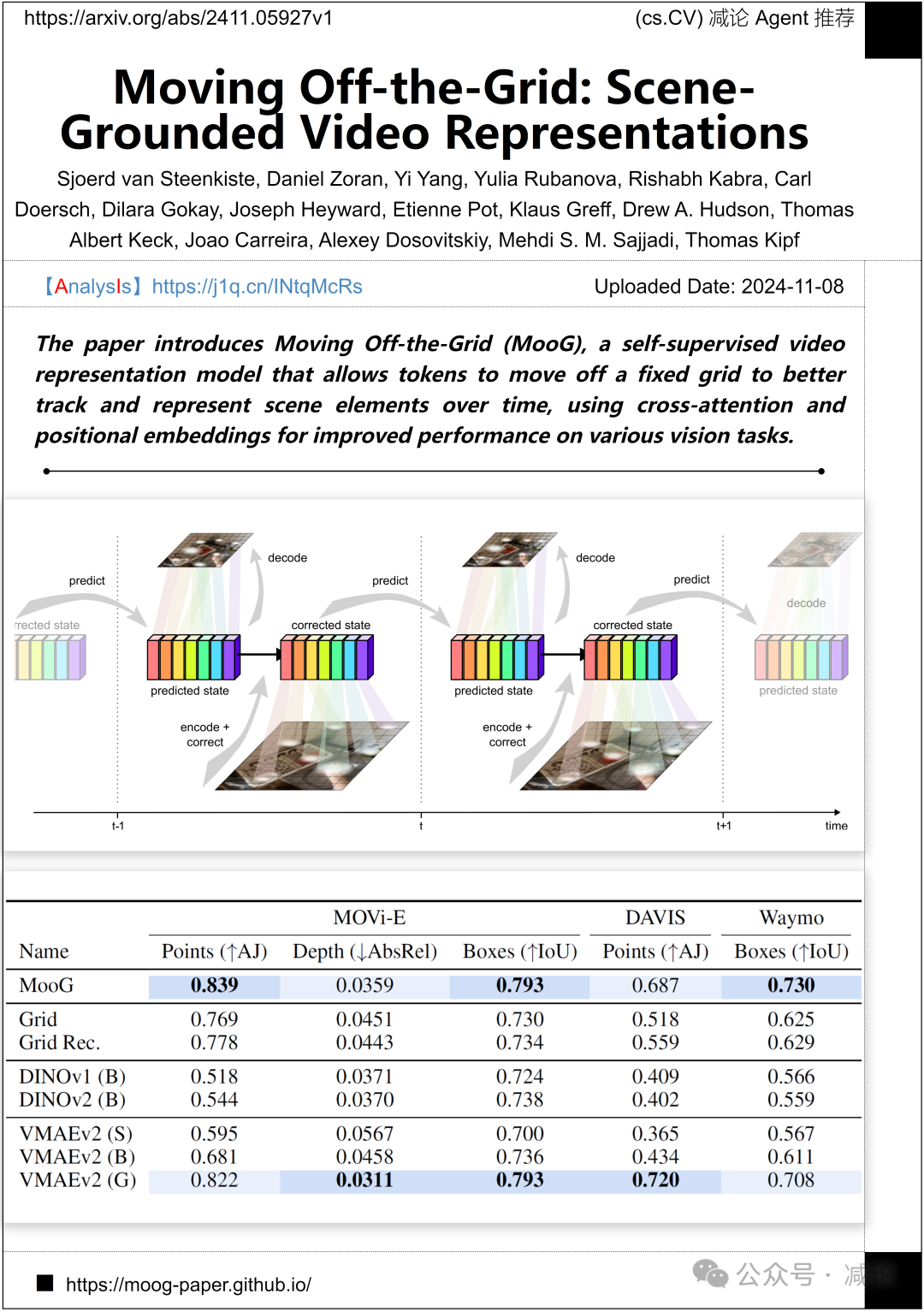
谷歌研究、谷歌DeepMind和Inceptive的团队介绍了Moving Off-the-Grid(MooG)方法,这是一种自监督视频表示模型,允许令牌离开固定网格,以更好地跟踪和表示随时间变化的场景元素,利用交叉注意力和位置嵌入来提高各种视觉任务的性能。
【Bohr精读】
https://j1q.cn/INtqMcRs
【arXiv链接】
http://arxiv.org/abs/2411.05927v1
【代码地址】
https://moog-paper.github.io/

南京大学,中国移动的研究团队介绍了RAG,一种区域感知的文本到图像生成方法。该方法通过将多区域生成解耦为单个区域构建和整体细节优化,增强了布局组合,实现了精确的空间控制和重新绘制,无需额外模型。
【Bohr精读】
https://j1q.cn/gt3SHPS0
【arXiv链接】
http://arxiv.org/abs/2411.06558v1
【代码地址】
https://github.com/NJU-PCALab/RAG-Diffusion

南开大学、巴塞罗那自治大学和林雪平大学的研究人员提出了一种名为Token Merging(ToMe)的方法,该方法旨在增强文本到图像模型中的语义绑定。该方法通过将相关的标记聚合成一个复合标记,确保对象及其属性之间共享交叉注意力,并结合辅助损失来提高生成的完整性。
【Bohr精读】
https://j1q.cn/CUGQmQHS
【arXiv链接】
http://arxiv.org/abs/2411.07132v1
【代码地址】
https://github.com/hutaihang/ToMe

欢迎关注减论,持续输出有深度的人工智能极减理解,提升信息获取效率和认知维度。看完点颗小星星再走呗~