
转自公众号:知识图谱科技
http://mp.weixin.qq.com/s?__biz=MzI3ODE5Mzc1Ng==&mid=2247492661&idx=1&sn=a0b4124eb0a54baa765c30c40eb068d8


最近世界顶级大学医学院纷纷在生成式人工智能领域进行深入的研究。
MIT和谷歌紧随其后,也发布了最新的研究成果MDAgents,一个用于医疗决策的自适应大模型多智能体。这篇文章介绍了MDAgents框架,这是一种自适应的多代理协作框架,通过动态分配协作结构来优化大型语言模型在复杂医疗决策任务中的表现。MDAgents在十个医疗基准测试中的七个中表现出色,显著提高了对医疗知识和多模态推理任务的理解和准确性。

基础模型正在成为医学领域的宝贵工具。尽管它们前景广阔,但战略性部署大型语言模型 (LLM) 以在复杂的医疗任务中有效利用仍然是一个悬而未决的问题。我们引入了一个新的框架,Medical Decision-making Agents ( MDAgents ),旨在通过为 LLM 团队自动分配协作结构来解决这一差距。分配的单独或小组协作结构是根据手头的医疗任务量身定制的,这是对现实世界医疗决策过程如何适应不同复杂性任务的简单模拟。我们在包含真实世界医学知识和具有挑战性的临床诊断的一系列医学基准中,使用最先进的 LLM 来评估我们的框架和基线方法。在需要理解医学知识和多模态推理的任务上,MDAgents 在十分之七的基准中取得了最佳性能,与之前的多智能体设置相比,显示出高达 11.8% 的显着改进 (p < 0.05)。消融研究表明,我们的 MDAgents 可以有效地确定医疗复杂性,以优化各种医疗任务的效率和准确性。我们还探讨了群体共识的动态,提供了关于协作代理在复杂的临床团队动态中如何表现的见解。
https://arxiv.org/abs/2404.15155
https://github.com/mitmedialab/MDAgents

核心速览
研究背景
-
研究问题:这篇文章要解决的问题是如何在复杂的医疗任务中有效利用大型语言模型(LLMs)。尽管LLMs在医学领域显示出潜力,但如何设计它们以适应复杂的医疗决策过程仍然是一个开放的问题。
-
研究难点:该问题的研究难点包括:医学决策过程的复杂性、多模态数据的处理、以及如何在不同复杂度的任务中动态分配LLMs的合作结构。
-
相关工作:该问题的研究相关工作包括:LLMs在医学领域的应用、多智能体协作框架、以及基于提示工程和检索增强生成的方法。
研究方法
这篇论文提出了Medical Decision-making Agents(MDAgents),用于解决LLMs在复杂医疗任务中的应用问题。具体来说,
-
医学复杂度检查:首先,系统评估医疗查询的复杂度,将其分类为低、中或高复杂度。这是通过临床决策技术来实现的。
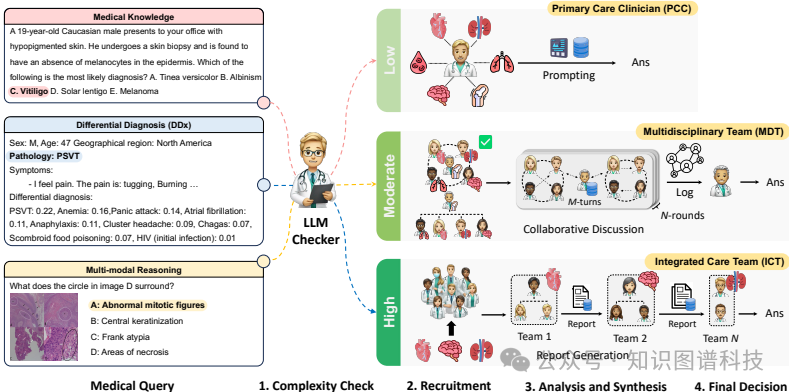
2. 专家招募:根据复杂度评估,框架激活单个初级保健临床医生(PCC)处理低复杂度问题,或多学科团队(MDT)或综合护理团队(ICT)处理中或高复杂度问题。
3. 分析与综合:对于单独的查询,使用提示技术如思维链(CoT)和自一致性(SC)。MDT涉及多个LLM代理形成共识,而ICT则为最复杂的案例综合信息。
4. 决策:最终阶段综合所有输入,为医疗查询提供明智的答案。
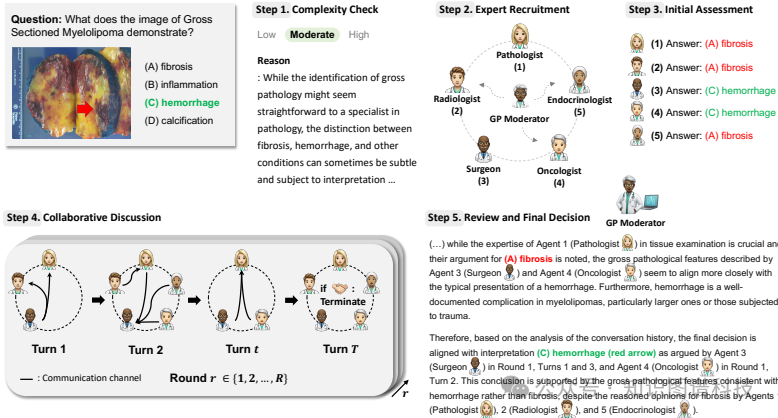 此外,MDAgents框架还包含以下关键组件:
此外,MDAgents框架还包含以下关键组件:
-
调节器代理:作为全科医生或急诊室医生,首先对医疗查询进行分类,确定其复杂度并选择适当的处理路径。
-
招募代理:根据复杂度评估招募适当的专家团队。
-
通用医生/专家代理:根据案例的复杂度,这些代理可能是独立工作还是作为团队成员。
实验设计
为了验证MDAgents框架的有效性,研究人员在十个数据集上进行了全面的实验,包括MedQA、PubMedQA、DDXPlus、SymCat、JAMA、MedBullets、Path-VQA、PMC-VQA、MIMIC-CXR和MedVidQA。每个数据集使用50个样本进行测试,推理时间分别为:低复杂度14.7秒,中复杂度95.5秒,高复杂度226秒。实验设置了三种设置:
-
单独设置:使用单个LLM代理进行决策。
-
组设置:实施多智能体协作进行决策。
-
自适应设置:提出的MDAgents方法自适应地构建从PCP到MDT和ICT的推理结构。
结果与分析
-
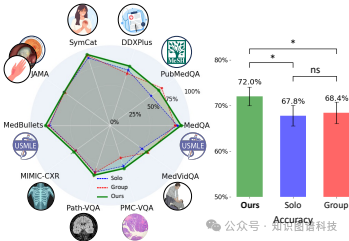
准确率比较:在十个医疗基准测试中,MDAgents在七个基准上表现优于之前的单独和组方法,显示出显著的改进,最高提高了4.2%(p<0.05)。
-
消融研究:消融研究表明,MDAgents有效地确定了医学复杂度以优化效率和准确性。特别是,调节器审查和外部医学知识在组协作中的结合平均准确率提高了11.8%。
-
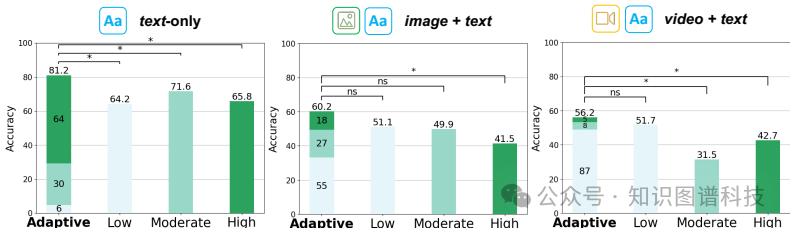
多模态数据处理:MDAgents不仅在文本数据上表现出高精度,还能有效地综合视觉数据,这在医学诊断评估中至关重要。
-
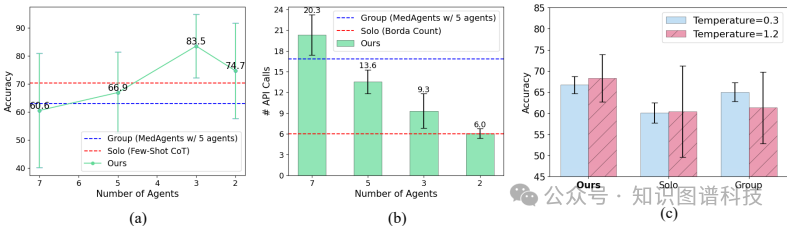
智能体数量的影响:实验表明,更多的智能体并不总是导致更好的性能。MDAgents通过智能校准协作智能体的数量实现了最佳性能,减少了API调用次数。
总体结论
这篇论文介绍了MDAgents,一种增强LLMs在复杂医疗决策中应用的框架。通过动态构建有效的协作模型,MDAgents反映了临床设置中的细致咨询方面。实验结果表明,MDAgents在七个医疗基准上优于之前的单独和组方法,展示了其在多模态推理和协作过程中的强大能力。未来的研究方向包括整合专门的医学基础模型、实现以患者为中心的诊断,以及解决潜在的风险和偏见。
论文评价
优点与创新
-
引入MDAgents框架:首次提出了一个自适应决策框架,通过动态协作的AI代理来模拟现实世界中的医疗决策过程。
-
显著性能提升:在10个医疗基准测试中,MDAgents在7个基准上取得了最佳性能,相比之前的单方法和组方法有显著提升,最高提升了4.2%。
-
复杂度分类优化:通过消融研究展示了MDAgents在确定医疗复杂度以优化效率和准确性方面的有效性。
-
多模态推理能力:在文本和图像数据集上的表现优于单方法和组方法,特别是在需要多模态推理的任务中表现突出。
-
协作策略动态分配:根据查询的复杂度动态分配协作策略,提高了决策的灵活性和效率。
-
多种交互方式:支持多种交互方式,包括链式思维提示(CoT)和自我一致性(SC),增强了模型的推理能力。
-
实验结果可复现:提供了详细的实验设置和方法,确保了实验结果的可复现性。
不足与反思
-
医疗领域基础模型的限制:未来工作将考虑整合专门训练的医疗数据基础模型,如MedGemini、AMIE和Med-PaLM 2,以增强系统的整体性能和可靠性。
-
患者中心诊断的局限:当前框架主要支持选择题回答,未能充分考虑现实世界中诊断的患者中心特性。未来版本将致力于构建一个更互动的系统,直接与患者和护理人员进行多方参与的多利益相关者诊断。
-
潜在风险:尽管框架显示出潜力,但存在医疗幻觉和生成不准确或误导性信息的风险。未来工作将集成自我纠正机制,如基于强化学习的自我纠正,以及规则基础的奖励结构,以确保模型在训练过程中遵循特定的安全和准确性指南。
关键问题及回答
问题1:MDAgents框架在处理不同复杂度的医疗查询时,具体是如何操作的?
-
低复杂度查询:对于简单、明确的医学问题,如常见急性病或稳定慢性病,系统会部署一个初级保健临床医生(PCP)代理,使用少量示例进行提示。答案直接从代理的回答中获得。
-
中等复杂度查询:对于涉及多个相互作用的医学问题,系统会组建一个多学科团队(MDT),通过迭代讨论达成共识。每轮讨论中,代理们交流意见,直到达到共识或决定继续下一轮。
-
高复杂度查询:对于需要广泛协调和跨学科专家知识的复杂病例,系统会组建一个综合护理团队(ICT),通过分阶段的报告和最终审查做出决策。每个团队生成一份综合报告,最终决策者综合所有报告并给出最终答案。
问题2:在实验中,MDAgents框架在不同设置下的表现如何?与其他方法相比有何优势?
-
单独设置:使用单个LLM代理进行决策。实验结果显示,MDAgents在七个医疗基准上表现优于之前的单独方法,显示出显著的改进,最高提高了4.2%(p<0.05)。
-
组设置:实施多智能体协作进行决策。与单独方法相比,MDAgents在某些复杂任务上表现更好,特别是在多模态数据集(如Path-VQA、PMC-VQA和MIMIC-CXR)上,MDAgents的平均准确率为56.2%,显著高于单独方法的50.8%。
-
自适应设置:提出的MDAgents方法自适应地构建从PCP到MDT和ICT的推理结构。通过智能校准协作智能体的数量,MDAgents实现了最佳性能,减少了API调用次数,同时保持了高精度。

总体而言,MDAgents框架通过动态构建有效的协作模型,反映了临床设置中的细致咨询方面,显著提高了在复杂医疗决策任务中的表现。
问题3:MDAgents框架在多模态数据处理方面有哪些优势?如何进行智能体数量的调整?
-
多模态数据处理:MDAgents不仅在文本数据上表现出高精度,还能有效地综合视觉数据,这在医学诊断评估中至关重要。例如,在PMC-VQA数据集上,MDAgents的平均准确率为56.4%,显著高于其他方法的48.2%。
-
智能体数量的调整:实验表明,更多的智能体并不总是导致更好的性能。MDAgents通过智能校准协作智能体的数量实现了最佳性能。具体来说,MDAgents在低复杂度任务中使用3个智能体,中复杂度任务中使用5个智能体,高复杂度任务中使用7个智能体。这种策略不仅减少了API调用次数,还提高了决策的效率和准确性。

参考文献:
-
喜讯|柯基数据中标两个“大模型+医学”国自然面上项目 -
医疗保健和医学领域的大模型综述 – 斯坦福&加州大学 -
医学GraphRAG:通过知识图谱检索增强实现安全医疗大语言模型 – 牛津大学最新论文 -
消除幻觉的知识图谱增强医学大模型 – “Nature”NPJ数字医学杂志 -
Almanac: 一种用于临床医学的检索增强RAG大语言模型(2023vs2024版)