
收录于话题
2024年11月11日arXiv cs.CV发文量约69余篇,减论Agent通过算法为您推荐并自动化整理为卡片供您参考,预计为您节省30分钟浏览arXiv的时间。
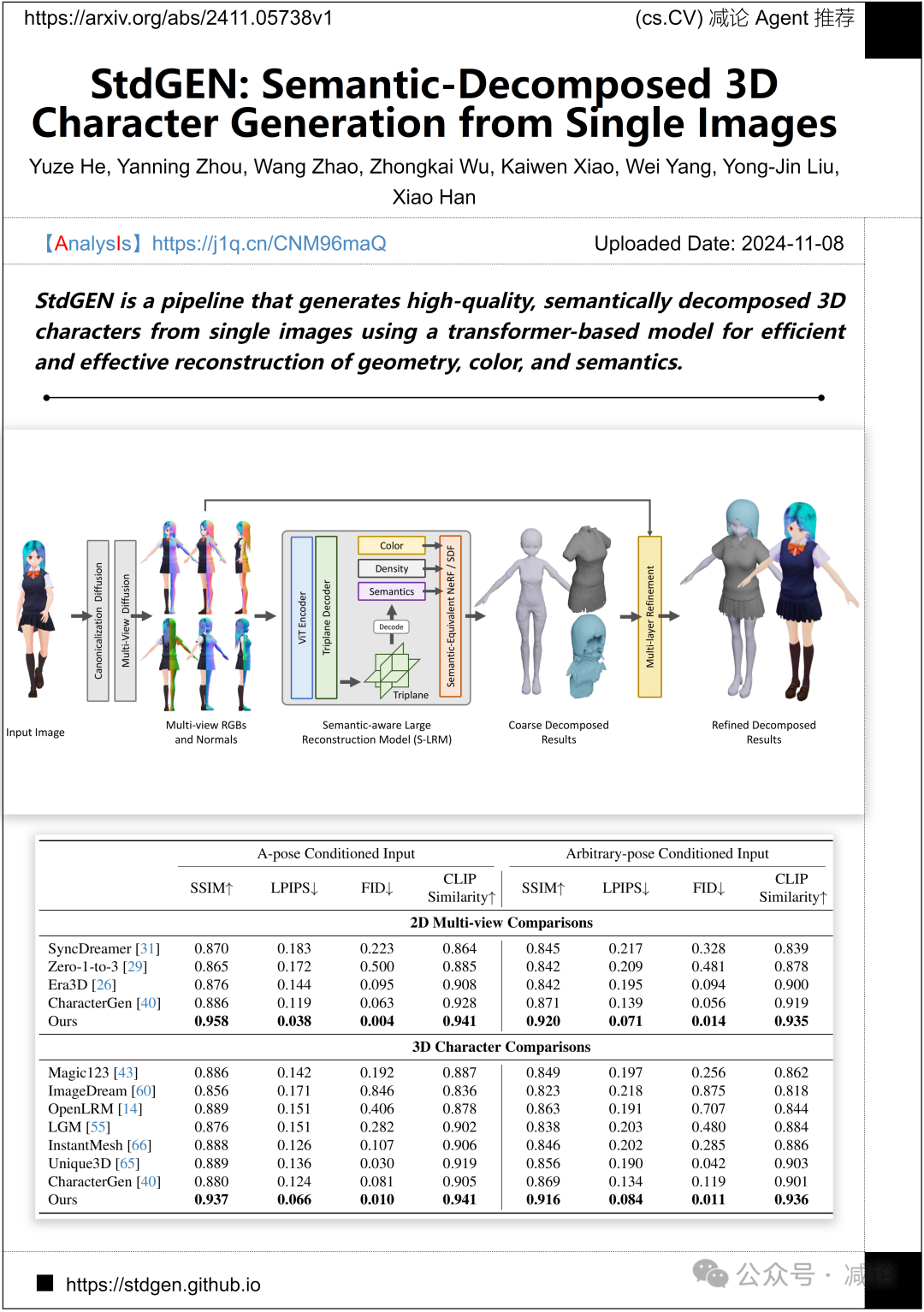

腾讯 AI Lab, 清华大学, 北航提出了StdGEN方法,该方法是一个管道,使用基于transformer的模型从单个图像生成高质量、语义分解的3D角色,以实现几何、颜色和语义的高效重建。
【Bohr精读】
https://j1q.cn/CNM96maQ
【arXiv链接】
http://arxiv.org/abs/2411.05738v1
【代码地址】
https://stdgen.github.io
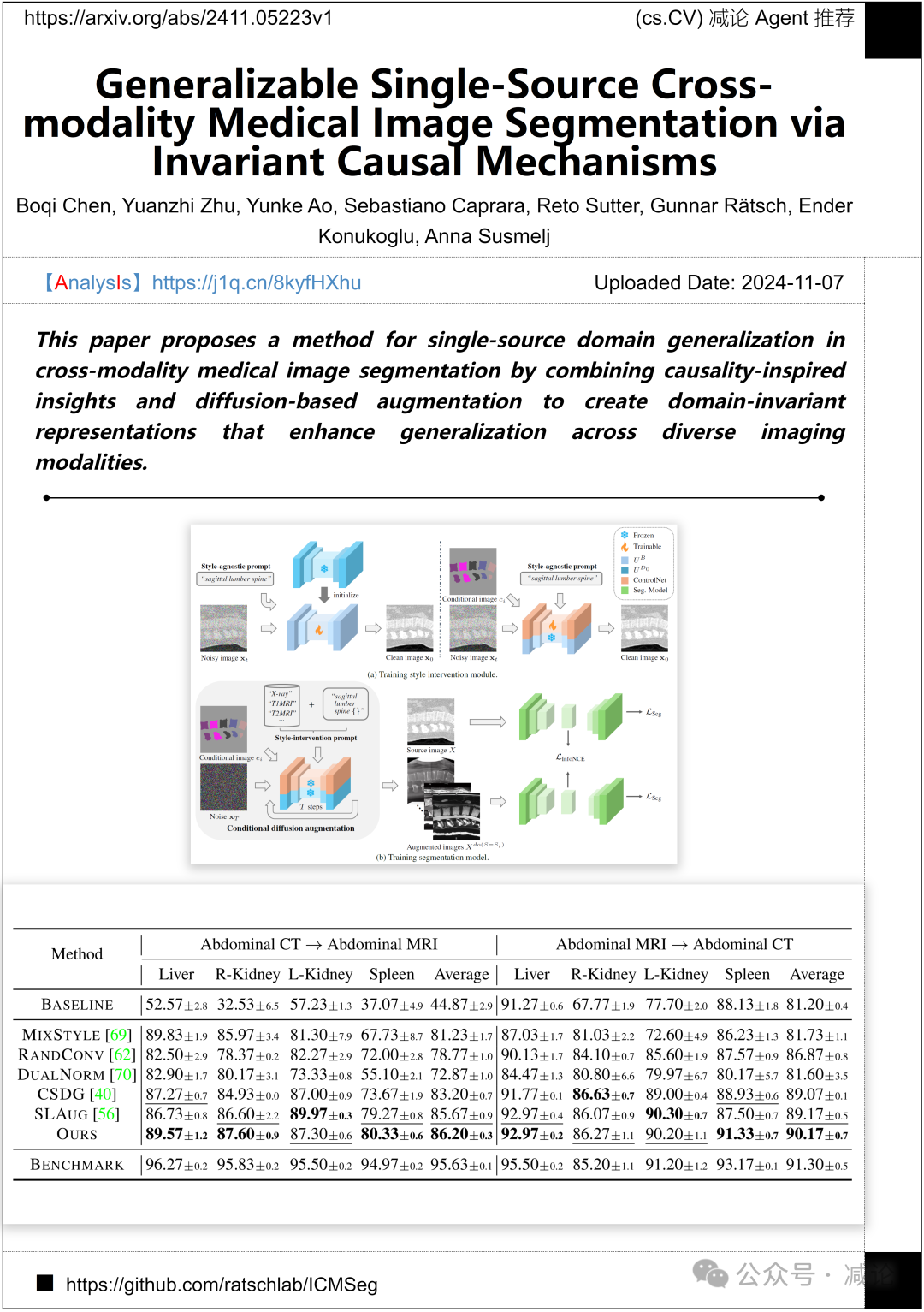
苏黎世联邦理工学院和苏黎世大学的研究团队提出了一种方法,通过结合启发自因果关系的见解和基于扩散的增强,实现跨模态医学图像分割中的单源域泛化,从而创建增强泛化能力的域不变表示,跨越多样化成像模态。
【Bohr精读】
https://j1q.cn/8kyfHXhu
【arXiv链接】
http://arxiv.org/abs/2411.05223v1
【代码地址】
https://github.com/ratschlab/ICMSeg

得克萨斯大学奥斯汀分校,AMD团队介绍了Online-LoRA,这是一个用于无任务在线持续学习的框架,通过在线权重正则化策略实时微调预训练的Vision Transformer模型,以减轻灾难性遗忘并适应数据分布的变化。
【Bohr精读】
https://j1q.cn/HFrTUYPk
【arXiv链接】
http://arxiv.org/abs/2411.05663v1
【代码地址】
https://github.com/Christina200/Online-LoRA-official.git

香港中文大学,上海人工智能实验室的研究团队提出了一种新颖的多模态零样本离线全景感知(ZOPP)框架。该框架利用视觉基础模型和3D点云表示,能够自动生成高质量的自动驾驶场景的3D标签,解决了现有方法在人类级别识别和数据不平衡方面的局限性。
【Bohr精读】
https://j1q.cn/RGZcor4i
【arXiv链接】
http://arxiv.org/abs/2411.05311v1
【代码地址】
https://github.com/PJLab-ADG/ZOPP
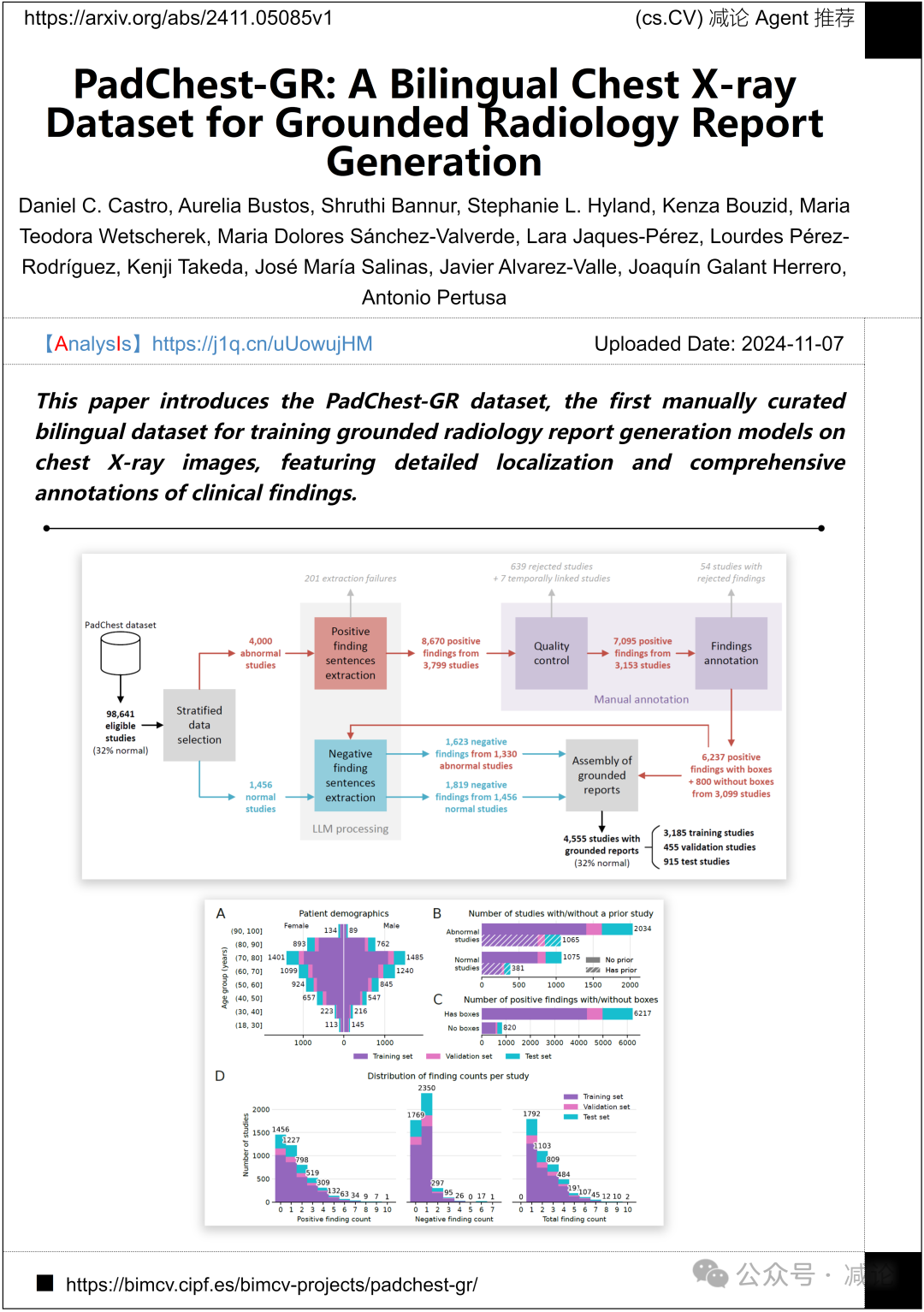
微软研究院、Medbravo、阿利坎特大学计算研究所和阿利坎特大学的研究人员提出了PadChest-GR数据集,这是第一个为训练基于胸部X光图像的放射学报告生成模型而手动策划的双语数据集,具有详细的定位和临床发现的全面注释。
【Bohr精读】
https://j1q.cn/uUowujHM
【arXiv链接】
http://arxiv.org/abs/2411.05085v1
【代码地址】
https://bimcv.cipf.es/bimcv-projects/padchest-gr/

加州大学伯克利分校和宾夕法尼亚大学的研究团队提出了VLMnav,一个端到端的导航框架。该框架利用视觉语言模型直接选择动作,无需微调或先前的导航数据,实现在各种导航任务中的通用性能。
【Bohr精读】
https://j1q.cn/oEr25kYW
【arXiv链接】
http://arxiv.org/abs/2411.05755v1
【代码地址】
jirl-upenn.github.io/VLMnav/
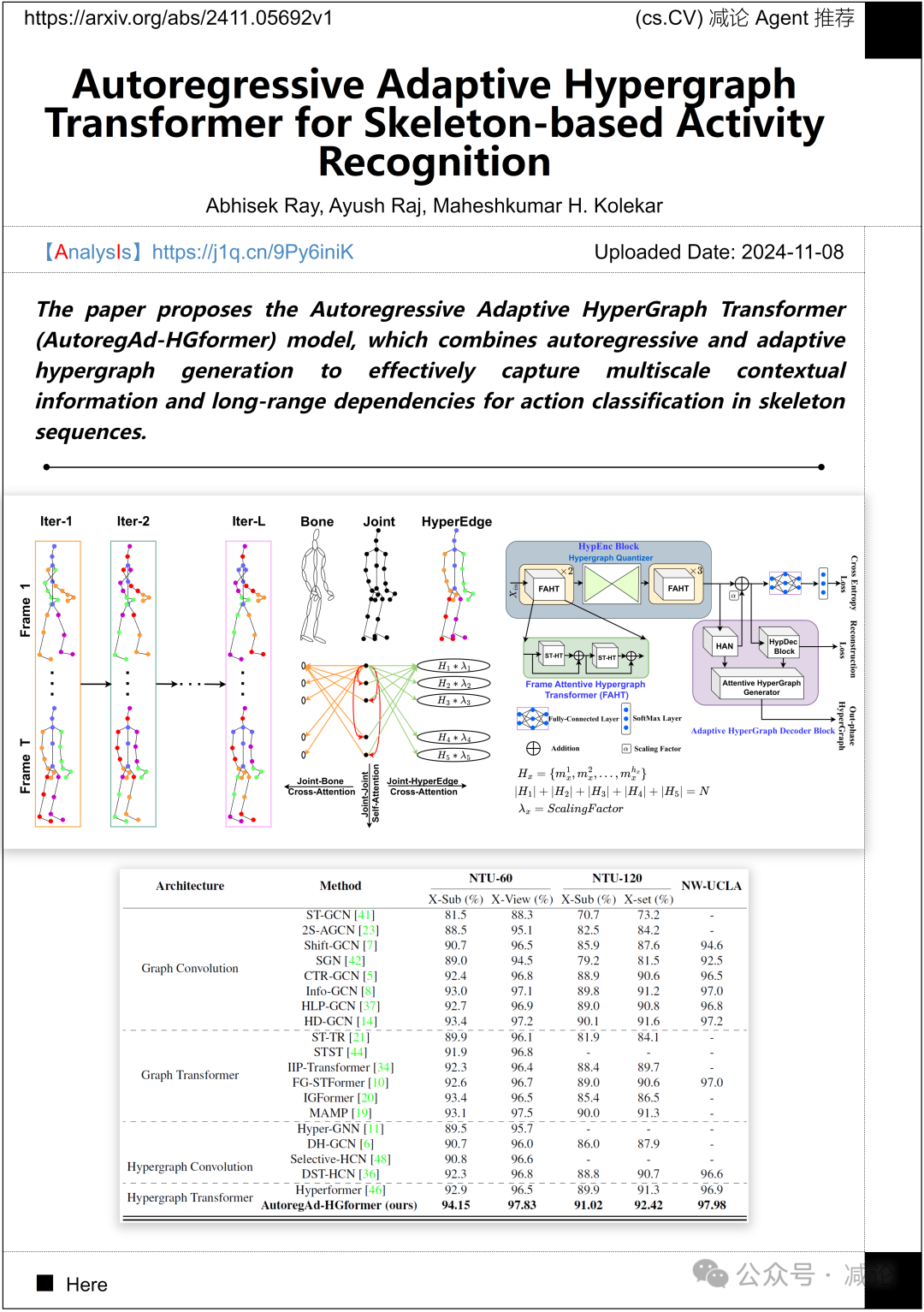
印度理工学院帕特纳提出了自回归自适应超图变换器(AutoregAd-HGformer)模型,结合自回归和自适应超图生成,以有效捕获骨架序列中的多尺度上下文信息和长距离依赖关系,用于动作分类。
【Bohr精读】
https://j1q.cn/9Py6iniK
【arXiv链接】
http://arxiv.org/abs/2411.05692v1
【代码地址】
https://github.com/rayabhisek123/AutoregAd-HGformer

贝拉内尔大学、里斯本新星计算机科学研究中心、波尔图大学工程学院、TEC研究所的团队提出了一种两步方法,利用预训练的视觉语言模型自动预测临床概念,并利用大型语言模型生成疾病诊断,解决了深度学习临床系统中数据稀缺和可解释性挑战,而无需进行大量重新训练或大量注释数据集。
【Bohr精读】
https://j1q.cn/qZZnINiW
【arXiv链接】
http://arxiv.org/abs/2411.05609v1
【代码地址】
https://github.com/CristianoPatricio/2-step-concept-based-skin-diagnosis
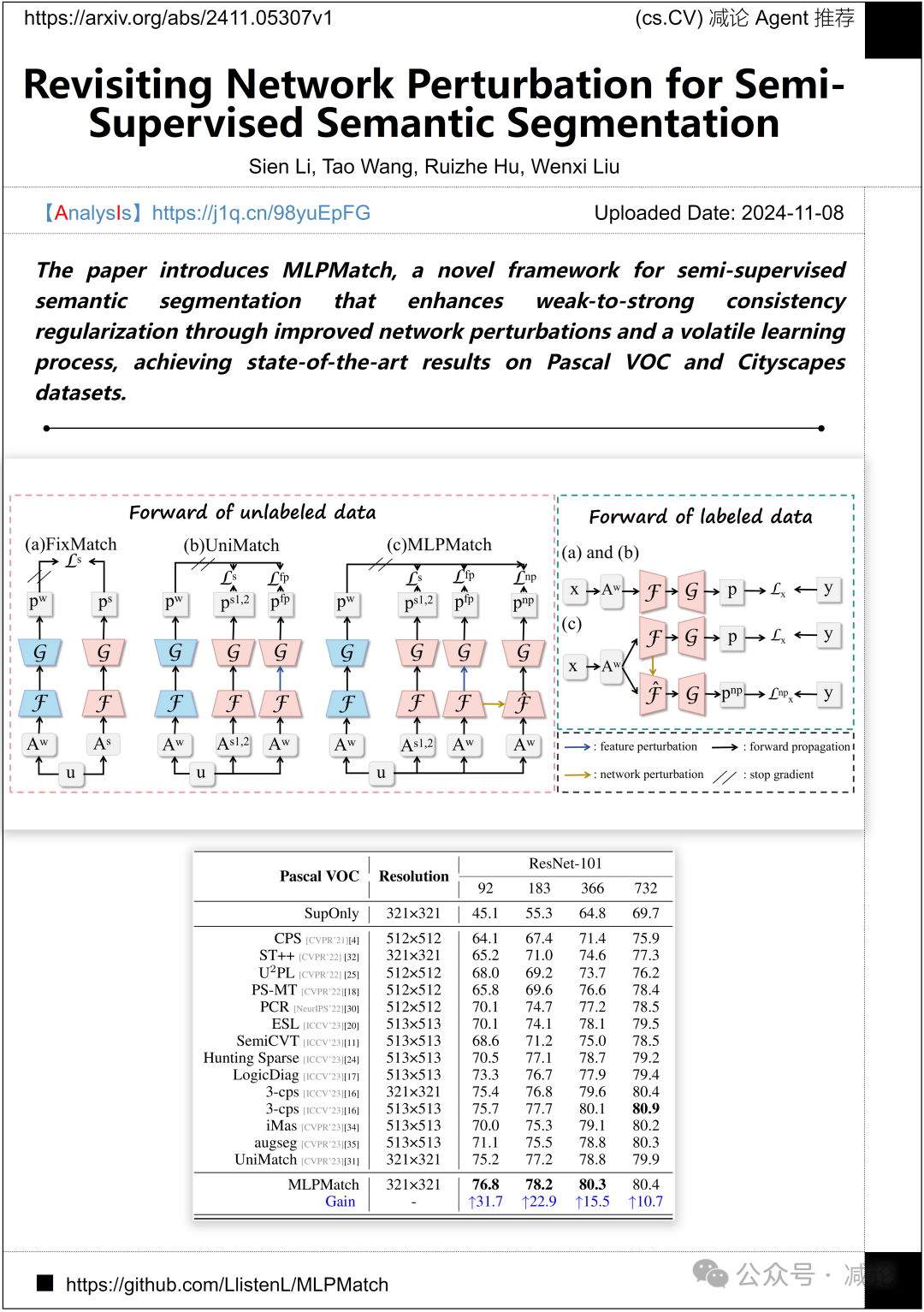
福州大学的研究团队提出了MLPMatch框架,用于半监督语义分割。该框架通过改进的网络扰动和不稳定的学习过程增强了弱到强的一致性正则化,在Pascal VOC和Cityscapes数据集上取得了SOTA结果。
【Bohr精读】
https://j1q.cn/98yuEpFG
【arXiv链接】
http://arxiv.org/abs/2411.05307v1
【代码地址】
https://github.com/LlistenL/MLPMatch

欢迎关注减论,持续输出有深度的人工智能极减理解,提升信息获取效率和认知维度。看完点颗小星星再走呗~