


前言:
护理生成式人工智能相比诊疗方向更容易落地,最近也成为医学大模型的研究热点方向之一。
由中国卫生信息与健康医疗大数据学会护理学分会主办的2024年护理信息大会将于11月15日-17日在厦门举办。2024CHMIA中国护理信息大会&NursGPT启动仪式
11.16上午,首都医学科学创新中心“居家老人慢病护理大模型NursGPT”重点项目将在开幕式启动,并在大会专场论坛“科技前瞻:生成式AI推动护理专业变革”研讨前沿的人工智能大模型技术如何变革医护产学研新范式。
精彩纷呈的护理信息大会,前沿科技解密,行业专家分享,共同启迪智慧护理的新未来!欢迎医院、科研院所、企业报名参会参展。
核心速览
研究背景
-
研究问题:这篇文章研究了使用大型语言模型(LLMs)在患者向医疗保健提供者发送消息时,引导患者创建高效且全面的临床护理信息的可行性。目标是确保医疗保健提供者能够一次性收到所有必要的信息,准确安全地回答患者的问题,从而消除来回通信、延迟和挫败感。
-
研究难点:该问题的研究难点包括:患者初始消息有时缺乏准确的上下文细节,导致医务人员需要多次沟通以收集必要信息;患者门户中患者与医疗保健提供者之间的来回通信频繁,增加了医务人员的工作负担,并可能导致患者无法及时进行下一步治疗。
-
相关工作:之前的研究表明,LLMs在起草临床回复方面具有潜力,例如ChatGPT生成的回复在质量和同理心上评分较高。然而,关于LLMs生成后续问题以帮助患者创建高效全面的初始消息的研究尚未得到充分理解。

研究方法
这篇论文提出了使用LLMs生成后续问题,以帮助患者在其撰写消息时提供更多信息,从而使医务人员能够一次性回答患者的问题。具体来说,
-
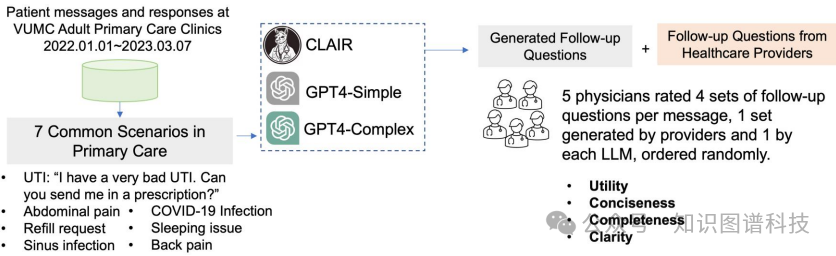
数据收集:研究收集了2022年1月1日至2023年3月7日期间,通过Vanderbilt大学医疗中心的患者门户My Health发送的患者消息数据。
-
场景识别:通过与内科医生进行访谈,识别了7个常见的患者消息场景。
-
模型生成:使用三种LLMs生成后续问题:
-
综合LLM人工智能响应器(CLAIR):在VUMC的患者-提供者消息数据上微调的LLM。
-
GPT4(简单提示):使用简单提示的GPT4模型。
-
GPT4(复杂提示):使用复杂提示的GPT4模型,专注于澄清患者症状并检查患者病情的最近变化。
-
评估标准:邀请五位医生评估生成的后续问题,使用5点Likert量表对以下指标进行评分:
-
清晰度:后续问题是否易于理解和回答。
-
完整性:后续问题是否包含了回答问题所需的所有重要信息。
-
简练性:后续问题是否简洁。
-
实用性:后续问题对医务人员回答患者问题是否有用。
实验设计
-
数据收集:从2022年1月1日至2023年3月7日期间,收集了通过Vanderbilt大学医疗中心的患者门户My Health发送的患者消息数据。
-
场景选择:通过与内科医生进行访谈,识别了7个常见的患者消息场景。
-
模型生成:使用三种LLMs生成后续问题:CLAIR、GPT4(简单提示)和GPT4(复杂提示)。
-
评估:邀请五位医生评估生成的后续问题,使用5点Likert量表对清晰度、完整性、简练性和实用性进行评分。
结果与分析
-
评分结果:五位医生的平均实践年限为12.8年,ICC值为0.76,表明评分者之间具有高度一致性。
2. 最佳评分:在七个场景中,GPT4-complex生成了两组最佳后续问题,其余五个最佳后续问题来自CLAIR模型。
3.评分分布:在清晰度、完整性、简练性和实用性方面,医疗提供者生成的后续问题得分最高,CLAIR模型次之,GPT4-simple和GPT4-complex模型得分较低。
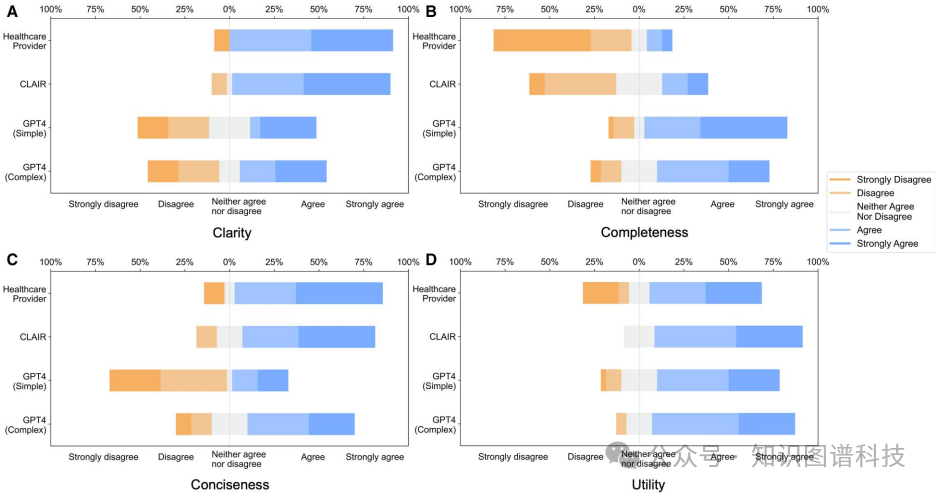
4.具体评分:CLAIR模型在实用性和清晰度方面得分较高,但在完整性方面得分较低;GPT4-complex在完整性和简练性方面得分较高,但在清晰度方面得分较低。
总体结论
这项研究表明,LLMs可以生成有助于澄清医学问题的后续问题,其效果与医疗保健提供者生成的后续问题相当。这种方法有望提高患者与医疗保健提供者之间的通信效率,减少来回通信的延迟和挫败感。未来的研究可以考虑患者的反馈,进一步优化LLMs生成的后续问题,并探索其在异步虚拟就诊、远程医疗或面对面就诊中的应用潜力。
论文评价
优点与创新
-
创新的应用场景:该研究探讨了使用大型语言模型(LLMs)在患者撰写消息给医疗提供者时生成跟进问题的可行性,旨在帮助医疗提供者首次回答患者的问题,减少来回的信息交换。
-
多种模型的对比:研究比较了三种不同的LLMs模型(CLAIR、GPT4-simple、GPT4-complex)与医疗提供者生成的实际跟进问题的表现。
-
详细的评估:使用五位医生对生成的跟进问题进行评分,评估标准包括清晰度、完整性、简洁性和实用性,提供了全面的比较。
-
本地化数据的使用:CLAIR模型是在范德堡大学医学中心(VUMC)的患者消息和医生回复数据上进行微调的,具有本地化的优势。
-
多样化的应用场景:研究涵盖了多种常见的患者消息场景,确保了模型的广泛适用性。
-
高一致性的评分:五位医生的评分一致性较高(ICC值为0.76),表明评分结果具有较高的可靠性。
不足与反思
-
评估角度单一:目前仅从医生的角度评估了生成的跟进问题,未来研究可以考虑从患者的角度评估这些问题的实用性,以更好地帮助患者撰写消息。
-
外部临床知识的嵌入:通过微调或检索增强生成来嵌入外部临床知识(如UpToDate中的临床指南)可能会提高生成跟进问题的性能。
-
临床影响的模糊性:使用跟进问题指导患者撰写消息的临床影响尚不清楚。下一步工作将实施一个工具,在患者门户中展示跟进问题,并评估其对临床医生行为和患者的影响。
关键问题及回答
问题1:在研究中,如何识别和选择常见的患者消息场景?
研究通过与内科医生进行访谈,识别了7个常见的患者消息场景。具体步骤如下:
-
访谈内科医生:研究团队与内科医生(A.P.W., S.H.)进行访谈,了解他们在通过My Health与患者沟通时遇到的常见场景。
-
自动计数消息轮次:初步考虑通过自动计数消息轮次来识别常见场景,但这需要开发自动分类模型和框架。
-
选择代表性场景:基于医生的经验和访谈结果,选择了7个涉及患者与提供者之间来回沟通的代表性消息线程。
-
移除敏感信息:从这些消息中移除了受保护的健康信息,但保留了其他内容以便后续分析。
问题2:在模型生成后续问题时,使用了哪些LLMs,它们的具体生成方式是什么?
研究使用了三种LLMs生成后续问题:
-
综合LLM人工智能响应器(CLAIR):在VUMC的患者-提供者消息数据上进行微调的LLM。具体来说,CLAIR模型使用了Llama2(70B)模型,并通过低秩适应(low-rank adaptation)在其本地数据集上进行监督微调。
-
GPT4(简单提示):使用简单提示的GPT4模型。简单提示的设计旨在引导模型生成与患者症状相关的后续问题。
-
GPT4(复杂提示):使用复杂提示的GPT4模型,专注于澄清患者症状并检查患者病情的最近变化。复杂提示的设计更为详细,旨在引导模型生成更全面和具体的后续问题。
问题3:评估生成的后续问题时,使用了哪些指标,这些指标的评分结果如何?
评估生成的后续问题时,使用了以下四个指标:
-
清晰度:后续问题是否易于理解和回答。
-
完整性:后续问题是否包含了回答问题所需的所有重要信息。
-
简练性:后续问题是否简洁。
-
实用性:后续问题对医务人员回答患者问题是否有用。
评分结果显示:
-
医疗提供者生成的后续问题在清晰度、简练性和实用性方面得分较高,但在完整性方面得分较低。
-
CLAIR模型在清晰度和简练性方面得分与医疗提供者相当,但在实用性方面得分更高,完整性得分低于医疗提供者但高于GPT4模型。
-
GPT4-simple模型在完整性方面得分较高,但在清晰度和简练性方面得分较低。
-
GPT4-complex模型在完整性和简练性方面得分较高,但在清晰度方面得分较低。
总体而言,CLAIR模型在实用性和清晰度方面表现最佳,而GPT4-complex模型在完整性和简练性方面表现较好。

参考文献