

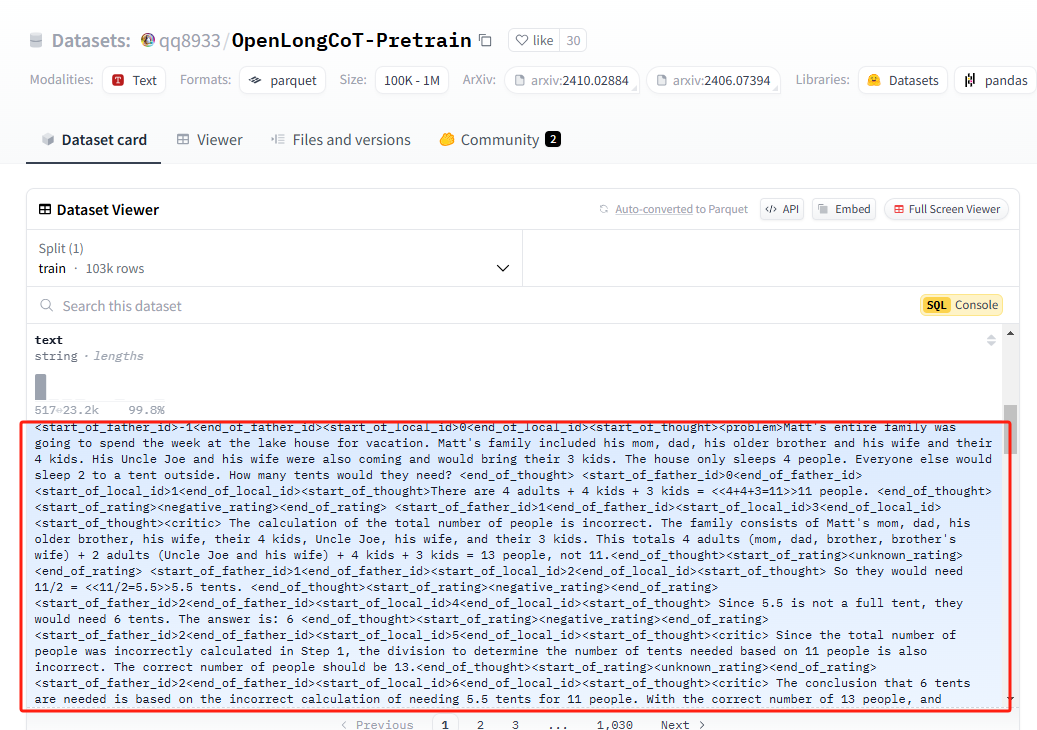
此次开源的还包括长思维链CoT预训练数据OpenLongCot-Pretrain(103K),每条数据包括问题描述、多步推理,最终答案

https://huggingface.co/datasets/qq8933/OpenLongCoT-Pretrainhttps://github.com/SimpleBerry/LLaMA-O1
推荐阅读
欢迎关注我的公众号“PaperAgent”,每天一篇大模型(LLM)文章来锻炼我们的思维,简单的例子,不简单的方法,提升自己。

此次开源的还包括长思维链CoT预训练数据OpenLongCot-Pretrain(103K),每条数据包括问题描述、多步推理,最终答案
https://huggingface.co/datasets/qq8933/OpenLongCoT-Pretrainhttps://github.com/SimpleBerry/LLaMA-O1
推荐阅读
欢迎关注我的公众号“PaperAgent”,每天一篇大模型(LLM)文章来锻炼我们的思维,简单的例子,不简单的方法,提升自己。
上一篇:剪映里的AI,效果很赞!