
收录于话题
2024年11月6日arXiv cs.CV发文量约109余篇,减论Agent通过算法为您推荐并自动化整理为卡片供您参考,预计为您节省48分钟浏览arXiv的时间。


洛桑联邦理工学院的研究团队介绍了Multi-Transmotion方法,这是一个基于transformer的预训练模型,用于人体运动预测。该方法整合了多个数据集,并采用了一种新颖的掩码策略来捕获丰富的表示,展示了在各种下游任务中的强大性能。
【Bohr精读】
https://j1q.cn/WJRhN9PK
【arXiv链接】
http://arxiv.org/abs/2411.02673v1
【代码地址】
https://github.com/vita-epfl/multi-transmotion

北卡罗来纳大学教堂山分校和微软团队提出了LiVOS,一种用于视频对象分割的轻量级记忆网络。该方法通过线性注意力进行线性匹配,将记忆匹配重新构建为一个循环过程。同时,将二次注意力矩阵减少为一个恒定大小的时空不可知的二维状态,并引入门控线性匹配来控制信息的保留或丢弃。
【Bohr精读】
https://j1q.cn/RXsJvB2v
【arXiv链接】
http://arxiv.org/abs/2411.02818v1
【代码地址】
https://github.com/uncbiag/LiVOS

南洋理工大学、谢赫穆罕默德人工智能大学、中山大学的研究团队提出了一种语义对齐的对抗进化三角(SA-AET)方法。该方法通过在对抗进化三角内进行战略采样,增强对抗多模态示例对视觉语言预训练(VLP)模型的可转移性,从而通过在语义图像文本特征对比空间中生成对抗示例来增强对抗多样性。
【Bohr精读】
https://j1q.cn/NNuCXeUa
【arXiv链接】
http://arxiv.org/abs/2411.02669v1
【代码地址】
https://github.com/jiaxiaojunQAQ/SA-AET
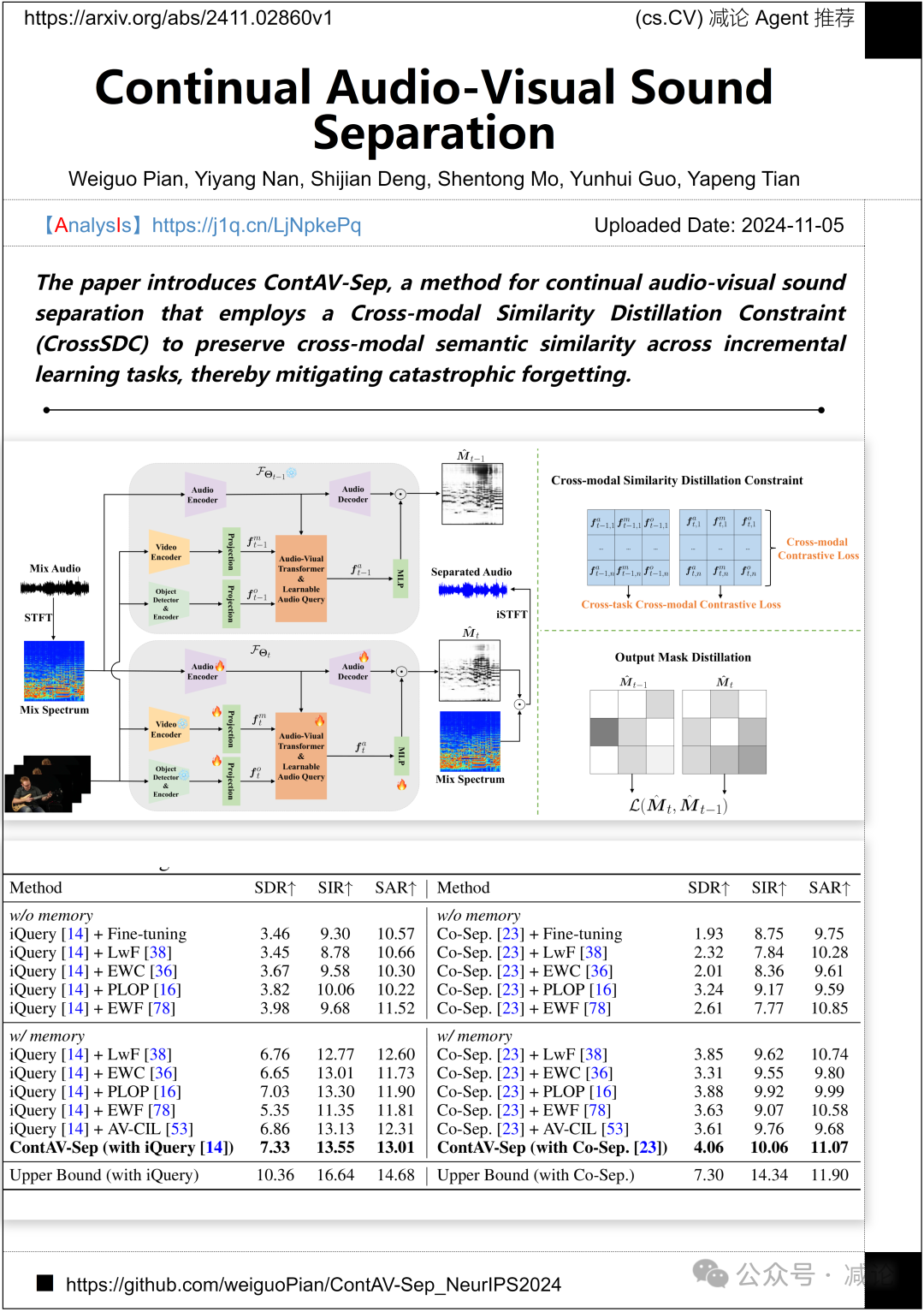
德克萨斯大学达拉斯分校,布朗大学,卡内基梅隆大学的研究团队介绍了ContAV-Sep方法。该方法采用了跨模态相似度蒸馏约束(CrossSDC),以保持跨增量学习任务中的跨模态语义相似性,从而减轻灾难性遗忘。
【Bohr精读】
https://j1q.cn/LjNpkePq
【arXiv链接】
http://arxiv.org/abs/2411.02860v1
【代码地址】
https://github.com/weiguoPian/ContAV-Sep_NeurIPS2024

滑铁卢大学和NVIDIA的研究团队提出了一种使用多模态大型语言模型(MLLMs)的通用多模态检索方法。该方法包括模态感知的硬负采样和持续微调,以增强多模态和文本到文本检索能力。此外,他们还探讨了将MLLMs用作零样本重新排序器,以进一步提高在复杂查询场景中的检索准确性。
【Bohr精读】
https://j1q.cn/Q7gjBUrq
【arXiv链接】
http://arxiv.org/abs/2411.02571v1
【代码地址】
https://huggingface.co/nvidia/MM-Embed

麻省理工学院、伦敦大学学院、马萨诸塞大学阿默斯特分校的研究团队推出了一个名为INQUIRE的文本到图像检索基准。该论文旨在挑战多模态视觉语言模型,涵盖了一个新的五百万图像数据集,重点关注生态和生物多样性概念,需要细致图像理解和领域专业知识。
【Bohr精读】
https://j1q.cn/UFOdVKuM
【arXiv链接】
http://arxiv.org/abs/2411.02537v1
【代码地址】
https://inquire-benchmark.github.io/, https://github.com/inquire-benchmark/INQUIRE, https://github.com/inquire-benchmark/INQUIRE/tree/main/data

慕尼黑工业大学和伦敦帝国学院的Fellow团队提出了一种基于图的框架,用于拓扑准确的图像分割。他们构建了一个组件图,编码了预测和地面真相的拓扑信息,以识别拓扑关键区域并基于局部邻域信息计算损失,旨在在保持拓扑的同时具有高效的计算能力。
【Bohr精读】
https://j1q.cn/9pXpHLOy
【arXiv链接】
http://arxiv.org/abs/2411.03228v1
【代码地址】
https://anonymous.4open.science/r/Topograph
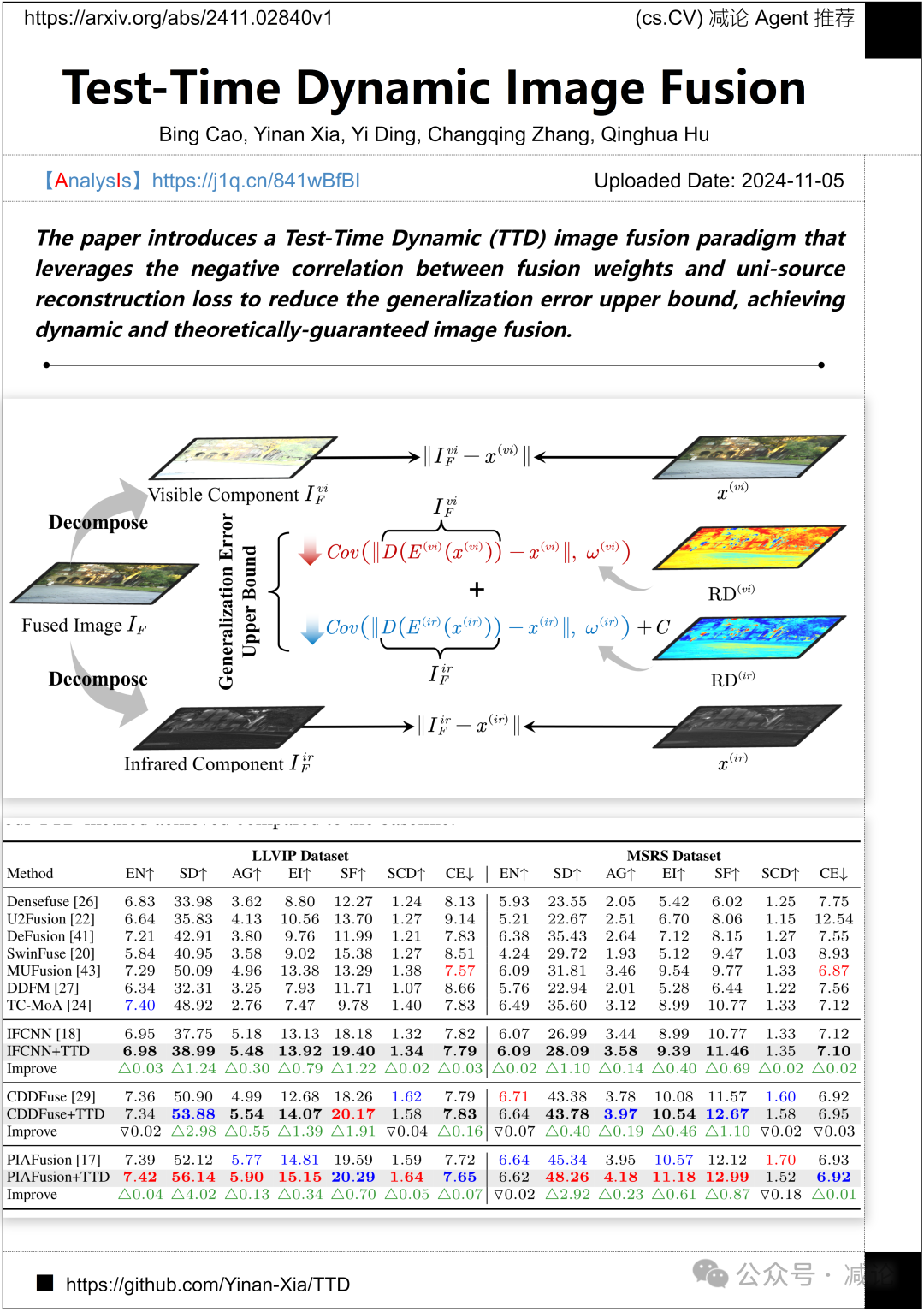
天津大学的研究团队提出了一种利用融合权重与单源重建损失之间负相关性的测试时间动态(TTD)图像融合范式,以降低泛化误差上界,实现动态且理论上保证的图像融合。
【Bohr精读】
https://j1q.cn/841wBfBI
【arXiv链接】
http://arxiv.org/abs/2411.02840v1
【代码地址】
https://github.com/Yinan-Xia/TTD

北京大学、香港科技大学、香港科技大学(广州)的研究团队提出了DiT4Edit,一种基于扩散Transformer的图像编辑框架。该方法利用DPM-Solver反演算法、统一的注意力控制和补丁合并,相较于基于UNet的方法更快地生成更高质量的编辑图像。
【Bohr精读】
https://j1q.cn/KVY3uDrR
【arXiv链接】
http://arxiv.org/abs/2411.03286v1
【代码地址】
https://github.com/fkyyyy/DiT4Edit

亚利桑那州立大学和马里兰大学巴尔的摩县分校的研究团队提出了一种名为TripletCLIP的方法。该方法结合了通过上下文学习和文本到图像扩散模型生成的困难负面图像–文本对,同时使用了一种新颖的三元对比损失函数进行训练,从而增强了CLIP模型的组合推理能力。
【Bohr精读】
https://j1q.cn/VagmS9CM
【arXiv链接】
http://arxiv.org/abs/2411.02545v1
【代码地址】
tripletclip.github.io

滑铁卢大学和阿尔伯塔大学的研究团队提出了一个针对动态室内环境中智能移动平台的实时、延迟感知的合作感知系统。该系统包括一个多模传感器节点网络和一个中心节点提供感知服务,采用新颖算法用于层次聚类、LiDAR-摄像头融合和延迟感知全局感知,以提高检测准确性和对延迟的鲁棒性。
【Bohr精读】
https://j1q.cn/x6HKCQ0C
【arXiv链接】
http://arxiv.org/abs/2411.02624v1
【代码地址】
https://github.com/NingMingHao/MVSLab-IndoorCooperativePerception
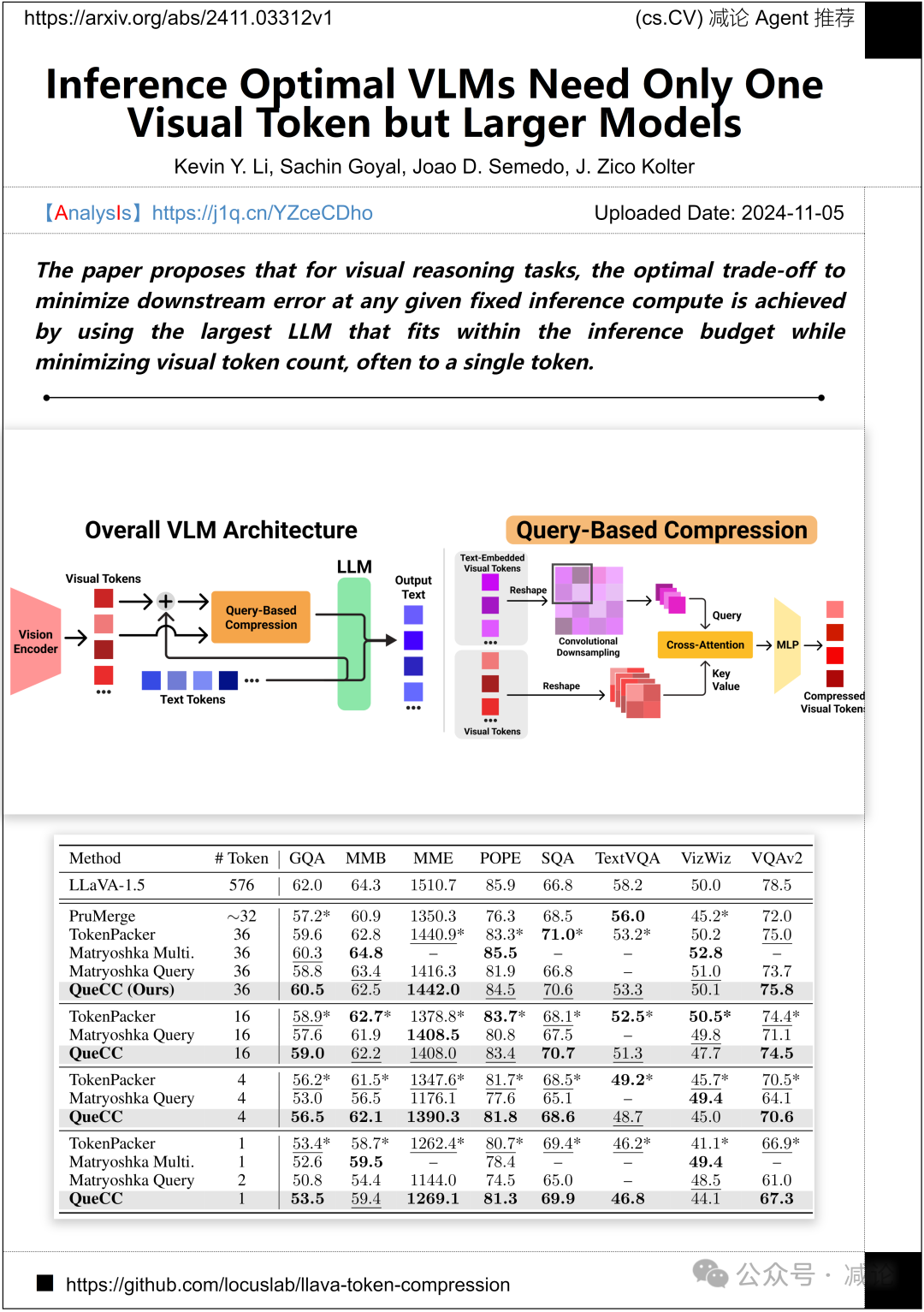
卡内基梅隆大学的博世人工智能中心团队提出了一种新的方法。他们的论文提出,通过使用在推理预算内最大的LLM,同时最小化视觉标记数量,通常缩减到一个标记,可以实现在任何固定推理计算下最小化下游错误的最佳权衡。
【Bohr精读】
https://j1q.cn/YZceCDho
【arXiv链接】
http://arxiv.org/abs/2411.03312v1
【代码地址】
https://github.com/locuslab/llava-token-compression

欢迎关注减论,持续输出有深度的人工智能极减理解,提升信息获取效率和认知维度。看完点颗小星星再走呗~