转自公众号:知识图谱科技
http://mp.weixin.qq.com/s?__biz=MzI3ODE5Mzc1Ng==&mid=2247492475&idx=1&sn=d44714764cd925969f52a08c893fc85f



2024年7月15日,中国医学科学院基础医学研究所龙尔平团队与耶鲁大学陈庆宇团队合作,在 Nature Medicine 期刊发表了题为:Outpatient reception via collaboration between nurses and a large language model: a randomized controlled trial 的研究论文。该研究旨在通过开发和部署特定于站点的提示工程聊天机器人(SSPEC),评估其在门诊接待中的有效性,并与护士主导的接待进行比较。这项随机对照试验研究表明,将大型语言模型(LLM)与护士合作用于门诊接待,可以提高患者满意度,减少重复问答和负面情绪,并提升回复质量
原文地址: https://www.nature.com/articles/s41591-024-03148-7
源代码可以通过以下链接访问:https://github.com/ZigengHuang/SSPEC
SSPEC 是使用 OpenAI 版本 0.28.1 (https://github.com/openai/openai-python)
RAGAS 版本 0.0.18 (https://github.com/explodinggradients/ragas) 和
LangChain 版本 0.0.333 (https://github.com/langchain-ai/langchain) 开发的。
核心速览
研究背景
接待是患者寻求医疗服务的一个重要环节,也是影响医疗体验的关键组成部分。然而,现有的沟通系统主要依赖人工,这既劳动密集,又需要专业知识。一个有前途的替代方案是利用大型语言模型(LLM)的能力来辅助医疗中心接待处的沟通。在这里,我们整理了一个独特的数据集,包括来自两个医疗中心10个接待站的门诊患者与接待护士之间的35418个真实对话音频案例,以开发一个特定场所的提示工程聊天机器人(SSPEC)。与护士主导的会话(50.5% ≤2轮)相比,SSPEC有效解决了患者的查询,在较少的查询和响应轮次(Q&R;68.0% ≤2轮)中处理的查询比例更高(P = 0.009),涵盖了行政、分诊和初级医疗问题。随后,我们建立了护士与SSPEC的协作模型,监督在实际应用中遇到的不确定性。我们在一项涉及2164名参与者的单中心随机对照试验中,主要终点表明,护士与SSPEC的协作模型获得了更高的患者满意反馈(3.91 ± 0.90对比护士组的3.39 ± 1.15,P < 0.001)。关键的次要结果显示,重复Q&R的比率降低(3.2%对比护士组的14.4%,P < 0.001),就诊期间的负面情绪减少(2.4%对比护士组的7.8%,P < 0.001),在完整性(4.37 ± 0.95对比护士组的3.42 ± 1.22,P < 0.001)、同理心(4.14 ± 0.98对比护士组的3.27 ± 1.22,P < 0.001)和可读性(3.86 ± 0.95对比护士组的3.71 ± 1.07,P = 0.006)等方面提高了响应质量。总体而言,我们的研究支持将LLM集成到日常医院工作流程中的可行性,并提出了一个改善沟通的范式,以造福患者和护士。
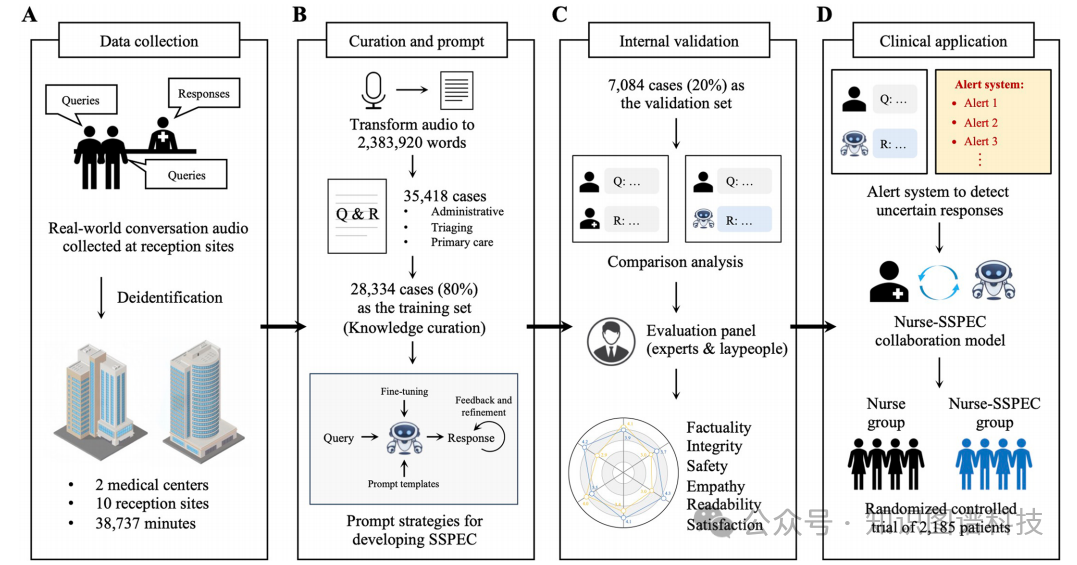 图. SSPEC研究设计概述,数据采集、设计、评估及验证的总流程
图. SSPEC研究设计概述,数据采集、设计、评估及验证的总流程
研究设计概述。(A) 从两个医疗中心的10个接待站收集了对话音频。(B) 通过仔细的手动编辑将音频数据转化为文本格式,涵盖了患者询问的多种内容,包括行政问题、分诊和初级护理关切。这些案例被用作每个站点知识整理的训练集。采用微调和提示策略开发了站点特定的提示工程聊天机器人(SSPEC)。(C) 与训练集无关的案例被保留作为验证集,用于在事实性、完整性、安全性、同理心、可读性和满意度方面进行对比测试。(D) 实施了警报系统,以提醒SSPEC响应中的不确定性。随后,建立了接待护士与SSPEC之间的合作模型。该模型随后在随机对照试验中进行了测试,以确定其在门诊接待环境中的实用性。
-
研究问题:这篇文章要解决的问题是如何通过护士与大语言模型(LLM)的合作来改善门诊接待流程。现有的通信系统主要依赖人力,既费时又费知识。LLM在医疗中心接待地点的应用被认为是一种有前景的替代方案。
-
研究难点:该问题的研究难点包括:现有LLM模型主要基于在线材料和科学文献的知识,缺乏特定场景下的知识;当前LLM存在编造事实和其他错误,抑制了其在医疗环境中的应用信心;缺乏对LLM在医学应用中的严格实验研究。
-
相关工作:相关工作包括在美国医学执照考试(USMLE)风格问题和公共论坛上回答患者问题的LLM,但这些工作存在上述提到的局限性。
-
患者与护士对话的情境设置

本研究涉及门诊病人、即将入院的患者或寻求帮助的个人。参与者在到达医院入口时招募,招募对象是对护士提出问题并同意参与对话录音的患者。在招募后,参与者被引导到接待地点与护士进行面对面会晤。在音频录制开始之前,先获得了护士和患者的知情同意。
研究方法
这篇论文提出了一个名为SSPEC(site-specific prompt engineering chatbot)的聊天机器人,用于解决门诊接待中的沟通问题。具体来说,
-
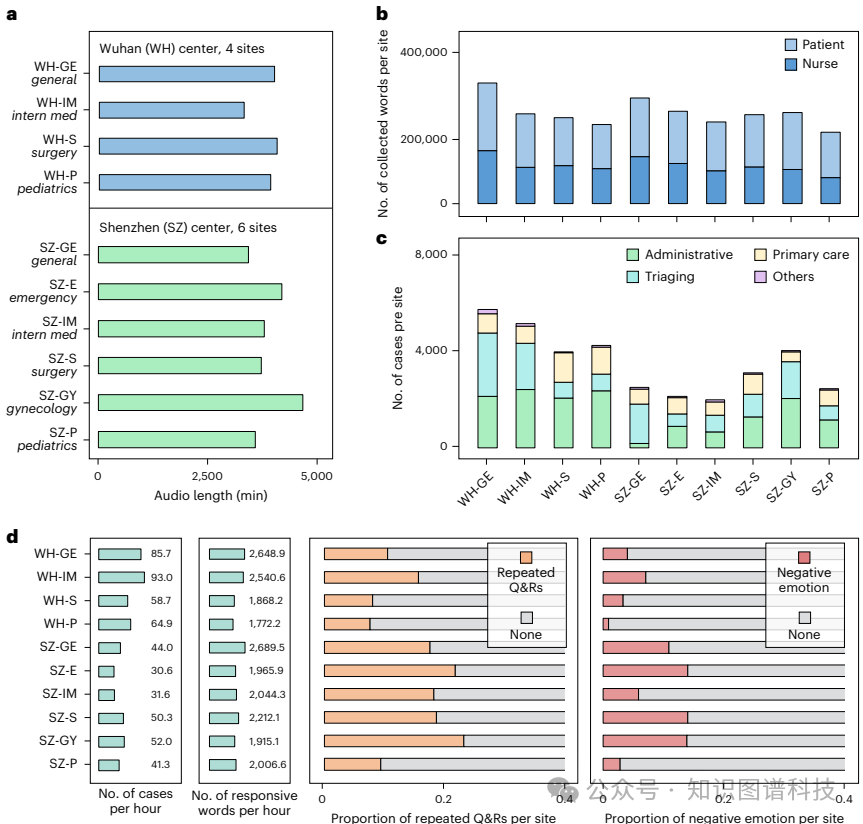
数据收集:首先,从两个医疗中心的10个接待站点收集了35,418个真实对话音频样本,这些样本涵盖了行政、分诊和初级护理等各种查询类型。
-
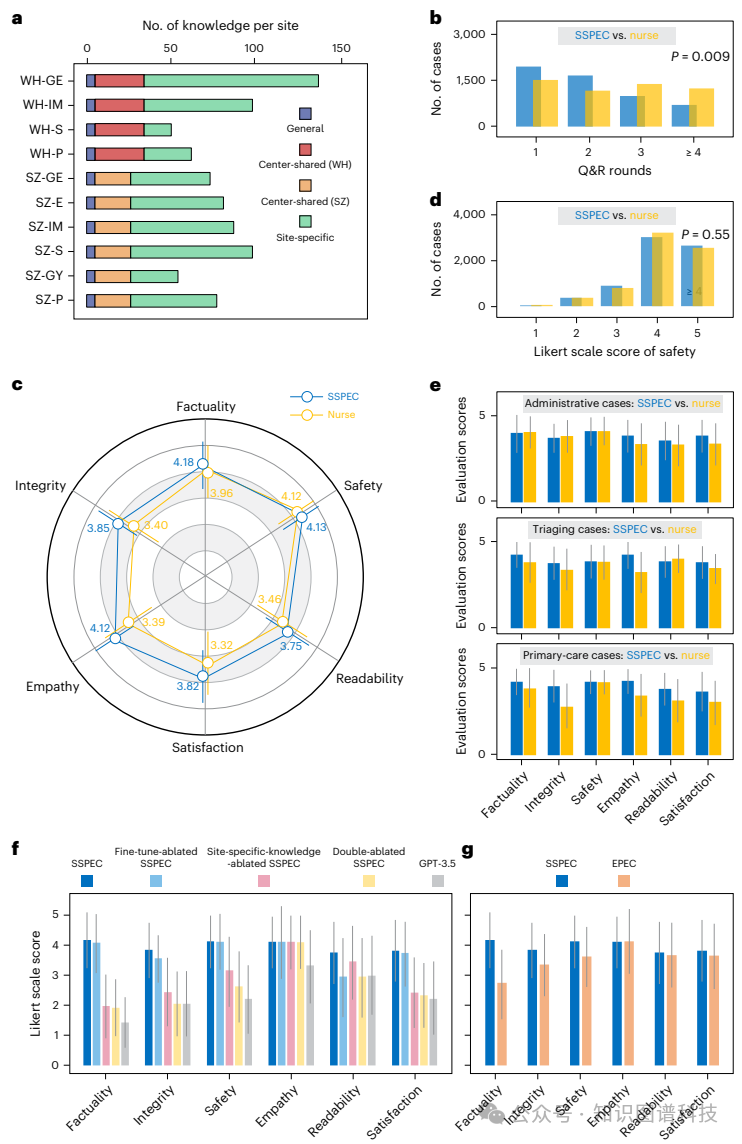
知识整理:手动整理了每个站点的知识,共编译了580条独特信息。这些知识被整合到提示模板中,并通过微调和反馈机制进行优化,以开发SSPEC。
-
模型开发:使用GPT-3.5作为SSPEC的基础模型,通过自动化微调方法改进其能力。然后,使用包含站点特定知识的提示模板,并通过反馈模块评估和优化其响应。
-
内部验证:使用验证集(20%的数据)评估SSPEC的性能,比较其与人类护士在事实性、完整性、安全性、同理心、可读性和满意度等方面的表现。
实验设计
-
数据收集:在武汉和深圳的两个医疗中心,从10个接待站点收集了38,737分钟的对话音频,并将其转换为文本,去除了敏感信息后得到2,383,920字的语料库。
-
样本选择:最终分析了2,164名患者,其中1,080名参与SSPEC协作组,1,084名参与护士组。患者在到达接待站点时被随机分配到两个组之一。

-
参数配置:SSPEC的微调和提示模板根据每个站点的特定知识进行定制。反馈模块包括关键词匹配、独立LLM评估和自动评估,以确保响应的质量和安全性。
结果与分析
-
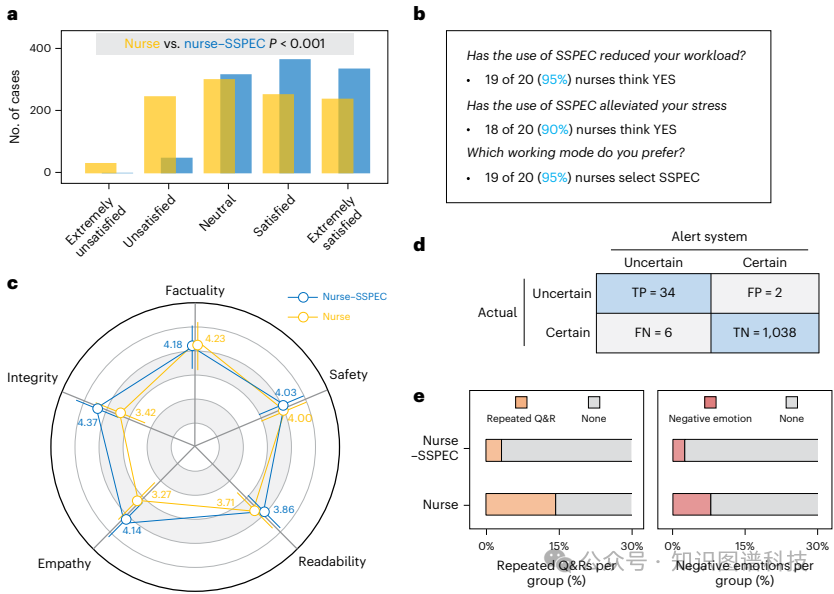
患者满意度:SSPEC协作组患者的满意度显著高于护士组(3.91±0.90 vs. 3.39±1.15,P<0.001)。
-
重复问答率:SSPEC协作组的重复问答率显著低于护士组(3.2% vs. 14.4%,P<0.001)。
-
负面情绪:SSPEC协作组在对话中检测到的负面情绪显著低于护士组(2.4% vs. 7.8%,P<0.001)。
-
响应质量:SSPEC协作组在事实性、完整性、安全性、同理心和可读性方面的响应质量均优于护士组。
总体结论
这篇论文展示了将LLM集成到日常医院工作流程中的可行性,并提出了一种改善患者和护士沟通的新范式。SSPEC在处理门诊接待中的患者查询时表现出更高的效率和更强的同理心支持。护士-SSPEC协作模型显著提高了患者和护士的满意度,减少了重复问答和负面情绪。尽管存在一些潜在的挑战和改进空间,但该研究为LLM在医疗领域的应用提供了有力的证据。
论文评价
优点与创新
-
大规模真实对话语料库:研究收集了来自两个医疗中心10个接待站的35,418例真实对话音频语料库,涵盖了行政、分诊和初级护理等各种查询类型。
-
定制化的提示工程聊天机器人(SSPEC):开发了基于真实对话和特定站点知识的SSPEC,显著提高了患者查询的解决效率。
-
患者满意度提高:在单中心随机对照试验中,SSPEC合作模型的患者满意度显著高于护士主导的会话(3.91±0.90 vs 3.39±1.15,P<0.001)。
-
减少重复问答和负面情绪:SSPEC合作模型减少了重复问答的发生率(3.2% vs 14.4%,P<0.001)和就诊过程中的负面情绪(2.4% vs 7.8%,P<0.001)。
-
增强响应质量:SSPEC合作模型在事实性、完整性、同理心和可读性方面的响应质量均优于护士(P值均小于0.001)。
-
多维度评估:通过独立评估团队对SSPEC的响应进行多维度评估,确保了评估的全面性和客观性。
-
幻觉消除的预警:
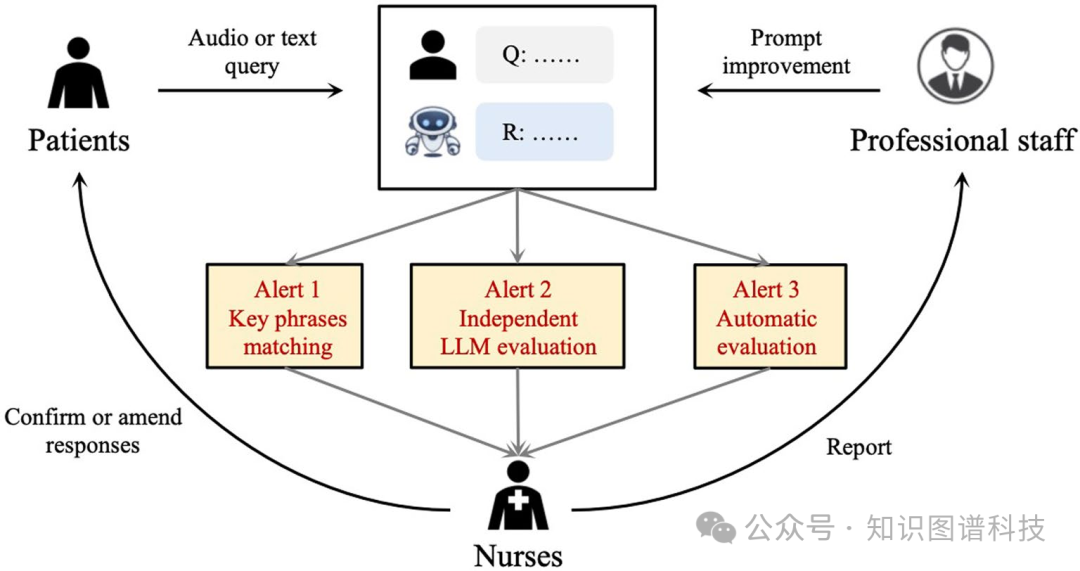
护士-SSPEC 协作模型在减轻不确定性方面的警报系统。患者到达接待地点时,他们的询问会被自动记录并转化为文本。为了解决 SSPEC 可能生成的不确定或潜在有害的回复,已经实施了一个警报系统。该系统在检测到任何“不确定信号”时,会通过关键短语匹配、独立的 LLM 评估或自动评估向护士触发警报。此警报促使护士立即审核或修改响应。此外,一个专门的团队会审查所有患者与 SSPEC 的对话,以不断完善提示。
不足与反思
-
知识整理的局限性:当前的知识整理过程主要依赖手动操作,尽管严格遵循了HIPAA标准,但手动处理数据限制了大规模应用的可能性。
-
警报系统的敏感性:尽管警报系统能够有效识别不确定响应,但仍有少量不确定响应未被修正,这些响应可能会对患者造成潜在风险。
-
患者对聊天机器人的接受度:部分患者可能对完全依赖聊天机器人持保留态度,未来需要提供选项以便患者在必要时向护士确认。
-
护士对SSPEC的依赖性:存在护士过度依赖SSPEC的风险,可能导致他们在与患者的互动中缺乏参与感。
-
隐私和安全问题:尽管采取了严格的匿名化和加密措施,但未来应用中仍需确保符合HIPAA等隐私法规的要求。
-
本地化模型的开发:建议开发本地化的LLM模型以获得更多实际应用的优势,并涉及医疗专业人员、患者、伦理学家和法律专家等多方利益相关者进行评估。
关键问题及回答
问题1:SSPEC在内部验证中的表现如何?与人类护士相比有哪些优势?
在内部验证中,SSPEC在解决患者查询方面表现出色。具体来说,68.0%的查询在两轮内得到解决,而护士主导的会话中这一比例为50.5%(P=0.009)。此外,SSPEC在事实性、完整性、安全性、同理心、可读性和满意度等方面的表现与人类护士相当甚至更优。例如,SSPEC在同理心支持方面得分4.12±0.86,而人类护士为3.39±1.21(P<0.001),表明SSPEC在提供同理心支持方面具有显著优势。
问题2:在随机对照试验中,护士-SSPEC协作模型的患者满意度为何显著高于护士组?
患者对护士-SSPEC协作模型的满意度显著高于护士组(3.91±0.90 vs. 3.39±1.15,P<0.001)。这可能是由于以下几个原因:首先,SSPEC能够高效地解决患者查询,减少重复查询和响应的比例(3.2% vs. 14.4%,P<0.001);其次,SSPEC在对话中表现出更高的同理心和更好的情感支持,减少了负面情绪的发生率(2.4% vs. 7.8%,P<0.001);最后,与SSPEC合作的护士普遍认为SSPEC减轻了他们的工作负担(19/20同意),缓解了他们的压力(18/20同意),并且更愿意与SSPEC进行对话(19/20同意)。
问题3:SSPEC的开发过程中,如何确保知识整理的准确性和有效性?
在SSPEC的开发过程中,知识整理的准确性和有效性通过以下步骤确保:
-
初始评估:将收集的语料库按接待站点分为不同池子。
-
知识识别:识别最有可能被需求的知识,包括相关人员、关键观察、分析、决策和行动。
-
知识组织:将知识分类为通用知识、中心共享知识和站点特定知识,确保信息的一致性和去除冗余。
-
知识格式化:所有知识按主题总结并以陈述句形式呈现。
-
专家手册使用:使用武汉和深圳医疗中心的专家手册作为知识收集的替代方法,补充和完善SSPEC的知识库。
通过这些步骤,SSPEC能够整合大量真实对话数据和站点特定知识,从而提高其在门诊接待中的性能和效果。
思维导图