
收录于话题
2024年11月5日arXiv cs.CV发文量约200余篇,减论Agent通过算法为您推荐并自动化整理为卡片供您参考,预计为您节省92分钟浏览arXiv的时间。


浙江大学, 香港中文大学多媒体实验室提出了一种新颖的多视角立体框架,同时考虑所有源图像,而不依赖深度范围先验知识,利用带有3D姿态嵌入的多视差注意力模块来隐式建模多视角几何约束。
【Bohr精读】
https://j1q.cn/eD68P6ql
【arXiv链接】
http://arxiv.org/abs/2411.01893v1
【代码地址】
https://zju3dv.github.io/GD-PoseMVS/

帝国理工学院Meta AI团队提出了一个统一的语音识别(USR)框架,通过自监督预训练和半监督微调与伪标记相结合,为听觉、视觉和视听语音识别任务训练单一模型。
【Bohr精读】
https://j1q.cn/IbMCf6Vp
【arXiv链接】
http://arxiv.org/abs/2411.02256v1
【代码地址】
https://github.com/ahaliassos/usr
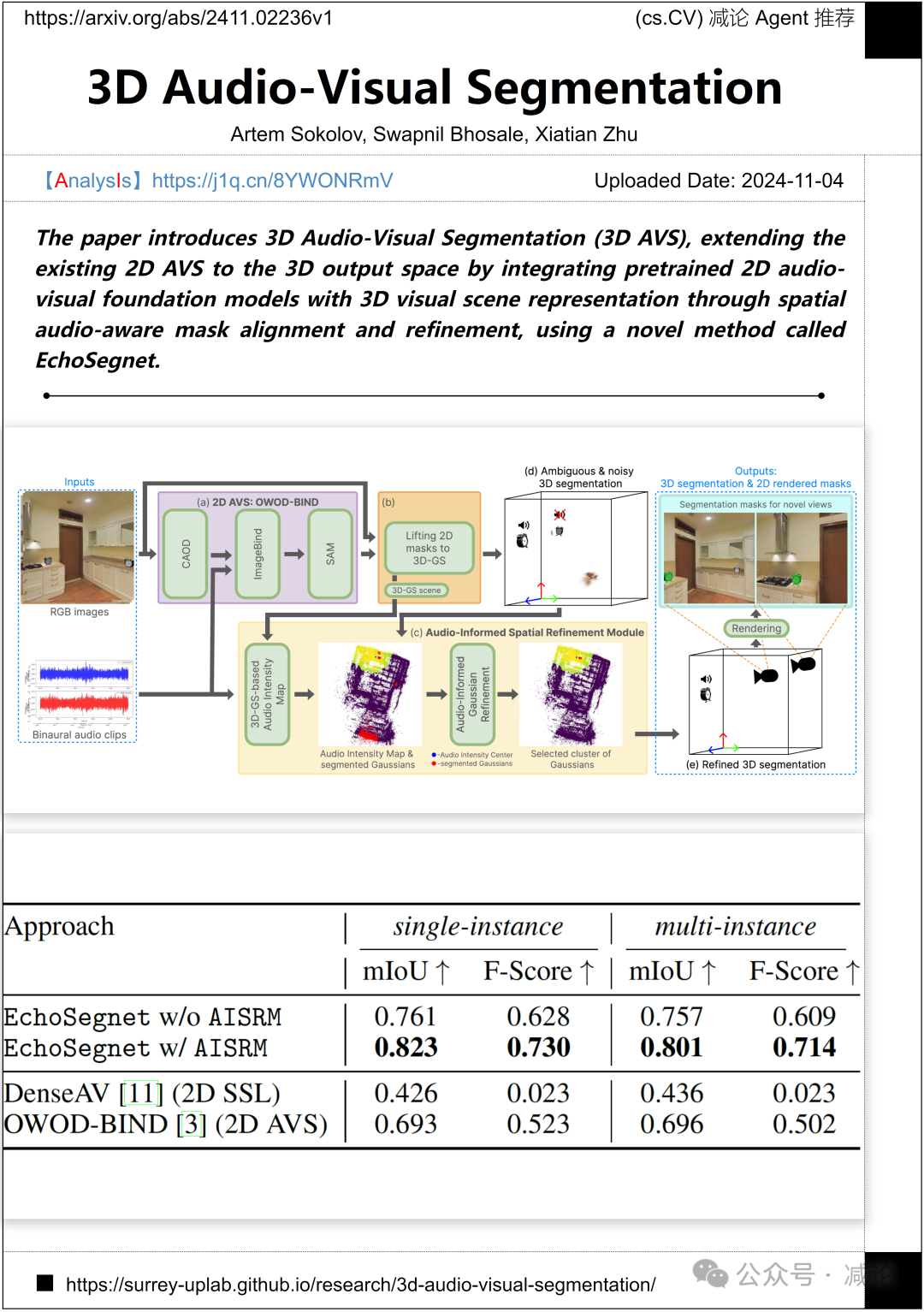
萨里大学的研究团队介绍了一种名为EchoSegnet的新方法,用于3D音频–视觉分割(3D AVS)。该方法结合了预训练的2D音频–视觉基础模型和3D视觉场景表示,通过空间音频感知掩膜对齐和细化,将现有的2D AVS扩展到3D输出空间。
【Bohr精读】
https://j1q.cn/8YWONRmV
【arXiv链接】
http://arxiv.org/abs/2411.02236v1
【代码地址】
https://surrey-uplab.github.io/research/3d-audio-visual-segmentation/

腾讯, 上海人工智能实验室, 台湾大学 的研究团队介绍了MVPaint,一个3D纹理框架,通过同步多视角生成、3D空间纹理修补和UV细化生成高分辨率、无缝和多视角一致的纹理。
【Bohr精读】
https://j1q.cn/qgfgttvs
【arXiv链接】
http://arxiv.org/abs/2411.02336v1
【代码地址】
http://mvpaint.github.io
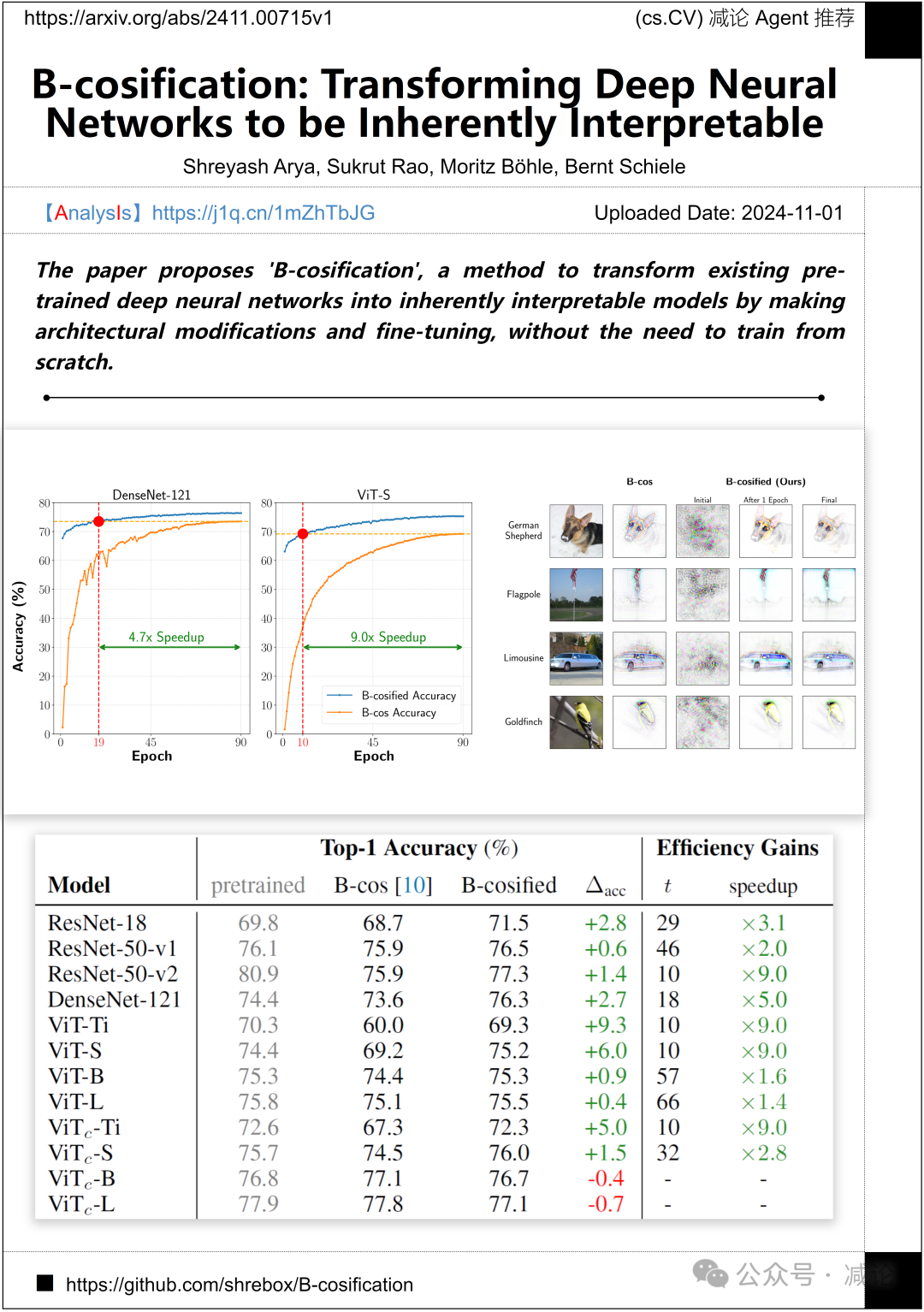
马克斯·普朗克信息学研究所的研究团队提出了“B-余弦化”方法,通过进行架构修改和微调,将现有的预训练深度神经网络转化为固有可解释模型,而无需从头开始训练。
【Bohr精读】
https://j1q.cn/1mZhTbJG
【arXiv链接】
http://arxiv.org/abs/2411.00715v1
【代码地址】
https://github.com/shrebox/B-cosification
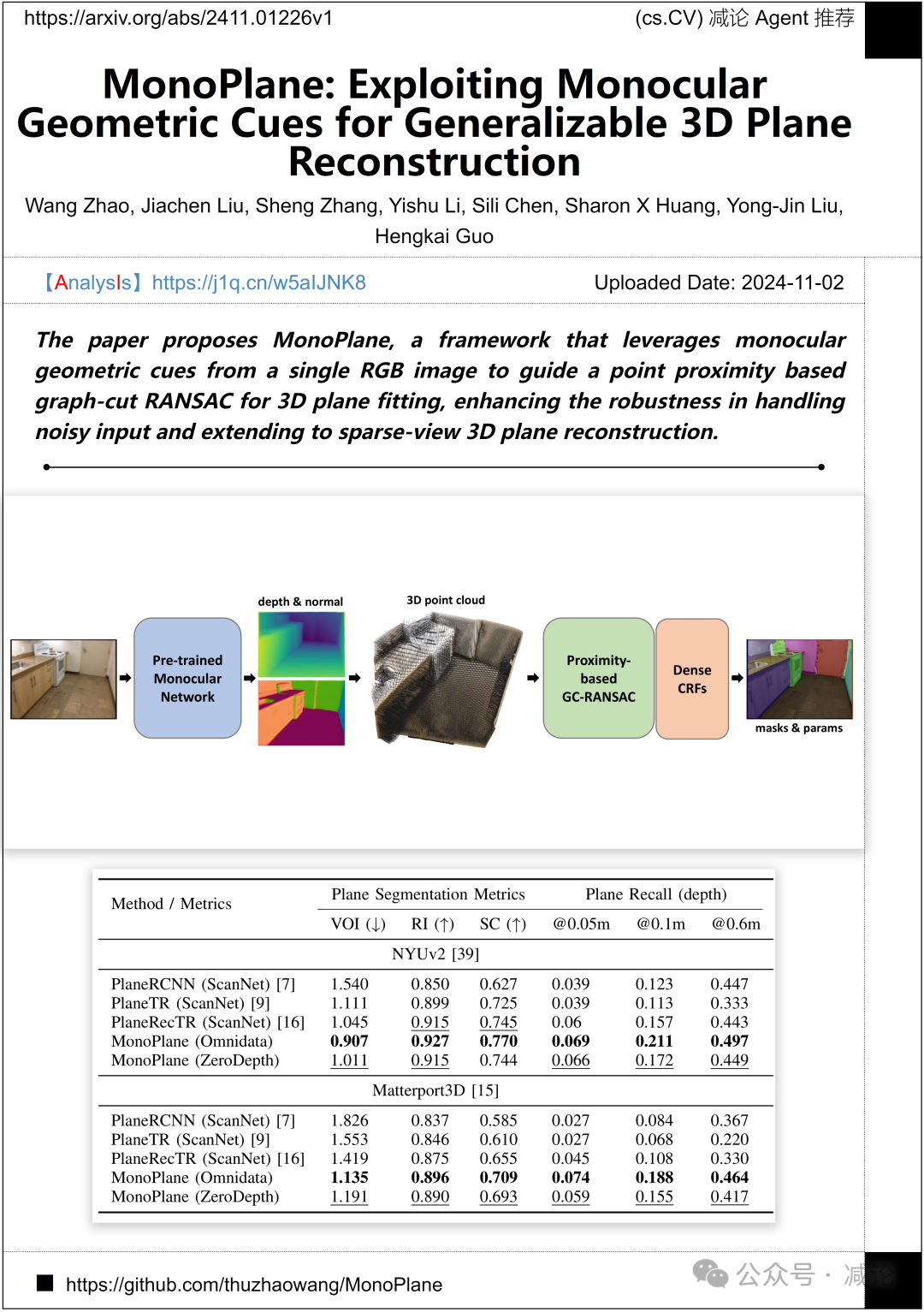
清华大学, 宾夕法尼亚州立大学, 字节跳动公司的研究团队提出了MonoPlane,这是一个框架,利用单个RGB图像中的单眼几何线索来引导基于点邻近性的图割RANSAC进行3D平面拟合,增强了处理嘈杂输入的鲁棒性,并扩展到稀疏视角的3D平面重建。
【Bohr精读】
https://j1q.cn/w5aIJNK8
【arXiv链接】
http://arxiv.org/abs/2411.01226v1
【代码地址】
https://github.com/thuzhaowang/MonoPlane

加州大学伯克利分校和德克萨斯大学奥斯汀分校的研究团队介绍了X-DRIVE,一种双分支多模态潜在扩散框架。该框架通过建模点云和多视角图像的联合分布,并通过跨模态极线条件模块增强跨模态一致性,实现对齐LiDAR和多视角摄像头数据的可控可靠合成。
【Bohr精读】
https://j1q.cn/QN1IuJn3
【arXiv链接】
http://arxiv.org/abs/2411.01123v1
【代码地址】
https://github.com/yichen928/X-Drive
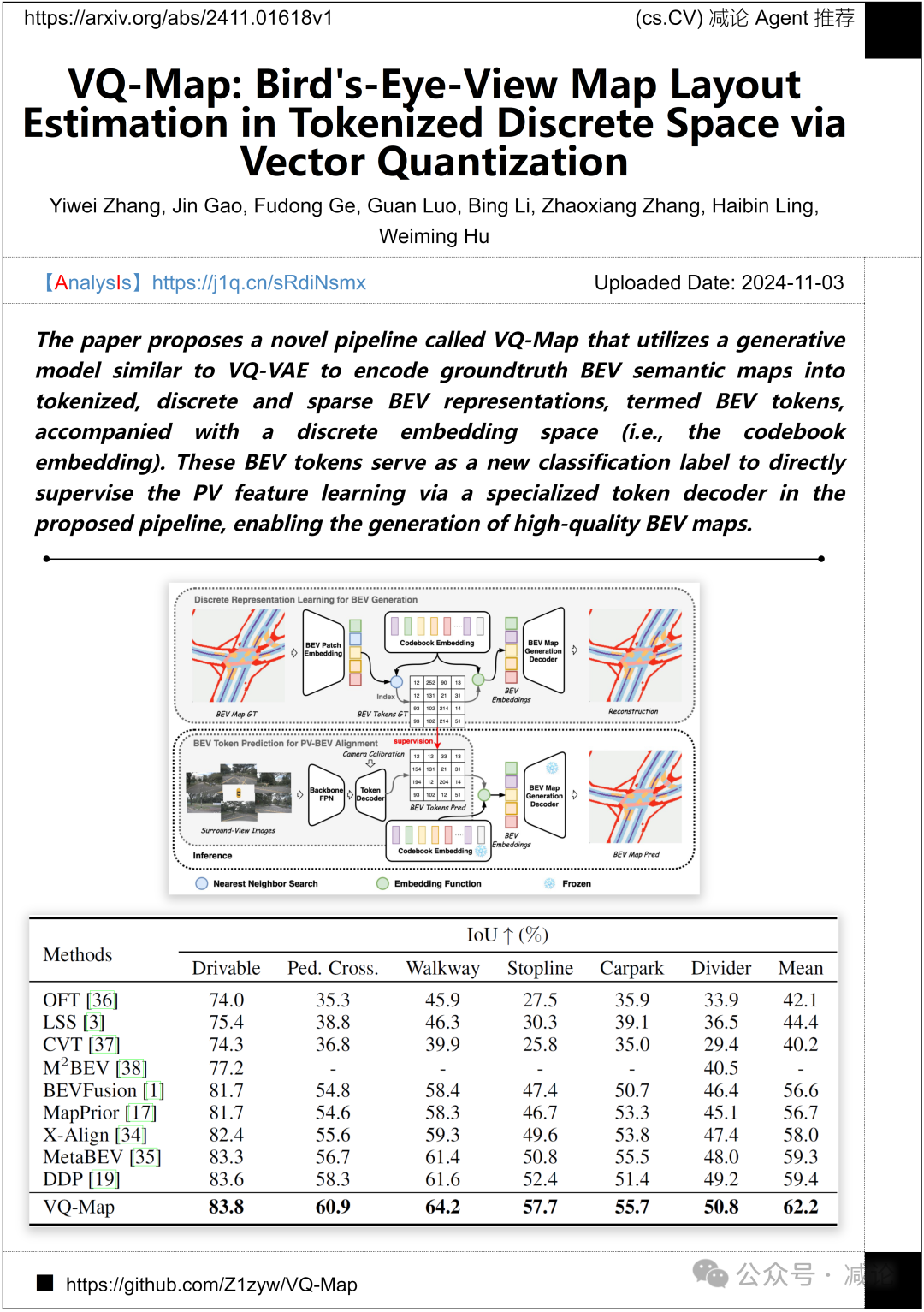
中国科学院大学和纽约州立大学斯托尼布鲁克分校的研究团队提出了一种名为VQ-Map的新型流程。该方法利用类似于VQ-VAE的生成模型,将地面真值BEV语义地图编码为标记化、离散和稀疏的BEV表示,称为BEV标记,配备离散嵌入空间(即码书嵌入)。这些BEV标记作为新的分类标签,通过提出的流程中的专门的标记解码器直接监督PV特征学习,从而实现高质量BEV地图的生成。
【Bohr精读】
https://j1q.cn/sRdiNsmx
【arXiv链接】
http://arxiv.org/abs/2411.01618v1
【代码地址】
https://github.com/Z1zyw/VQ-Map

西安交通大学的研究团队提出了HeightMapNet,这是一个用于端到端高清地图学习的框架。该框架建立了图像特征和道路表面高度分布之间的动态关系,整合高度先验以提高鸟瞰特征的准确性,引入前景–背景分离网络以精确关注道路微特征,并利用BEV空间内的多尺度特征来优化空间几何信息的利用。
【Bohr精读】
https://j1q.cn/DMyfxruE
【arXiv链接】
http://arxiv.org/abs/2411.01408v1
【代码地址】
https://github.com/adasfag/HeightMapNet/

不列颠哥伦比亚大学和维多利亚大学的研究团队提出了Conformal-in-the-Loop(CitL)训练框架,该框架利用符合预测来评估样本的不确定性,调整样本权重,并修剪不可靠的示例,以增强模型对不平衡和嘈杂数据集的鲁棒性和准确性。
【Bohr精读】
https://j1q.cn/zQVdKN1S
【arXiv链接】
http://arxiv.org/abs/2411.02281v1
【代码地址】
CitL
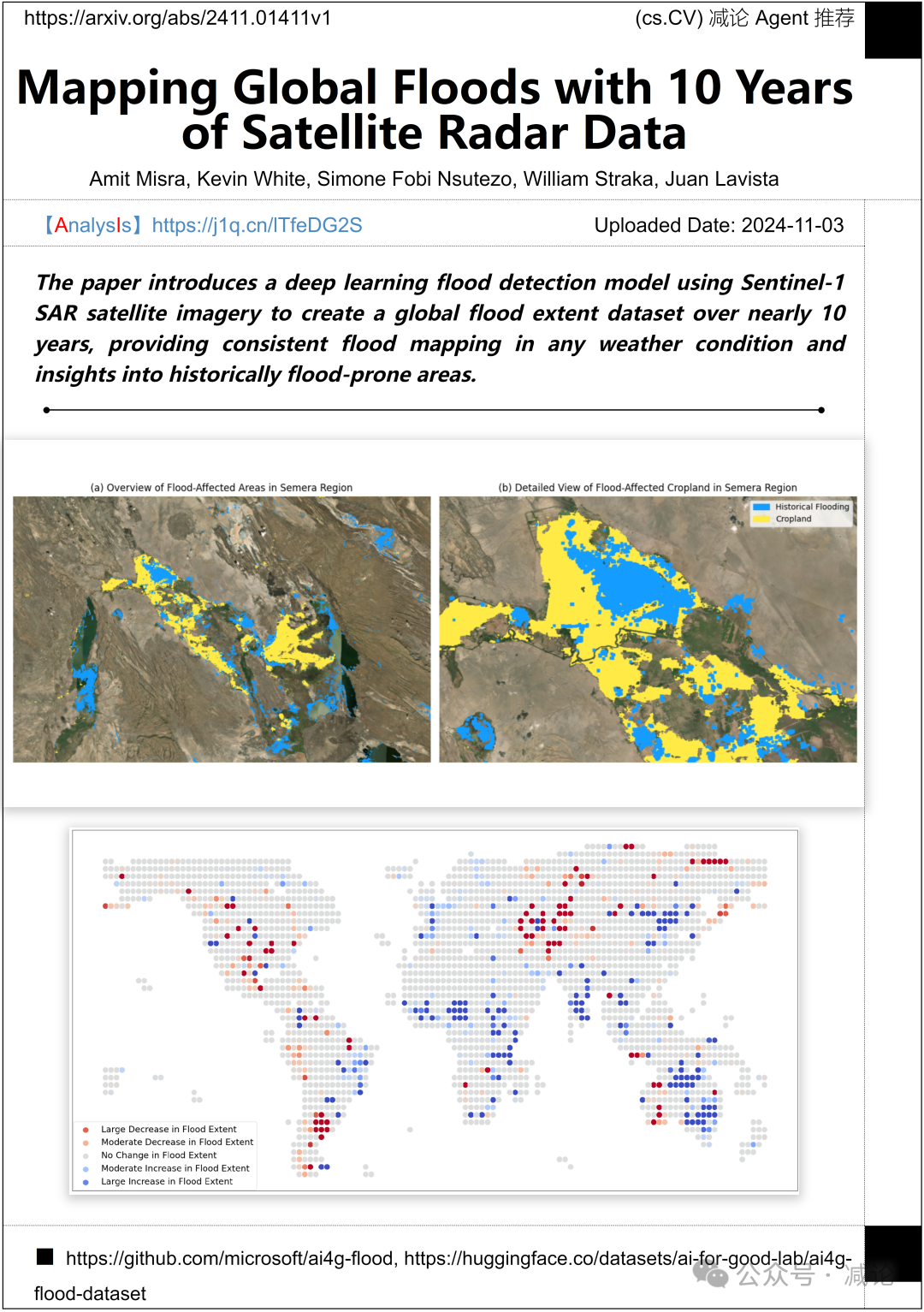
微软AI公益研究实验室、威斯康星大学麦迪逊分校、气象卫星研究合作研究所的团队提出了一种利用Sentinel-1 SAR卫星图像的深度学习洪水检测模型,以创建一个近10年的全球洪水范围数据集,提供在任何天气条件下的一致洪水映射,并深入了解历史上易受洪水影响的地区。
【Bohr精读】
https://j1q.cn/lTfeDG2S
【arXiv链接】
http://arxiv.org/abs/2411.01411v1
【代码地址】
https://github.com/microsoft/ai4g-flood, https://huggingface.co/datasets/ai-for-good-lab/ai4g-flood-dataset

北京大学和清华大学的研究团队提出了GarmentLab,这是一个统一的服装操纵仿真和基准测试工具。GarmentLab集成了多种仿真方法、丰富的资产和真实世界基准测试,显著缩小了仿真到真实的差距。
【Bohr精读】
https://j1q.cn/DggJOhw8
【arXiv链接】
http://arxiv.org/abs/2411.01200v1
【代码地址】
https://garmentlab.github.io/

西安交通大学的研究团队介绍了Polar R-CNN,一种端到端的基于锚点的车道检测方法。该方法使用局部和全局极坐标系统来减少所需锚点的数量,并采用三元组头部与启发式图神经网络块,实现无非极大值抑制(NMS)范式,提高在密集车道场景中的性能。
【Bohr精读】
https://j1q.cn/HQLdw6g2
【arXiv链接】
http://arxiv.org/abs/2411.01499v1
【代码地址】
https://github.com/ShqWW/PolarRCNN

清华大学软件学院、韦恩州立大学计算机科学系和腾讯共同推出了一种名为MultiPull的方法。该方法通过优化从粗到细的准确符号距离函数(SDFs),学习原始点云中的多尺度隐式场。同时,MultiPull利用多级频率特征,并从空间距离和法线一致性的角度引入优化约束。
【Bohr精读】
https://j1q.cn/9Iz9Kadj
【arXiv链接】
http://arxiv.org/abs/2411.01208v1
【代码地址】
https://takeshie.github.io/MultiPull
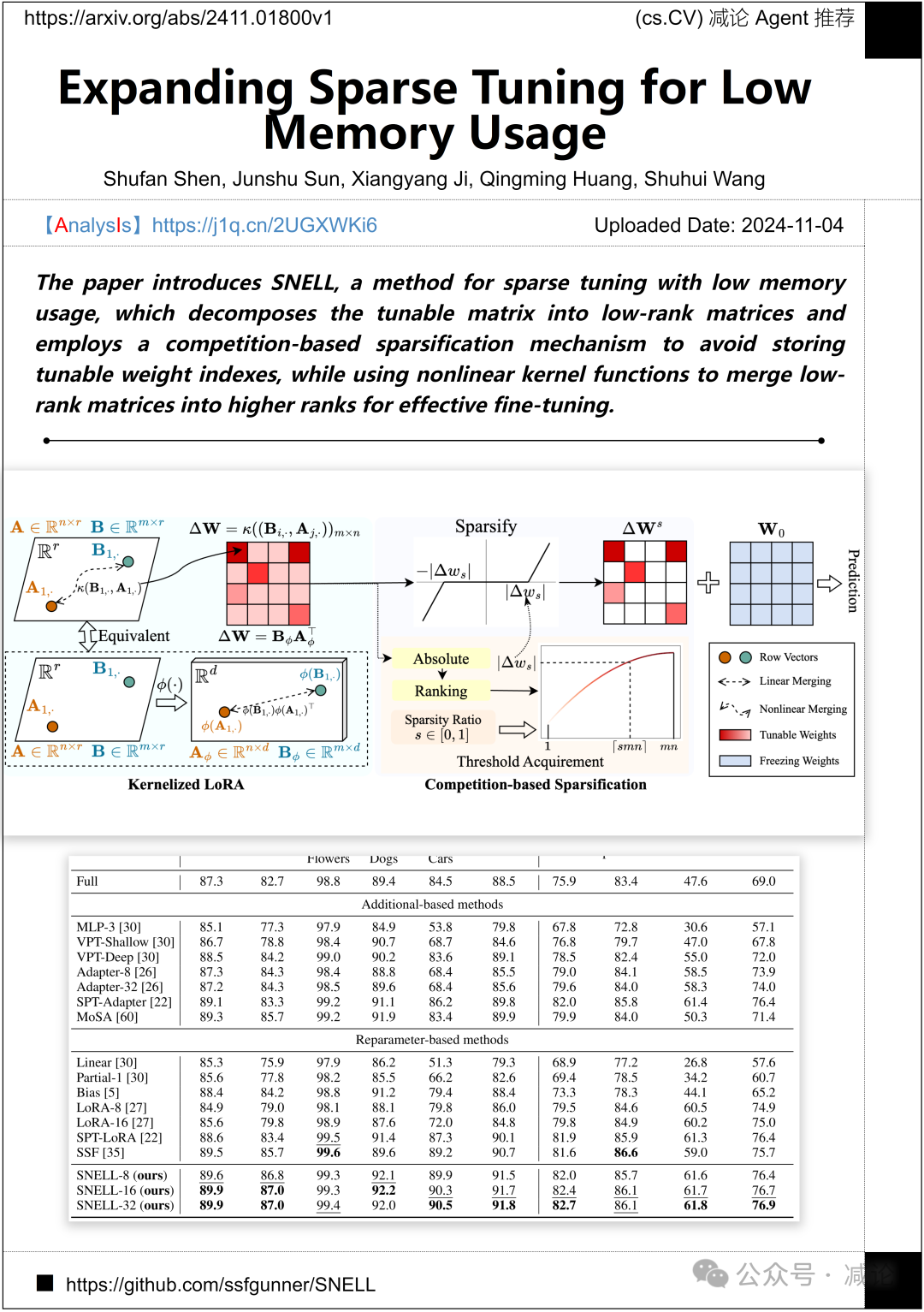
中国科学院计算技术研究所和清华大学的研究人员推出了一种名为SNELL的稀疏调整方法。该方法具有低内存使用率,能够将可调整矩阵分解为低秩矩阵,并采用基于竞争的稀疏化机制,以避免存储可调权重索引。同时,SNELL方法还利用非线性核函数将低秩矩阵合并为更高秩,以实现有效微调。
【Bohr精读】
https://j1q.cn/2UGXWKi6
【arXiv链接】
http://arxiv.org/abs/2411.01800v1
【代码地址】
https://github.com/ssfgunner/SNELL

麻省理工学院提出了一种自适应长度的图像标记器(ALIT),该论文递归地将2D图像标记处理为1D潜在标记。通过在每次迭代中添加新标记来自适应地增加表示能力,以学习2D图像的可变长度标记表示。
【Bohr精读】
https://j1q.cn/T40Qy4xV
【arXiv链接】
http://arxiv.org/abs/2411.02393v1
【代码地址】
https://github.com/ShivamDuggal4/adaptive-length-tokenizer

欢迎关注减论,持续输出有深度的人工智能极减理解,提升信息获取效率和认知维度。看完点颗小星星再走呗~