
今天和大家聊聊PCA,很久没有写过关于降维的内容了。
通常来讲,主成分分析(PCA)主要用于简化数据集、去除噪音、找出数据中的主要特征,从而帮助我们理解数据的结构。
1. 什么是降维?
假设你每天记录自己的饮食数据,有几百个变量,比如你吃的食物种类、摄入的卡路里、脂肪、蛋白质、碳水化合物的含量等。分析这些数据太复杂了!但是,如果我们能从这几百个变量中,找到几个最重要的、能解释大部分信息的变量,那分析起来就容易得多了。这就是降维的目的——把复杂问题变简单,但保留最重要的信息。
2. 主成分分析是怎么做到降维的?
你可以把主成分分析看成是在高维数据中找一条最重要的方向。更具体地说,PCA会从所有数据中找出那些变化最多的方向,因为这些方向上的变化往往能代表数据的主要特征。我们把这些方向叫做主成分。
3. 举个例子
假设你有一个二维数据集,比如记录了你每天走的步数和吃的甜点数量。你可以画出这些数据在一个平面上的分布,X轴是步数,Y轴是甜点数量。也许你会发现数据点的分布大概沿着一条对角线方向(比如步数多的人吃的甜点少,或者反之)。主成分分析会找到这条“对角线”作为最重要的方向(第一主成分),因为它能解释你数据中最多的变化。
然后,PCA可能会发现另一个垂直于这条对角线的方向(第二主成分),这个方向可能解释了剩下的一些信息,但它比第一主成分重要性低。
4. 实际操作
如果我们把数据点投影到这条“对角线”上,数据就变成了一维(用这条“对角线”的值来表示数据)。原来的二维数据被简化了,但你仍然能捕捉到数据中的主要变化。这样,分析数据就变得更容易了。
5. 为什么主成分分析有用?
主成分分析有很多用处,比如:
-
去噪音:去除那些影响较小的维度,只保留主要信息。 -
数据可视化:通过降维,把高维数据转化为二维或三维,方便可视化和理解。 -
加快计算:在机器学习中,减少不必要的维度,能让算法运行得更快。
主成分分析就是帮我们从复杂的多维数据中找出最有代表性的一些方向(主成分),用这些方向来简化问题,从而更好地理解和分析数据。你可以把它想象成整理房间,虽然物品很多,但你只挑出最重要的几件来摆放,房间看起来就整洁明了了。
下面,咱们从原理详细的和大家聊聊~
主成分分析
数据标准化
假设我们有一个数据矩阵 (尺寸为 ,表示 个样本,每个样本有 个特征)。为了消除不同特征取值范围的影响,通常需要对数据进行标准化:
其中, 是各列(即各特征)的均值, 是各列的标准差。这个步骤会将每个特征转化为均值为 0,标准差为 1 的数据。
协方差矩阵
我们计算标准化数据的协方差矩阵,协方差矩阵是 的矩阵:
这个矩阵可以用来表示每个特征与其他特征之间的线性关系。
求解特征值与特征向量
接下来,对协方差矩阵 进行特征值分解,得到特征值 以及对应的特征向量 。这些特征值和特征向量是 PCA 的核心:
-
特征向量 定义了主成分的方向。 -
特征值 代表了该方向上的方差大小,即主成分的重要性。
选择主成分
我们根据特征值大小排序,选择前 个特征值所对应的特征向量,这些特征向量构成主成分空间。通常,我们选择特征值累积占总特征值 90% 或以上的方向作为主成分。
数据投影
将原数据投影到这些主成分上,形成降维后的数据:
其中, 是由前 个特征向量组成的矩阵。
案例实现
现在我们使用虚拟数据集来进行手动实现 PCA,并绘制相关图形。
我们生成一个三维的虚拟数据集,添加一些噪声,并进行 PCA。
import numpy as np
import matplotlib.pyplot as plt
# 设置随机种子以便复现
np.random.seed(42)
# 生成虚拟数据
mean = [5, 10, 15] # 三维数据的均值
cov = [[10, 3, 1], [3, 5, 0.5], [1, 0.5, 2]] # 协方差矩阵
data = np.random.multivariate_normal(mean, cov, size=500) # 生成500个样本
# 绘制三维数据的初始分布
fig = plt.figure(figsize=(8, 6))
ax = fig.add_subplot(111, projection='3d')
ax.scatter(data[:, 0], data[:, 1], data[:, 2], c='blue', s=50, alpha=0.5, marker='o')
ax.set_xlabel('X1')
ax.set_ylabel('X2')
ax.set_zlabel('X3')
plt.title("3D Scatter Plot of Original Data", fontsize=14)
plt.show()
标准化数据
# 标准化数据
mean_data = np.mean(data, axis=0)
std_data = np.std(data, axis=0)
data_std = (data - mean_data) / std_data
# 打印标准化后的数据均值和标准差,验证标准化
print("均值:", np.mean(data_std, axis=0))
print("标准差:", np.std(data_std, axis=0))
计算协方差矩阵并进行特征分解
# 计算协方差矩阵
cov_matrix = np.cov(data_std.T)
print("协方差矩阵:n", cov_matrix)
# 计算特征值和特征向量
eig_values, eig_vectors = np.linalg.eig(cov_matrix)
# 按特征值从大到小排序
sorted_indices = np.argsort(eig_values)[::-1]
eig_values = eig_values[sorted_indices]
eig_vectors = eig_vectors[:, sorted_indices]
# 打印特征值和对应的特征向量
print("特征值:", eig_values)
print("特征向量:n", eig_vectors)
选择主成分并计算投影
# 选择前两大主成分
V_2 = eig_vectors[:, :2]
# 将数据投影到前两大主成分上
projected_data = np.dot(data_std, V_2)
# 绘制投影后的二维数据
plt.figure(figsize=(8, 6))
plt.scatter(projected_data[:, 0], projected_data[:, 1], c='green', s=50, alpha=0.5, marker='o')
plt.xlabel('Principal Component 1')
plt.ylabel('Principal Component 2')
plt.title("2D Scatter Plot of Projected Data", fontsize=14)
plt.show()
累积方差解释率
# 计算累积方差解释率
explained_variance_ratio = eig_values / np.sum(eig_values)
cumulative_variance_ratio = np.cumsum(explained_variance_ratio)
# 绘制累积方差解释率曲线
plt.figure(figsize=(8, 6))
plt.plot(range(1, len(cumulative_variance_ratio) + 1), cumulative_variance_ratio, marker='o', color='red')
plt.xlabel('Number of Principal Components')
plt.ylabel('Cumulative Explained Variance')
plt.title('Cumulative Explained Variance Ratio', fontsize=14)
plt.grid(True)
plt.show()
绘制主成分方向
# 在原始三维数据上绘制主成分方向
fig = plt.figure(figsize=(8, 6))
ax = fig.add_subplot(111, projection='3d')
# 原始数据
ax.scatter(data[:, 0], data[:, 1], data[:, 2], c='blue', s=50, alpha=0.5, marker='o')
# 主成分向量
mean_shifted = np.mean(data, axis=0)
for i in range(2): # 只绘制前两个主成分
vector = eig_vectors[:, i] * np.sqrt(eig_values[i]) * 5 # 缩放特征向量
ax.quiver(*mean_shifted, *vector, color=['red', 'green'][i], linewidth=3)
ax.set_xlabel('X1')
ax.set_ylabel('X2')
ax.set_zlabel('X3')
plt.title("Principal Component Directions", fontsize=14)
plt.show()
1. 原始数据的 3D 散点图,展示了三维数据的初始分布。

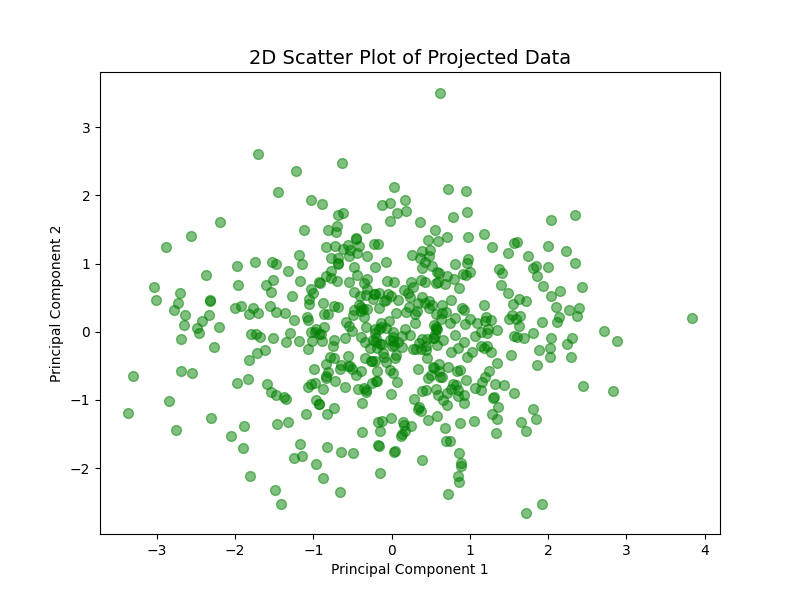
2. 投影后的二维数据散点图,展示了经过 PCA 降维后的数据。
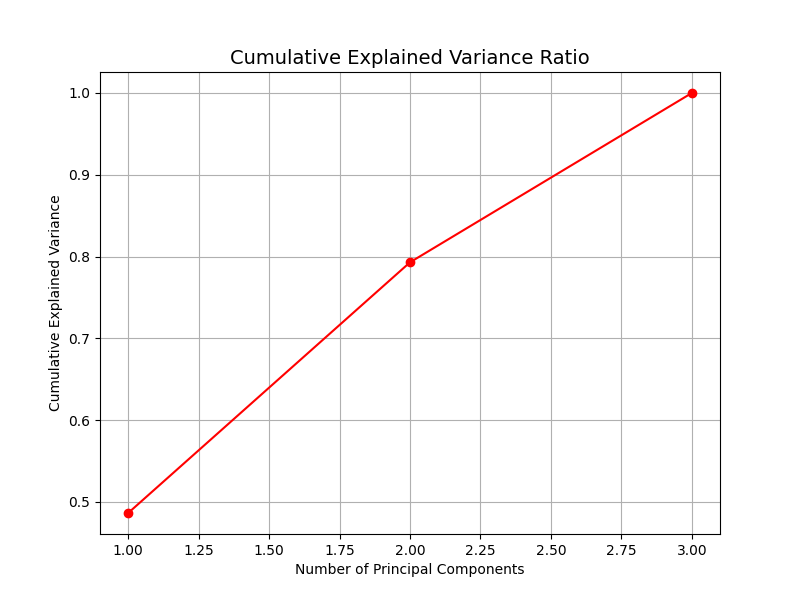
3. 累积方差解释率曲线,显示了主成分解释方差的能力,帮助我们选择合适的主成分数量。
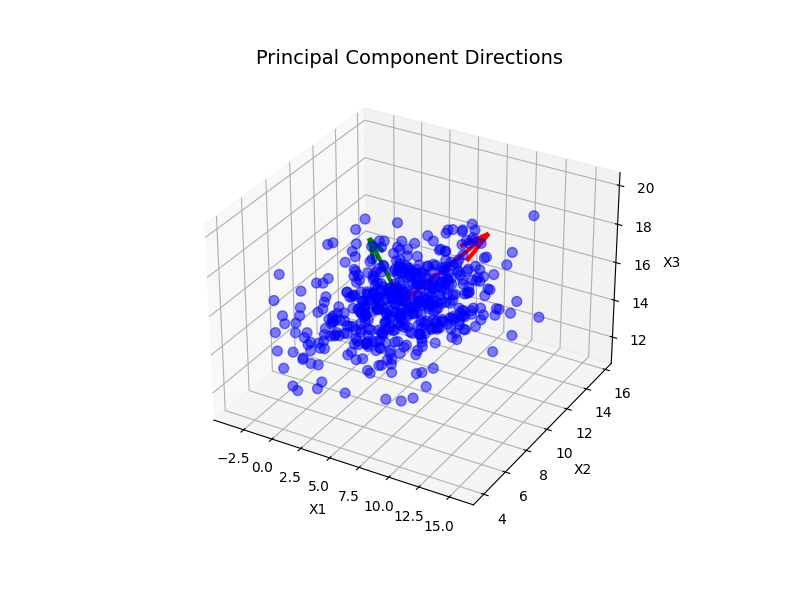
4. 主成分方向的3D图,展示了原始数据中前两个主成分的方向。
整个的代码实现了从头开始的主成分分析,具体步骤包括:数据标准化、协方差矩阵计算、特征值分解、选择主成分以及将数据投影到低维空间。