


-
标题:AgentReview: Exploring Peer Review Dynamics with LLM Agents -
arXiv:https://arxiv.org/abs/2406.12708 -
github网站:https://AgentReview.github.io -
code: https://github.com/Ahren09/AgentReview
摘要总结
同行评审是科学出版完整性和发展的基础。传统的同行评审分析方法往往依赖对现有同行评审数据的探索和统计,这不足以充分解决过程的多变量特性,无法考虑潜在变量,并且由于数据的敏感性而受到隐私问题的进一步限制。本文介绍了AgentReview,这是第一个基于大型语言模型(LLM)的同行评审模拟框架,能够有效拆解多个潜在因素的影响,并解决隐私问题。我们的研究揭示了重要的洞察,包括由于评审者偏见导致的论文决定变化达37.1%,这得到了社会影响理论、利他主义疲劳和权威偏见等社会学理论的支持。我们相信,这项研究可以为改善同行评审机制的设计提供有价值的见解。
论文精读
研究背景
- 研究问题:这篇文章要解决的问题是如何在保护审稿人隐私的前提下,通过大规模语言模型(LLM)代理模拟同行评审过程,揭示影响同行评审结果的多重潜在因素。
- 研究难点:该问题的研究难点包括:同行评审过程的多变量性质、难以测量的潜在变量以及数据隐私问题。
- 相关工作:该问题的研究相关工作包括对现有同行评审数据的分析和统计,但这些方法未能充分考虑过程的多元性、潜在变量和数据隐私问题。
研究方法
这篇论文提出了AGENTREVIEW,第一个基于LLM的同行评审模拟框架。具体来说,
-
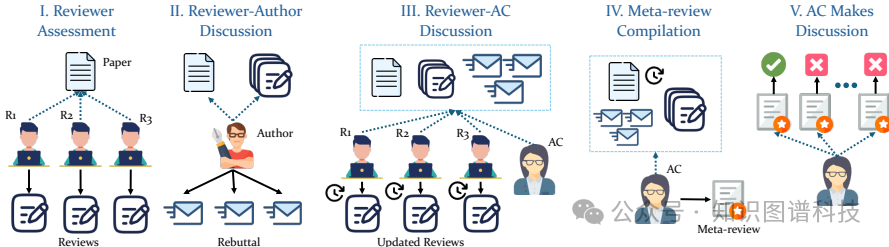
框架概述:AGENTREVIEW通过集成LLM代理和基于代理的建模来模拟同行评审过程。该框架包括审稿人、作者和领域主席(AC)三个角色,所有角色均由LLM代理驱动。
-
评审过程设计:使用一个结构化的五阶段管道来模拟同行评审过程:
- 评审人评估:每个评审人独立评估稿件,生成包含四个部分(重要性与创新性、接受理由、拒绝理由和改进建议)的评论。
- 作者-评审人讨论:作者在评审人-AC讨论期间回应初始评论。
- 评审人-AC讨论:AC发起讨论,要求评审人重新考虑初始评分并更新评论。
- 元评审编写:AC综合讨论、反馈和自己的观察,编写元评审。
- 论文决定:AC审查所有元评审,做出接受或拒绝的决定。
- 数据选择:使用ICLR会议的真实提交数据,确保模拟评论与现实场景紧密相关。数据选择标准包括会议的国际影响力、论文的公开可用性、质量分布和时间跨度。
- 基线设置:建立一个没有特定LLM代理特征的基线设置,以便测量单个变量变化的影响。
实验设计
- 数据收集:从ICLR会议的真实提交中检索2020年至2023年的论文数据,涵盖口头报告、亮点、海报和拒绝四类论文。
- 样本选择:采用分层抽样技术从每类论文中选择样本,最终得到350篇拒绝论文、125篇海报、29篇亮点和19篇口头报告论文。
- 参数配置:在实验中,逐步替换正常评审人为负责任或不负责任的评审人,并分析其对评审结果的影响。
结果与分析
- 评审人的作用:
- 社会影响力:评审人在反驳后通常会调整评分以与同伴保持一致,导致评分的标准差显著下降。
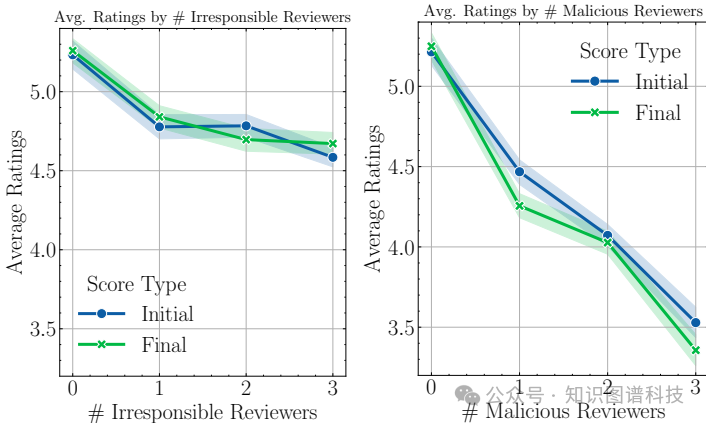
- 利他主义疲劳和同伴效应:一个不负责的评审人可以导致所有评审人的承诺显著下降。
- 群体思维和回音室效应:有偏见的评审人通过互动放大彼此的负面意见,导致评分下降。
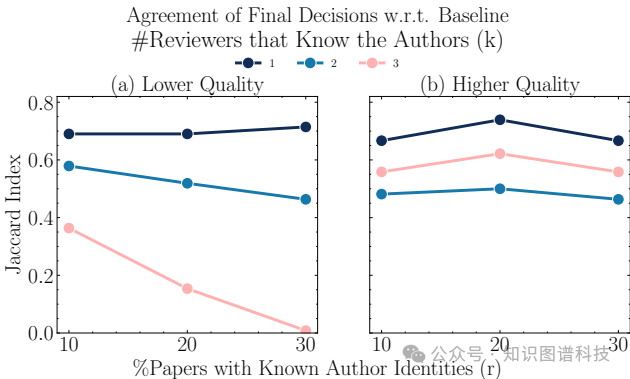
- 权威偏见和晕轮效应:评审人倾向于认为知名作者的稿件更准确,当所有评审人知道作者身份的比例为10%时,决策变化显著。
- 锚定偏见:反驳阶段对最终结果的影响较小,可能是由于评审人过于依赖初步印象。
- 领域主席的作用:
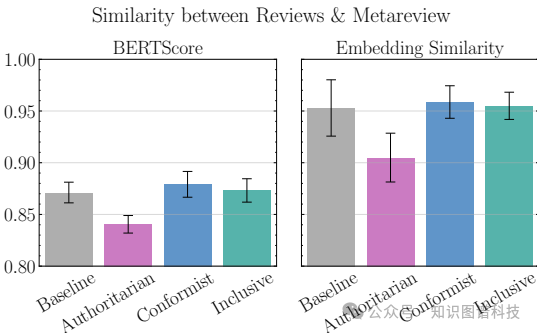
- 包容性AC:最能与基线保持一致,有效整合多样化观点。
- 权威AC:决策与基线相关性较低,可能受个人偏见影响。
- 顺从AC:尽管与评审人评价高度语义重叠,但可能缺乏独立判断。
- 作者匿名性的影响:
- 权威偏见:评审人更倾向于给知名作者的稿件好评。
- 同行评审机制的影响:
- 反驳的影响:取消反驳阶段对最终决定影响较小,可能是由于锚定偏见。
- 整体评分的影响:取消整体评分显著改变了决策格局,可能导致不同的决定。
角色和提示词示例

总体结论
这篇论文提出了AGENTREVIEW,第一个基于LLM的同行评审模拟框架,解决了同行评审过程中的多重潜在因素和数据隐私问题。研究揭示了社会影响力、利他主义疲劳、群体思维、权威偏见、锚定偏见等社会学理论在同行评审中的作用。AGENTREVIEW为未来设计更公平、透明的同行评审机制提供了有价值的见解。
论文评价
优点与创新
- 创新性框架:AGENTREVIEW是第一个利用大型语言模型(LLMs)和代理建模来模拟同行评审过程的框架。
- 综合数据集:通过模拟生成了超过53,800篇评审文档,包括超过10,000篇评审和反驳,支持未来对学术同行评审过程的分析。
- 新颖见解:研究揭示了几项重大发现,这些发现与社会学理论相一致,支持未来的研究。
- 多变量分析:AGENTREVIEW能够系统地探索和分离同行评审过程中的多个变量,揭示了审稿人偏见、社会影响力、利他主义疲劳、群体思维等多种因素的影响。
- 隐私保护:通过模拟生成数据,避免了使用真实的审稿人数据,保护了审稿人的隐私。
- 灵活性:框架设计灵活,支持探索替代的审稿人特征和更复杂的评审过程。
不足与反思
- 动态实验结果调整:AGENTREVIEW无法在审稿人-作者讨论阶段(第II阶段)动态地根据审稿人的评论调整实验结果,因为LLMs缺乏生成新实证数据的能力。
- 单一变量分析:尽管分析了同行评审过程的多个单独变量,如审稿人的承诺、意图和知识水平,但现实中的同行评审涉及多个相互作用的维度。
- 直接比较:没有直接将模拟结果与实际同行评审结果进行比较,由于人类审稿人特征的广泛变异性(如承诺、意图和知识水平),建立一致的基线进行比较具有挑战性。
- 模型能力限制:LLMs在生成评审时仍然存在伦理问题,尽管LLM生成的评审可以提供有价值的反馈,但强烈建议不建议在实际同行评审过程中将其作为人类审稿人的替代品。
关键问题及回答
问题1:AGENTREVIEW框架如何设计评审人、作者和领域主席(AC)三个角色的交互方式?
在AGENTREVIEW框架中,评审人、作者和领域主席(AC)三个角色通过一系列结构化步骤进行交互。具体流程如下:
- 评审人评估:每个评审人独立评估稿件,生成包含四个部分(重要性与创新性、接受理由、拒绝理由和改进建议)的评论。
- 作者-评审人讨论:作者在初始评论后提供反驳文件,回应评审人的意见。
- 评审人-AC讨论:领域主席(AC)发起讨论,要求评审人重新考虑初始评分,并提供更新后的评论。
- 元评审编写:AC综合讨论、反馈和自己的观察,编写元评审。
- 论文决定:AC审查所有元评审,做出接受或拒绝的决定。
每个角色的特征(如知识水平、责任感、意图等)通过提示和固定特征输入系统,确保模拟的评审过程符合现实情况。
问题2:AGENTREVIEW框架在实验设计中如何处理数据选择和基线设置?
- 数据收集:从OpenReview API检索2020-2023年间ICLR的论文数据,涵盖口头报告、聚焦报告、海报和拒绝四类。
- 样本选择:采用分层抽样技术从每类论文中抽取样本,最终得到350篇拒绝论文、125篇海报、29篇聚焦报告和19篇口头报告。
- 参数配置:在实验中,逐步替换正常评审人为负责任或不负责任的评审人,分析其对评审结果的影响。
为了确保实验的一致性和可重复性,建立一个没有特定LLM代理特征的基线设置。这个基线设置用于测量单个变量变化的影响,确保实验结果的可靠性。
问题3:AGENTREVIEW框架的研究发现有哪些重要的社会学理论在同行评审中的作用?
- 社会影响力:评审人在反驳后通常会调整评分以与同伴保持一致,导致评分的标准差显著下降。
- 利他主义疲劳和同伴效应:一个不负责的评审人可以导致所有评审人的承诺显著下降。
- 群体思维和回音室效应:有偏见的评审人通过互动放大彼此的负面意见,导致评分下降。
- 权威偏见和晕轮效应:评审人倾向于认为知名作者的稿件更准确,当所有评审人知道作者身份的比例为10%时,决策变化显著。
- 锚定偏见:反驳阶段对最终结果的影响较小,可能是由于评审人过于依赖初步印象。
这些发现揭示了社会学理论在同行评审过程中的重要作用,并为改进同行评审机制提供了有价值的见解。
思维导图

参考文献
- AI4S—使用GPT-4撰写生物医学科学综述文章的初步评估研究
- 哈佛医学院将生成式人工智能纳入课程和临床实践,以培训下一代医生
- 斯坦福&哈佛医学院 – MMedAgent,一个用于医疗领域的多模态医疗AI智能体
-
喜讯|柯基数据中标两个“大模型+医学”国自然面上项目 - 哈佛医学院&辉瑞推出基于知识图谱的复杂医学问答智能体MedAI
- 通过知识图谱自动生成和丰富加速医学知识发现 – 哈佛大学等
-
医疗保健和医学领域的大模型综述 – 斯坦福&加州大学 -
医学GraphRAG:通过知识图谱检索增强实现安全医疗大语言模型 – 牛津大学最新论文 -
消除幻觉的知识图谱增强医学大模型 – “Nature”NPJ数字医学杂志 -
Almanac: 一种用于临床医学的检索增强RAG大语言模型(2023vs2024版) - “大模型+知识图谱”双轮驱动的医药数智化转型新范式-OpenKG TOC专家谈
- 医学AI专家Anthropic CEO万字长文预测人工智能将消除癌症、人类寿命翻倍,世界变得更美好
- 医疗保健和医学领域的大模型综述 – 斯坦福&加州大学
- OpenAI o1模型的医学初步研究:我们离人工智能医生更近了吗?
- 智慧升级!医学知识助手“e晓智”全新升级,探索学术无限可能丨吉智探秘
- Nature杂志 – 针对生物医学研究和医疗保健的生成式大语言模型研究
- MEDCO:一种颠覆医学教育的多智能体Copilot