
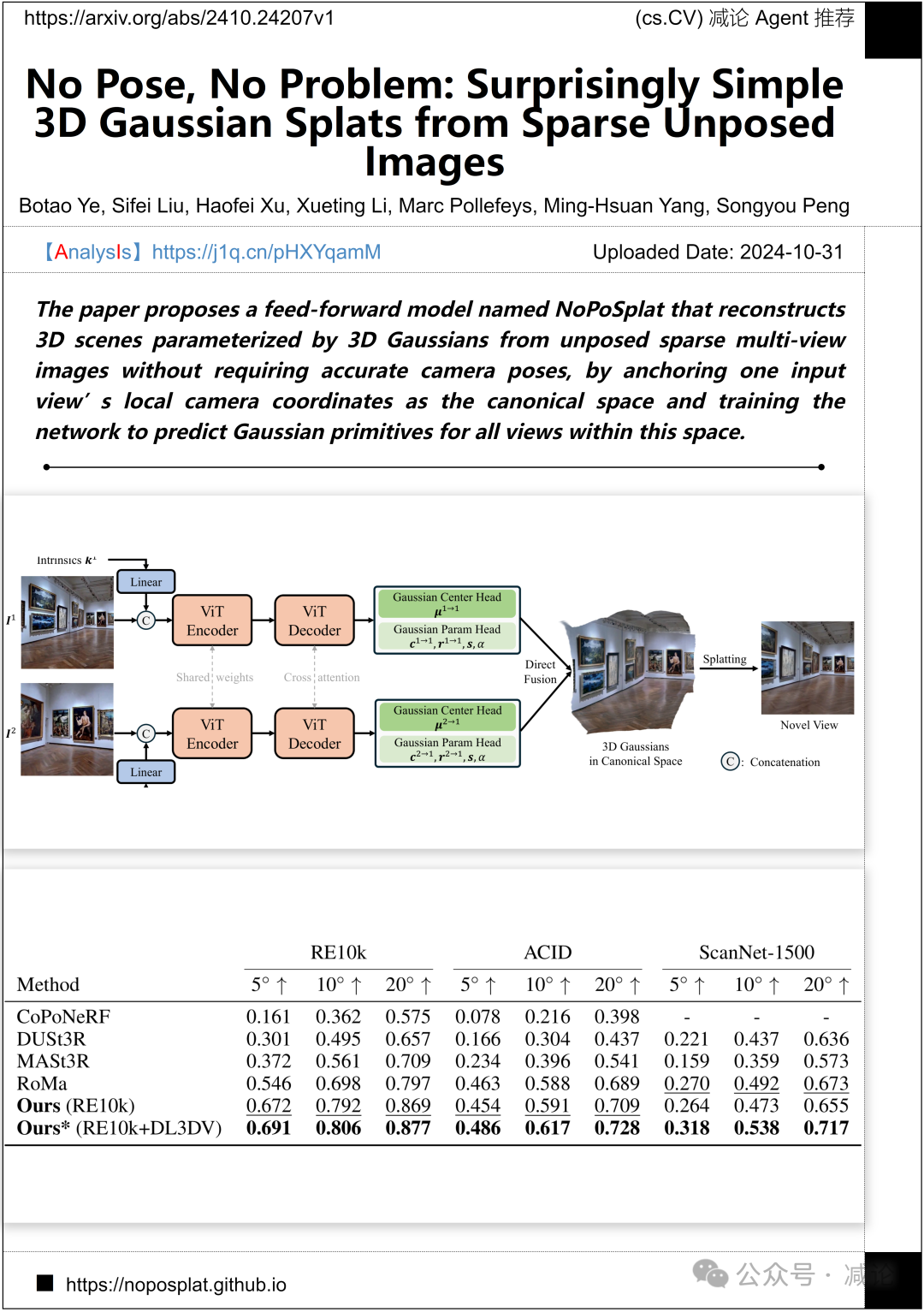

英伟达, 苏黎世联邦理工学院, 加州大学默瑟德的研究团队提出了一个名为NoPoSplat的前馈模型,该模型能够从未定位的稀疏多视图图像中重建由3D高斯参数化的3D场景,而无需准确的相机姿势。该模型通过将一个输入视图的局部相机坐标作为规范空间锚定,并训练网络以预测该空间内所有视图的高斯基元。
【Bohr精读】
https://j1q.cn/pHXYqamM
【arXiv链接】
http://arxiv.org/abs/2410.24207v1
【代码地址】
https://noposplat.github.io

香港理工大學、亞馬遜、南方科技大學的研究团队提出了一个名为DEcomposed MOtion (DEMO)的框架,通过将文本编码和条件分解为内容和动作组件,引入文本–动作和视频–动作监督,以增强文本到视频生成中的动作合成。
【Bohr精读】
https://j1q.cn/NUDBgrfm
【arXiv链接】
http://arxiv.org/abs/2410.24219v1
【代码地址】
https://PR-Ryan.github.io/DEMO-project/

西安电子科技大学、重庆邮电大学和新加坡国立大学的研究团队推出了一项名为Change Detection Question Answering and Grounding (CDQAG)的新任务,旨在扩展传统的遥感变化检测。他们构建了一个新的基准数据集QAG-360K,并提出了一个名为VisTA的基线方法,通过提供可解释的文本答案和直观的视觉证据来统一问答和定位。
【Bohr精读】
https://j1q.cn/9PrQOag2
【arXiv链接】
http://arxiv.org/abs/2410.23828v1
【代码地址】
https://github.com/like413/VisTA

佐治亚理工学院和斯坦福大学的研究团队提出了EgoMimic框架。该框架利用Project Aria眼镜捕获人类数据,采用低成本双手机器人设置、跨领域对齐技术和统一的策略学习架构,实现了从人类自我中心视频和远程操作机器人数据的协同训练。
【Bohr精读】
https://j1q.cn/vZc3MKgN
【arXiv链接】
http://arxiv.org/abs/2410.24221v1
【代码地址】
https://egomimic.github.io/

上海启智研究院上海人工智能实验室团队介绍了ImOV3D框架,该框架通过利用2D图像并创建伪多模态表示来解决开放词汇3D物体检测中标注的3D数据稀缺问题,从而弥合2D图像和D点云之间的模态差距。
【Bohr精读】
https://j1q.cn/Wr3RViS9
【arXiv链接】
http://arxiv.org/abs/2410.24001v1
【代码地址】
https://github.com/yangtiming/ImOV3D
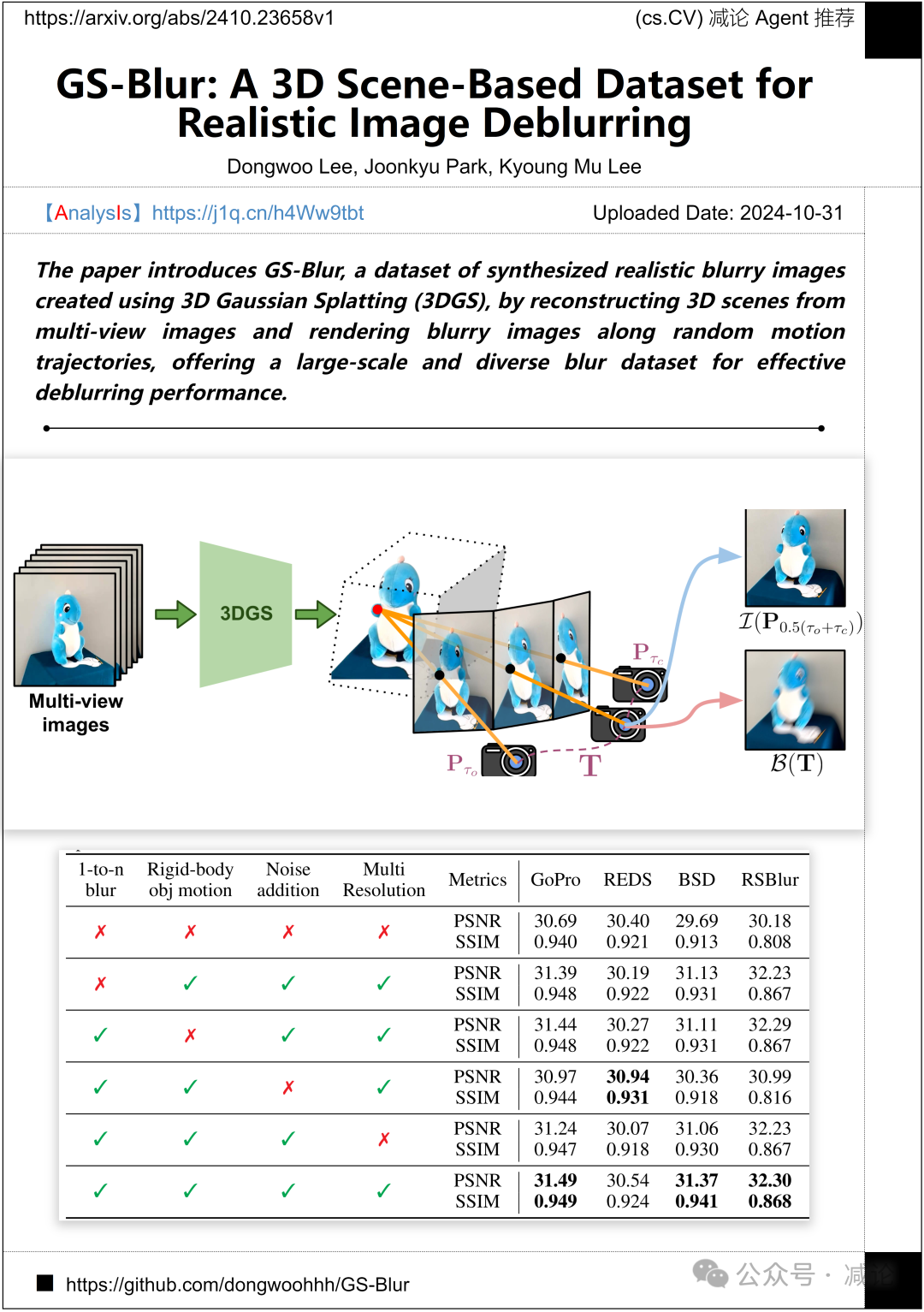
首尔国立大学的研究团队介绍了GS-Blur,这是一个使用3D高斯喷溅(3DGS)创建的合成逼真模糊图像数据集,通过从多视图图像重建3D场景并沿着随机运动轨迹渲染模糊图像,为有效去模糊性能提供了大规模和多样化的模糊数据集。
【Bohr精读】
https://j1q.cn/h4Ww9tbt
【arXiv链接】
http://arxiv.org/abs/2410.23658v1
【代码地址】
https://github.com/dongwoohhh/GS-Blur
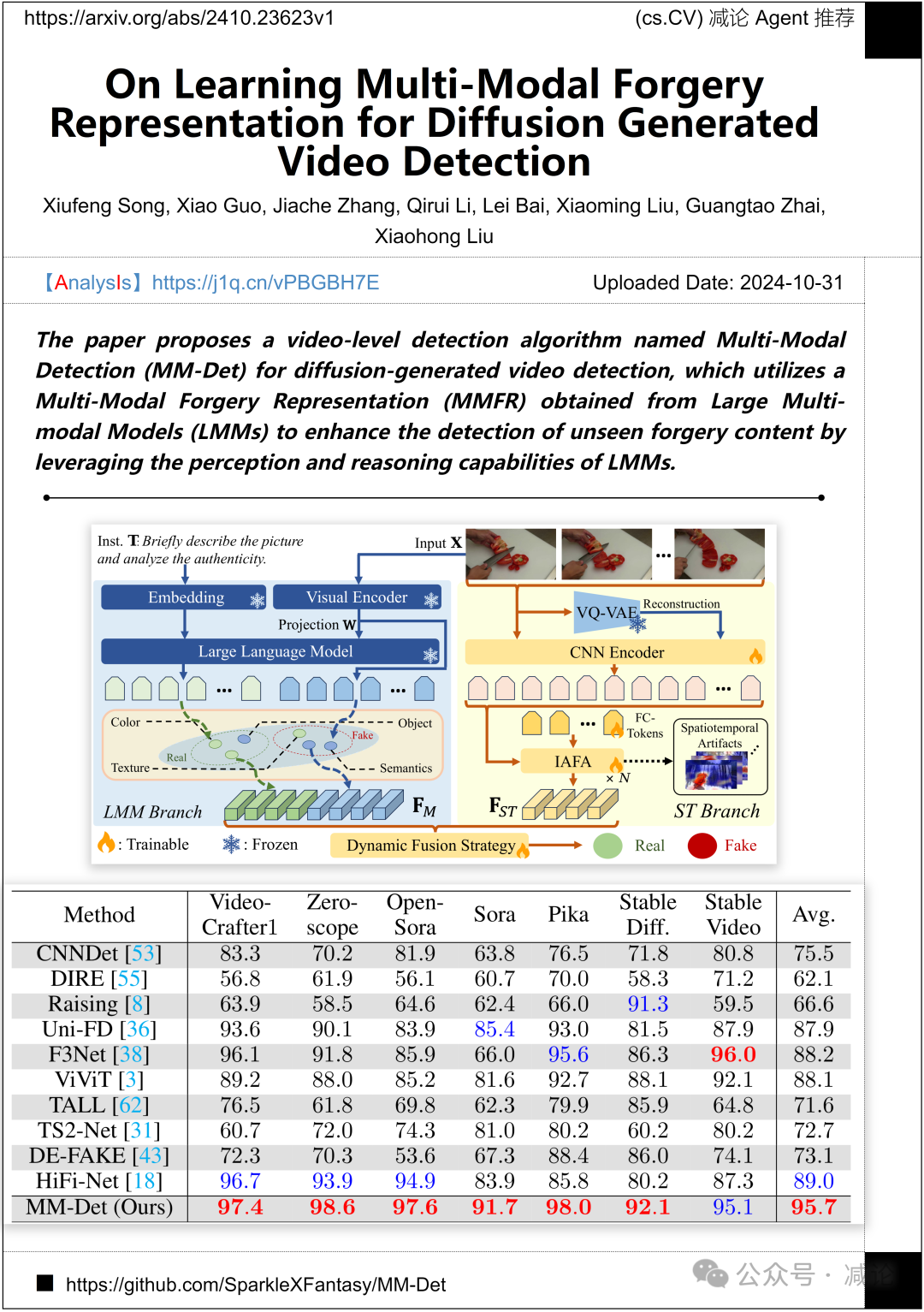
上海交通大学、密歇根州立大学以及上海人工智能实验室的研究团队提出了一种名为多模态检测(MM-Det)的视频级检测算法。该算法利用大型多模态模型(LMMs)获得的多模态伪造表示(MMFR)来增强对未见伪造内容的检测,通过利用LMMs的感知和推理能力。
【Bohr精读】
https://j1q.cn/vPBGBH7E
【arXiv链接】
http://arxiv.org/abs/2410.23623v1
【代码地址】
https://github.com/SparkleXFantasy/MM-Det

康奈尔大学和哥伦比亚大学的研究团队介绍了AllClear,这是卫星图像中用于云去除的最大公共数据集。该数据集包括分布在全球的23,742个感兴趣区域,涵盖多样化的土地利用模式,其中包括来自Sentinel-2、Landsat 8/9和Sentinel-1的400万张图像。此外,AllClear还提供了云掩模和土地覆盖地图等辅助数据,旨在促进更好的云去除结果。
【Bohr精读】
https://j1q.cn/Bk4QKAuQ
【arXiv链接】
http://arxiv.org/abs/2410.23891v1
【代码地址】
https://allclear.cs.cornell.edu, https://github.com/Zhou-Hangyu/allclear

北京大学、约翰霍普金斯大学和百度联合提出了低秩专家混合(MoLE)方法,该方法将在特定的面部和手部特写数据集上训练的低秩模块作为专家集成到专家混合框架中,以增强扩散模型的人类中心图像生成能力。
【Bohr精读】
https://j1q.cn/lgVKgpKW
【arXiv链接】
http://arxiv.org/abs/2410.23332v1
【代码地址】
https://sites.google.com/view/mole4diffuser/
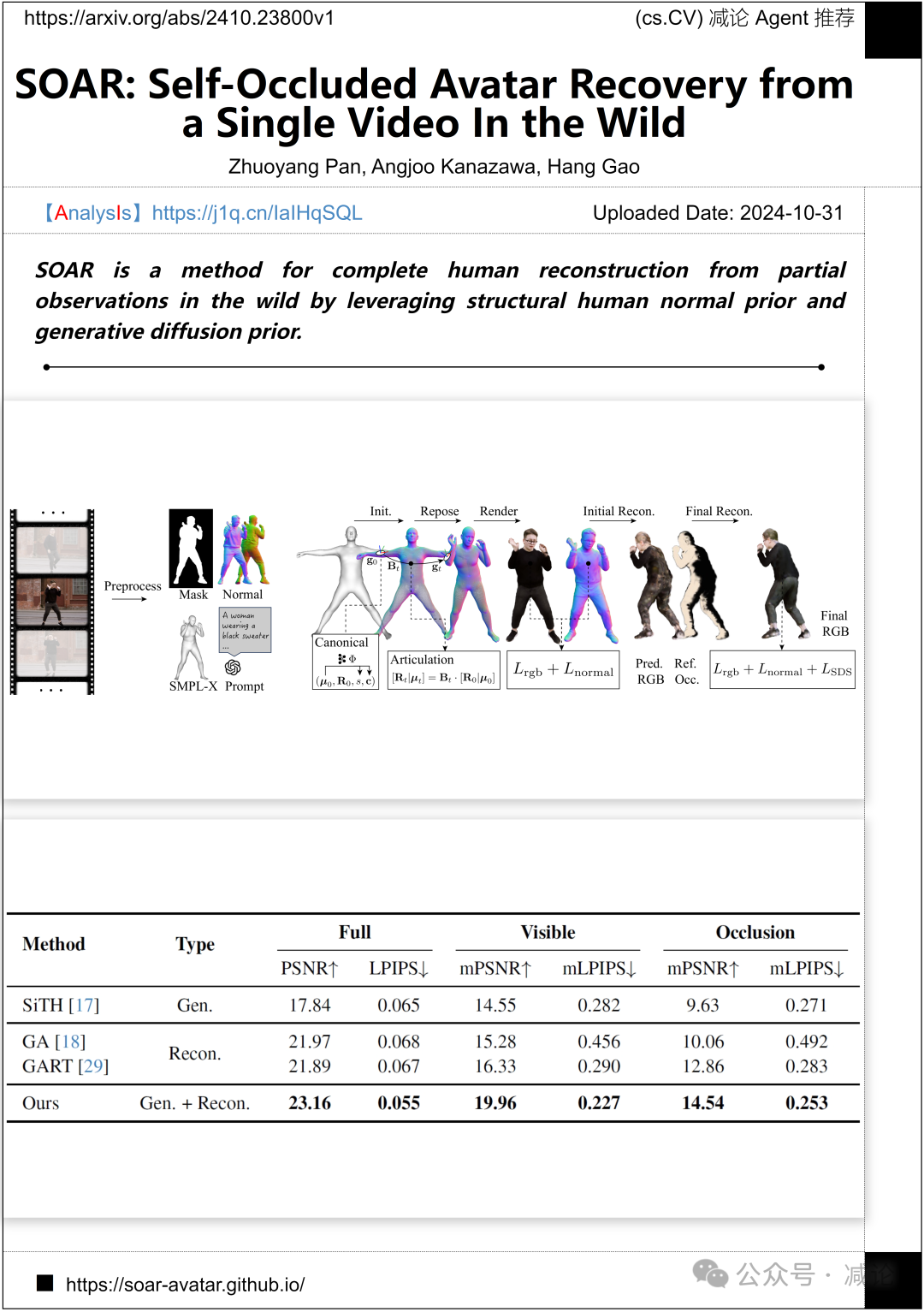
加州大学伯克利分校和上海科技大学的研究团队提出了SOAR方法,这是一种利用结构化人类正常先验和生成扩散先验,在野外从部分观测中完全重建人类的方法。
【Bohr精读】
https://j1q.cn/IaIHqSQL
【arXiv链接】
http://arxiv.org/abs/2410.23800v1
【代码地址】
https://soar-avatar.github.io/
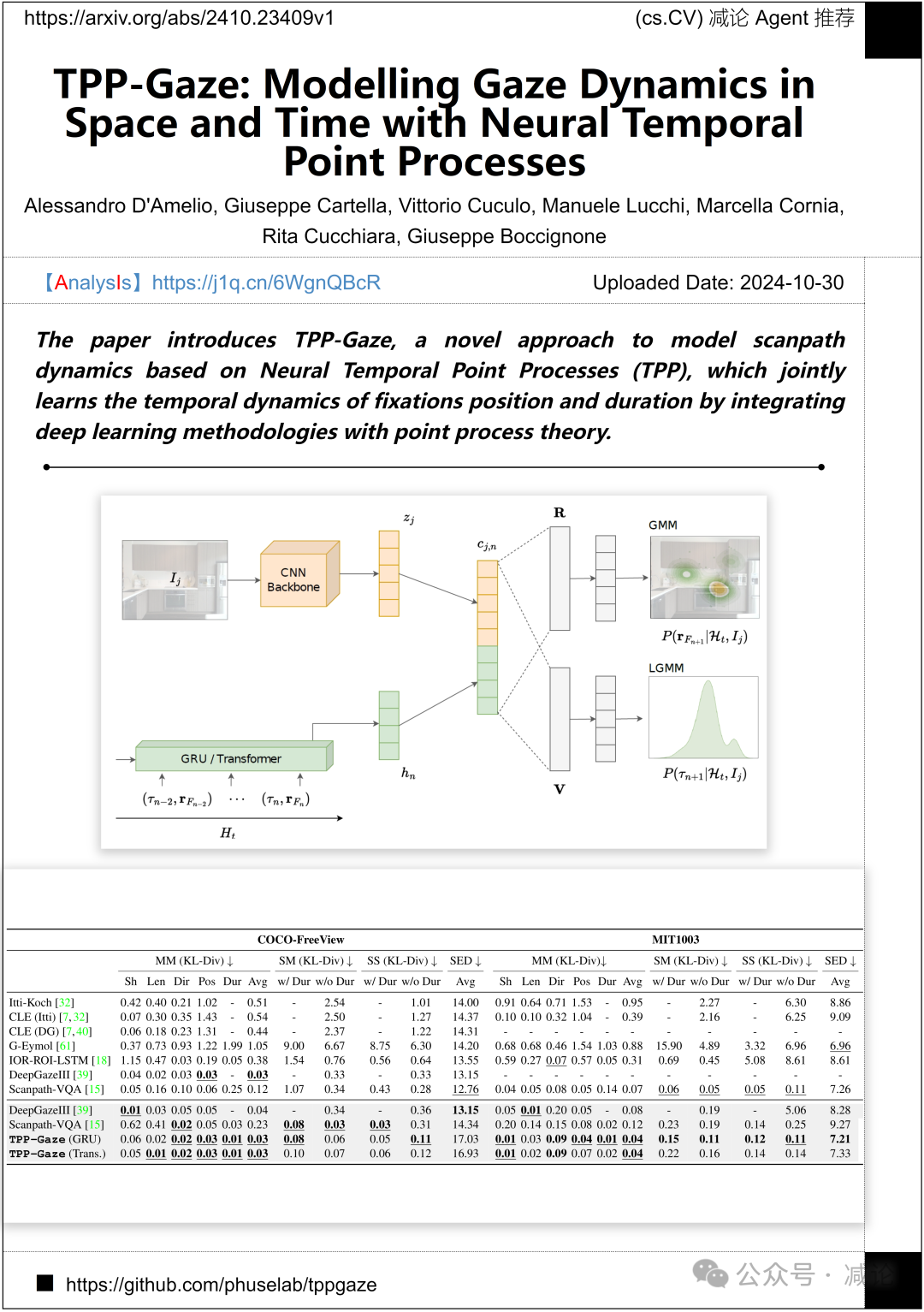
米兰大学和莫德纳和雷焦艾米利亚大学的研究团队提出了TPP-Gaze,一种基于神经时间点过程(TPP)的模型扫视路径动态的新方法,通过将深度学习方法与点过程理论相结合,共同学习注视位置和持续时间的时间动态。
【Bohr精读】
https://j1q.cn/6WgnQBcR
【arXiv链接】
http://arxiv.org/abs/2410.23409v1
【代码地址】
https://github.com/phuselab/tppgaze
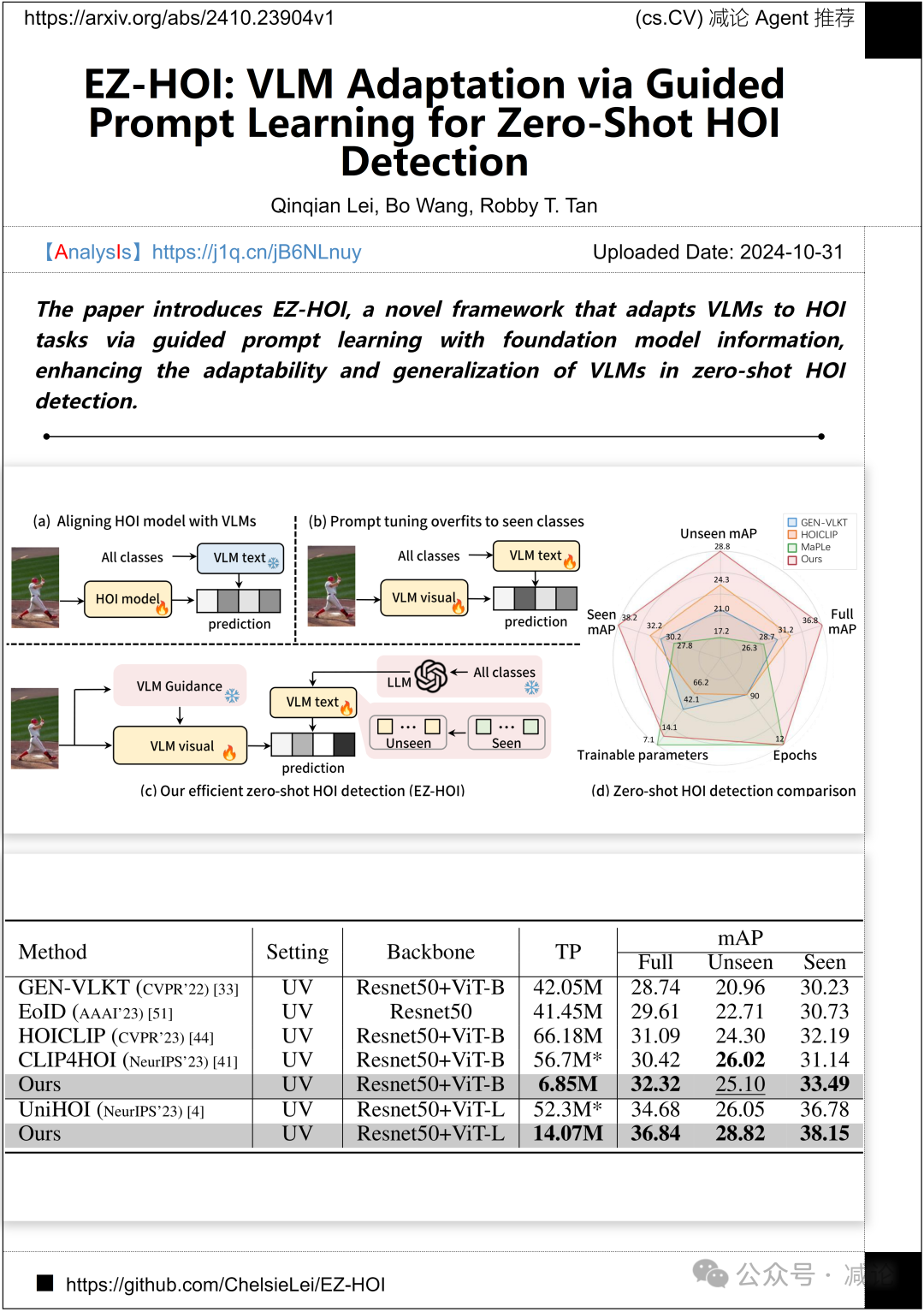
新加坡国立大学、密西西比大学和华硕智能云服务团队推出了一篇关于EZ-HOI框架的学术论文。该论文介绍了EZ-HOI,这是一个新颖的框架,通过引导提示学习基础模型信息,将VLMs调整到HOI任务中,增强了VLMs在零样本HOI检测中的适应性和泛化能力。
【Bohr精读】
https://j1q.cn/jB6NLnuy
【arXiv链接】
http://arxiv.org/abs/2410.23904v1
【代码地址】
https://github.com/ChelsieLei/EZ-HOI
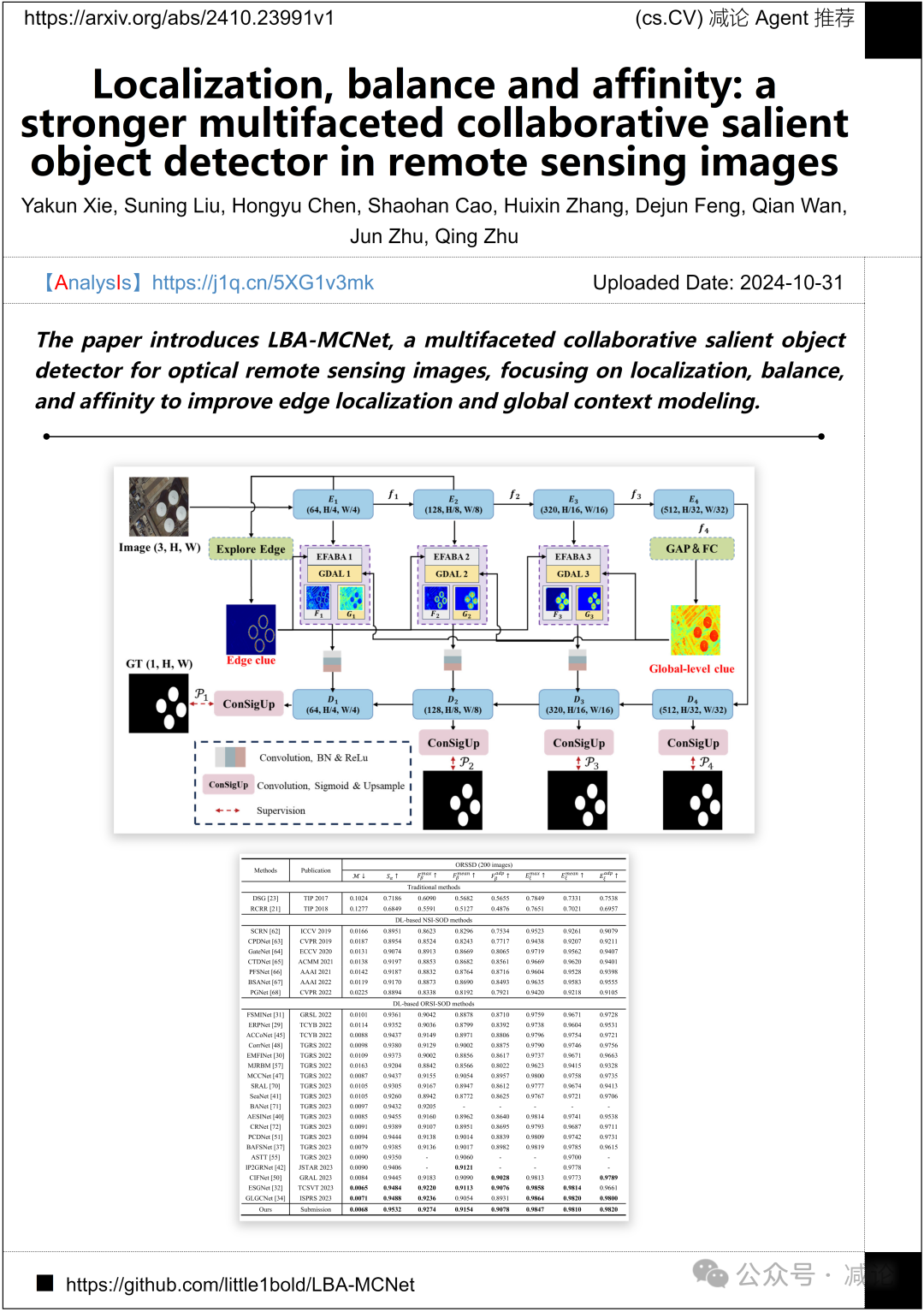
西南交通大学和成都师范大学的研究团队提出了LBA-MCNet,这是一种多方面协作的显著目标检测器,用于光学遥感图像。该论文侧重于定位、平衡和亲和力,旨在改善边缘定位和全局上下文建模。
【Bohr精读】
https://j1q.cn/5XG1v3mk
【arXiv链接】
http://arxiv.org/abs/2410.23991v1
【代码地址】
https://github.com/little1bold/LBA-MCNet
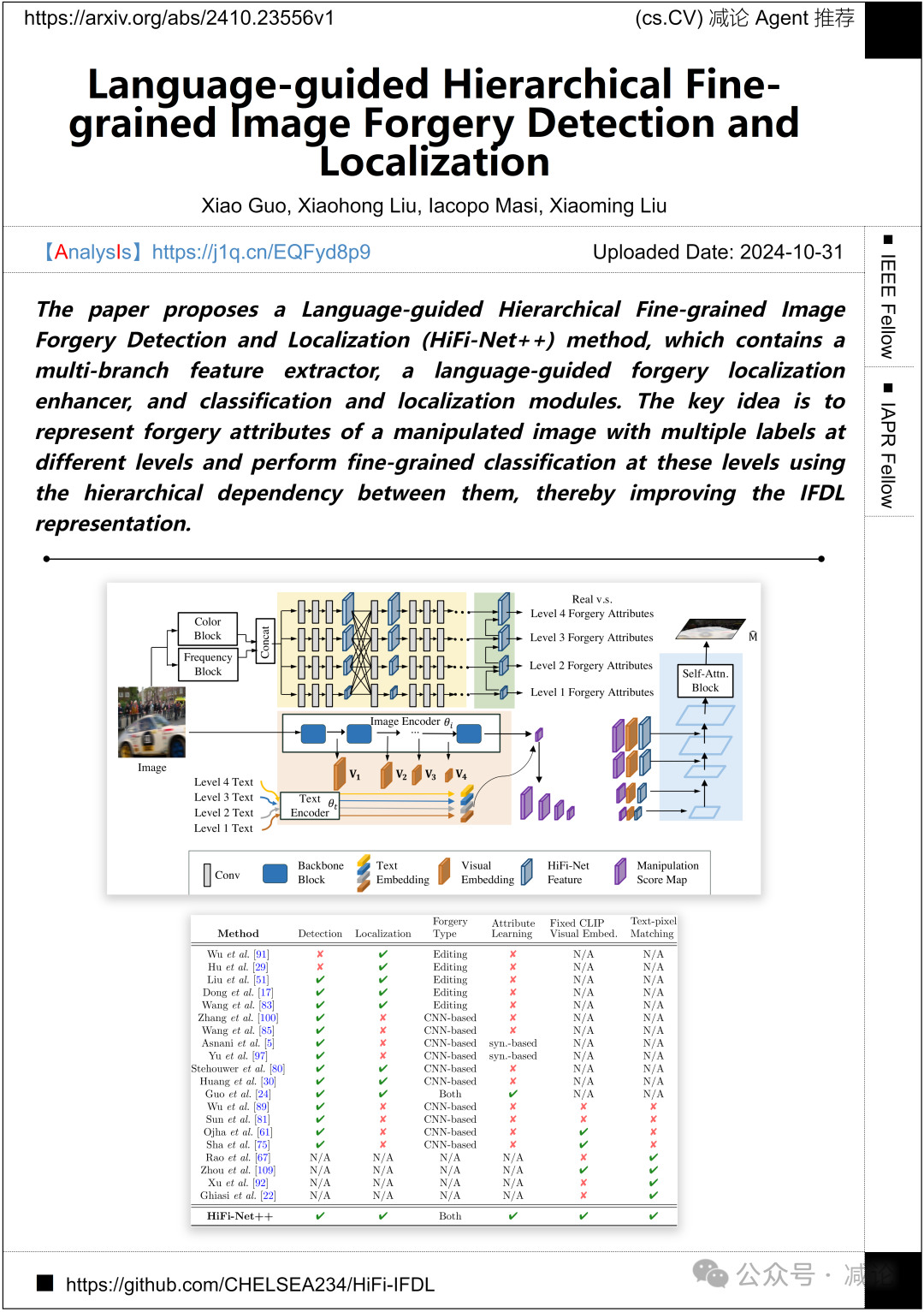
密歇根州立大学、上海交通大学和罗马大学的作者团队介绍了一种语言引导的分层细粒度图像伪造检测和定位(HiFi-Net++)方法。该方法包含多分支特征提取器、语言引导的伪造定位增强器以及分类和定位模块。其关键思想是利用不同级别的多个标签表示操纵图像的伪造属性,并通过这些级别之间的分层依赖性进行细粒度分类,从而改进IFDL表示。
【Bohr精读】
https://j1q.cn/EQFyd8p9
【arXiv链接】
http://arxiv.org/abs/2410.23556v1
【代码地址】
https://github.com/CHELSEA234/HiFi-IFDL
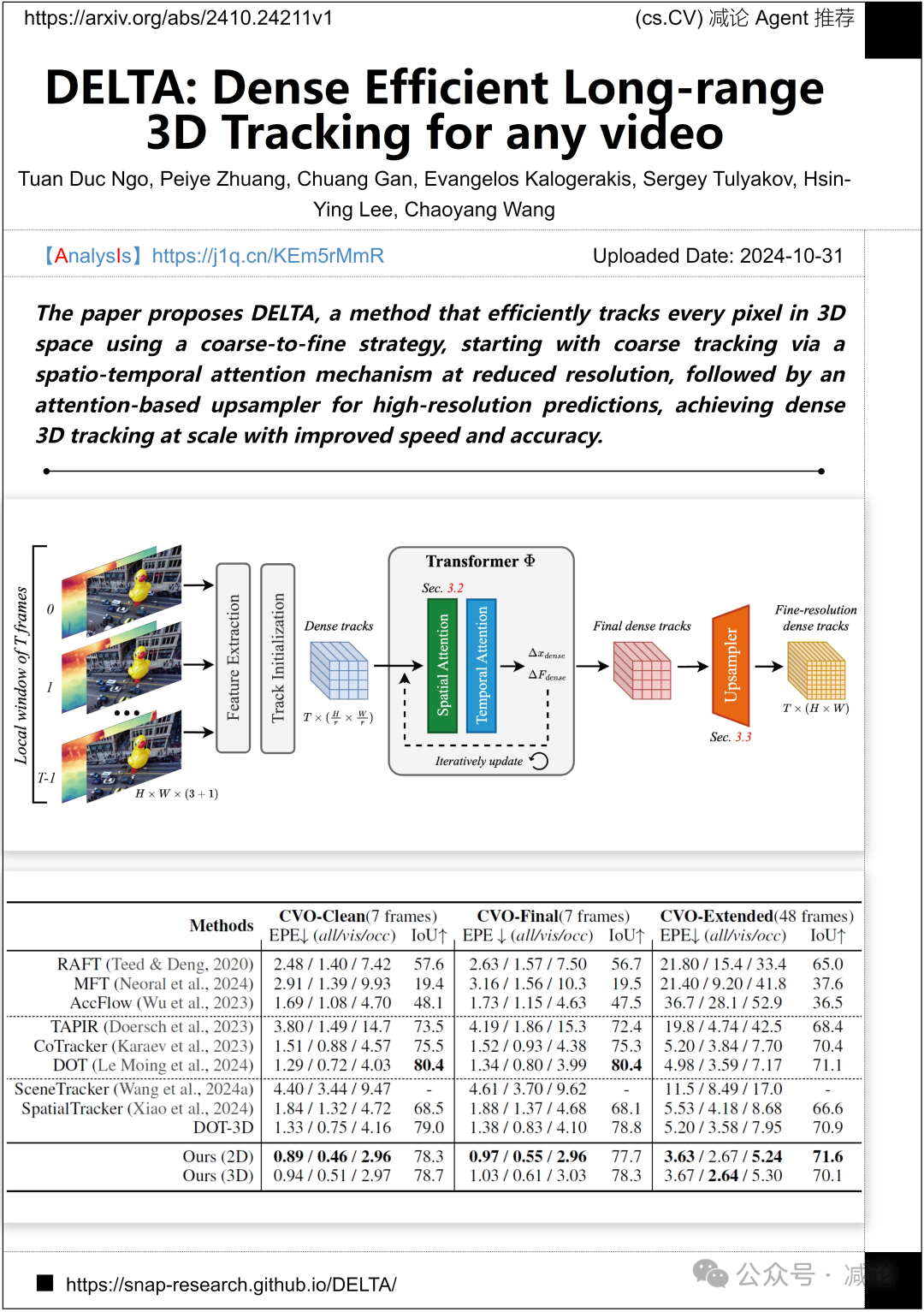
马萨诸塞大学阿默斯特分校和Snap公司的研究团队提出了DELTA方法,该方法通过粗到精的策略,利用空间–时间注意机制在降低分辨率下进行粗跟踪,然后通过基于注意力的上采样器进行高分辨率预测,实现了在规模上具有改进速度和准确性的密集3D跟踪。
【Bohr精读】
https://j1q.cn/KEm5rMmR
【arXiv链接】
http://arxiv.org/abs/2410.24211v1
【代码地址】
https://snap-research.github.io/DELTA/

香港浸会大学,NVIDIA人工智能技术中心提出了一种针对3D高斯喷溅(3DGS)模型的不确定性感知水印方法,该方法通过约束模型参数的扰动实现对版权保护的隐形水印,从而允许在各种失真下可靠地提取版权信息,包括从3D高斯和2D渲染图像中提取。
【Bohr精读】
https://j1q.cn/QDVdwUhf
【arXiv链接】
http://arxiv.org/abs/2410.23718v1
【代码地址】
https://kevinhuangxf.github.io/GaussianMarker