
大家好,今儿和大家聊聊谱聚类~
谱聚类(Spectral Clustering)是一种常用的聚类算法,特别适用于处理非球形、非线性分布的数据。简单来说,谱聚类利用数据点之间的相似性或连接关系,先将数据转换到一个“图”(Graph)的形式,然后在这个图上操作,最终实现数据的分组。
几点非常重要:
-
相似性矩阵:设想你有一堆数据点(例如一群同学),我们首先需要知道哪些同学关系更近,比如谁和谁更像好朋友。所以,我们给每对同学打一个分数,表示他们有多亲近,这就形成了一个“相似性矩阵”。分数越高,表示两个人关系越密切,越可能属于同一个小组。
-
构建图:接下来,我们可以想象每个同学是一个点,如果两个同学的相似度很高(关系很密切),我们就给他们之间画一条边,形成一个图。点就是同学,边表示他们的关系。通过这个图,我们可以看到有些同学联系很紧密,而有些则很疏远。
-
切割图:谱聚类的关键步骤是如何把图切开,分成几个部分,使得每个部分里的同学关系更密切,而不同部分的同学之间关系较疏远。这时候,我们利用数学中的“谱分解”技术,把这个图分割开。换句话说,我们利用图的结构信息,找到一个最好的分割方式。
-
聚类结果:最后,根据切割的结果,我们可以把同学们分成几个小组。每个小组里的同学关系密切,他们是“朋友”,而不同小组之间的联系较少。
举例说明:
假设你有 8 个学生,你知道他们的相似度,比如说:
-
学生 A 和 B 很像(相似度 0.9) -
学生 B 和 C 也很像(相似度 0.8) -
但是 A 和 D 完全不像(相似度 0.1) -
C 和 E 关系一般(相似度 0.5)
通过这种相似度,我们构建一个图:A-B-C 关系比较紧密,D-E-F 关系较紧密,G-H 是另外一组。
谱聚类会根据这个图来切割,最终可能会把 A、B、C 分成一组,D、E、F 分成一组,G 和 H 形成另一组,因为它们之间的关系紧密。
谱聚类算法不像一些简单的算法(如 K-Means)那样依赖数据的形状,而是通过计算数据点之间的相似性,构建图来找到自然的分组。对于复杂分布的数据,它往往能给出更合理的聚类结果。
下面,咱们从原理和案例分别和大家聊聊~
数学推导步骤:
1. 相似性矩阵:
给定数据集 ,我们计算所有数据点之间的相似性。常用的相似性度量方法是高斯核函数:
这里 是相似性矩阵, 是两个数据点 和 之间的欧氏距离, 是控制相似性的尺度参数。
2. 度矩阵:
度矩阵 是一个对角矩阵,其元素为相似性矩阵每一行的和:
3. 拉普拉斯矩阵:
拉普拉斯矩阵 定义为:
或者,标准化的拉普拉斯矩阵为:
4. 特征分解:
我们计算标准化拉普拉斯矩阵 的特征值和特征向量。将前 个最小特征值对应的特征向量取出,构成矩阵 。
5. 聚类:
对 的每一行进行归一化,然后在新的特征空间上进行聚类,通常使用 K-Means 进行最后的分组。
Python代码实现
import numpy as np
import matplotlib.pyplot as plt
from scipy.spatial.distance import pdist, squareform
from scipy.linalg import eigh
from sklearn.cluster import KMeans
# 生成虚拟数据集
np.random.seed(0)
n_samples = 500
data1 = np.random.randn(n_samples // 2, 2) + [2, 2]
data2 = np.random.randn(n_samples // 2, 2) + [-2, -2]
X = np.vstack([data1, data2])
# 高斯核相似性矩阵
def gaussian_similarity(X, sigma=1.0):
pairwise_dists = squareform(pdist(X, 'sqeuclidean'))
return np.exp(-pairwise_dists / (2 * sigma ** 2))
# 计算相似性矩阵
S = gaussian_similarity(X, sigma=1.5)
# 度矩阵 D
D = np.diag(np.sum(S, axis=1))
# 拉普拉斯矩阵 L
L = D - S
# 标准化拉普拉斯矩阵
D_inv_sqrt = np.diag(1.0 / np.sqrt(np.diag(D)))
L_sym = np.eye(len(S)) - D_inv_sqrt @ S @ D_inv_sqrt
# 特征值分解
eigvals, eigvecs = eigh(L_sym)
# 取前两个最小特征值对应的特征向量
k = 2
U = eigvecs[:, :k]
# 对 U 的每一行进行归一化
U_normalized = U / np.linalg.norm(U, axis=1, keepdims=True)
# 在新的特征空间上用 KMeans 聚类
kmeans = KMeans(n_clusters=2)
labels = kmeans.fit_predict(U_normalized)
# 绘制图形
plt.figure(figsize=(16, 12))
# 原始数据集
plt.subplot(2, 2, 1)
plt.scatter(X[:, 0], X[:, 1], c='blue', s=50, cmap='viridis')
plt.title("Original Data", fontsize=15)
# 相似性矩阵 S 的热力图
plt.subplot(2, 2, 2)
plt.imshow(S, cmap='hot', interpolation='nearest')
plt.title("Similarity Matrix (S)", fontsize=15)
# 拉普拉斯矩阵的热力图
plt.subplot(2, 2, 3)
plt.imshow(L_sym, cmap='coolwarm', interpolation='nearest')
plt.title("Normalized Laplacian (L_sym)", fontsize=15)
# 聚类结果
plt.subplot(2, 2, 4)
plt.scatter(X[:, 0], X[:, 1], c=labels, s=50, cmap='viridis')
plt.title("Spectral Clustering Result", fontsize=15)
plt.tight_layout()
plt.show()
1. 生成虚拟数据集:创建两个分布不同的数据集,分别加了偏移量以模拟两类数据。
2. 相似性矩阵:使用高斯核计算相似性。
3. 度矩阵和拉普拉斯矩阵:根据相似性矩阵计算度矩阵和拉普拉斯矩阵。
4. 特征分解:对标准化拉普拉斯矩阵进行特征分解,提取出前两个最小的特征值对应的特征向量。
5. 聚类:对特征向量进行 KMeans 聚类,分成两类。
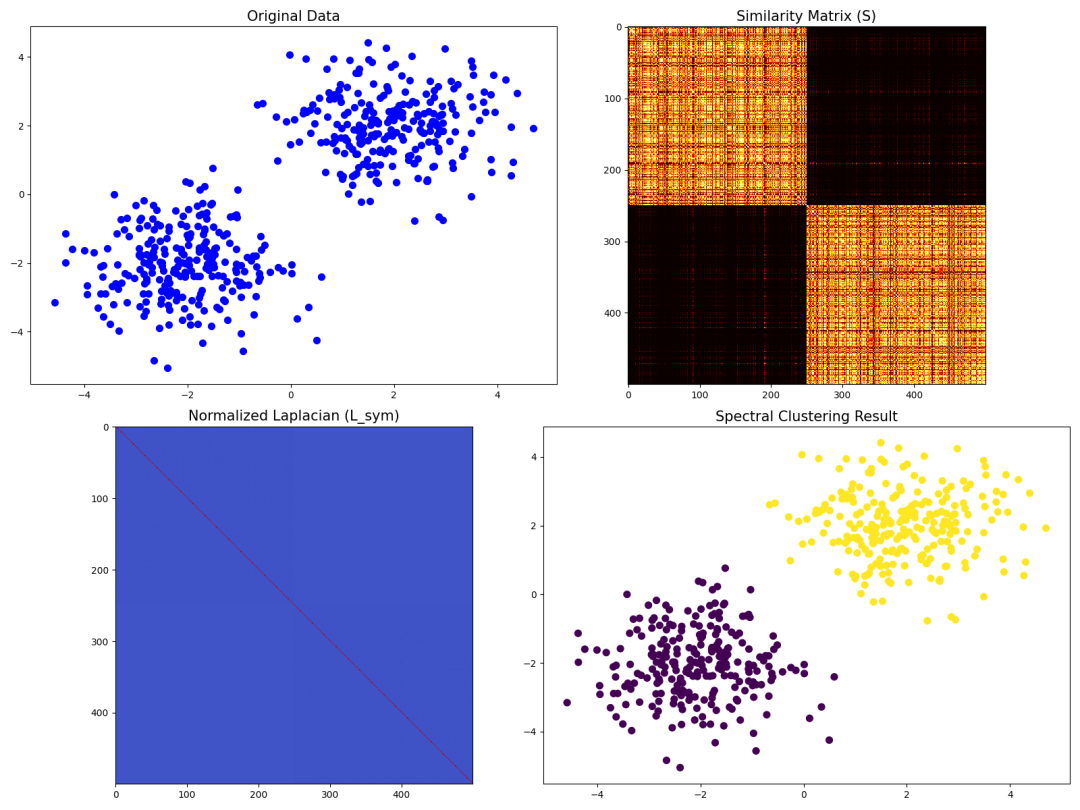

-
原始数据:展示了最初的数据点分布。 -
相似性矩阵:展示了数据点之间的相似性强弱。 -
标准化拉普拉斯矩阵:展示了用于谱聚类的核心矩阵结构。 -
聚类结果:展示了谱聚类的最终分组效果。
这样通过数学推导和图形分析,谱聚类的过程得以实现,并且可以直观地观察各个步骤的中间结果。
最后