


核心速览
本文介绍了MEDCO(Medical EDucation COpilots),一种基于多智能体框架的医疗教育Copilot副驾驶系统。
[2408.12496] MEDCO: Medical Education Copilots Based on A Multi-Agent Framework,https://arxiv.org/abs/2408.12496
研究者提出了一种基于多智能体框架的医学教育Copilot系统MEDCO,该系统通过模拟真实的医疗训练环境,帮助医学学生提高临床诊断和沟通能力,实验结果表明MEDCO能显著提升学生的诊断表现,并展现出类人的学习行为。
研究背景
- 研究问题:这篇文章要解决的问题是如何利用大型语言模型(LLMs)作为医学教育的副驾驶,模拟真实的医学训练环境,提升医学生在临床诊断和患者沟通方面的能力。
- 研究难点:该问题的研究难点包括:现有的AI辅助教育工具多为单一学习模式,无法模拟真实医学训练的多学科和互动特性;医学生需要掌握有效的提问技巧,这在现有工具中未能得到充分训练;医学是一门多学科学科,需要跨学科合作和同伴讨论。
- 相关工作:该问题的研究相关工作包括:ChatGPT在医学教育中的应用探索;单模态LLM代理在医学文本数据中的应用;以及多模态LLM代理在医学任务中的应用。
研究方法
这篇论文提出了MEDCO(Medical Education COpilots),一种基于多代理框架的副驾驶系统,用于解决医学教育中的上述问题。具体来说,
-
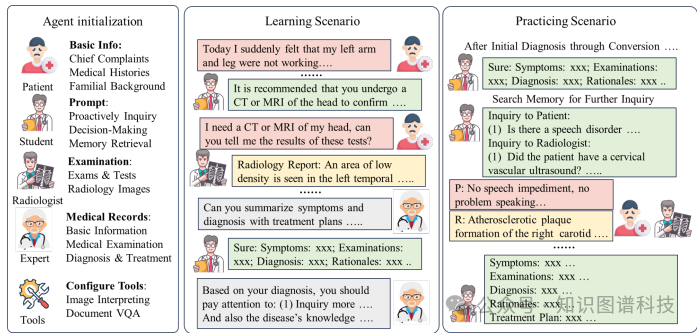
代理初始化:MEDCO框架目前包含四个角色:代理患者、代理放射科医生、代理医学生和代理医学专家。每个角色通过不同的提示(prompt)来初始化,分配相应的医学知识和角色功能。
-
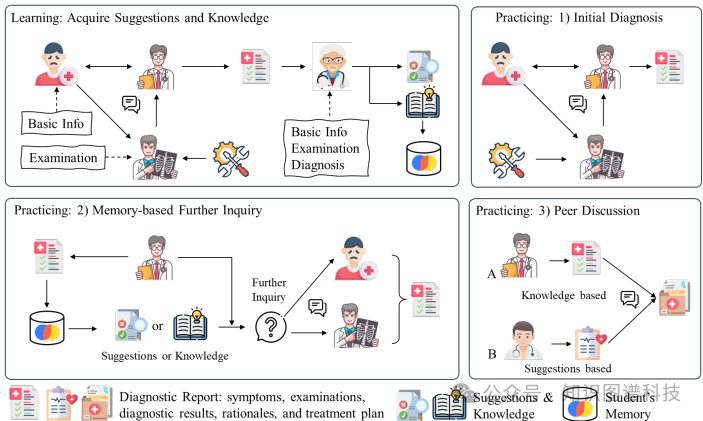
学习场景:在学习场景中,代理医学生通过与代理患者和代理放射科医生的互动,生成初步诊断报告。代理医学专家根据完整的医学记录评估报告,并提供反馈和建议。代理医学生将诊断建议和特定疾病知识整合到其记忆中。
-
实践场景:在实践场景中,代理医学生根据初始诊断,重新访问记忆中的知识或建议,提出进一步的问题以获得更准确的最终诊断。如果有两名代理医学生,他们可以讨论各自的诊断以提高结果。
实验设计
-
数据集:实验使用了MVME数据集,包含506个高质量的中文医学案例。数据集按科室分为训练集(259个案例)和测试集(247个案例)。为了验证框架的多模态能力,选择了16个神经学案例的完整测试集,并收集了相应的放射学图像或报告照片。
- 评估指标:实验使用了三种评估指标:
-
HDE(Holistic Diagnostic Evaluation):专家对学生报告的评分,包括症状、医学检查、诊断结果、诊断理由和治疗计划五个部分。
-
SEMA(Semantic Embedding-based Matching Assessment):基于语义嵌入的匹配评估,提取学生诊断和医学记录中的疾病实体,计算召回率、精确率、F1值等指标。
-
CASCADE(Coarse And Specific Code Assessment for Diagnostic Evaluation):粗粒度和细粒度级别的ICD-10编码评估,计算不同级别的诊断准确率。
-
实现细节:实验中,GPT-3.5扮演患者角色,Claude-3.5-Sonnet-20240620扮演放射科医生和医学专家角色。学生的记忆和ICD-10指标使用Chromadb和OpenAI嵌入进行高效存储和快速查询。设计了两个工具来解释放射学图像和报告照片。
结果与分析
-
代理学生的学习效果:经过学习场景的训练,代理学生的整体表现显著提高。具体来说,Claude3.5-Sonnet模型的得分最高,平均为2.283,而学生(GPT-3.5)的平均得分为1.965。通过回忆学习和回顾建议,学生的得分分别提高到2.169和2.122。同伴讨论得分最高,为2.299。
-
ICD-10指标:SEMA指标显示,通过同伴讨论,学生的召回率和F1值显著提高,分别达到29.72和36.04,超过了未训练的学生(召回率17.95,F1值26.01)。Claude3.5-Sonnet的精确率最高,为55.13。CASCADE指标显示,学生在粗粒度和中等粒度级别的准确率显著提高,分别为46.67%和18.33%。
-
强模型学生的学习效果:对于使用强模型(如Claude3.5-Sonnet)的代理学生,MEDCO显著提高了其临床咨询和诊断能力。具体来说,未训练的学生得分为2.283,而使用回忆知识和建议的学生得分分别提高到2.586和2.693。同伴讨论得分最高,为2.686。
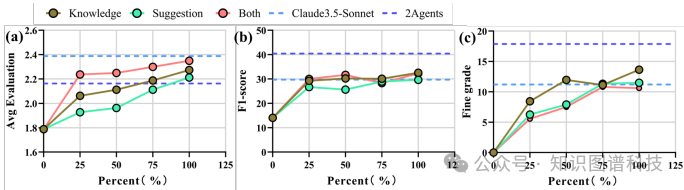
学习曲线:随着训练案例数量的增加,代理学生的学习曲线显示出一致的性能提升。即使在有限的训练样本下,学习也能显著提高精度和召回率。
-
多模态支持:多模态输入显著提高了代理学生的性能,特别是对于细粒度级别的诊断。具体来说,多模态输入使得Claude3.5-Sonnet的F1值接近2 Agents的基准。
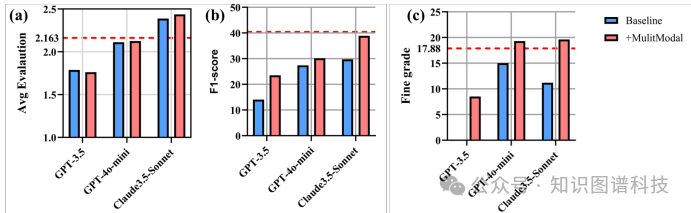
总体结论
这篇论文介绍了MEDCO,一种创新的多代理副驾驶系统,用于医学教育。MEDCO使医学生能够动态地与代理患者、专业医生和医学专家互动,学习各种疾病的诊断和治疗。研究表明,MEDCO可以有效地将通用模型适应于医学专业化,并且也可以用于实际学生,提供有针对性的反馈,模拟多样化的患者接触和多学科合作,增强学习体验。此外,这种AI驱动的副驾驶系统也有潜力应用于更广泛的教育领域。
论文评价
优点与创新
-
多代理框架:提出了MEDCO(Medical Education COpilots),一种基于多代理的协作系统,能够模拟真实的医学训练环境。
-
多模态交互:框架支持文本、医学影像和报告照片等多种模态的输入,增强了学习环境的沉浸感和实用性。
-
分层评估指标:引入了基于ICD-10的分层评估指标(HDE、SEMA、CASCADE),能够从粗粒度到细粒度全面评估诊断准确性。
-
人类样学习行为:实验结果表明,模拟的学生在学习过程中表现出类似人类的学习行为,随着学习的深入,性能逐渐提升。
-
跨学科协作:框架支持多学科协作,包括与患者的互动、与放射科医生的协作以及与医学专家的讨论,模拟了真实的医疗团队工作环境。
-
记忆机制:实现了记忆机制,能够存储和检索学习过程中的建议和案例知识,帮助学生巩固记忆和应用所学知识。
不足与反思
-
虚拟与现实差距:目前的学生角色仅由LLM模拟,与真实学生在学习能力上存在差距,MEDCO在实际医学教育中的应用效果需进一步验证。
-
数据集规模:当前使用的MVME数据集规模较小,未来需要更大规模的多模态协作数据集,以进一步提升系统的潜力。
-
反馈形式:目前学生仅能获得文本形式的反馈,未来工作可以扩展为包括医学影像示例等多模态反馈,以提高学生的诊断技能和知识面。
代理能力扩展:可以扩展代理医生的多部门协作能力,例如通过基础AI模型或专用AI模型辅助放射科医生进行图像分析和报告生成。
论文思维导图
关键问题及回答
问题1:MEDCO框架中的多智能体是如何初始化的?它们各自的角色是什么?
MEDCO框架目前包含三个智能体:代理患者、代理医学专家和代理放射科医生。每个智能体的角色和职责如下:
-
代理患者:模拟各种症状和健康条件,与学生学习互动,回答学生的问题,参与检查和表达担忧。
-
代理医学专家:评估学生的诊断并提供改进建议,总结病例特定的知识,帮助学生学习和提高。
-
代理放射科医生:模拟多科室合作,解释医学影像,提供放射科医生的专业意见和报告。
这些智能体通过特定的提示和医学信息被初始化,以便在不同的学习场景和实践场景中发挥作用。
问题2:MEDCO框架的学习场景和实践场景是如何设计的?它们在提升学生诊断能力方面有何不同?
学习场景:在学习场景中,代理学生通过与代理患者和代理放射科医生的互动生成诊断报告。具体步骤包括:
-
初始诊断:学生与患者和放射科医生互动,收集症状和检查结果,生成初步诊断报告。
-
评估:代理医学专家评估学生的诊断报告,提供反馈和建议,包括改进的诊断理由和相关疾病知识。
-
学习反馈:学生将诊断建议和病例特定知识整合到其记忆中,以便在未来的实践中应用。
实践场景:在实践场景中,学生在初始诊断后,可以回顾所学知识或建议,提出进一步的问题以进行更准确的最终诊断。具体步骤包括:
-
初始诊断:学生与患者和放射科医生互动,生成初步诊断报告。
-
回顾和学习:学生回顾所学知识或建议,提出进一步的问题以获取更多信息。
-
进一步诊断:学生根据额外的信息提出更细致的问题,进行最终的诊断。如果有两名学生,他们还可以讨论各自的诊断以提高结果。
这两种场景的设计旨在通过不同的互动和学习方式,提升学生的诊断能力和临床推理能力。学习场景注重知识和技能的积累,而实践场景则强调在实际病例中的应用和改进。
问题3:MEDCO框架在评估代理学生诊断能力方面使用了哪些具体的评估指标?这些指标如何反映学生的表现?
MEDCO框架使用了三种评估指标来评估代理学生的诊断能力:
-
HDE(整体诊断评估):专家对学生报告的评分,包括症状、医学检查、诊断结果、诊断理由和治疗计划五个方面。这个指标从定性角度评估学生的整体诊断过程。
-
SEMA(基于语义嵌入的匹配评估):提取学生诊断结果和医学记录中的疾病实体,计算召回率、精确率、F1值等指标。这个指标从定量角度评估学生在疾病实体识别和匹配方面的表现。
-
CASCADE(粗粒度和细粒度代码评估):根据ICD-10编码系统,在不同层次(粗粒度、中粒度、细粒度)上评估诊断准确性。这个指标从层次化角度评估学生在不同诊断精度上的表现。
这些指标综合反映了学生在诊断过程中的知识掌握程度、临床推理能力和细节处理能力。通过这些评估指标,可以全面了解代理学生在不同方面的表现,并指导其在未来的学习和实践中进行改进。
附录样例

参考文献
- 哈佛医学院将生成式人工智能纳入课程和临床实践,以培训下一代医生
- 斯坦福&哈佛医学院 – MMedAgent,一个用于医疗领域的多模态医疗AI智能体
-
喜讯|柯基数据中标两个“大模型+医学”国自然面上项目 - 哈佛医学院&辉瑞推出基于知识图谱的复杂医学问答智能体MedAI
- 通过知识图谱自动生成和丰富加速医学知识发现 – 哈佛大学等
-
医疗保健和医学领域的大模型综述 – 斯坦福&加州大学 -
医学GraphRAG:通过知识图谱检索增强实现安全医疗大语言模型 – 牛津大学最新论文 -
消除幻觉的知识图谱增强医学大模型 – “Nature”NPJ数字医学杂志 -
Almanac: 一种用于临床医学的检索增强RAG大语言模型(2023vs2024版) - “大模型+知识图谱”双轮驱动的医药数智化转型新范式-OpenKG TOC专家谈
- 医学AI专家Anthropic CEO万字长文预测人工智能将消除癌症、人类寿命翻倍,世界变得更美好
- 医疗保健和医学领域的大模型综述 – 斯坦福&加州大学
- OpenAI o1模型的医学初步研究:我们离人工智能医生更近了吗?
- AI4S—使用GPT-4撰写生物医学科学综述文章的初步评估研究
- 智慧升级!医学知识助手“e晓智”全新升级,探索学术无限可能丨吉智探秘
- Nature杂志 – 针对生物医学研究和医疗保健的生成式大语言模型研究