
2024年10月29日arXiv cs.CV发文量约191余篇,减论Agent通过算法为您推荐并自动化整理为卡片供您参考,预计为您节省87分钟浏览arXiv的时间。
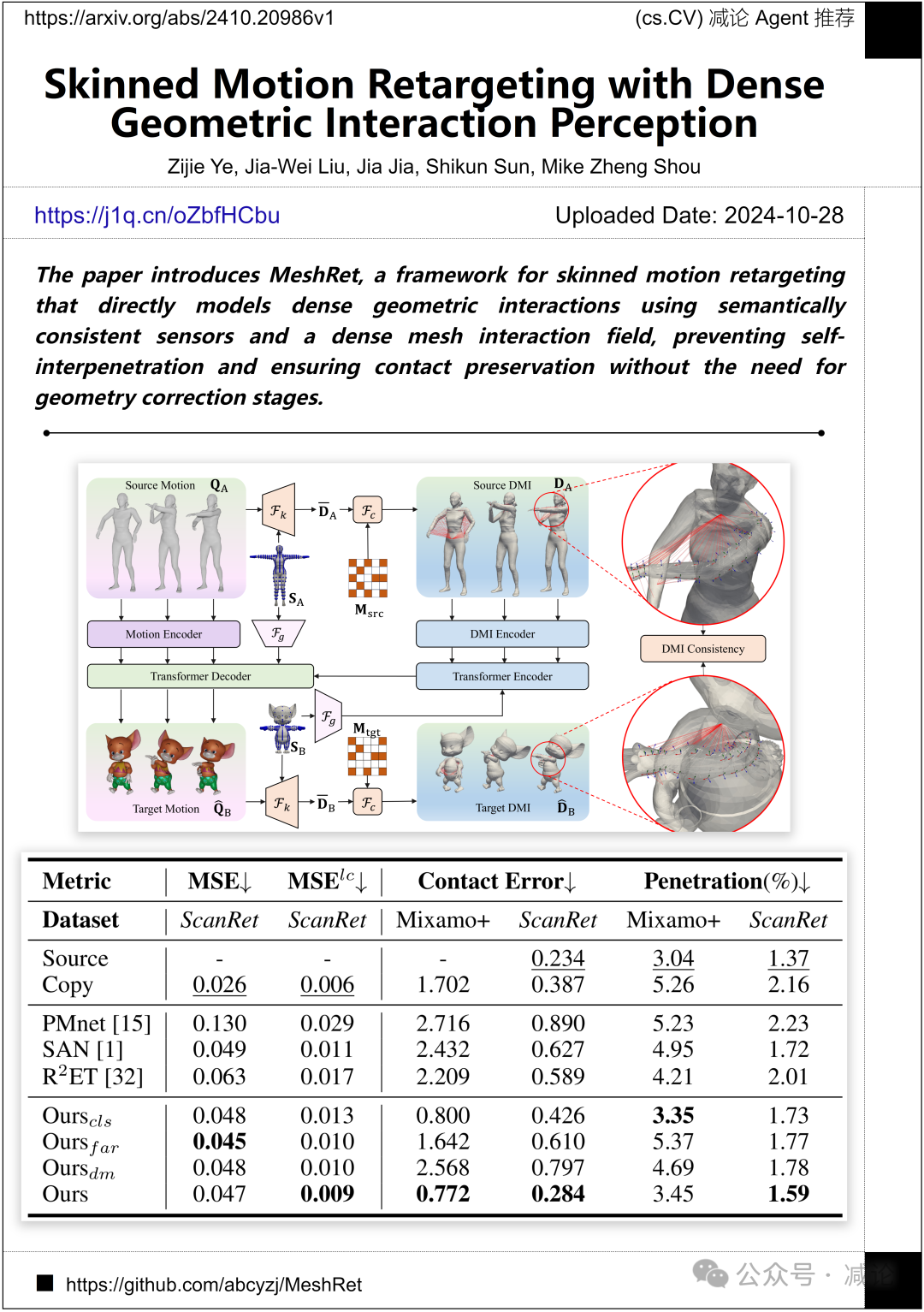

清华大学和新加坡国立大学的研究团队提出了MeshRet框架,用于皮肤动作重定向。该框架通过直接模拟密集几何交互,使用语义一致的传感器和密集网格交互场,防止自相穿和确保接触保留,无需几何校正阶段。
https://j1q.cn/oZbfHCbu
http://arxiv.org/abs/2410.20986v1
https://github.com/abcyzj/MeshRet
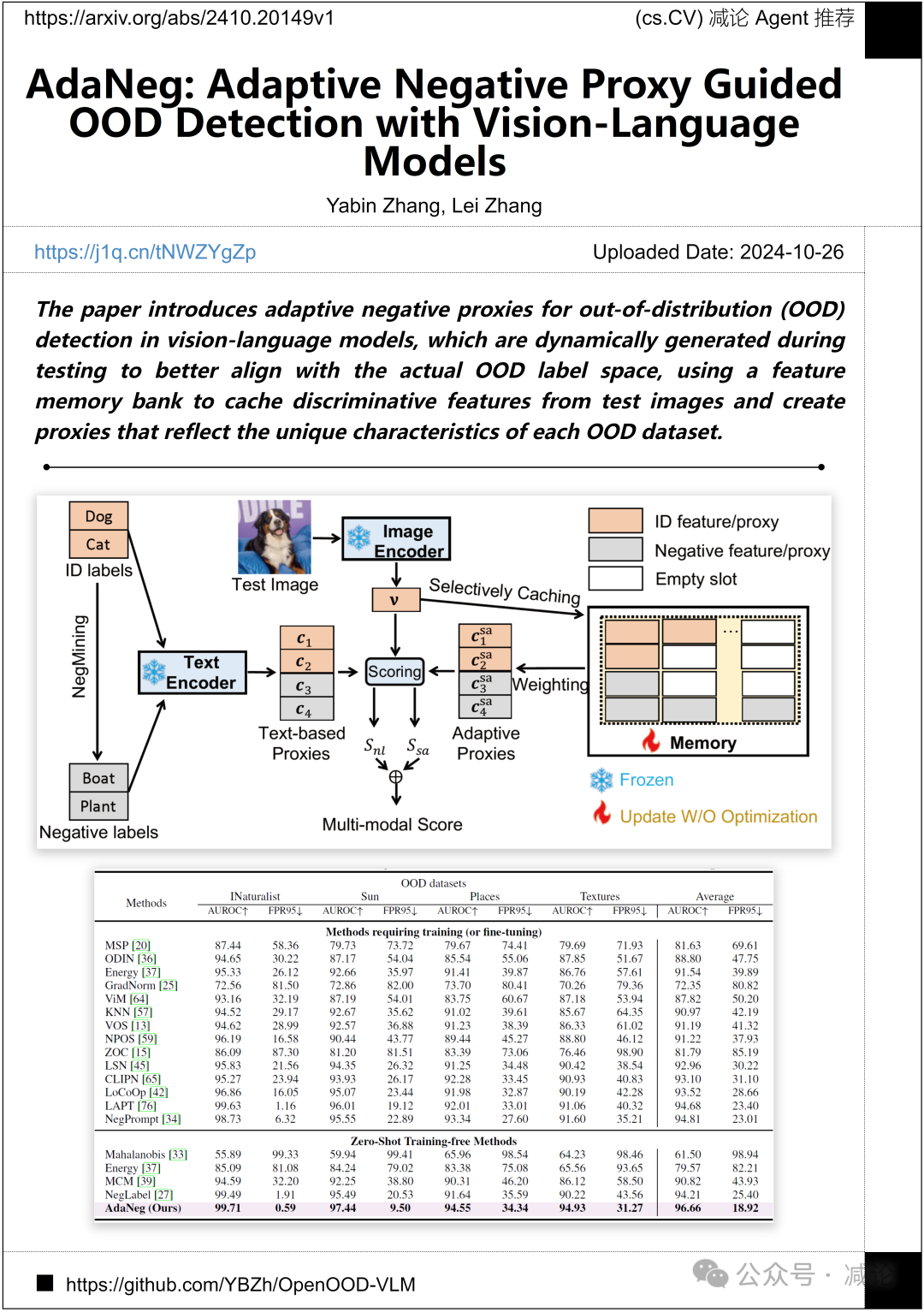
香港理工大学的研究团队介绍了在视觉–语言模型中用于检测超出分布(OOD)的自适应负代理。这些代理在测试期间动态生成,以更好地与实际的OOD标签空间对齐,利用特征存储器缓存测试图像中的判别特征并创建反映每个OOD数据集独特特征的代理。
https://j1q.cn/tNWZYgZp
http://arxiv.org/abs/2410.20149v1
https://github.com/YBZh/OpenOOD-VLM

卡内基梅隆大学的研究团队介绍了一种新颖的无标记算法,利用多视角实例分割、分割条件下的2D姿势估计和3D姿势预测在时间反馈循环中跟踪3D人体姿势。他们成功创建了Harmony4D数据集,实现了在严重遮挡和近距离交互中最小化手动干预的目标。
https://j1q.cn/2UgjvREs
http://arxiv.org/abs/2410.20294v1
https://jyuntins.github.io/harmony4d/

悉尼科技大学和浙江大学提出了DIFFUSIONHOI,一种利用大型关系驱动扩散模型的人–物交互(HOI)检测方法。他们引入了一种基于反演的策略,以学习嵌入空间中人与物体之间关系模式的表达,并将其用作文本提示,引导扩散模型生成描绘特定交互的图像,并提取与HOI相关的线索,而无需进行繁重的微调。
https://j1q.cn/6Kd6yMkk
http://arxiv.org/abs/2410.20155v1
https://github.com/0liliulei/DiffusionHOI

浙江大学、阿里巴巴集团和上海交通大学的研究团队推出了一篇关于OmniSep的学术论文。该论文介绍了OmniSep,一种新颖的全模态声音分离框架,它采用Query-Mixup策略在训练过程中融合来自不同模态的查询特征,实现多模态的同时优化,提高了在文本、图像和音频查询任务中的声音分离性能。
https://j1q.cn/4cN4TfGX
http://arxiv.org/abs/2410.21269v1
https://omnisep.github.io/
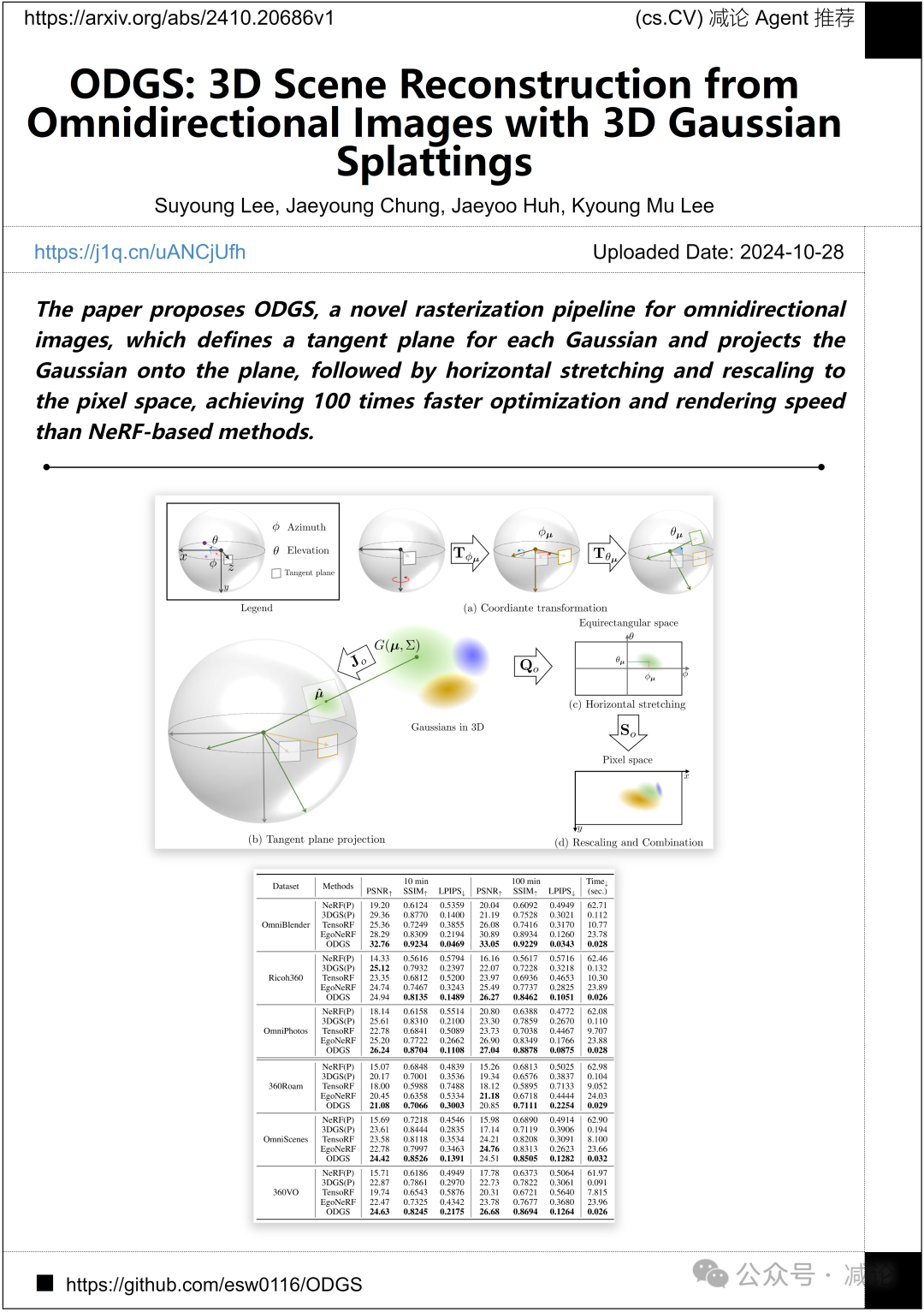
首尔大学的研究团队提出了ODGS方法,这是一种新颖的全向图像光栅化流水线。该方法为每个高斯定义了一个切平面,并将高斯投影到平面上,然后进行水平拉伸和重新缩放到像素空间。通过这种方法,实现了比基于NeRF的方法快100倍的优化和渲染速度。
https://j1q.cn/uANCjUfh
http://arxiv.org/abs/2410.20686v1
https://github.com/esw0116/ODGS

新疆大学、信息技术大学和谢赫穆罕默德人工智能大学联合提出了NT-VOT211,这是一个大规模基准,用于评估夜间条件下的视觉目标跟踪算法,包括211个不同视频和211,000个带有8个属性的标注帧。
https://j1q.cn/vY22Q2mr
http://arxiv.org/abs/2410.20421v1
https://github.com/LiuYuML/NV-VOT211

马里兰大学帕克学院的研究团队提出了一种全面的令牌化方案,利用学习到的查询和轻量级AR先验模型来优化自回归生成任务的潜在空间,从而提高视频重建和生成性能。
https://j1q.cn/Vh68ZtKF
http://arxiv.org/abs/2410.21264v1
https://hywang66.github.io/larp/
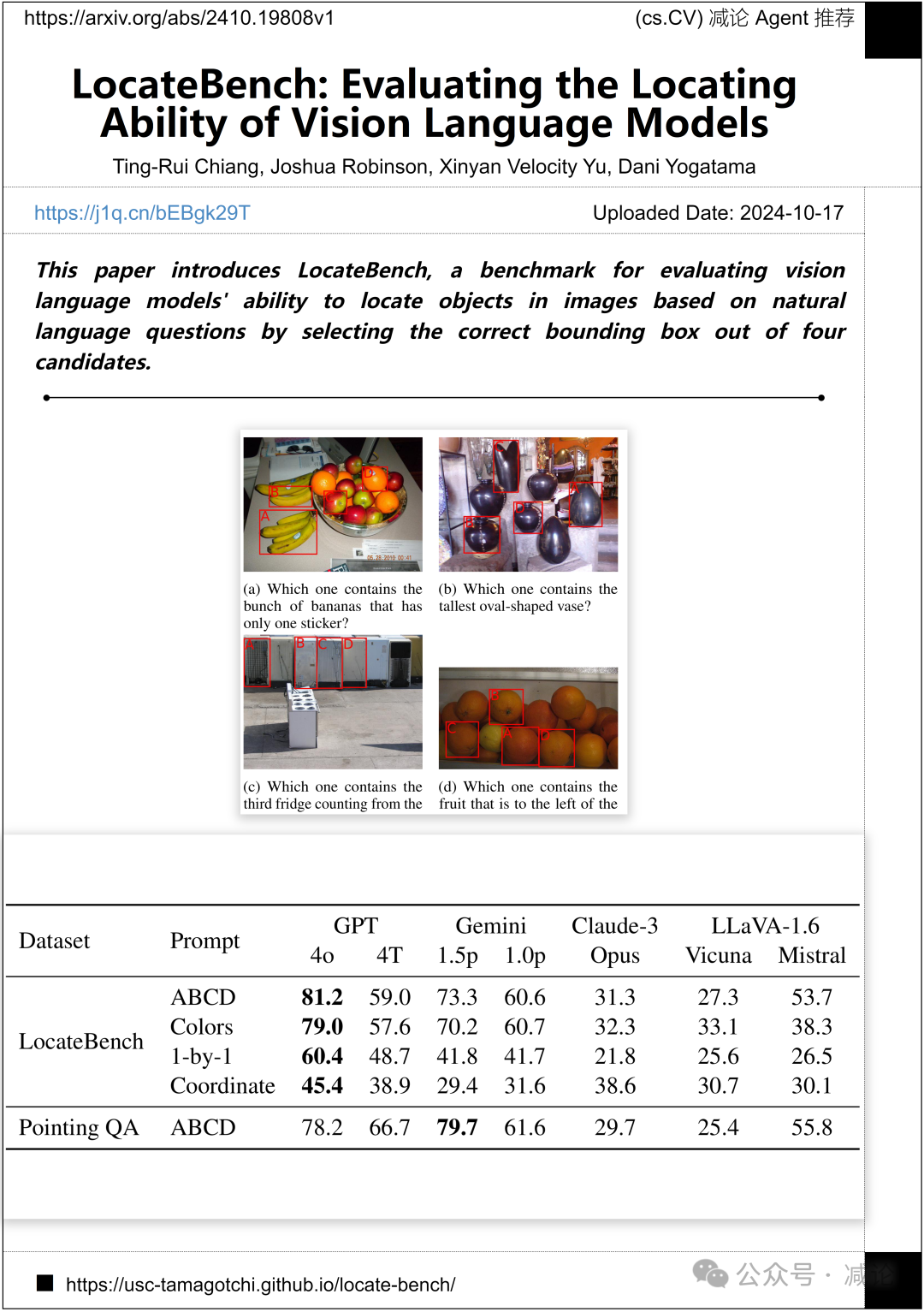
南加州大学的研究团队介绍了LocateBench,这是一个基于自然语言问题,在图像中定位物体的能力评估视觉语言模型的基准,通过从四个候选框中选择正确的边界框。
https://j1q.cn/bEBgk29T
http://arxiv.org/abs/2410.19808v1
https://usc-tamagotchi.github.io/locate-bench/
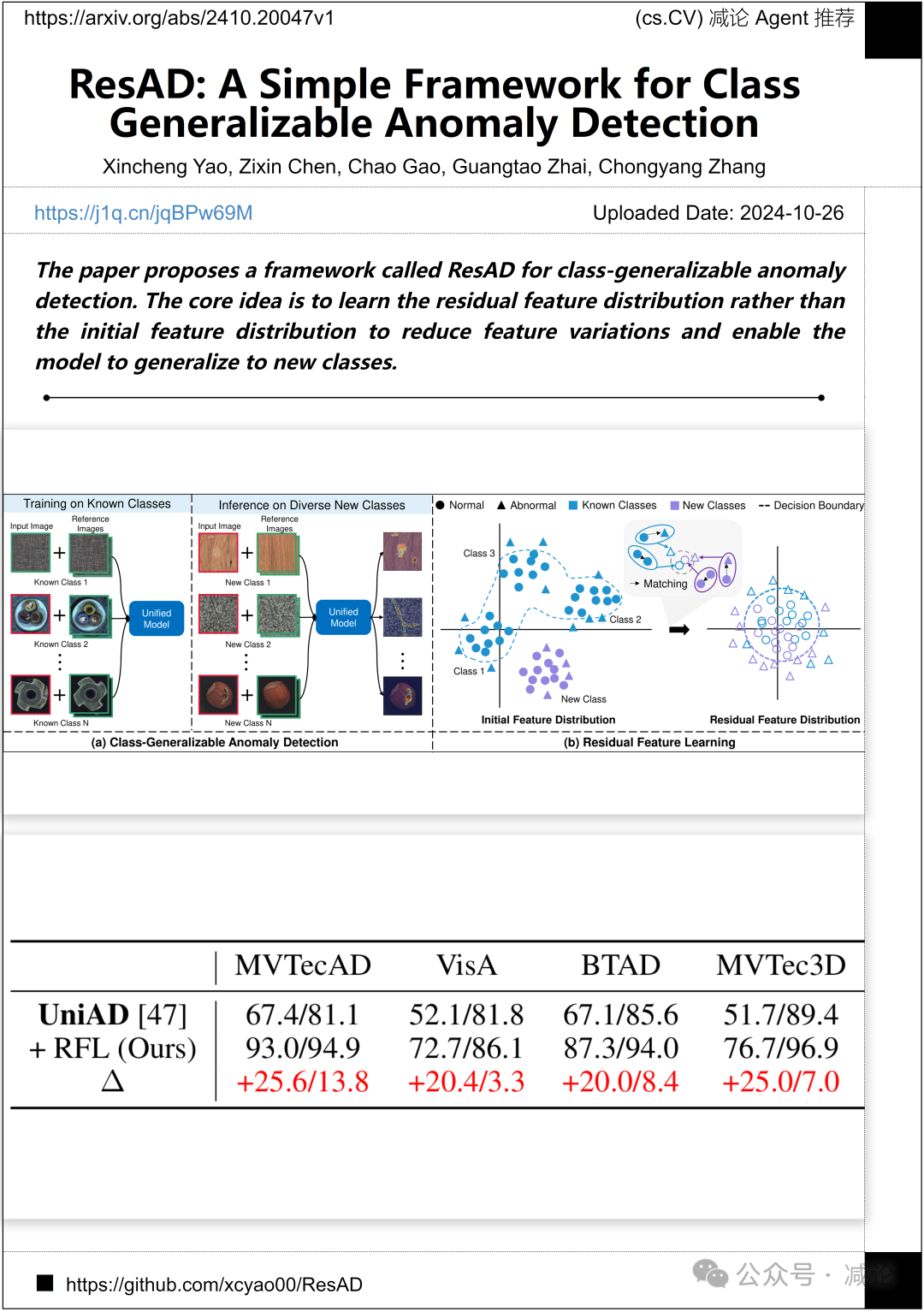
上海交通大学与中国太平洋保险集团有限公司的研究团队提出了一个名为ResAD的框架,用于类别通用的异常检测。该框架的核心思想是学习残差特征分布,而不是初始特征分布,以减少特征变化并使模型能够泛化到新类别。
https://j1q.cn/jqBPw69M
http://arxiv.org/abs/2410.20047v1
https://github.com/xcyao00/ResAD

沙特阿拉伯国王科技大学Meta人工智能团队介绍了MarDini,这是一个视频扩散模型,它将遮蔽自回归用于时间规划和扩散模型用于空间生成相结合,应用于不对称网络设计,实现了规模化高效且高质量的视频生成。
https://j1q.cn/fQcxQeUO
http://arxiv.org/abs/2410.20280v1
https://mardini-vidgen.github.io
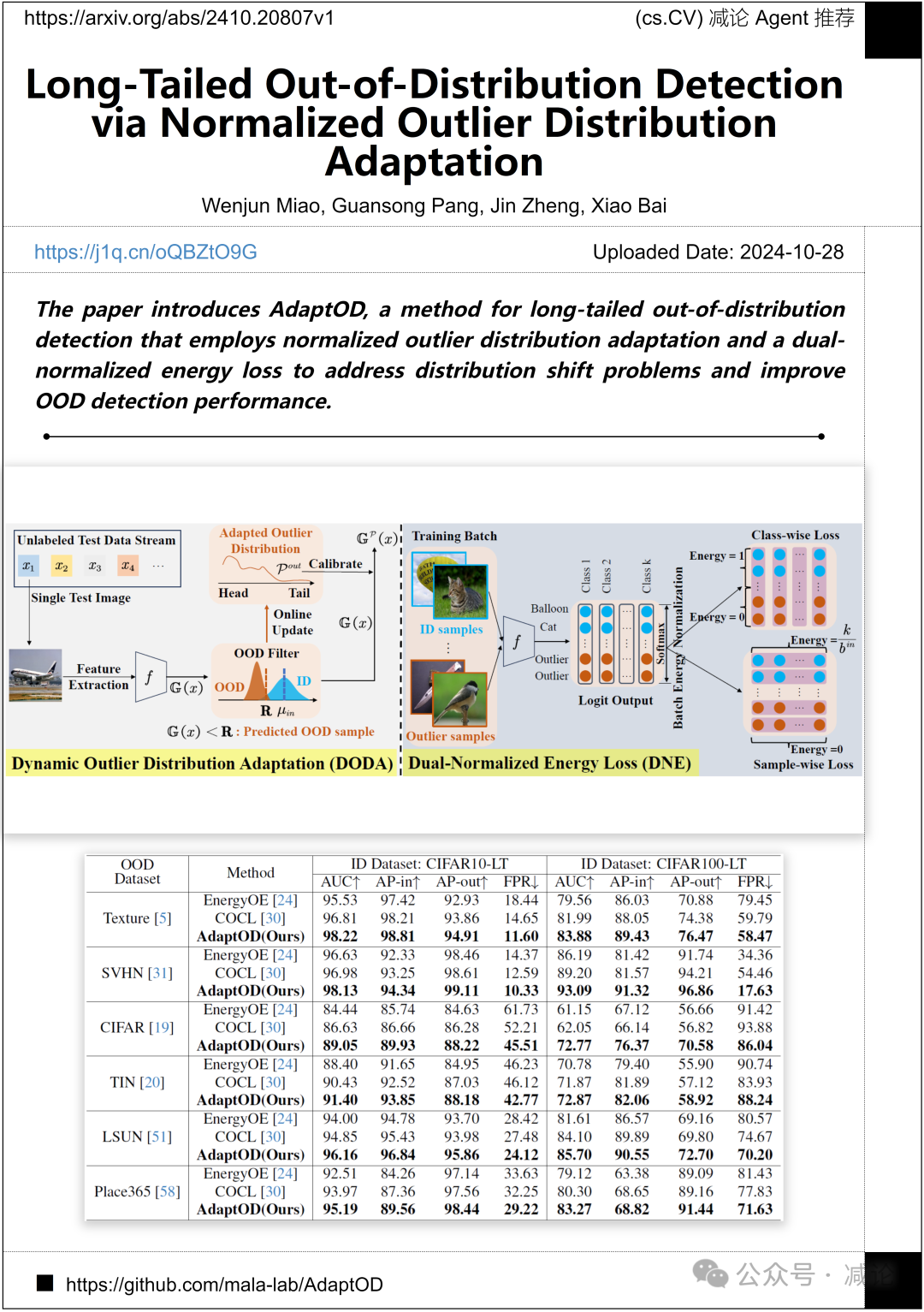
北京航空航天大学与新加坡管理大学的研究团队提出了AdaptOD方法,用于长尾分布的离群检测。该方法采用了归一化异常值分布适应和双归一化能量损失,以解决分布偏移问题并提高离群检测性能。
https://j1q.cn/oQBZtO9G
http://arxiv.org/abs/2410.20807v1
https://github.com/mala-lab/AdaptOD

浙江大学和香港中文大学的Avolution AI团队推出了论文,介绍了BlinkVision作为一个以RGB帧和事件为特征的光流、场景流和点追踪估计基准,具有丰富的模态、丰富的注释、大量类别词汇和自然数据。
https://j1q.cn/J3k99wls
http://arxiv.org/abs/2410.20451v1
https://www.blinkvision.net/

安徽大学和西北工业大学的研究团队提出了一个指导解缠网络(GDNet),用于光学引导热成像无人机图像超分辨率(OTUAV-SR)。他们将光学图像表示解缠为特定属性的引导特征,形成更具区分性的表示,以应对多样化的无人机场景条件。
https://j1q.cn/cWmZp7wF
http://arxiv.org/abs/2410.20466v1
https://github.com/Jocelyney/GDNet

中国人民大学和莫纳什大学的作者团队提出了一个基于提示学习的通用点云分析规范框架。该框架通过最大化任务特定预测和任务无关知识之间的相互一致性,对提示学习轨迹施加多个显式约束。
https://j1q.cn/1aqVRrJV
http://arxiv.org/abs/2410.20406v1
https://github.com/auniquesun/Point-PRC

南开大学计算机视觉实验室介绍了Grid4D模型,这是一种基于高斯飞溅的动态场景渲染模型,采用4D分解哈希编码方法表示4D输入,不依赖于低秩假设,结合方向注意力模块聚合空间和时间特征,并使用平滑正则化项改善模型的变形预测。
https://j1q.cn/wiNyHnsl
http://arxiv.org/abs/2410.20815v1
https://jiaweixu8.github.io/Grid4D-web/