
前言,近日应邀参加了北京容芯致远科技有限公司的市场活动,从公司名字不难看出他们是一家专注于芯片研发的企业,但深入了解后发现,他们和国内做CPU、GPU及DPU芯片类的公司有着显著区别。尽管我在服务器领域搬砖多年,对各种类型的芯片并不陌生,但在聆听了该公司关于其产品设计和解决方案的介绍之后,还是感到耳目一新。容芯致远的目标市场是给信创“提速”,用其负责人的一句话概况是“硬件中间件”,帮助国产CPU、国产AI芯片以及国产通用和GPU的服务器解决性能、生态等核心问题,看到这里相信很多朋友是蒙的,接下来我们展开聊聊。
一、信创替代面临的难点分析
为什么做信创,其“必要性”是老生常谈了,国家也出台了一些列政策指导文件,我也不再赘述,通过近几年的实践来看,信创替代道路并非一帆风顺,有很多短期和长期问题要逐一攻克,结合个人理解,将信创替代“难点”归纳为如下四个方面:
1、硬件层面的性能差距:
我们熟悉的x86 CPU品牌Intel、AMD和以及英伟达的GPU,都已更新迭代了二十多年,放眼全球都是行业的标杆,在前几天,AMD重磅发布了其第五代的服务器CPU 代号Turin,单颗CPU的核心数高达192c,反观国内信创CPU市场,表现比较好的某光其单颗CPU最大核心数也仅为64c,和AMD相比客观来看,至少有2代左右的差距。在信创替代服务器规划时,往往采用1:N的方式,1代表目前主流x86服务器的台数,而N为信创CPU的服务器台数,只能采用N>1才能实现性能上的“信创替代”;
2、软件系统的应用生态:
说到计算机领域的生态,有个时髦的词叫Wintel,是指由Microsoft Windows操作系统与Intel CPU所组成的计算机生态,这个系统生态已经经过了30多年的发展非常成熟,同时也建立起来了很高的“技术壁垒”,国内的信创替代在生态层面就是要打破Wintel的壁垒,比如基于ARM打造的鲲鹏和飞腾CPU、自研指令集的龙芯等,通过搭配国产麒麟、统信这类国产OS及国产化的中间件产品,在信创生态的建设方面有了长足的进步,但是和Wintel相比在成熟的、丰富度等方面依然有较大差距,还需要市场的持续“打磨”。
3、产品核心IP可持续性:
信创CPU的技术路线主要有三个,1)是基于国外商业化的指令集和微架构做产品研发(如基于ARM的飞腾、鲲鹏、海光)、2)是基于开源的指令集架构做产品研发(基于risc-v的阿里玄铁CPU),3)是从指令集的层面进行研发(如基于自研LoongArch的龙芯CPU),为了阻碍国内信创的发展,国外公司已经从指令集授权上进行限制对信创CPU的可持续性迭代造成了影响,所以现在国内对Risc-v的呼声很高。
4、市场化的产品性价比:
现阶段信创产品方案依然是“又贵又难用”,为了推动信创替代,确保2027年底前完成特定行业的的信创替代工作,相关部门2024年8月下发政策文件,明确通过中央财政对信创类项目的产品采购进行补贴(不同地区补贴比例也有差异),来弥补“性价比差”带来的采购压力。
二、怎么理解硬件“中间件”
相信很多朋友都听过“软件中间件”,国内比较知名的有东方通、宝兰德等,产品定位是OS和应用程序之间的产品,它屏蔽了应用程序与底层系统的通讯,交互,连接等复杂又通用化的功能,以产品形式提供,在系统交互时,利用中间件作为“桥梁”,避免了大量的代码开发和人工成本。理论上来讲,中间件所提供的功能都能通过“代码”实现,只不过开发的周期和需要考虑的问题太多,逐渐的,这些部分的功能,以中间件产品的形式进行了替代。
硬件“中间件”的理念是相同的,帮助国产CPU、GPU等部件解决在国产化替代过程中的“性能不足、生态不兼容、性价比低”的问题。用户不需要改变服务器原有的结构,只写增加一张或者几张标准的“PCIe”插卡即可实现,具体的产品形态我们在下文介绍。
三、“容芯致远”产品和方案组成
通过容芯致远产品和方案的分享,了解到他们目前推出了面向三类“卡式”产品,分别是面向国产CPU服务器的通用数据加速卡、面向国产GPU场景的AI加速卡以及面向存储类业务的数据加速卡,统称为DAU,即数据加速单元,下面我选择前面2个产品进行分享;
1、提高国产CPU服务器计算性能和整机IO能力的加速卡
增加DAU加速单元,改变服务器冯诺依曼架构为存算分离架构,剥离CPU 对数据处理的功能,降低 CPU 负荷,释放CPU原有的IO数据处理压力和国产化芯片的PCIE总线IO带宽占用率,从根本上解决国产服务器性能瓶颈,有效提升整体的IO性能3-10倍(项目实际值),通过DAU加速单元高速并发处理,提升CPU计算资源使用率约2倍,技术原理图如下:
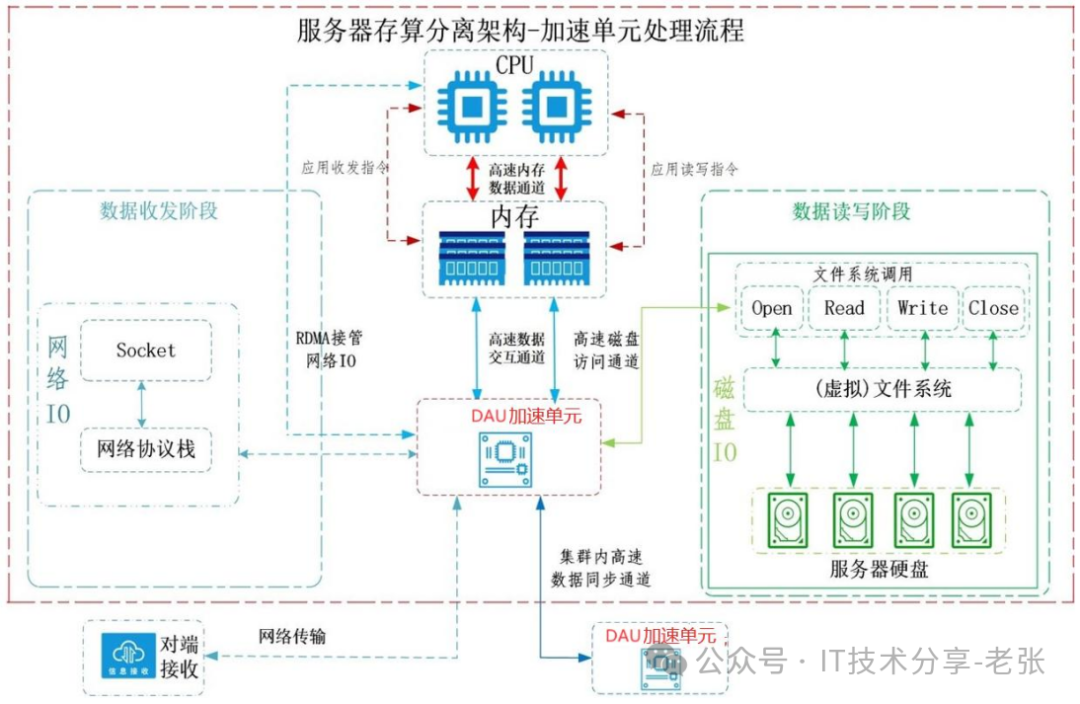

2、提高国产GPU性能的加速卡
现阶段国产GPU的核心问题是的生态系统不完善,直接影响到了国产GPU的市场普及,随着大数据分析、AI计算等应用对算力需求巨大,在分布式系统中,大模型训练对算力基础设施的要求从单卡拓展到了集群层面,这对大规模卡间互联的兼容性、传输效率、时延等指标提出了更高的要求。“容芯致远”的方案是通过加速卡+NVME构建独立的分布式数据加速平台,不占用CPU资源,满足数据/模型快速加载、交互;卡间速率可达到500GB/s以上,节点间速率达到400Gbps ,并且可以实现不同品牌、型号GPU卡的混插,内置驱动与主流GPU卡适配实现拉通国产GPU生态目的,通过智算MAAS平台可按照业务或任务需要进行卡级资源调度,还可以调度异构GPU卡进行混卡推理和混卡训练,提高智算资源的使用效率的同时,降低了使用难度。
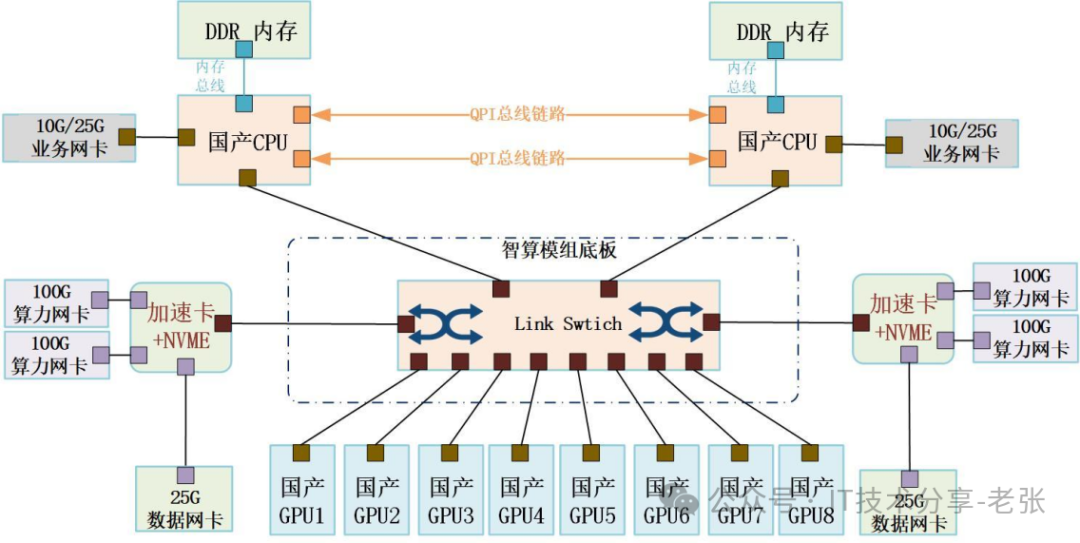
针对信创桌面云的细分业务场景,我们公司超云的飞腾平台服务器也和容芯致远做了方案验证,在实际的桌面并行数量上有3倍以上的效果提升。
四、信创替代趋势的思考
信创替代是大势所趋、未来的市场空间会无限大,如何在保证可用、易用的同时降低综合成本是信创替代能够成功的“关键”,容芯致远从“打辅助”的角度为国产CPU和GPU产品的加速落地提高了支撑,为客户侧提供了更实用的“信创替代”选择方案,大家如果也感兴趣,想获取容芯致远的产品资料,可以关注公众号“IT技术分享-老张”后,在信息栏发送“20241029”自动获的百度网盘的下载链接。