在数字媒体和人工智能的交汇点上,字节跳动的最新创新——PersonaTalk,正引领一场视觉配音的革命。这一音频驱动的视觉配音框架在SIGGRAPH Asia 2024 Conference Track上大放异彩,以其精准同步、个性保留、通用性强和多语言支持等特性,预示着视频制作和虚拟互动的新趋势。
主要特点
-
声音与表情的无缝融合:PersonaTalk让视频中的人物口型与输入语音完美同步,带来前所未有的观看体验。
-
个性魅力的极致展现:在确保唇形同步的同时,保留说话者的独特风格和面部特征,让每个视频都充满个性。
-
无与伦比的通用性:作为一个多功能框架,PersonaTalk能够轻松适应各种应用场景,无需针对特定人物进行定制训练。
-
多语言环境的自由切换:无论是中文、英文还是其他语言,PersonaTalk都能提供卓越的配音效果,极大地扩展了应用的多样性。
技术方案
PersonaTalk采用了创新的双阶段框架,结合风格感知的动画生成和双分支并行的注意力模块,不仅提升了人脸三维重建的精度,还通过注意力机制渲染出稳定且逼真的脸部和嘴部纹理。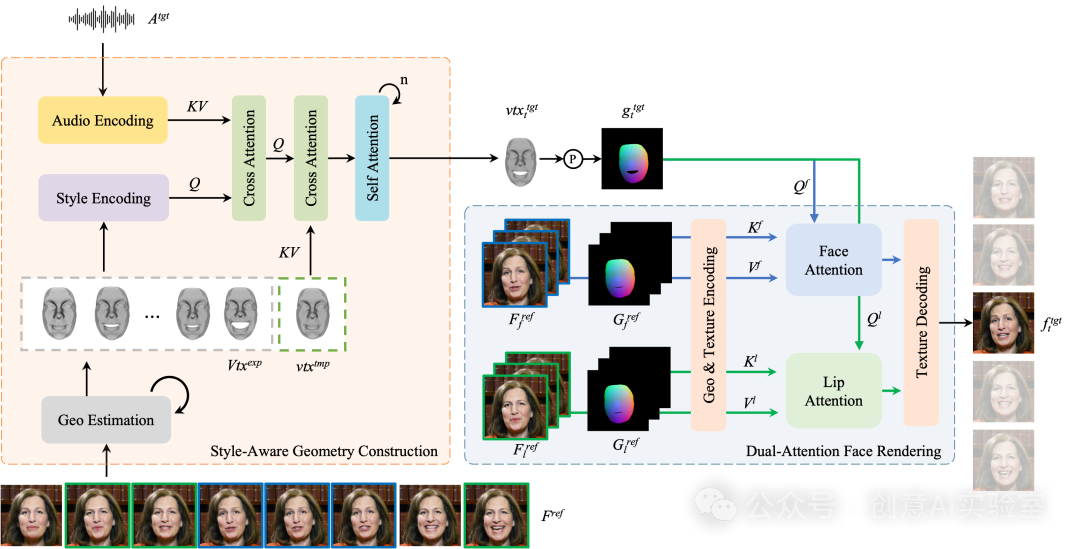

应用前景
PersonaTalk的问世预示着视频制作、虚拟主播和跨语言内容创作等领域的变革。它不仅极大提升了视频配音的效率和质量,还为创作者打开了新的创意空间,使得高质量视频内容的制作变得更加便捷和普及。
结语
随着技术的不断进步,PersonaTalk有望在更多领域展现其潜力,推动视频内容创作和数字人技术的创新发展。整合先进的音频技术和深度学习算法,PersonaTalk正在开创一个全新的视听交互时代,让交流变得更加丰富和多元。
项目地址:
文档:https://arxiv.org/pdf/2409.05379
项目:https://grisoon.github.io/PersonaTalk
文章内容来自于网络,由百合树AI整理,如有侵权,联系删除。如需开始AI写作请返回主页。
