


华中科技大学和百度公司的研究团队提出了一种名为Reverse Chain-of-Thought (R-CoT)的两阶段流水线,用于生成高质量的几何推理数据。在第一阶段,GeoChain生成高保真度的几何图像和相应的描述。在第二阶段,Reverse A&Q使用这些描述逐步以相反顺序生成推理结果并提出问题,提高生成数据的准确性。
http://arxiv.org/abs/2410.17885v1
https://github.com/dle666/R-CoT

塔帕尔人工智能、中国三峡大学和南开大学的研究团队提出了一个名为PCNet的新颖框架,用于植物伪装检测。该框架包括一个多尺度全局特征增强模块和一个多尺度特征细化模块,旨在解决植物伪装带来的独特挑战。
http://arxiv.org/abs/2410.17598v1
https://github.com/yjybuaa/PlantCamo
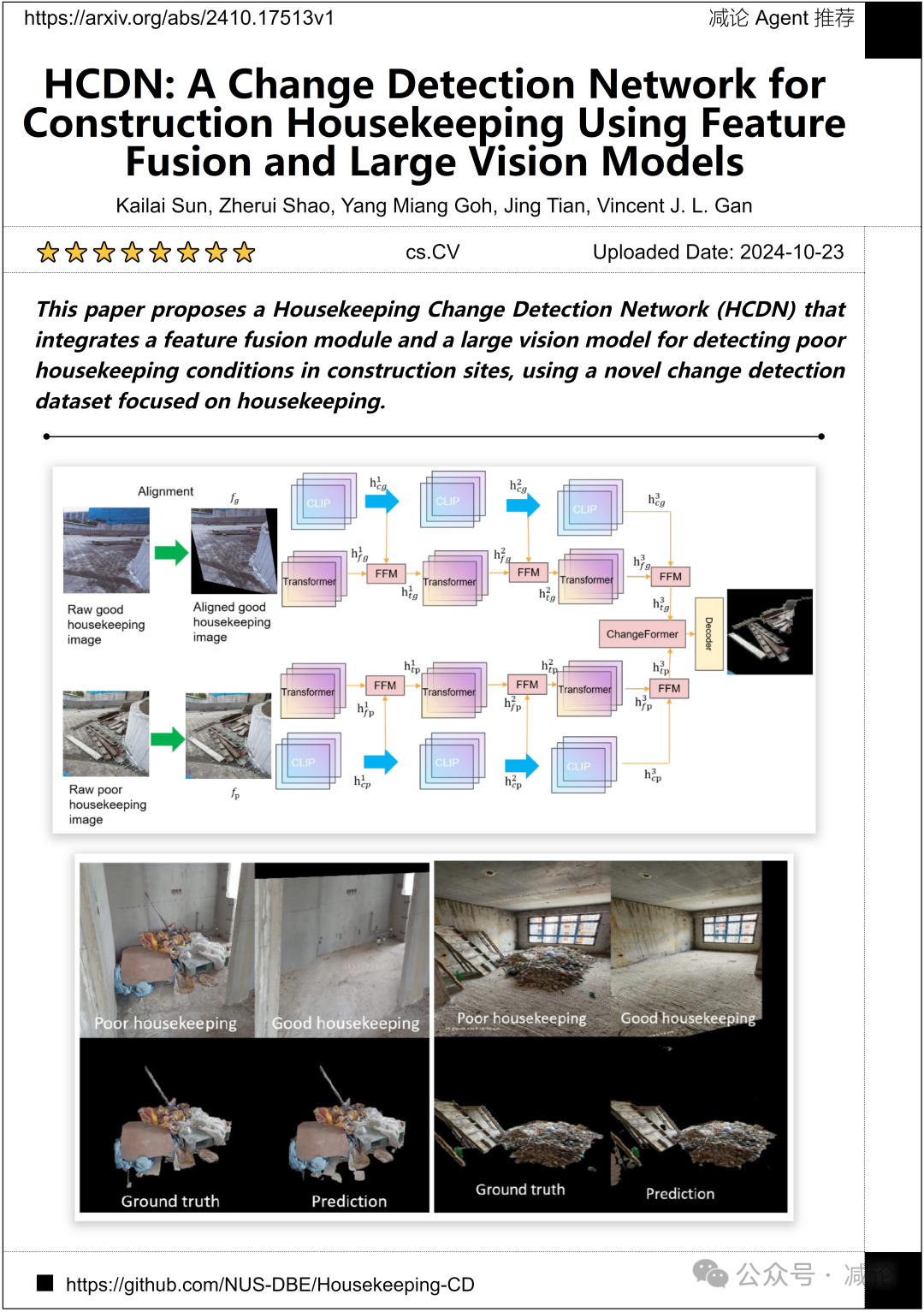
新加坡国立大学NUS-ISS团队提出了一个家政变化检测网络(HCDN),该网络整合了特征融合模块和一个大视觉模型,用于检测建筑工地中的糟糕家政条件,使用了一个专注于家政的新颖变化检测数据集。
http://arxiv.org/abs/2410.17513v1
https://github.com/NUS-DBE/Housekeeping-CD

上海交通大学和苏州大学的作者团队推出了一篇论文,提出了一种数据驱动的方法。该方法利用人类运动模仿算法的最新进展来学习人类的逆动力学。关键思想是使用运动模仿算法生成一个大规模的人类运动数据集,其中包含相应的动力学(ImDy),然后使用这些数据来以完全监督的方式训练一个数据驱动的求解器(ImDyS)用于人类逆动力学。
http://arxiv.org/abs/2410.17610v1
https://foruck.github.io/ImDy
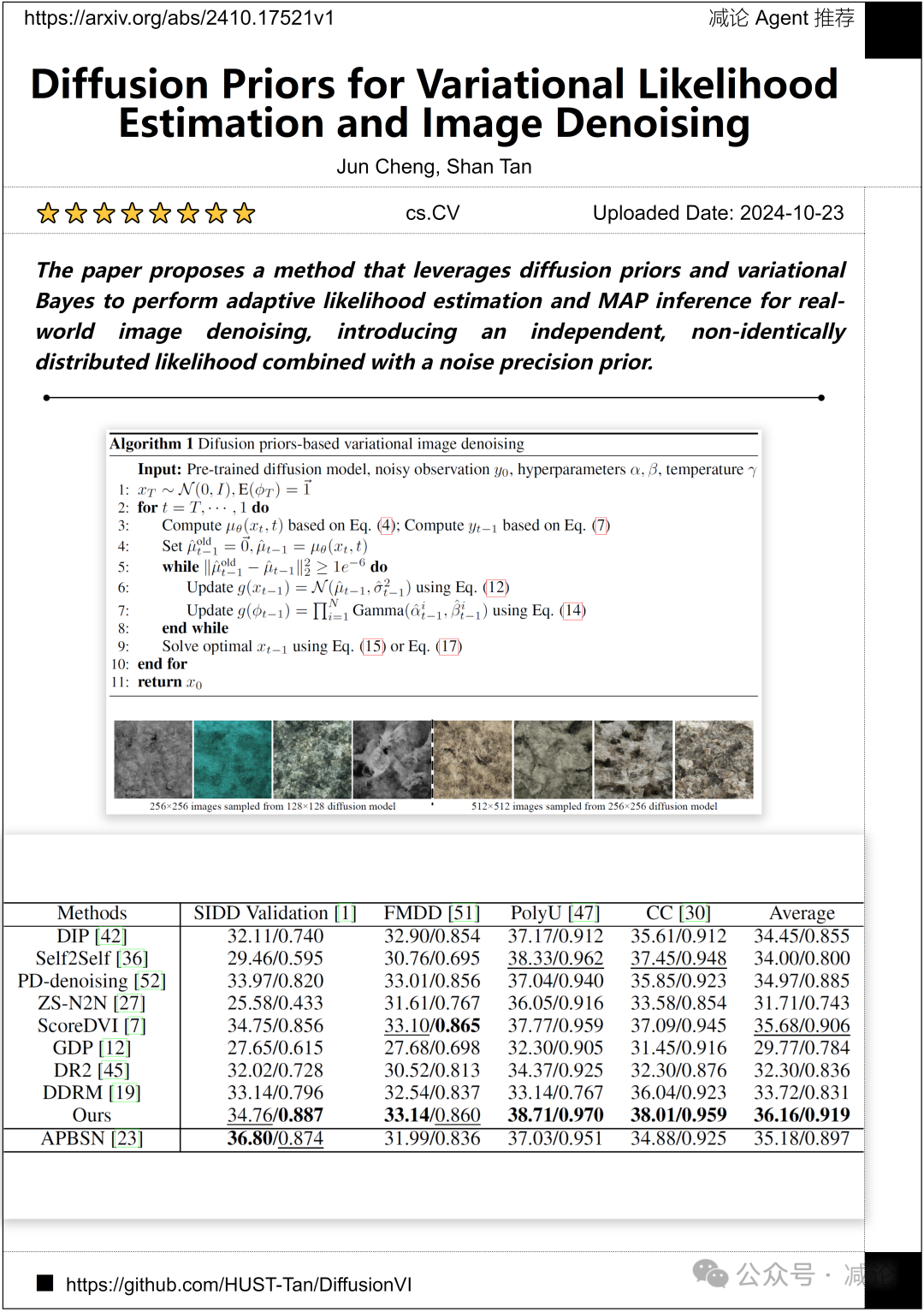
华中科技大学的研究团队提出了一种利用扩散先验和变分贝叶斯进行自适应似然估计和最大后验推断的方法,用于实际图像去噪,引入了一个独立的、非同分布的似然结合噪声精度先验。
http://arxiv.org/abs/2410.17521v1
https://github.com/HUST-Tan/DiffusionVI

穆罕默德·本·扎耶德人工智能大学、中国科学院沈阳自动化研究所、复旦大学大数据研究所的研究团队提出了一种概念增量文本到图像扩散模型(CIDM)。该模型通过使用概念巩固损失、弹性权重聚合模块和可控上下文综合策略,解决了灾难性遗忘和概念忽视问题,实现了对新概念的增量学习。
http://arxiv.org/abs/2410.17594v1
https://github.com/JiahuaDong/CIFC

莫斯科物理技术学院的空天信息研究所、莫斯科物理技术学院、以及斯科尔科技团队提出了一个用于评估文本和视觉领域多模态机器遗忘的基准,名为CLEAR。该论文展示了在遗忘过程中将?1正则化纳入LoRA权重以减轻灾难性遗忘的有效性。
http://arxiv.org/abs/2410.18057v1
https://huggingface.co/datasets/therem/CLEAR

中国科学院信息工程研究所、中央民族大学信息工程学院、阿德莱德大学澳大利亚机器视觉中心的研究团队提出了一种名为Denoise-I2W的新型去噪图像到词映射方法,用于零样本组合图像检索(ZS-CIR)。该方法涉及一个伪三元组构建模块,用于构建伪三元组以对去噪映射网络进行预训练,以及一个伪组合映射模块,将伪参考图像映射到与伪操作文本相结合的伪词标记。该方法旨在消除意图无关的视觉信息,增强准确的ZS-CIR。
http://arxiv.org/abs/2410.17393v1
https://github.com/Pter61/denoise-i2w-tmm

南洋理工大学与华中科技大学的研究团队提出了自适应渲染损失正则化方法,用于几种零样本神经辐射场(NeRF)。该方法旨在减轻位置编码(PE)的频率正则化和渲染损失之间的不一致性,通过引入两阶段渲染监督和自适应渲染损失权重学习。
http://arxiv.org/abs/2410.17839v1
https://github.com/GhiXu/AR-NeRF
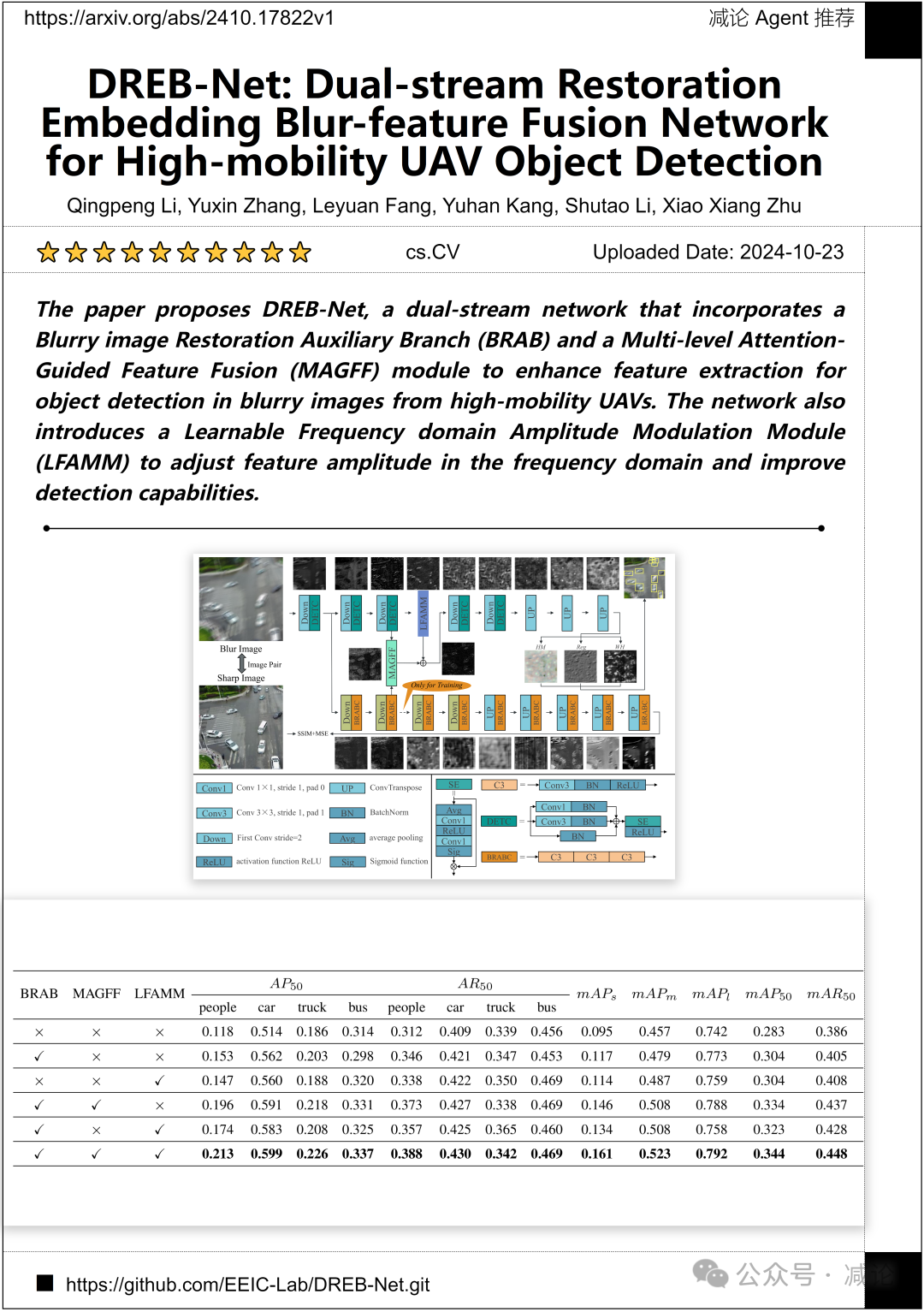
湖南大学和慕尼黑工业大学的研究团队提出了DREB-Net,这是一个双流网络,它包含一个模糊图像恢复辅助分支(BRAB)和一个多级注意力引导特征融合(MAGFF)模块,以增强对高机动性无人机模糊图像中物体检测的特征提取。该网络还引入了一个可学习的频域幅度调制模块(LFAMM),用于调整频域中的特征幅度并提高检测能力。
http://arxiv.org/abs/2410.17822v1
https://github.com/EEIC-Lab/DREB-Net.git
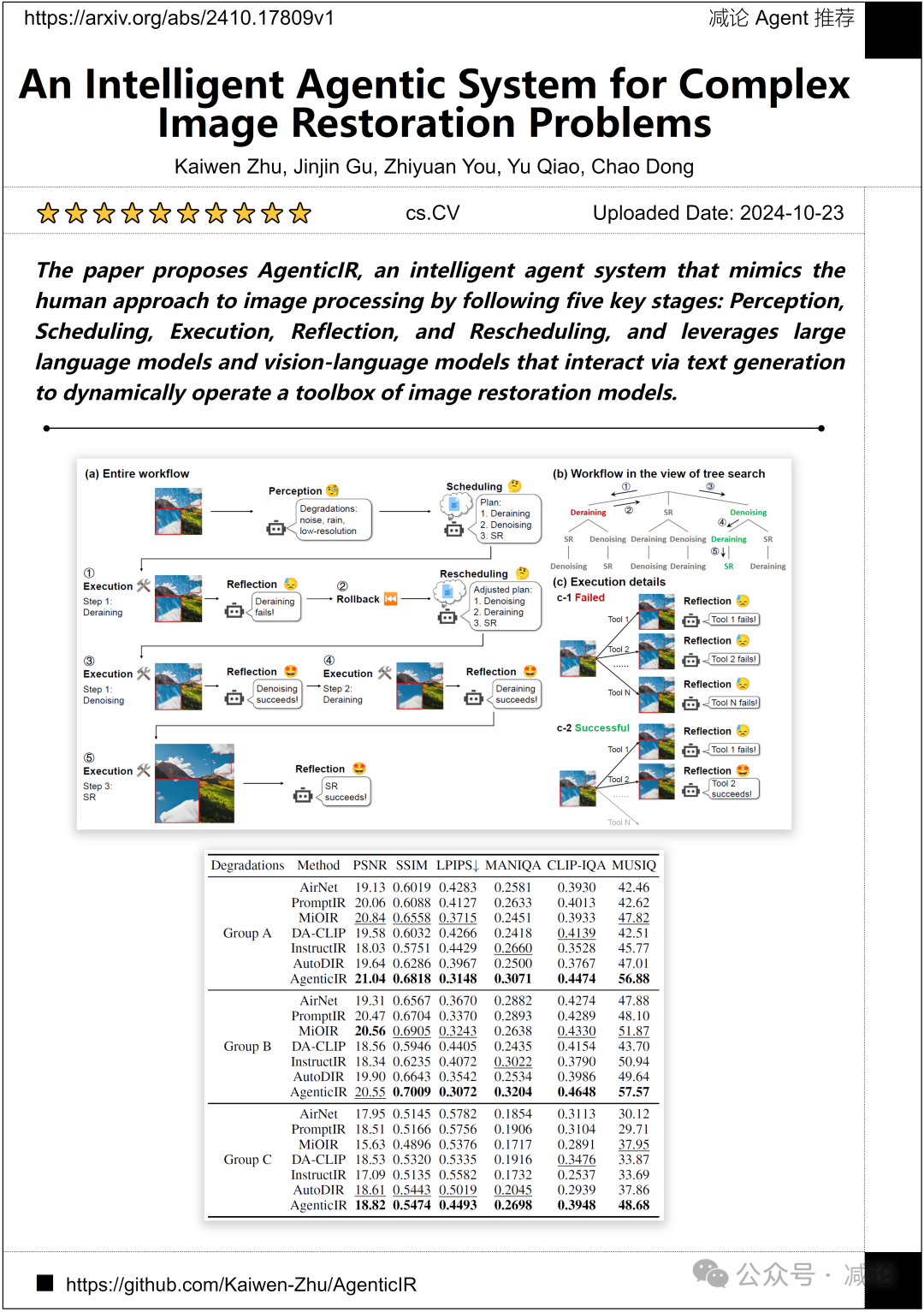
悉尼大学、香港中文大学和上海交通大学的研究团队提出了AgenticIR,这是一个智能代理系统,通过感知、调度、执行、反思和重新调度五个关键阶段,模仿人类处理图像的方法。该系统利用大型语言模型和视觉–语言模型,通过文本生成相互交互,动态操作一组图像恢复模型的工具箱。
http://arxiv.org/abs/2410.17809v1
https://github.com/Kaiwen-Zhu/AgenticIR

北京理工大学, 悉尼大学, 南洋理工大学 提出了ADEM-VL,一种用于大型语言模型的高效视觉–语言调整方法,它使用无参数的跨注意力机制进行多模态融合,减少可训练参数数量,加快训练和推理速度。
http://arxiv.org/abs/2410.17779v1
https://github.com/Hao840/ADEM-VL

阿卜杜拉国王科技大学和Meta AI以及韩国大学的团队提出了LongVU,一种用于长视频理解的时空自适应压缩机制。该方法利用跨模态查询和帧间依赖关系来减少视频中的冗余,同时保留视觉细节,允许在有限的上下文长度内进行有效处理。
http://arxiv.org/abs/2410.17434v1
https://github.com/Vision-CAIR/LongVU, https://vision-cair.github.io/LongVU
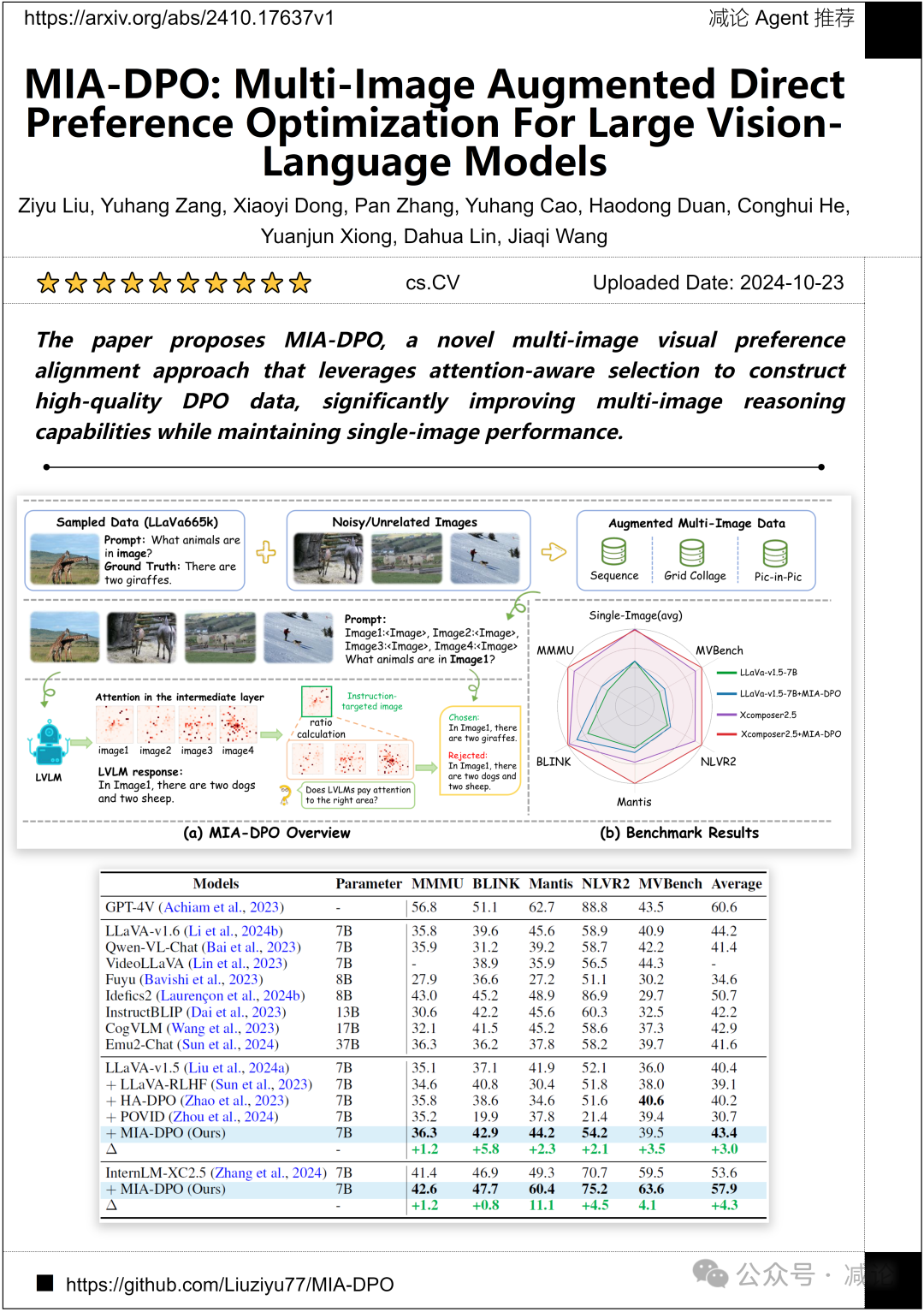
上海交通大学人工智能实验室团队推出了一篇新论文,提出了MIA-DPO方法。这是一种多图像视觉偏好对齐方法,利用注意力感知选择来构建高质量的DPO数据,显著提高了多图像推理能力,同时保持单图像性能。
http://arxiv.org/abs/2410.17637v1
https://github.com/Liuziyu77/MIA-DPO

上海交通大学–密歇根大学联合学院的研究团队提出了一个基于Transformer的框架,其中包含一个不对称特征增强模块(TAFE),通过增强局部信息并使用多尺度交互注意力策略将改进的特征金字塔融合到Transformer编码器的嵌入中,以改善手术场景分割。
http://arxiv.org/abs/2410.17642v1
https://github.com/cyuan-sjtu/ViT-asym