


本文介绍了一种名为Hierarchical Reinforced Trader (HRT)的新型交易策略,该策略采用双层强化学习框架,旨在优化股票选择和执行过程。文章首先概述了自动化股票交易的挑战,包括维度的诅咒、交易行为的惯性以及投资组合多样化的不足。针对这些挑战,HRT通过结合基于Proximal Policy Optimization (PPO)的高级控制器(High-Level Controller, HLC)和基于Deep Deterministic Policy Gradient (DDPG)的低级控制器(Low-Level Controller, LLC),在策略股票选择和优化交易执行方面实现了创新。
1. 引言
自动化股票交易策略的挑战包括维度的诅咒、交易行为的惯性以及投资组合多样化的不足。维度的诅咒指的是随着股票数量的增加,数据和状态动作空间的维度呈指数级增长,导致计算复杂性、样本效率低下和潜在的训练不稳定性。交易行为的惯性描述了DRL代理根据收到的奖励重复之前行动(买入、卖出或持有)的倾向,而不一定是当前最有利可图的行动。投资组合多样化的不足发生在DRL代理反复关注少数股票时,增加了特定行业的风险,使得投资组合更容易受到这些行业不利发展的的影响。
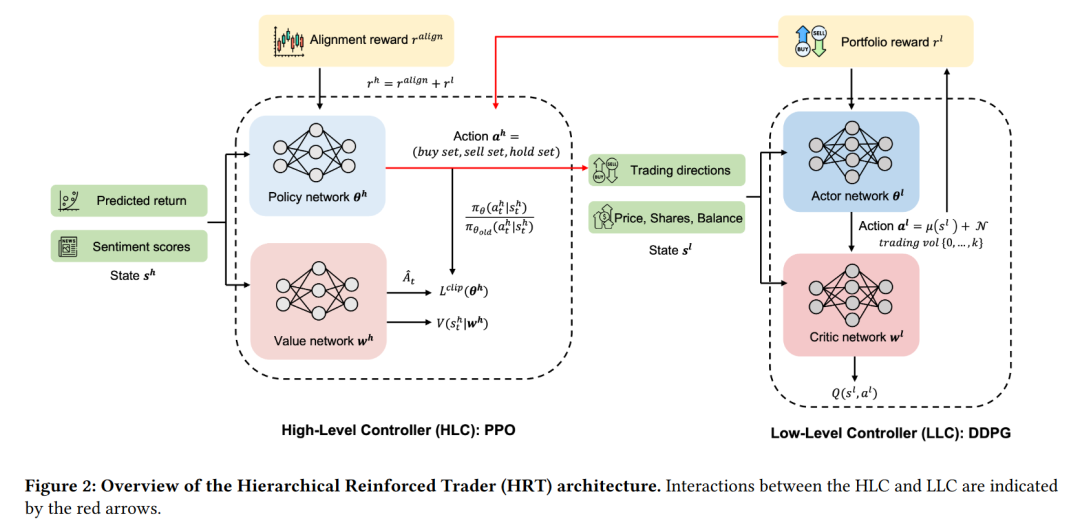
为了解决这些问题,作者提出了Hierarchical Reinforced Trader (HRT),这是一种新颖的交易策略,采用了分层强化学习框架。HRT通过两个主要组件来执行其交易策略:高级控制器(High-Level Controller, HLC)负责战略性股票选择,而低级控制器(Low-Level Controller, LLC)则负责优化所选股票的交易量,以增强投资组合价值。
HRT的主要贡献包括引入了利用分层强化学习框架的HRT代理,并提出了一种名为分阶段交替训练的算法来联合训练HLC和LLC。此外,通过在更大的股票池(S&P 500)上测试和验证结果,展示了与单独的DDPG和PPO方法相比,在不同市场条件下持续实现更高夏普比率的能力。
2. 相关工作
2.1 DRL在交易中的应用
DRL通过与市场的连续交互进行动态优化,识别复杂的非线性模式,并将中间阶段(例如,建模、交易信号生成、投资组合优化和交易执行)整合到单一的DRL框架中。研究者尝试了各种DRL方法,包括PPO、A2C和DDPG,以及它们的集成策略,显示出优于单个DRL代理的性能。此外,通过引入额外信息(如预测误差影响的乐观或悲观的强化学习)来扩展DRL,显示出了有希望的方向。还有研究表明,通过添加更多特征或信号来丰富状态表示,可以帮助代理更有效地把握市场动态。例如,自适应DDPG扩展,包括情感感知方法,增强了模型的鲁棒性。将情感分析和知识图谱结合起来,可以进一步细化算法交易策略。
2.2 分层强化学习(HRL)
DRL在状态空间和动作空间相对较小时表现良好,但在某些问题上,DRL可能不足或训练时间过长。HRL提供了一种分而治之的策略,将决策问题分解为更易管理的子问题。HRL将决策制定分解为分层策略:高层策略关注粗粒度决策,而低层策略关注细粒度、详细的动作。这种分层方法有助于更有效地导航大型动作空间。尽管在交易领域HRL的研究有限,但已有一些研究开发了用于特定交易任务的HRL系统,如高频交易和配对交易。
3. 方法论
HRT策略包括HLC和LLC的设计和交互方式。HLC负责分析市场条件和情绪,以确定买卖或持有的交易方向,而LLC则根据HLC的策略来优化交易量。HRT采用联合训练方法,即分阶段交替训练HLC和LLC,以确保策略和执行策略的一致性和增强。
3.1 概览
HRT模型架构通过将交易过程分为两个层次的决策来提高交易性能:高层次的股票选择和低层次的交易执行。HRT模型的两个主要组件是HLC和LLC,它们通过红色箭头表示的交互方式协同工作。HLC负责分析市场条件和情绪,以确定买卖或持有的交易方向。LLC则根据HLC的决策来优化交易量,以提高投资组合的价值。
3.2 高级控制器(HLC)
HLC的设计目标是解决股票选择问题。它基于预测的前向回报和情绪分数来决定买卖或持有的交易方向。HLC的状态空间包括预测的前向回报和情绪分数,动作空间是离散的,包括买入、卖出和持有。HLC的奖励函数结合了与实际股价变动对齐的奖励和来自LLC的反馈。

HLC采用PPO算法,通过概率比率和裁剪机制来更新策略,以防止性能恶化。PPO算法的目标是最大化一个综合奖励函数,该函数是所有股票的对齐奖励和LLC奖励的线性组合。
3.3 低级控制器(LLC)
LLC在HLC决定的买卖股票集合基础上,细化决策,确定交易的最优数量。LLC的状态空间包括股票价格、持股数量和现金余额,动作空间是连续的,表示要交易的股票数量。LLC的奖励函数基于交易执行后的投资组合价值变化。
LLC采用DDPG框架,通过经验回放缓冲区和目标网络来更新策略。DDPG算法的步骤,包括初始化网络、探索噪声、选择动作、计算奖励、存储转换、更新批评者和行动者网络等。

3.4 联合训练HLC和LLC
文章提出了一种分阶段交替训练方法,首先优化HLC以建立交易决策的战略基础,然后冻结HLC参数,专注于训练LLC。通过迭代交替过程,细化HLC和LLC的策略,确保战略和执行策略的一致性。这种训练方法允许HLC和LLC通过相互反馈进行补充学习,从而提高整体效果。
4. 性能评估
文章使用S&P 500指数作为数据集,对HRT策略进行了性能评估。数据预处理部分包括计算每日前向回报和情绪分数,以及使用随机抽样的新闻来计算情绪分数。训练设置部分详细说明了实验的硬件配置、学习率、折扣因子等参数。评估指标包括累积回报、年化回报、年化波动率、夏普比率和最大回撤。
4.1 股票数据预处理
数据集选用了S&P 500指数成分股,以确保足够的流动性,并使用该指数作为评估整体美国市场表现的基准。研究的样本内期间是从2015年1月1日至2019年12月31日,用于模型的训练,而2020年用于验证模型性能。此外,文章还特别分析了2021年和2022年这两个分别代表牛市和熊市的市场条件。
数据来源是雅虎财经,包括开盘、最高、最低、收盘和成交量(OHLCV)数据。基于这些数据,计算了每日前向回报,使用历史数据的开盘价变化百分比来表示。此外,还采用了Qlib提供的158个特征和Transformer模型的编码器部分来预测前向回报。情绪分析方面,使用了在LLaMA 2 13B模型上进行指令调整的finetuned FinGPT模型,以评估新闻对市场情绪的影响。
4.2 训练设置
实验使用了NVIDIA Tesla V100 GPU,并利用FinRL库进行实验,以确保与先前工作的可比性和开发效率。对于PPO-based HLC和DDPG-based LLC的网络参数设置、学习率、折扣因子等进行了详细说明。
4.3 评估指标
用于评估交易性能的指标,包括累积回报、年化回报、年化波动率、夏普比率和最大回撤。这些指标能够全面地比较不同交易代理和基准的交易性能。
4.4 结果
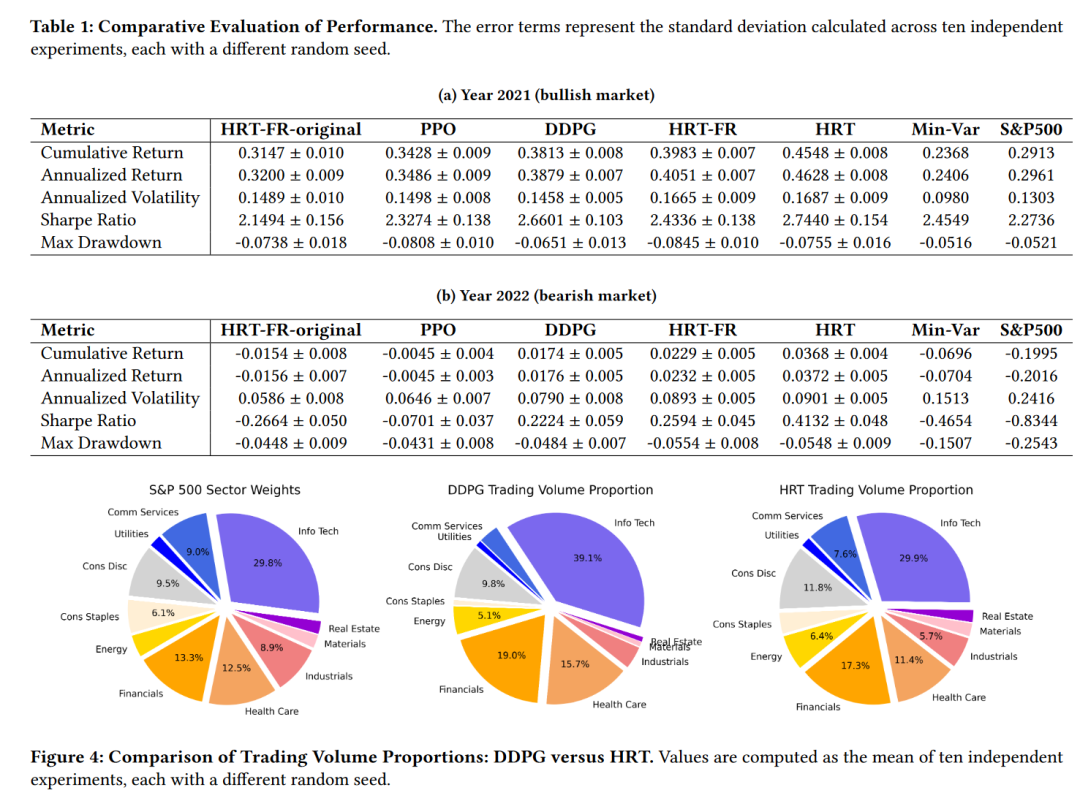
通过对比HRT与其他DRL模型(如单独的DDPG和PPO模型)以及S&P 500指数的表现,文章证明了HRT策略在不同市场条件下的有效性。在2021年的牛市期间,HRT实现了比S&P 500更高的夏普比率。在2022年的熊市期间,HRT也显示出了较小的最大回撤,表明其在市场下跌时的风险控制能力。

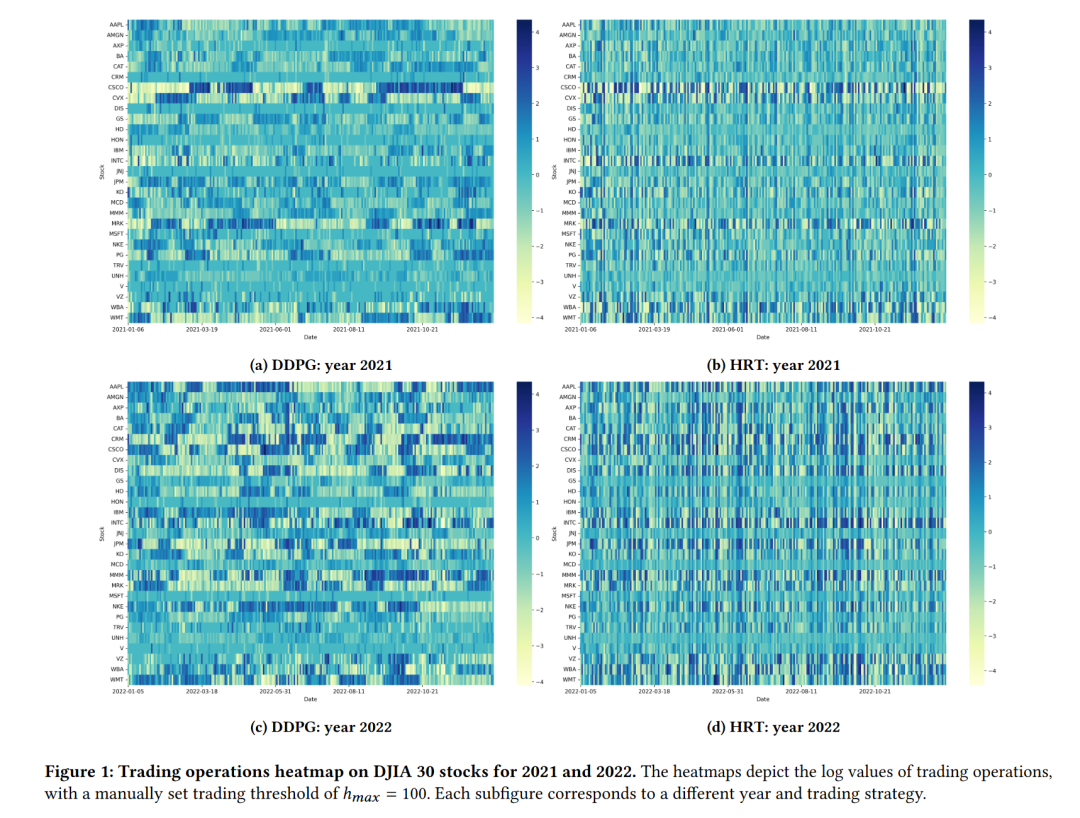
通过与DDPG策略的比较,HRT展现了更多样化和频繁的交易行为,以及更接近S&P 500行业权重的多样化投资组合。
5. 结论和未来工作
文章总结了HRT策略的主要贡献,并提出了未来研究的方向,包括将交易过程建模为部分可观察的马尔可夫决策过程(POMDP),以及探索自适应学习率和最新的DRL模型以提高整体性能。通过在实际的S&P 500数据上进行测试,HRT代理在各种市场条件下均实现了正的累积回报,并保持了强大的夏普比率。即使在以股价大幅下跌和高波动性为特征的熊市中,HRT代理也设法保持了正的夏普比率。此外,HRT在降低动作和状态的维度方面显示出了希望,这表明未来的研究可以进一步缩小动作空间,例如通过分离买卖动作。HRT还似乎减轻了通常限制DDPG等模型多样化的惯性或动量效应,从而增强了交易算法的盈利能力和鲁棒性,并邀请重新评估在多股票交易中的应用。