
2024年10月21日Arxiv cs.CV发文量约80余篇,减论Agent通过算法为您推荐并自动化整理为卡片供您参考,预计为您节省34分钟浏览Arxiv的时间。


上海人工智能实验室, 浙江大学, 悉尼大学 的研究团队提出了Depth Any Video,这是一个用于视频深度估计的模型,利用可扩展的合成数据管道和生成式视频扩散模型,在真实世界的视频中实现了对精确深度注释的稳健泛化。
http://arxiv.org/abs/2410.10815v1
https://depthanyvideo.github.io
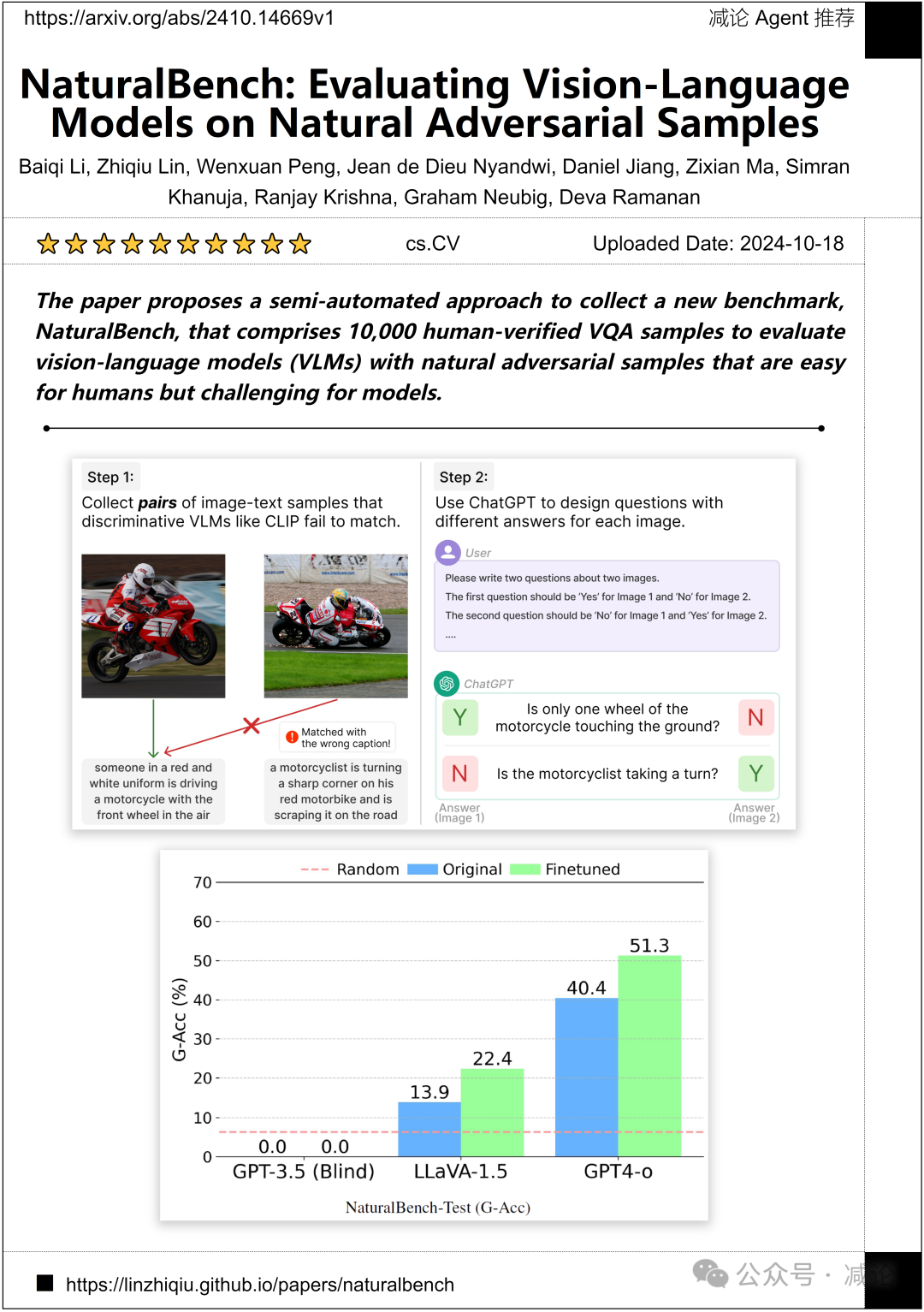
卡内基梅隆大学的研究团队提出了一种半自动化方法来收集一个新的基准数据集NaturalBench,其中包括10,000个经人工验证的VQA样本,用于评估视觉语言模型(VLMs)并提供自然对抗样本,这些样本对人类来说很容易,但对模型来说具有挑战性。
http://arxiv.org/abs/2410.14669v1
https://linzhiqiu.github.io/papers/naturalbench

DeepGlint的研究团队在悉尼大学和伦敦帝国学院联合提出了一种新的预训练范式,为LMMs引入了一个跨模态理解阶段,以增强LLMs的视觉理解能力。他们利用动态可学习的提示标记池,通过匈牙利算法将视觉标记替换为相关提示标记,并实现具有双向视觉和单向文本注意力的混合注意力机制。
http://arxiv.org/abs/2410.14332v1
https://github.com/deepglint/Croc
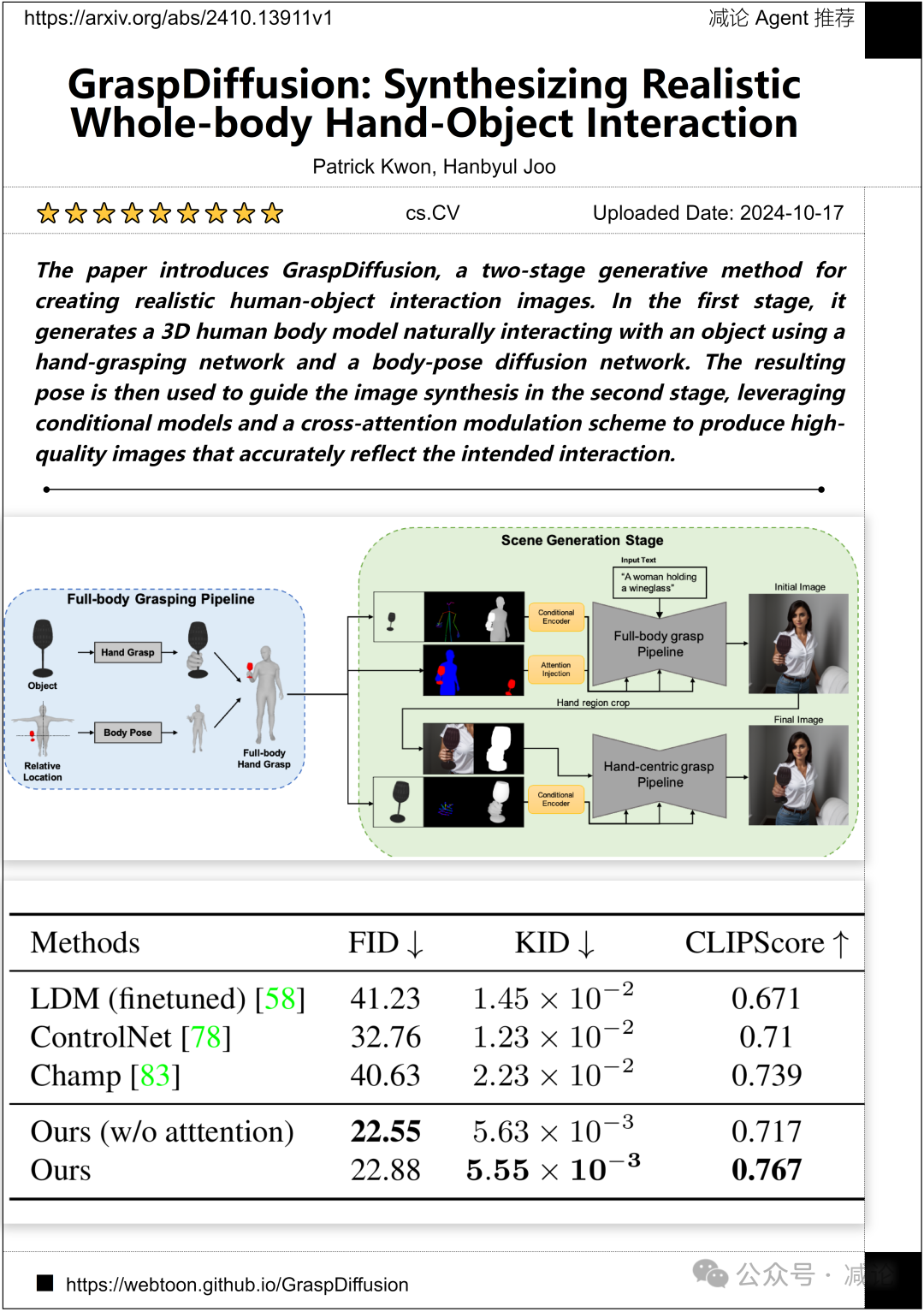
奈华Webtoon, 首尔国立大学的研究团队提出了GraspDiffusion方法,这是一种用于创建逼真人物–物体交互图像的两阶段生成方法。在第一阶段,利用手抓取网络和身体姿势扩散网络生成一个与物体自然交互的3D人体模型。然后,得到的姿势用于引导第二阶段的图像合成,利用条件模型和交叉注意力调制方案生成高质量图像,准确反映预期的交互。
http://arxiv.org/abs/2410.13911v1
https://webtoon.github.io/GraspDiffusion
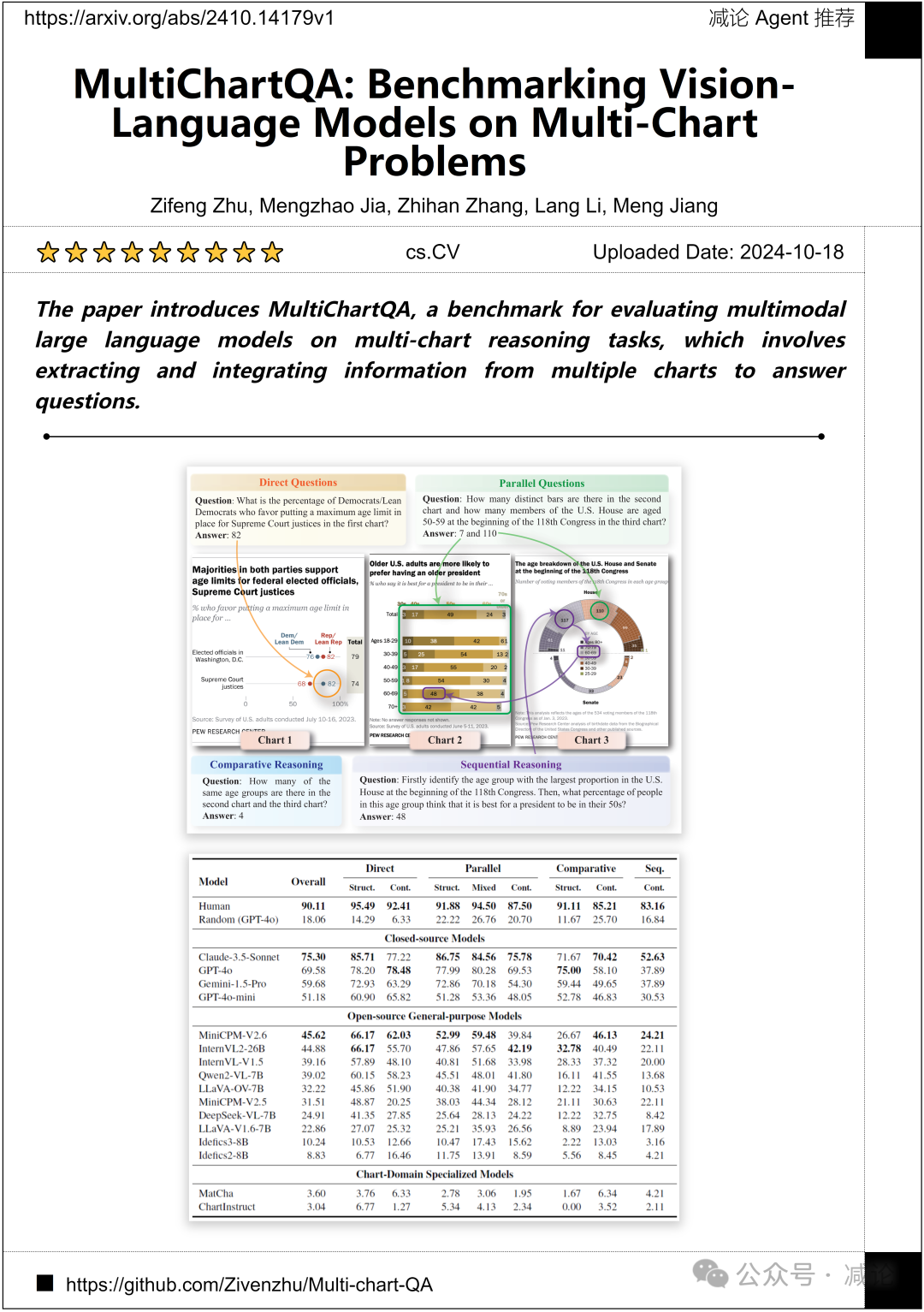
西安交通大学和圣母大学的研究团队介绍了MultiChartQA,这是一个用于评估多模态大型语言模型在多图推理任务上的基准,涉及从多个图表中提取和整合信息来回答问题。
http://arxiv.org/abs/2410.14179v1
https://github.com/Zivenzhu/Multi-chart-QA

浙江大学提出了一种基于能量的导航策略(ENP),通过能量模型对联合状态–动作分布进行建模,其中低能量值对应于专家最有可能执行的状态–动作对,从而与专家策略保持一致。
http://arxiv.org/abs/2410.14250v1
https://github.com/DefaultRui/VLN-ENP

哈尔滨工业大学、根特大学和南京大学的研究人员团队提出了一种新颖的MambaSCI方法。该方法将Mamba模型和UNet架构相结合,通过定制由STMamba、EDR和CA模块组成的Residual-Mamba-Blocks,实现了四通道Bayer图案彩色视频SCI的高效重建。
http://arxiv.org/abs/2410.14214v1
https://github.com/PAN083/MambaSCI

东北大学、中山大学、南洋理工大学的研究团队提出了一种深度表示手术方法,称为SurgeryV2,通过将合并模型的表示与所有层中的专家模型的表示对齐,以减轻基于模型合并的多任务学习中的表示偏差。
http://arxiv.org/abs/2410.14389v1
https://github.com/EnnengYang/SurgeryV2
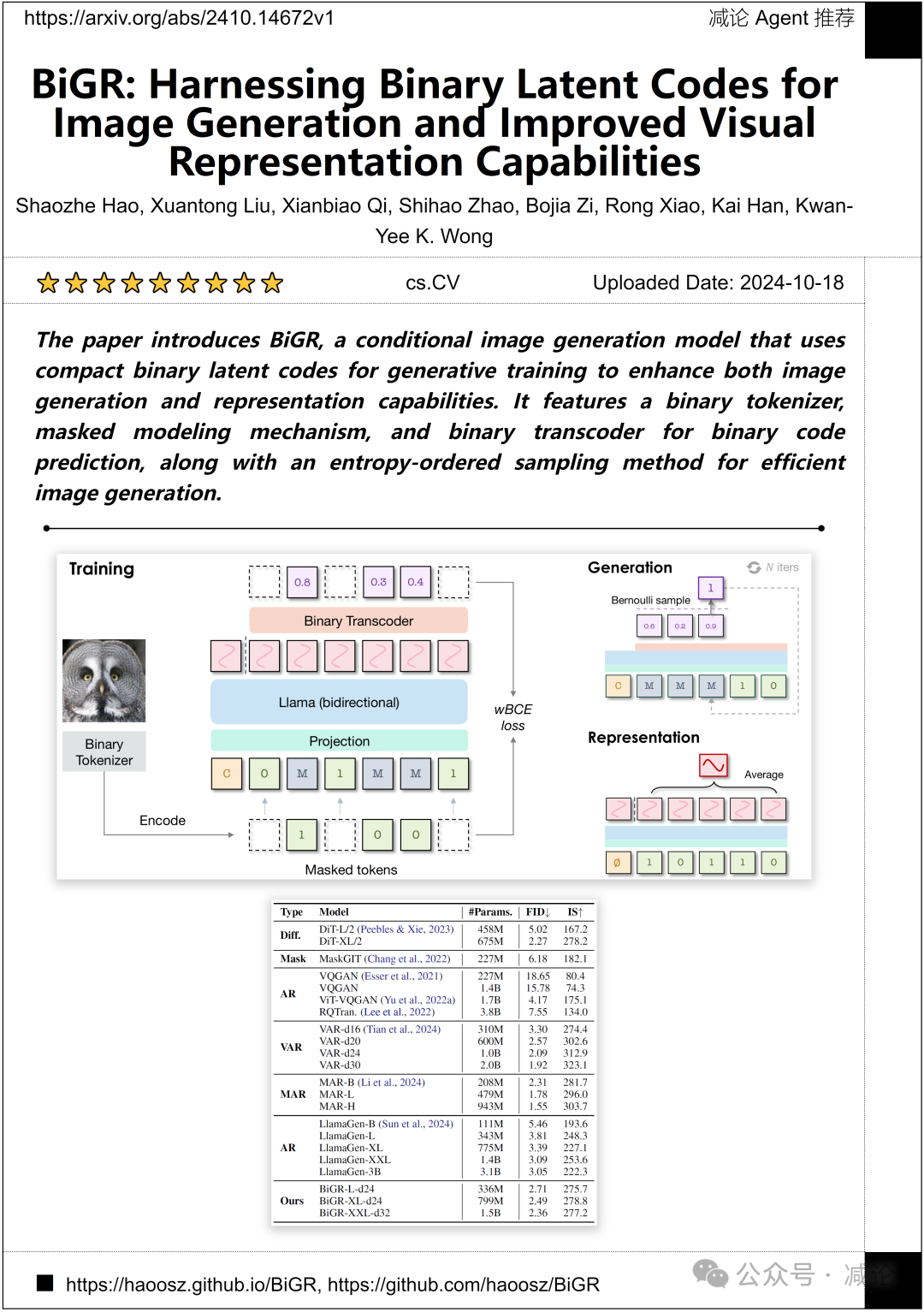
香港大學、香港科技大學、香港中文大學的研究人员提出了一种名为BiGR的条件图像生成模型。该模型利用紧凑的二进制潜在代码进行生成训练,以增强图像生成和表示能力。BiGR具有二进制标记器、掩码建模机制和二进制转码器,用于二进制代码预测,以及熵排序采样方法,用于高效图像生成。
http://arxiv.org/abs/2410.14672v1
https://haoosz.github.io/BiGR, https://github.com/haoosz/BiGR
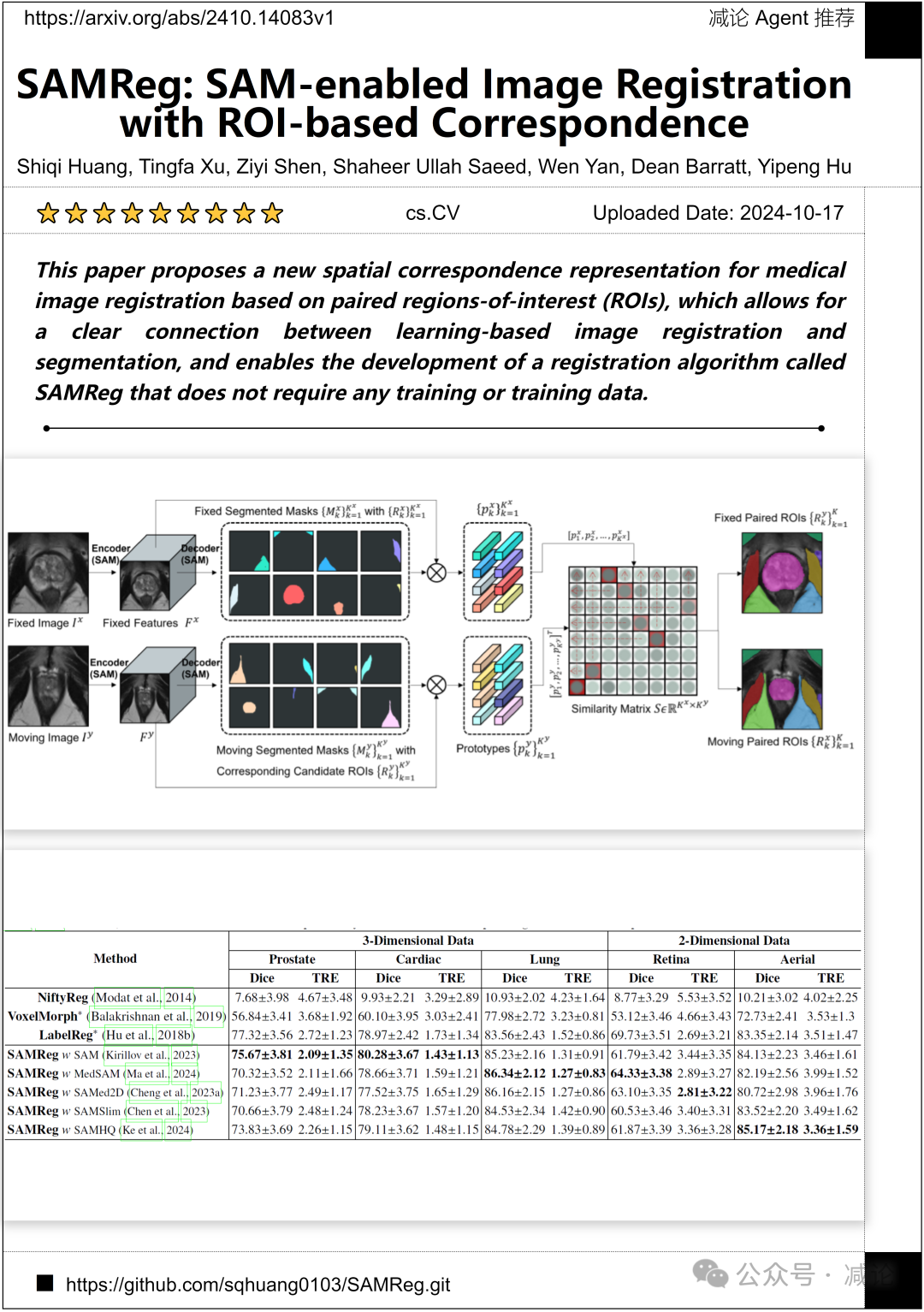
伦敦大学学院和北京理工大学的研究团队提出了一种基于配对感兴趣区域(ROIs)的医学图像配准的新空间对应表示。这种表示允许学习型图像配准和分割之间的明确连接,并实现了一种名为SAMReg的配准算法的开发,该算法不需要任何训练或训练数据。
http://arxiv.org/abs/2410.14083v1
https://github.com/sqhuang0103/SAMReg.git
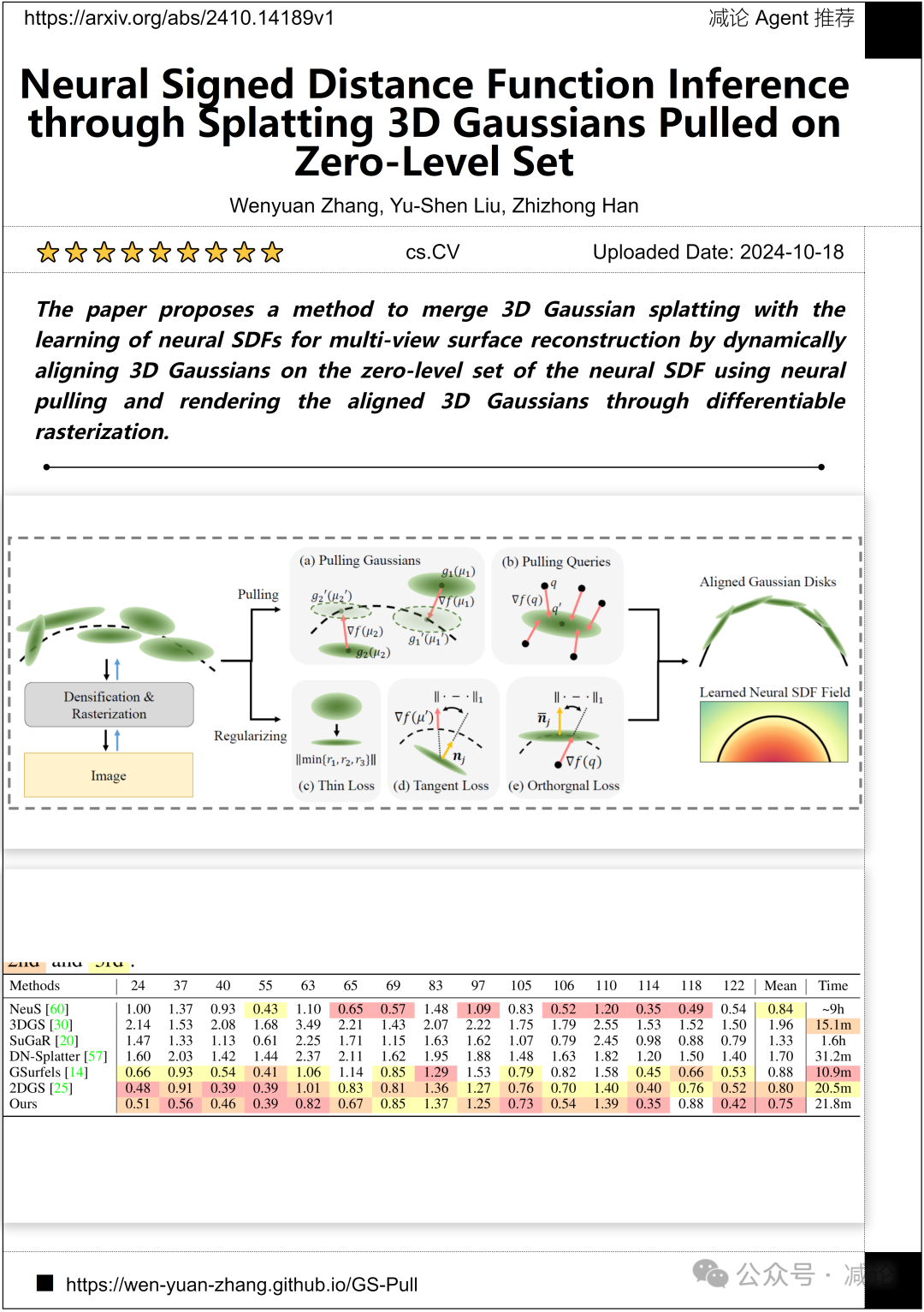
清华大学和韦恩州立大学的研究团队提出了一种方法,通过动态地将3D高斯函数对齐到神经SDF的零级集上,结合学习神经SDF,实现多视角表面重建,然后通过可微分光栅化渲染对齐的3D高斯函数。
http://arxiv.org/abs/2410.14189v1
https://wen-yuan-zhang.github.io/GS-Pull
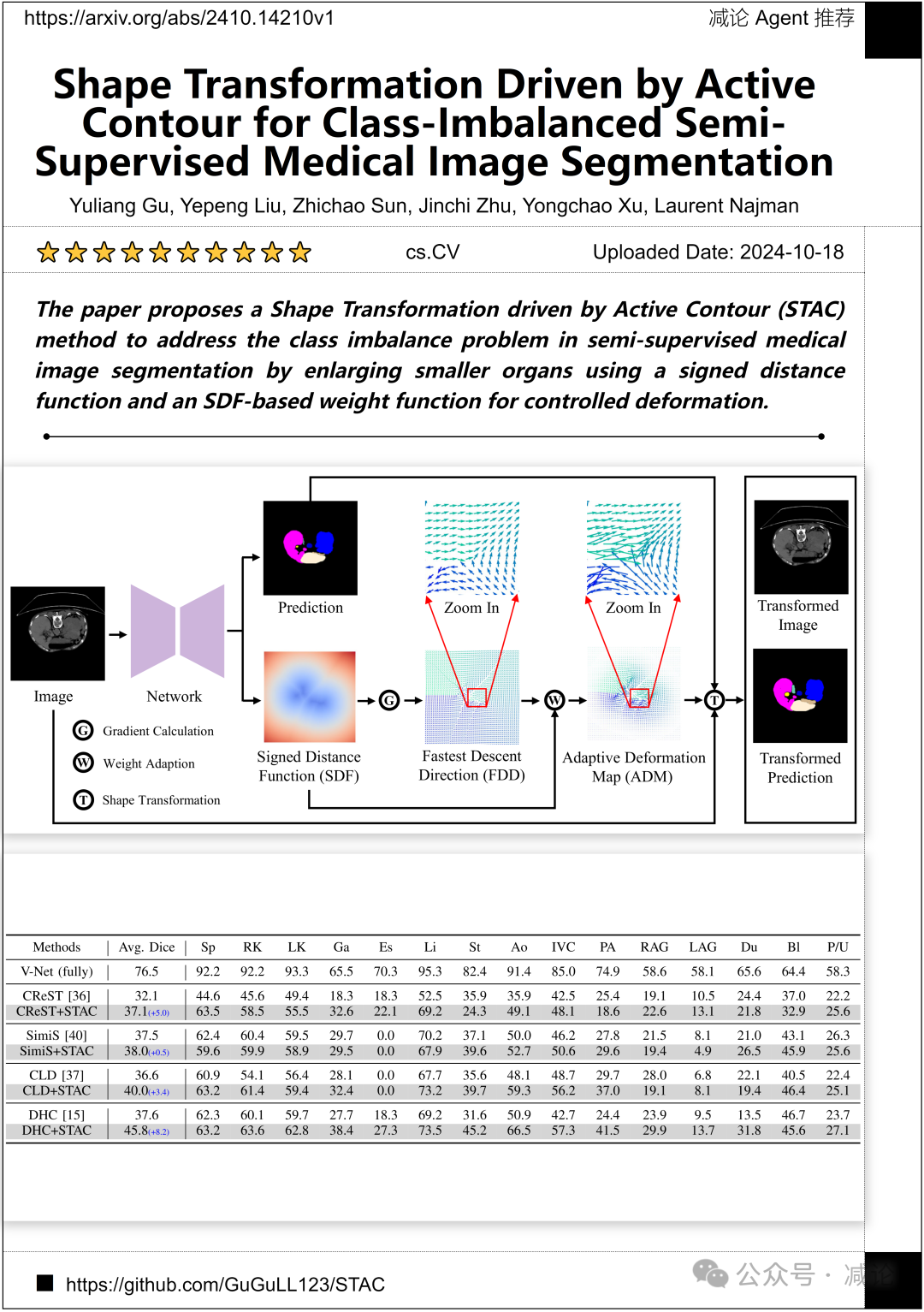
武汉大学与埃菲尔铁塔大学的研究团队提出了一种由主动轮廓驱动的形状变换(STAC)方法,通过使用有符号距离函数和基于SDF的权重函数来扩大较小器官,从而解决半监督医学图像分割中的类别不平衡问题。
http://arxiv.org/abs/2410.14210v1
https://github.com/GuGuLL123/STAC